Data Annotation Tutorial: Definition, Tools, Datasets

Data is an integral part of all machine learning and deep learning algorithms .
It is what drives these complex and sophisticated algorithms to deliver state-of-the-art performances.
If you want to build truly reliable AI models , you must provide the algorithms with data that is properly structured and labeled.
And that's where the process of data annotation comes into play.
You need to annotate data so that the machine learning systems can use it to learn how to perform given tasks.
Data annotation is simple, but it might not be easy 😉 Luckily, we are about to walk you through this process and share our best practices that will save you plenty of time (and trouble!).
Here’s what we’ll cover:

What is data annotation?
Types of data annotations.
- Automated data annotation vs. human annotation
V7 data annotation tutorial
Solve any video or image labeling task 10x faster and with 10x less manual work.
Don't start empty-handed. Explore our repository of 500+ open datasets and test-drive V7's tools.
Ready to streamline AI product deployment right away? Check out:
- V7 Model Training
- V7 Workflows
- V7 Auto Annotation
- V7 Dataset Management
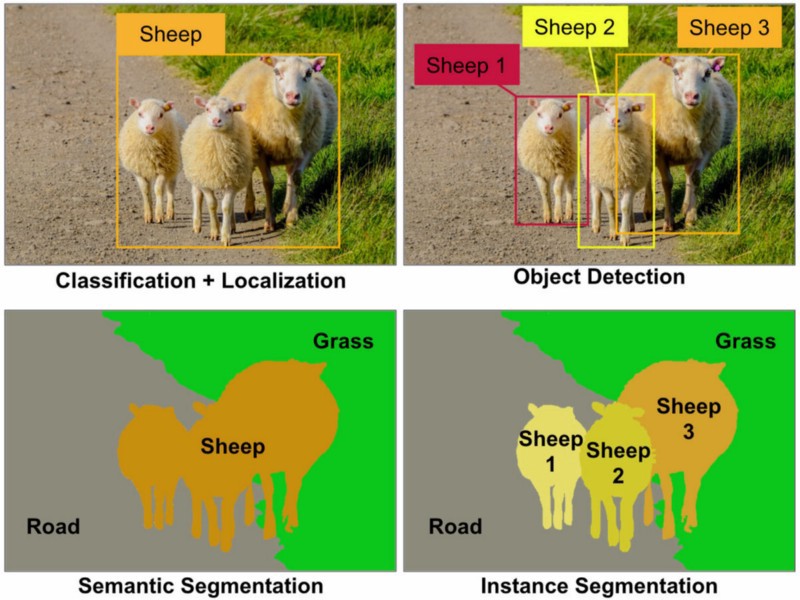
Essentially, this comes down to labeling the area or region of interest—this type of annotation is found specifically in images and videos. On the other hand, annotating text data largely encompasses adding relevant information, such as metadata, and assigning them to a certain class.
In machine learning , the task of data annotation usually falls into the category of supervised learning, where the learning algorithm associates input with the corresponding output, and optimizes itself to reduce errors.
Here are various types of data annotation and their characteristics.
Image annotation
Image annotation is the task of annotating an image with labels. It ensures that a machine learning algorithm recognizes an annotated area as a distinct object or class in a given image.
It involves creating bounding boxes (for object detection ) and segmentation masks (for semantic and instance segmentation) to differentiate the objects of different classes. In V7, you can also annotate the image using tools such as keypoint, 3D cuboids, polyline, keypoint skeleton, and a brush.
💡 Pro tip: Check out 13 Best Image Annotation Tools to find the annotation tool that suits your needs.
Image annotation is often used to create training datasets for the learning algorithms.
Those datasets are then used to build AI-enabled systems like self-driving cars, skin cancer detection tools, or drones that assess the damage and inspect industrial equipment.
💡 Pro tip: Check out AI in Healthcare and AI in Insurance to learn more about AI applications in those industries.
Now, let’s explore and understand the different types of image annotation methods.
- Bounding box
The bounding box involves drawing a rectangle around a certain object in a given image. The edges of bounding boxes ought to touch the outermost pixels of the labeled object.
Otherwise, the gaps will create IoU (Intersection over Union) discrepancies and your model might not perform at its optimum level.
💡 Pro tip: Read Annotating With Bounding Boxes: Quality Best Practices to learn more.
The 3D cuboid annotation is similar to bounding box annotation, but in addition to drawing a 2D box around the object, the user has to take into account the depth factor as well. It can be used to annotate objects such on flat planes that need to be navigated, such as cars or planes, or objects that require robotic grasping.
You can annotate with cuboids to build to train the following model types:
- Object Detection
- 3D Cuboid Estimation
- 6DoF Pose Estimation
Creating a 3D cuboid in V7 is quite easy, as V7's cuboid tool automatically connects the bounding boxes you create by adding a spatial depth. Here's the image of a plane annotated using cuboids.

While creating a 3D cuboid or a bounding box, you might notice that various objects might get unintentionally included in the annotated region. This situation is far from ideal, as the machine learning model might get confused and, as a result, misclassify those objects.
Luckily, there's a way to avoid this situation—
And that's where polygons come in handy. What makes them so effective is their ability to create a mask around the desired object at a pixel level.
V7 offers two ways in which you can create pixel-perfect polygon masks.
a) Polygon tool
You can pick the tool and simply start drawing a line made of individual points around the object in the image. The line doesn't need not be perfect, as once the starting and ending points are connected around the object, V7 will automatically create anchor points that can be adjusted for the desired accuracy.
Once you've created your polygon masks, you can add a label to the annotated object.

b) Auto-annotation tool
V7's auto-annotate tool is an alternative to manual polygon annotation that allows you to create polygon and pixel-wise masks 10x faster.
💡 Pro tip: Ready to train your models? Have a look at Mean Average Precision (mAP) Explained: Everything You Need to Know.
Keypoint tool
Keypoint annotation is another method to annotate an object by a series or collection of points.
This type of method is very useful in hand gesture detection, facial landmark detection, and motion tracking. Keypoints can be used alone, or in combination to form a point map that defines the pose of an object.

Keypoint skeleton tool
V7 also offers keypoint skeleton tool—a network of keypoints connected by vectors, used specifically for pose estimation.
It is used to define the 2D or 3D pose of a multi-limbed object. Keypoints skeletons have a defined set of points that can be moved to adapt to an object’s appearance.
You can use keypoint annotation to train a machine learning model to mimic human pose and then extrapolate their functionality for task-specific applications, for example, AI-enabled robots.
See how you can annotate your image and video data using the keypoint skeleton in V7.
💡 Pro tip: Check out 27+ Most Popular Computer Vision Applications and Use Cases.
Polyline tool
Polyline tool allows the user to create a sequence of joined lines.
You can use this too by clicking around the object of interest to create a point. Each point will create a line by joining the current point with the previous one. It can be used to annotate roads, lane marking, traffic signs, etc.

Semantic segmentation
Semantic segmentation is the task of grouping together similar parts or pixels of the object in a given image. Annotating data using this method allows the machine learning algorithm to learn and understand a specific feature, and it can help it to classify anomalies.
Semantic segmentation is very useful in the medical field, where radiologists use it to annotate X-Ray, MRI, and CT scans to identify the region of interest. Here's an example of a chest X-Ray annotation.

If you are looking for medical data, check out our list of healthcare datasets and see how you can annotate medical imaging data using V7.
Video annotation
Similar to image annotation, video annotation is the task of labeling sections or clips in the video to classify, detect or identify desired objects frame by frame.
Video annotation uses the same techniques as image annotation like bounding boxes or semantic segmentation, but on a frame-by-frame basis. It is an essential technique for computer vision tasks such as localization and object tracking.
Here's how V7 handles video annotation .
Tackle any video format frame by frame. Use AI models to label sequences. Interpolate any annotation.

Text annotation
Data annotation is also essential in tasks related to Natural Language Processing (NLP).
Text annotation refers to adding relevant information about the language data by adding labels or metadata. To get a more intuitive understanding of text annotation let's consider two examples.
1. Assigning Labels
Adding labels means assigning a sentence with a word that describes its type. It can be described with sentiments, technicality, etc. For example, one can assign a label such as “happy” to this sentence “I am pleased with this product, it is great”.
2. Adding metadata
Similarly, in this sentence “I’d like to order a pizza tonight”, one can add relevant information for the learning algorithm, so that it can prioritize and focus on certain words. For instance, one can add information like “I’d like to order a pizza ( food_item ) tonight ( time )”.
Now, let’s briefly explore various types of text annotations.
Sentiment Annotation
Sentiment annotation is nothing but assigning labels that represent human emotions such as sad, happy, angry, positive, negative, neutral, etc. Sentiment annotation finds application in any task related to sentiment analysis (e.g. in retail to measure customer satisfaction based on facial expressions)
Intent Annotation
The intent annotation also assigns labels to the sentences, but it focuses on the intent or desire behind the sentence. For instance, in a customer service scenario, a message like “I need to talk to Sam ”, can route the call to Sam alone, or a message like “I have a concern about the credit card ” can route the call to the team dealing credit card issues.
Named Entity Annotation (NER)
Named entity recognition (NER) aims to detect and classify predefined named entities or special expressions in a sentence.
It is used to search for words based on their meaning, such as the names of people, locations, etc. NER is useful in extracting information along with classifying and categorizing them.
Semantic annotation
Semantic annotation adds metadata, additional information, or tags to text that involves concepts and entities, such as people, places, or topics, as we saw earlier.
Automated data annotation vs. human annotations.
As the hours pass by, human annotators get tired and less focused, which often leads to poor performance and errors. Data annotation is a task that demands utter focus and skilled personnel, and manual annotation makes the process both time-consuming and expensive.
That's why leading ML teams bet on automated data labeling.
Here's how it works—
Once the annotation task is specified, a trained machine learning model can be applied to a set of unlabeled data. The model will then be able to predict the appropriate labels for the new and unseen dataset.
Here's how you can create an automated workflow in V7.
However, in cases where the model fails to label correctly, humans can intervene, review, and correct the mislabelled data. The corrected and reviewed data can be then used to train the labeling model once again.
Automated data labeling can save you tons of money and time, but it can lack accuracy. In contrast, human annotation can be much more costly, but it tends to be more accurate.
Finally, let me show you how you can take your data annotation to another level with V7 and start building robust computer vision models today.
To get started, go ahead and sign up for your 14-day free trial.
Once you are logged in, here's what to do next.
1. Collect and prepare training data
First and foremost, you need to collect the data you want to work with. Make sure that you access quality data to avoid issues with training your models.
Feel free to check out public datasets that you can find here:
- 65+ Best Free Datasets for Machine Learning
- 20+ Open Source Computer Vision Datasets

Once the data is downloaded, separate training data from the testing data . Also, make sure that your training data is varied, as it will enable the learning algorithm to extract rich information and avoid overfitting and underfitting.
2. Upload data to V7
Once the data is ready, you can upload it in bulk. Here's how:
1. Go to the Datasets tab in V7's dashboard, and click on “+ New Dataset”.

2. Give a name to the dataset that you want to upload.

It's worth mentioning that V7 offers three ways of uploading data to their server.
One is the conventional method of dragging and dropping the desired photos or folder to the interface. Another one is uploading by browsing in your local system. And the third one is by using the command line (CLI SDK) to directly upload the desired folder into the server.
Once the data has been uploaded, you can add your classes. This is especially helpful if you are outsourcing your data annotation or collaborating with a team, as it allows you to create annotation checklist and guidelines.
If you are annotating yourself, you can skip this part and add classes on the go later on in the "Classes" section or directly from the annotated image.

💡 Pro tip: Not sure what kind of model you want to build? Check out 15+ Top Computer Vision Project Ideas for Beginners.
3. Decide on the annotation type
If you have followed the steps above and decided to “Add New Class”, then you will have to add the class name and choose the annotation type for the class or the label that you want to add.

As mentioned before, V7 offers a wide variety of annotation tools , including:
- Auto-annotation
- Keypoint skeleton
Once you have added the name of your class, the system will save it for the whole dataset.
Image annotation experience in V7 is very smooth.
In fact, don't believe just me—here's what one of our users said in his G2 review:
V7 gives fast and intelligent auto-annotation experience. It's easy to use. UI is really interactive.
Apart from a wide range of available annotation tools, V7 also comes equipped with advanced dataset management features that will help you organize and manage your data from one place.
And let's not forget about V7's Neural Networks that allow you to train instance segmentation, image classification , and text recognition models.
Unlike other annotation tools, V7 allows you to annotate your data as a video rather than individual images.
You can upload your videos in any format, add and interpolate your annotations, create keyframes and sub annotations, and export your data in a few clicks!
Uploading and annotating videos is as simple as annotating images.
V7 offers frame by frame annotation method where you can essentially create a bounding box or semantic segmentation per-frame basis.

Apart from image and video annotation , V7 provides text annotation as well. Users can take advantage of the Text Scanner model that can automatically read the text in the images.
To get started, just go to the Neural Networks tab and run the Text Scanner model.

Once you have turned it on you can go back to the dataset tab and load the dataset. It is the same process as before.
Now you can create a new bounding box class. The bounding box will detect text in the image. You can specify the subtype as Text in the Classes page of your dataset.

Once the data is added and the annotation type is defined you can then add the Text Scanner model to your workflow under the Settings page of your dataset.

After adding the model to your workflow map your new text class.

Now, go back to the dataset tab and send your data the text scanner model by clicking on ‘Advance 1 Stage’; this will start the training process.

Once the training is over the model will detect and read text on any kind of image, whether it's a document, photo, or video.

💡 Pro tip: If you are looking for a free image annotation tool, check out The Complete Guide to CVAT—Pros & Cons
Data annotation: next steps.
Nice job! You've made it that far 😉
By now, you should have a pretty good idea of what is data annotation and how you can annotate data for machine learning.
We've covered image, video, and text annotation, which are used in training computer vision models. If you want to apply your new skills, go ahead, pick a project, sign up to V7, collect some data, and start labeling it to build image classifier or object detectors!
💡 To learn more, go ahead and check out:
An Introductory Guide to Quality Training Data for Machine Learning
Simple Guide to Data Preprocessing in Machine Learning
Data Cleaning Checklist: How to Prepare Your Machine Learning Data
3 Signs You Are Ready to Annotate Data for Machine Learning
The Beginner’s Guide to Contrastive Learning
9 Reinforcement Learning Real-Life Applications
Mean Average Precision (mAP) Explained: Everything You Need to Know
A Step-by-Step Guide to Text Annotation [+Free OCR Tool]
The Essential Guide to Data Augmentation in Deep Learning
Nilesh Barla is the founder of PerceptronAI, which aims to provide solutions in medical and material science through deep learning algorithms. He studied metallurgical and materials engineering at the National Institute of Technology Trichy, India, and enjoys researching new trends and algorithms in deep learning.
“Collecting user feedback and using human-in-the-loop methods for quality control are crucial for improving Al models over time and ensuring their reliability and safety. Capturing data on the inputs, outputs, user actions, and corrections can help filter and refine the dataset for fine-tuning and developing secure ML solutions.”
Building AI products? This guide breaks down the A to Z of delivering an AI success story.

Related articles

- Software Testing
- Software Development
- Data Annotation
- Data Annotation for Machine Learning: A to Z Guide

In this dynamic era of machine learning, the fuel that powers accurate algorithms and AI breakthroughs is high-quality data. To help you demystify the crucial role of data annotation for machine learning, and master the complete process of data annotation from its foundational principles to advanced techniques, we’ve created this comprehensive guide. Let’s dive in and enhance your machine-learning journey.
Data Annotation for Machine Learning
What is machine learning.
Machine learning is embedded in AI and allows machines to perform specific tasks through training. With data AI annotation, it can learn about pretty much everything. Machine learning techniques can be described into four types: Unsupervised learning, Semi-Supervised Learning, Supervised Learning, and Reinforcement learning
- Supervised Learning: Supervised learning learns from a set of labeled data. It is an algorithm that predicts the outcome of new data based on previously known labeled data.
- Unsupervised Learning : In unsupervised machine learning, training is based on unlabeled data. In this algorithm, you don’t know the outcome or the label of the input data.
- Semi-Supervised Learning : The AI will learn from a dataset that is partly labeled. This is the combination of the two types above.
- Reinforcement Learning : Reinforcement learning is the algorithm that helps a system determine its behavior to maximize its benefits. Currently, it is mainly applied to Game Theory, where algorithms need to determine the next move to achieve the highest score.
Although there are four types of techniques, the most frequently used are unsupervised and supervised learning. You can see how unsupervised and supervised learning works according to Booz Allen Hamilton’s description in this picture:

How data annotation for machine learning works
What is Annotated Data?
Data annotation for machine learning is the process of labeling or tagging data to make it understandable and usable for machine learning algorithms. This involves adding metadata, such as categories, tags, or attributes, to raw data, making it easier for algorithms to recognize patterns and learn from the data.
In fact, data annotation, or AI data processing, was once the most unwanted process of implementing AI in real life. Data annotation AI is a crucial step in creating supervised machine-learning models where the algorithm learns from labeled examples to make predictions or classifications.
The Importance of Data Annotation Machine Learning
Data annotation plays a pivotal role in machine learning for several reasons:
- Training Supervised Models : Most machine learning algorithms, especially supervised learning models, require labeled data to learn patterns and make predictions. Without accurate annotations, models cannot generalize well to new, unseen data.
- Quality and Performance : The quality of annotations directly impacts the quality and performance of machine learning models. Inaccurate or inconsistent annotations can lead to incorrect predictions and reduced model effectiveness.
- Algorithm Learning : Data annotation provides the algorithm with labeled examples, helping it understand the relationships between input data and the desired output. This enables the algorithm to learn and generalize from these examples.
- Feature Extraction : Annotations can also involve marking specific features within the data, aiding the algorithm in understanding relevant patterns and relationships.
- Benchmarking and Evaluation : Labeled datasets allow for benchmarking and evaluating the performance of different algorithms or models on standardized tasks.
- Domain Adaptation : Annotations can help adapt models to specific domains or tasks by providing tailored labeled data.
- Research and Development : In research and experimental settings, annotated data serves as a foundation for exploring new algorithms, techniques, and ideas.
- Industry Applications : Data annotation is essential in various industries, including healthcare (medical image analysis), autonomous vehicles (object detection), finance (fraud detection), and more.
Overall, data annotation is a critical step in the machine-learning pipeline that facilitates the creation of accurate, effective, and reliable models capable of performing a wide range of tasks across different domains.

Best data annotation for machine learning company
How to Process Data Annotation for Machine Learning?
Step 1: data collection.
Data collection is the process of gathering and measuring information from countless different sources. To use the data we collect to develop practical artificial intelligence (AI) and machine learning solutions, it must be collected and stored in a way that makes sense for the business problem at hand.
There are several ways to find data. In classification algorithm cases, it is possible to rely on class names to form keywords and to use crawling data from the Internet to find images. Or you can find photos, and videos from social networking sites, satellite images on Google, free collected data from public cameras or cars (Waymo, Tesla), and even you can buy data from third parties (notice the accuracy of data). Some of the standard datasets can be found on free websites like Common Objects in Context (COCO) , ImageNet , and Google’s Open Images .
Some common data types are Image, Video, Text, Audio, and 3D sensor data.
- Image data annotation for machine learning (photographs of people, objects, animals, etc.)
Image is perhaps the most common data type in the field of data annotation for machine learning. Since it deals with the most basic type of data there is, it plays an important part in a wide range of applications, namely robotic visions, facial recognition, or any kind of application that has to interpret images.
From the raw datasets provided from multiple sources, it is vital for these to be tagged with metadata that contains identifiers, captions, or keywords.
The significant fields that require enormous effort for data annotation for machine learning are healthcare applications (as in our case study of blood-cell annotation), and autonomous vehicles (as in our case study of traffic lights and sign annotation). With the effective and accurate annotation of images, AI applications can work flawlessly with no intervention from humans.
To train these solutions, metadata must be assigned to the images in the form of identifiers, captions, or keywords. From computer vision systems used by self-driving vehicles and machines that pick and sort produce to healthcare applications that auto-identify medical conditions, there are many use cases that require high volumes of annotated images. Image annotation increases precision and accuracy by effectively training these systems.

Image data annotation for machine learning
- Video data annotation for machine learning (Recorded tape from CCTV or camera, usually divided into scenes)
When compared with images, video is a more complex form of data that demands a bigger effort to annotate correctly. To put it simply, a video consists of different frames which can be understood as pictures. For example, a one-minute video can have thousands of frames, and to annotate this video, one must invest a lot of time.
One outstanding feature of video annotation in the Artificial Intelligence and Machine Learning model is that it offers great insight into how an object moves and its direction.
A video can also inform whether the object is partially obstructed or not while image annotation is limited to this.

Video data annotation for machine learning
- Text data annotation for machine learning: Different types of documents include numbers and words and they can be in multiple languages.
Algorithms use large amounts of annotated data to train AI models, which is part of a larger data labeling workflow. During the annotation process, a metadata tag is used to mark up the characteristics of a dataset. With text annotation, that data includes tags that highlight criteria such as keywords, phrases, or sentences. In certain applications, text annotation can also include tagging various sentiments in text, such as “angry” or “sarcastic” to teach the machine how to recognize human intent or emotion behind words.
The annotated data, known as training data, is what the machine processes. The goal? Help the machine understand the natural language of humans. This procedure, combined with data pre-processing and annotation, is known as natural language processing, or NLP.

Text data annotation for machine learning
- Audio data annotation for machine learning: They are sound records from people having dissimilar demographics.
As the market is trending with Voice AI Data Annotation for machine learning, LTS Group provides top-notch service in annotating voice data. We have annotators fluent in languages.
All types of sounds recorded as audio files can be annotated with additional keynotes and suitable metadata. The Cogito annotation team is capable of exploring the audio features and annotating the corpus with intelligent audio information. Each word in the audio is carefully listened to by the annotators in order to recognize the speech correctly with our sound annotation service.
The speech in an audio file contains different words and sentences that are meant for the listeners. Making such phrases in the audio files recognizable to machines is possible, by using a special data labeling technique while annotating the audio. In NLP or NLU, machine algorithms for speech recognition need audio linguistic annotation to recognize such audio.
Audio data annotation facilitates various real-life AI applications. A prime example is the application of an AI-powered audio transcription tool that swiftly generates accurate transcripts for podcast episodes within minutes.

Audio data annotation for machine learning
- 3D Sensor data annotation for machine learning: 3D models generated by sensor devices.
No matter what, money is always a factor. 3D-capable sensors greatly vary in build complexity and accordingly – in price, ranging from hundreds to thousands of dollars. Choosing them over the standard camera setup is not cheap, especially given that you would usually need multiple units in order to guarantee a large enough field of view.

3D sensor data annotation for machine learning
Low-resolution data annotation for machine learning
In many cases, the data gathered by 3D sensors are nowhere as dense or high-resolution as the one from conventional cameras. In the case of LiDARs, a standard sensor discretizes the vertical space in lines (the number of lines varies), each having a couple of hundred detection points. This produces approximately 1000 times fewer data points than what is contained in a standard HD picture. Furthermore, the further away the object is located, the fewer samples land on it, due to the conical shape of the laser beams’ spread. Thus the difficulty of detecting objects increases exponentially with their distance from the sensor.”
Step 2: Problem Identification
Knowing what problem you are dealing with will help you to decide the techniques you should use with the input data. In computer vision, there are some tasks such as:
- Image classification: Collect and classify the input data by assigning a class label to an image.
- Object detection & localization: Detect and locate the presence of objects in an image and indicate their location with a bounding box, point, line, or polyline.
- Object instance / semantic segmentation: In semantic segmentation, you have to label each pixel with a class of objects (Car, Person, Dog, etc.) and non-objects (Water, Sky, Road, etc.). Polygon and masking tools can be used for object semantic segmentation.
Step 3: Data Annotation for Machine Learning
After identifying the problems, now you can process the data labeling accordingly. With the classification task, the labels are the keywords used during finding and crawling data. For instance segmentation task, there should be a label for each pixel of the image. After getting the label, you need to use tools to perform image annotation (i.e. to set labels and metadata for images). The popular annotated data tools can be named Comma Coloring, Annotorious, and LabelMe.
However, this way is manual and time-consuming. A faster alternative is to use algorithms like Polygon-RNN ++ or Deep Extreme Cut. Polygon-RNN ++ takes the object in the image as the input and gives the output as polygon points surrounding the object to create segments, thus making it more convenient to label. The working principle of Deep Extreme Cut is similar to Polygon-RNN ++ but it allows up to 4 polygons.

Process of data annotation for machine learning
It is also possible to use the “Transfer Learning” method to label data, by using pre-trained models on large-scale datasets such as ImageNet, and Open Images. Since the pre-trained models have learned many features from millions of different images, their accuracy is fairly high. Based on these models, you can find and label each object in the image. It should be noted that these pre-trained models must be similar to the collected dataset to perform feature extraction or fine-turning.
Types of Annotation Data
Data Annotation for machine learning is the process of labeling the training data sets, which can be images, videos, or audio. Needless to say, AI Annotation is of paramount importance to Machine Learning (ML), as ML algorithms need (quality) annotated data to process.
In our AI training projects, we use different types of annotation. Choosing what type(s) to use mainly depends on what kind of data and annotation tools you are working on.
- Bounding Box : As you can guess, the target object will be framed by a rectangular box. The data labeled using bounding boxes are used in various industries, mostly in automotive vehicle, security, and e-commerce industries.
- Polygon : When it comes to irregular shapes like human bodies, logos, or street signs, to have a more precise outcome, Polygons should be your choice. The boundaries drawn around the objects can give an exact idea about the shape and size, which can help the machine make better predictions.
- Polyline : Polylines usually serve as a solution to reduce the weakness of bounding boxes, which usually contain unnecessary space. It is mainly used to annotate lanes on road images.
- 3D Cuboids : The 3D Cuboids are utilized to measure the volume of objects which can be vehicles, buildings, or furniture.
- Segmentation : Segmentation is similar to polygons but more complicated. While polygons just choose some objects of interest, with segmentation, layers of alike objects are labeled until every pixel of the picture is done, which leads to better results of detection.
- Landmark : Landmark annotation comes in handy for facial and emotional recognition, human pose estimation, and body detection. The applications using data labeled by landmarks can indicate the density of the target object within a specific scene.

Types of data annotation for machine learning
Popular Tools of Data Annotation for Machine Learning
In machine learning, data processing, and analysis are extremely important, so I will introduce to you some Tools for annotating data to make the job simpler:
- Labelbox : Labelbox is a widely used platform that supports various data types, such as images, text, and videos. It offers a user-friendly interface, project management features, collaboration tools, and integration with machine learning pipelines.
- Amazon SageMaker Ground Truth : Provided by Amazon Web Services, SageMaker Ground Truth combines human annotation and automated labeling using machine learning. It’s suitable for a range of data types and can be seamlessly integrated into AWS workflows.
- Supervisely : Supervised focuses on computer vision tasks like object detection and image segmentation. It offers pre-built labeling interfaces, collaboration features, and integration with popular deep-learning frameworks.
- VGG Image Annotator (VIA) : Developed by the University of Oxford’s Visual Geometry Group, VIA is an open-source tool for image annotation. It’s commonly used for object detection and annotation tasks and supports various annotation types.
- CVAT (Computer Vision Annotation Tool) : CVAT is another popular open-source tool, specifically designed for annotating images and videos in the context of computer vision tasks. It provides a collaborative platform for creating bounding boxes, polygons, and more.

Popular data annotation tools
When selecting a data annotation for machine learning tool, consider factors like the type of data you’re working with, the complexity of annotation tasks, collaboration requirements, integration with your machine learning workflow, and budget constraints. It’s also a good idea to try out a few tools to determine which one best suits your specific needs.
it is crucial for businesses to consider the top 5 annotation tool features to find the most suitable one for their products: Dataset management, Annotation Methods, Data Quality Control, Workforce Management, and Security.
Who can annotate data?
The data annotators are the ones in charge of labeling the data. There are some ways to allocate them:
In-house Annotating Data
The data scientists and AI researchers in your team are the ones who label data. The advantages of this way are easy to manage and has a high accuracy rate. However, it is such a waste of human resources since data scientists will have to spend much time and effort on a manual, repetitive task.
In fact, many AI projects have failed and been shut down, due to the poor quality of training data and inefficient management.
In order to ensure data labeling quality, you can check out our comprehensive Data annotation best practices . This guide follows the steps in a data annotation project and how to successfully and effectively manage the project:
- Define and plan the annotation project
- Managing timelines
- Creating guidelines and training workforce
- Feedback and changes
Outsourced AI Annotations Data
You can find a third party – a company that provides data annotation services. Although this option will cost less time and effort for your team, you need to ensure that the company commits to providing transparent and accurate data.
Online Workforce Resources for Data Annotation
Alternatively, you can use online workforce resources like Amazon Mechanical Turk or Crowdflower. These platforms recruit online workers around the world to do data annotation. However, the accuracy and the organization of the dataset are the issues that you need to consider when purchasing this service.
The Bottom Line
The data annotation for machine learning guide described here is basic and straightforward. To build machine learning, besides data scientists who will set the infrastructure and scale for complex machine learning tasks, you still need to find data annotators to label the input data. Lotus Quality Assurance provides professional data annotation services in different domains. With our quality review process, we commit to bringing a high-quality and secure service. Contact us for further support!
Our Clients Also Ask
What is data annotation in machine learning.
Data annotation in machine learning refers to the process of labeling or tagging data to create a labeled dataset. Labeled data is essential for training supervised machine learning models, where the algorithm learns patterns and relationships in the data to make predictions or classifications.
How many types of data annotation for machine learning?
Data Annotation for machine learning is the procedure of labeling the training data sets, which can be images, videos, or audio. In our AI training projects, we utilize diverse types of data annotation. Here are the most popular types: Bounding Box, Polygon, Polyline, 3D Cuboids, Segmentation, and Landmark.
What are the most popular data annotation tools?
Here are some popular tools for annotating data: Labelbox, Amazon SageMaker Ground Truth, CVAT (Computer Vision Annotation Tool), VGG Image Annotator (VIA), Annotator: ALOI Annotation Tool, Supervisely, LabelMe, Prodigy, etc.
What is a data annotator?
A data annotator is a person who adds labels or annotations to data, creating labeled datasets for training machine learning models. They follow guidelines to accurately label images, text, or other data types, helping models learn patterns and make accurate predictions.

Data Annotation's Role in Machine Learning: An Overview
Data annotation is a fundamental component of machine learning, playing a vital role in training models and enabling them to understand and interpret data accurately. By providing labeled data, annotations serve as the ground truth that guides machine learning algorithms in learning patterns and making accurate predictions. Various types of data annotation, including image annotation , text annotation , video annotation , and audio annotation , are utilized across different domains to enhance the performance and reliability of machine learning models.
To facilitate the annotation process, there are data labeling services and data annotation tools available, offering efficient solutions for accurately labeling and categorizing data. These services and tools streamline the annotation workflow, ensuring the quality and accuracy of annotations, and ultimately improving the performance of machine learning models.
Key Takeaways:
- Data annotation is crucial in machine learning for training models and making accurate predictions.
- Image annotation , text annotation , video annotation , and audio annotation are different types of data annotation techniques.
- Data labeling services and annotation tools exist to facilitate the annotation process.
- The quality and accuracy of annotations directly impact the performance and reliability of machine learning models.
- Data annotation is essential for various applications, including object recognition , sentiment analysis , and speech recognition.
What is Annotation in Machine Learning?
Annotation in machine learning refers to the process of labeling data to provide meaningful information to algorithms. It involves adding annotations or tags to data points to convey valuable information to algorithms more easily. Annotations can take different forms depending on the type of data being annotated, such as image annotation , text annotation , video annotation , and audio annotation . The effectiveness of annotations lies in their ability to provide context and structure to the data, enabling the algorithms to extract meaningful knowledge from the labeled examples.
Annotations play a crucial role in training machine learning models by providing a reference or ground truth that algorithms can learn from. By labeling data accurately, annotations aid in teaching models to recognize patterns, classify information, or perform specific tasks.
For example, in image annotation, objects, regions, or specific features within an image are labeled to train computer vision models. Text annotation involves labeling and categorizing textual data, contributing to natural language processing tasks like named entity recognition and sentiment analysis . In video annotation, objects or actions within video sequences are labeled, facilitating video analysis in applications such as surveillance and autonomous technology. Audio annotation encompasses labeling and transcribing audio data to enhance speaker identification , speech emotion recognition , and audio transcription tasks.
Each type of annotation technique contributes to the development and improvement of machine learning models in their respective domains. The labeled data creates a foundation that enables the models to interpret and understand the input they receive, resulting in more accurate and reliable predictions or outputs.
By leveraging the power of annotation in machine learning , organizations can unlock the potential of their data and build advanced models that can automate processes, make informed decisions, and drive innovation across various industries.
Benefits of Annotation in Machine Learning
Annotations provide context and structure to the data, enabling algorithms to extract meaningful knowledge from labeled examples. Annotated data serves as the ground truth for training machine learning models, facilitating pattern recognition and accurate predictions. By leveraging annotations, organizations can build advanced models that automate processes and make informed decisions. Annotation enhances the accuracy and reliability of machine learning models in various domains, from computer vision to natural language processing.
Types of Data Annotation: Image Annotation
Image annotation is a critical technique for training computer vision models to accurately recognize and classify objects within images. By labeling objects, regions, or specific features, image annotation provides valuable information to algorithms, enabling them to understand the presence and identity of objects. This enhances the accuracy and performance of computer vision algorithms, particularly for applications such as object recognition and image classification .
Several image annotation techniques are employed to annotate images effectively:
- Bounding boxes: This technique involves drawing rectangular boxes around objects or regions of interest within an image, clearly indicating their boundaries.
- Polygons: In polygon annotation, the contours of objects are outlined using a series of connected vertices, allowing for more precise labeling.
- Key points: Key point annotation involves marking specific points of interest, such as the corners of objects or the joints of a skeleton, to denote significant features for recognition.
- Semantic segmentation: This technique assigns semantic labels to pixels or regions within an image, enabling algorithms to differentiate objects and understand their boundaries.
Image annotation techniques , such as bounding boxes and semantic segmentation, play a crucial role in object recognition and image classification , enabling machines to accurately identify and classify objects within images.
Types of Data Annotation: Text Annotation
Text annotation is a crucial process in machine learning, involving the labeling and categorizing of textual data, such as documents, articles, or sentences. It plays a significant role in natural language processing tasks, enabling machines to understand and interpret the text accurately.
One of the primary applications of text annotation is named entity recognition , which involves identifying and classifying named entities within the text, such as people, organizations, locations, and dates. Sentiment analysis is another important task in which text annotation is utilized. It involves determining the sentiment or emotion expressed in the text, enabling sentiment classification for various purposes, such as customer feedback analysis or social media monitoring.
Part-of-speech tagging is yet another essential task enabled by text annotation. It involves assigning grammatical information, such as noun, verb, adjective, or adverb, to each word in the text. This provides valuable context and structure to the language, enabling machines to analyze and process the text effectively.
"Text annotation techniques provide valuable context and meaning to words within the text, enabling machines to understand and interpret the text accurately."
Text annotation plays a crucial role in various applications, including information extraction, text categorization, and question answering. By labeling and categorizing textual data, machine learning models can extract relevant information, classify texts into different categories, and provide accurate answers to user queries.
Overall, text annotation empowers machines to make sense of textual data, enabling them to perform a wide range of natural language processing tasks effectively. It enhances the understanding and interpretation of textual information, contributing to the development of advanced machine learning models in various domains.
Example of Text Annotation Workflow
Understanding the process of text annotation can provide further insights into its significance and impact. Here's an example of a typical text annotation workflow:
- Annotators receive a set of documents or sentences to be annotated.
- They read and analyze the text, identifying relevant entities, sentiments, and parts of speech.
- Using annotation tools, annotators label and categorize the identified entities, sentiments, and parts of speech.
- The annotated data is then used to train machine learning models, allowing them to learn patterns and make accurate predictions in various natural language processing tasks.
Through this workflow, text annotation facilitates the development of robust and reliable machine learning models that can effectively process and analyze textual data.

Types of Data Annotation: Video Annotation
Video annotation plays a critical role in enabling computer vision models to analyze and understand video content. This process involves labeling objects or actions within video sequences, allowing machines to track objects, classify actions, and identify specific time intervals or events. Video annotation techniques such as object tracking , action recognition , and temporal annotation enhance the capabilities of computer vision algorithms, facilitating applications such as surveillance, autonomous technology, and activity recognition.
Object tracking is a video annotation technique that focuses on following and tracing specific objects or targets throughout a video. By tracking objects, computer vision models can understand the movement and behavior of those objects within the video, improving object recognition and scene understanding.
Action recognition is another video annotation technique that involves labeling and categorizing different actions or activities performed within a video. This annotation enables machines to recognize and distinguish various actions, empowering applications like human activity analysis, sports video analysis, and video surveillance.
Temporal annotation is the process of marking specific time intervals or events within a video. It helps in identifying crucial moments or incidents that are significant for video analysis. Temporal annotation plays a vital role in applications like event detection, video summarization, and video search, enabling machines to pinpoint and extract relevant information.
Example: Video Annotation for Autonomous Driving
An illustrative example of video annotation is its application in autonomous driving. By annotating objects, actions, and temporal information within video footage, computer vision models can identify other vehicles, pedestrians, traffic signs, and road markings. This annotated data serves as a training ground truth for autonomous vehicles to make informed decisions and navigate safely on the roads. The accuracy and reliability of video annotation heavily influence the performance and safety of autonomous driving systems.
Types of Data Annotation: Audio Annotation
Audio annotation plays a crucial role in machine learning by labeling and transcribing audio data, enabling the extraction of valuable insights and patterns. This type of annotation is widely used in tasks such as speaker identification , speech emotion recognition , and audio transcription . Through various techniques like phonetic annotation, speaker diarization, and event labeling, audio annotation enhances the performance and accuracy of machine learning models in applications related to audio data.
Speaker Identification
Speaker identification is a key task in audio annotation, where machine learning models are trained to recognize and distinguish different speakers in audio recordings. By labeling the speakers and their corresponding segments in the data, models can accurately identify and differentiate speakers, enabling applications such as voice biometrics and speaker recognition systems.
Speech Emotion Recognition
Speech emotion recognition involves annotating audio data to identify and categorize the emotions expressed in spoken language. By labeling emotions such as happiness, sadness, anger, or surprise, machine learning models can accurately classify and interpret the emotional states of speakers. This enables applications in sentiment analysis, voice-based virtual assistants , and emotional speech recognition.
Transcription
Transcription involves the process of converting audio data into written text. Through audio annotation techniques like phonetic annotation and automatic speech recognition, machine learning models can transcribe spoken language accurately. Transcription is essential in various domains, including media and entertainment, customer support, and accessibility for the hearing impaired.
Audio annotation is a powerful tool for unlocking insights and understanding in audio data. By providing labeled information through techniques such as speaker identification, speech emotion recognition, and transcription, machine learning models can effectively analyze and interpret audio, creating valuable applications and solutions across industries.
Techniques of Audio Annotation
Why does annotation in machine learning matter.
Annotation plays a crucial role in machine learning as it provides labeled data that serves as the ground truth for training models. Without accurate and properly annotated data, machine learning algorithms would struggle to learn patterns and make meaningful predictions.
Annotation enables models to make informed decisions and predictions based on their training, even when faced with previously unseen data.
The quality and accuracy of annotations directly impact the performance and reliability of machine learning models, making annotation an essential component of the machine learning pipeline.
Key Challenges of Data Annotation in Machine Learning
Data annotation in machine learning presents several challenges that need to be addressed for successful implementation. These challenges include:
- Annotation Quality: High-quality annotations are crucial for training accurate and reliable machine learning models. Ensuring consistent, accurate, and detailed annotations that capture relevant information is essential for achieving optimal results.
- Scalability: The exponential growth of data poses a significant challenge in managing and annotating large volumes of data efficiently. Scaling annotation processes to handle increasingly large datasets while maintaining quality and accuracy is critical.
- Subjectivity: Data annotation can involve subjective judgments, such as determining the boundaries of objects or identifying sentiment. Managing subjectivity requires clear guidelines and continuous communication among annotators to maintain consistency and minimize bias.
- Consistency: Achieving consistent annotations across different annotators is crucial to ensure reliable training data. Consistency ensures that models can generalize effectively and make accurate predictions on unseen data.
- Privacy and Security: Data annotation often involves sensitive information, such as personally identifiable information (PII). Ensuring the privacy and security of annotated data by implementing robust data protection measures is essential to maintain trust and compliance.
Addressing these challenges is vital for obtaining high-quality annotated datasets that enable the development of accurate and reliable machine learning models.
"High-quality annotations are crucial for providing reliable training data for machine learning models."
Use Cases of Data Annotation in Machine Learning
Data annotation is a critical component in machine learning with various applications across different domains. Let's explore some common use cases where data annotation plays a vital role:
Medical Imaging
In the field of medical imaging , data annotation is crucial for accurate disease diagnosis and treatment planning. Annotated medical images assist healthcare professionals in identifying and analyzing abnormalities, enabling timely and effective interventions.
Autonomous Vehicles
Data annotation is essential for training autonomous vehicles to understand and interact with their environment. Annotated data helps in object recognition, allowing autonomous vehicles to accurately identify pedestrians, traffic signs, and other vehicles. It also contributes to road scene understanding, enabling autonomous vehicles to navigate safely and make informed decisions on the road.
Ecommerce platforms heavily rely on data annotation to enhance user experience and drive sales. Annotated product images and descriptions are used for recommendation systems, providing personalized product suggestions to customers based on their preferences and purchase history.
Sentiment Analysis
Sentiment analysis, which involves determining the sentiment or opinion expressed in customer reviews or social media posts, benefits greatly from data annotation. Annotated customer reviews serve as training data for sentiment classification models, enabling businesses to extract valuable insights and make data-driven decisions to improve their products and services.
Virtual Assistants
Data annotation is instrumental in training virtual assistants to accurately interpret and respond to user commands. Annotated voice recordings are used for speech recognition and natural language understanding, enabling virtual assistants to understand user queries and provide relevant and context-aware responses.
These are just a few examples of how data annotation is applied in machine learning to improve the performance and reliability of models across various domains. The precise and accurate labeling provided by data annotation enables machines to learn and make more informed decisions, ultimately enhancing the overall user experience and driving innovation.

Human vs. Machine in Data Annotation
When it comes to data annotation, there is an ongoing debate about the roles of humans and machines. Both have their advantages and limitations, and finding the right balance is crucial for accurate and meaningful annotations.
Machine automation in data annotation has the potential to streamline the process by leveraging algorithms to label data automatically. This approach is efficient, fast, and scalable, allowing large volumes of data to be annotated quickly.
However, human expertise in data annotation cannot be replaced. Human annotators bring a level of understanding, intuition, and domain-specific knowledge that machines currently lack. They are able to interpret complex contexts, understand nuances, and make subjective decisions that machines find challenging.
Human annotators play a vital role in creating ground truth datasets, ensuring the accuracy and quality of annotations. Their involvement improves the performance and reliability of machine learning models trained on annotated data. With their expertise, human annotators can provide valuable insights, identify edge cases, and handle ambiguous situations that machines struggle with.
"Human annotators bring a deeper understanding of intent, context, and domain-specific knowledge to the annotation process."
Additionally, human involvement can help address biases and inconsistencies in data annotation. By carefully selecting and training human annotators, organizations can ensure a high level of accuracy and reliability in annotations.
Although machine automation offers advantages in terms of speed and scalability , it is essential to strike a balance between human expertise and machine automation in data annotation. By combining the strengths of humans and machines, organizations can maximize the efficiency, accuracy, and effectiveness of the annotation process.
The Benefits of Human Expertise in Annotation
Human expertise in data annotation brings several key benefits:
- Deep understanding of intent and context: Human annotators can interpret complex data, understand subtle nuances, and accurately label data based on the intended meaning.
- Domain-specific knowledge: Human annotators bring domain-specific knowledge and subject matter expertise, enabling them to make informed decisions and handle industry-specific annotation tasks.
- Handling ambiguity and edge cases: Human annotators excel at handling ambiguous situations and edge cases that can arise in data annotation. They can make judgment calls and provide valuable insights.
- Quality control and feedback loop: Human annotators can actively participate in the quality control process by reviewing and providing feedback on automated annotations. This iterative feedback loop helps improve the accuracy and reliability of the annotation process over time.
The Role of Machine Automation in Annotation
Machine automation in data annotation offers several advantages:
- Efficiency and scalability : Machines can annotate large volumes of data quickly and efficiently, enabling organizations to process and label massive datasets with ease.
- Consistency : Machines can provide consistent annotations, reducing human error and ensuring uniformity in labeling.
- Speed: Automated annotation tools can expedite the annotation process, enabling organizations to save time and resources.
- Cost-effectiveness: Machine automation can reduce the cost of annotation by minimizing the need for extensive human labor.
However, it is important to note that machine automation has limitations, particularly in cases that require subjective analysis, contextual understanding, or handling complex semantics. In such cases, human expertise remains crucial.
Incorporating Human and Machine Collaboration
To achieve the best results, organizations should aim for a collaborative approach that leverages the strengths of both humans and machines. This can include:
- Using human annotators to curate high-quality annotated datasets that serve as the ground truth for model training.
- Employing automated tools and algorithms to assist human annotators in the annotation process, speeding up certain tasks and enhancing efficiency.
- Implementing a feedback loop between human annotators and automated systems to continuously improve and refine annotations.
- Regularly reviewing and auditing the annotations to maintain quality and consistency.
By combining the power of human expertise with machine automation, organizations can achieve accurate, reliable, and scalable data annotation, ultimately enhancing the performance and reliability of machine learning models.
Data annotation plays a pivotal role in machine learning, enabling models to learn from labeled examples and make accurate predictions. The importance of annotation in machine learning cannot be overstated, as it provides the necessary ground truth data for training models. Different annotation techniques, such as image annotation, text annotation, video annotation, and audio annotation, are used to train machine learning models in various domains.
The challenges associated with data annotation, including annotation quality , scalability, subjectivity , consistency, and privacy and security , must be addressed to ensure the success of data annotation projects. High-quality annotations are crucial for generating reliable training data and improving the performance and reliability of machine learning models.
By leveraging both human expertise and machine automation, organizations can generate high-quality labeled datasets and develop accurate and reliable machine learning models. Human annotators provide domain-specific knowledge and expertise, ensuring the accuracy and meaning of annotations. At the same time, machine automation can help streamline the annotation process and improve scalability.
As the field of machine learning continues to advance, the importance of data annotation will only grow. The quality and accuracy of annotations directly impact the performance and reliability of machine learning models, making annotation an essential component of the machine learning pipeline.
Whether it's image annotation for object recognition, text annotation for sentiment analysis, video annotation for action recognition , or audio annotation for speaker identification, data annotation plays a crucial role in enabling machines to understand and interpret various types of data.
With the proper implementation of data annotation, organizations can unlock the full potential of machine learning and harness its power to drive innovation and solve complex problems across a wide range of industries.
What is data annotation in machine learning?
Data annotation in machine learning refers to the process of labeling data to provide meaningful information to algorithms. It involves adding annotations or tags to data points to convey valuable information to algorithms easier.
What are the different types of data annotation?
The different types of data annotation include image annotation, text annotation, video annotation, and audio annotation.
What is image annotation?
Image annotation involves labeling objects, regions, or specific features within an image. It helps in training computer vision models to recognize and classify objects accurately.
What is text annotation?
Text annotation involves labeling and categorizing textual data, such as documents, articles, or sentences. It is commonly used in natural language processing tasks like named entity recognition , sentiment analysis, and part-of-speech tagging .
What is video annotation?
Video annotation is the process of labeling objects or actions within video sequences. It enables computer vision models to analyze and understand video content.
What is audio annotation?
Audio annotation encompasses the process of labeling and transcribing audio data. It plays a crucial role in tasks such as speaker identification, speech emotion recognition, and audio transcription.
Why is annotation important in machine learning?
Annotation is important in machine learning because it provides labeled data that serves as the ground truth for training models. Without accurate and properly annotated data, machine learning algorithms would struggle to learn patterns and make meaningful predictions.
What are the key challenges of data annotation?
The key challenges of data annotation include annotation quality , scalability, subjectivity, consistency, and privacy and security .
What are some use cases of data annotation?
Some common use cases of data annotation include medical imaging , autonomous vehicles, ecommerce , sentiment analysis, and virtual assistants.
What is the role of humans vs. machines in data annotation?
While machines have the potential to automate certain aspects of the annotation process, human expertise is crucial for accurate and meaningful annotations. Human annotators bring a deeper understanding of intent, context, and domain-specific knowledge to the annotation process.
Why is data annotation important in machine learning?
Data annotation is important in machine learning as it enables models to learn from labeled examples and make accurate predictions.
Efficient Image Data Annotation Methods
Data annotation vs. data labeling: explained, understanding data labeling techniques.

Data labeling, or data annotation, is part of the preprocessing stage when developing a machine learning (ML) model.
Data labeling requires the identification of raw data (i.e., images, text files, videos), and then the addition of one or more labels to that data to specify its context for the models, allowing the machine learning model to make accurate predictions.
Data labeling underpins different machine learning and deep learning use cases, including computer vision and natural language processing (NLP).
Discover the power of integrating a data lakehouse strategy into your data architecture, including enhancements to scale AI and cost optimization opportunities.
Register for the ebook on generative AI
Companies integrate software, processes and data annotators to clean, structure and label data. This training data becomes the foundation for machine learning models. These labels allow analysts to isolate variables within datasets, and this, in turn, enables the selection of optimal data predictors for ML models. The labels identify the appropriate data vectors to be pulled in for model training, where the model, then, learns to make the best predictions.
Along with machine assistance, data labeling tasks require “ human-in-the-loop (HITL) ” participation. HITL leverages the judgment of human “data labelers” toward creating, training, fine-tuning and testing ML models. They help guide the data labeling process by feeding the models datasets that are most applicable to a given project.
Labeled data vs. unlabeled data
Computers use labeled and unlabeled data to train ML models, but what is the difference ?
- Labeled data is used in supervised learning , whereas unlabeled data is used in unsupervised learning .
- Labeled data is more difficult to acquire and store (i.e. time consuming and expensive), whereas unlabeled data is easier to acquire and store.
- Labeled data can be used to determine actionable insights (e.g. forecasting tasks), whereas unlabeled data is more limited in its usefulness. Unsupervised learning methods can help discover new clusters of data, allowing for new categorizations when labeling.
Computers can also use combined data for semi-supervised learning, which reduces the need for manually labeled data while providing a large annotated dataset.
Data labeling is a critical step in developing a high-performance ML model. Though labeling appears simple, it’s not always easy to implement. As a result, companies must consider multiple factors and methods to determine the best approach to labeling. Since each data labeling method has its pros and cons, a detailed assessment of task complexity, as well as the size, scope and duration of the project is advised.
Here are some paths to labeling your data:
- Internal labeling - Using in-house data science experts simplifies tracking, provides greater accuracy, and increases quality. However, this approach typically requires more time and favors large companies with extensive resources.
- Synthetic labeling - This approach generates new project data from pre-existing datasets, which enhances data quality and time efficiency. However, synthetic labeling requires extensive computing power, which can increase pricing.
- Programmatic labeling - This automated data labeling process uses scripts to reduce time consumption and the need for human annotation. However, the possibility of technical problems requires HITL to remain a part of the quality assurance (QA) process.
- Outsourcing - This can be an optimal choice for high-level temporary projects, but developing and managing a freelance-oriented workflow can also be time-consuming. Though freelancing platforms provide comprehensive candidate information to ease the vetting process, hiring managed data labeling teams provides pre-vetted staff and pre-built data labeling tools.
- Crowdsourcing - This approach is quicker and more cost-effective due to its micro-tasking capability and web-based distribution. However, worker quality, QA, and project management vary across crowdsourcing platforms. One of the most famous examples of crowdsourced data labeling is Recaptcha. This project was two-fold in that it controlled for bots while simultaneously improving data annotation of images. For example, a Recaptcha prompt would ask a user to identify all the photos containing a car to prove that they were human, and then this program could check itself based on the results of other users. The input of from these users provided a database of labels for an array of images.
The general tradeoff of data labeling is that while it can decrease a business’s time to scale, it tends to come at a cost. More accurate data generally improves model predictions, so despite its high cost, the value that it provides is usually well worth the investment. Since data annotation provides more context to datasets, it enhances the performance of exploratory data analysis as well as machine learning (ML) and artificial intelligence (AI) applications. For example, data labeling produces more relevant search results across search engine platforms and better product recommendations on e-commerce platforms. Let’s delve deeper into other key benefits and challenges:
Data labeling provides users, teams and companies with greater context, quality and usability. More specifically, you can expect:
- More Precise Predictions: Accurate data labeling ensures better quality assurance within machine learning algorithms, allowing the model to train and yield the expected output. Otherwise, as the old saying goes, “garbage in, garbage out.” Properly labeled data provide the “ ground truth ” (i.e., how labels reflect “real world” scenarios) for testing and iterating subsequent models.
- Better Data Usability: Data labeling can also improve usability of data variables within a model. For example, you might reclassify a categorical variable as a binary variable to make it more consumable for a model. Aggregating data in this way can optimize the model by reducing the number of model variables or enable the inclusion of control variables. Whether you’re using data to build computer vision models (i.e. putting bounding boxes around objects) or NLP models (i.e. classifying text for social sentiment), utilizing high-quality data is a top priority.
Challenges
Data labeling is not without its challenges. In particular, some of the most common challenges are:
- Expensive and time-consuming: While data labeling is critical for machine learning models, it can be costly from both a resource and time perspective. If a business takes a more automated approach, engineering teams will still need to set up data pipelines prior to data processing, and manual labeling will almost always be expensive and time-consuming.
- Prone to Human-Error: These labeling approaches are also subject to human-error (e.g. coding errors, manual entry errors), which can decrease the quality of data. This, in turn, leads to inaccurate data processing and modeling. Quality assurance checks are essential to maintaining data quality.
No matter the approach, the following best practices optimize data labeling accuracy and efficiency:
- Intuitive and streamlined task interfaces minimize cognitive load and context switching for human labelers.
- Consensus: Measures the rate of agreement between multiple labelers(human or machine). A consensus score is calculated by dividing the sum of agreeing labels by the total number of labels per asset.
- Label auditing: Verifies the accuracy of labels and updates them as needed.
- Transfer learning: Takes one or more pre-trained models from one dataset and applies them to another. This can include multi-task learning, in which multiple tasks are learned in tandem.
- Membership query synthesis - Generates a synthetic instance and requests a label for it.
- Pool-based sampling - Ranks all unlabeled instances according to informativeness measurement and selects the best queries to annotate.
- Stream-based selective sampling - Selects unlabeled instances one by one, and labels or ignores them depending on their informativeness or uncertainty.
Though data labeling can enhance accuracy, quality and usability in multiple contexts across industries, its more prominent use cases include:
- Computer vision: A field of AI that uses training data to build a computer vision model that enables image segmentation and category automation, identifies key points in an image and detects the location of objects. In fact, IBM offers a computer vision platform, Maximo Visual Inspection , that enables subject matter experts (SMEs) to label and train deep learning vision models that can be deployed in the cloud, edge devices, and local data centers. Computer vision is used in multiple industries - from energy and utilities to manufacturing and automotive. By 2022, this surging field is expected to reach a market value of USD 48.6 billion.
- Natural language processing (NLP): A branch of AI that combines computational linguistics with statistical, machine learning, and deep learning models to identify and tag important sections of text that generate training data for sentiment analysis, entity name recognition and optical character recognition. NLP is increasingly being used in enterprise solutions like spam detection, machine translation, speech recognition , text summarization, virtual assistants and chatbots, and voice-operated GPS systems. This has made NLP a critical component in the evolution of mission-critical business processes.
The natural language processing (NLP) service for advanced text analytics.
Enable AI workloads and consolidate primary and secondary big data storage with industry-leading, on-premises object storage.
See, predict and prevent issues with advanced AI-powered remote monitoring and computer vision for assets and operations.
Scale AI workloads for all your data, anywhere, with IBM watsonx.data, a fit-for-purpose data store built on an open data lakehouse architecture.

How to Resist the Temptation of AI When Writing

Salesforce’s BLIP Image Captioning: Create Captions from Images

Researchers create “The Consensus Game” to elevate AI’s text comprehension and generation skills

‘Tinder’s Most Swiped Man’, 33, breaks his silence on THAT date with ‘amazing’ Vanessa Feltz, 62… as he reveals they ‘shared a bottle of Sauvignon Blanc’ and she ‘loved his pheromones’ on intimate night out

Here’s Proof the AI Boom Is Real: More People Are Tapping ChatGPT at Work
- Applications
- Machine Learning
What is Data Annotation? Definition, Tools, Types and More
Introduction
Data annotation plays a crucial role in the field of machine learning, enabling the development of accurate and reliable models. In this article, we will explore the various aspects of data annotation, including its importance, types, tools, and techniques. We will also delve into the different career opportunities available in this field, the industry applications, job market trends, and the salaries associated with data annotation.
Let’s get started!
What is Data Annotation?
Data annotation involves the process of labeling or tagging data to make it understandable for machines. It provides the necessary context and information for machine learning algorithms to learn and make accurate predictions. By annotating data, we enable machines to recognize patterns, objects, and sentiments, thereby enhancing their ability to perform complex tasks.
What is the Importance of Data Annotation in Machine Learning?
Data annotation is a critical component in machine learning as it serves as the foundation for training models. Without properly annotated data, machine learning algorithms would struggle to understand and interpret the input. Accurate and comprehensive data annotation ensures that models can make informed decisions and predictions, leading to improved performance and reliability.
Become an AI/ML expert today with our BlackBelt Plus Program!
Types of Data Annotation
Data annotation can be performed using various tools and techniques, depending on the complexity and requirements of the task at hand.
What is the Process?
Time needed: 5 minutes
The data annotation process involves several stages to ensure the quality and reliability of the annotated data.
Data collection involves gathering relevant data from various sources, such as images, text documents, videos, or audio recordings. The quality and diversity of the collected data directly impact the performance of the trained models.
Annotation guidelines provide instructions and standards for annotators to follow. They define the labeling criteria, annotation formats, and any specific guidelines for handling ambiguous cases.
Annotation quality control involves reviewing and validating the annotated data to ensure accuracy and consistency. It may include inter-annotator agreement checks, regular feedback sessions, and continuous monitoring of annotation quality.
The iterative annotation process involves refining and improving the annotations based on feedback and model performance. It allows for continuous learning and adaptation to enhance the quality of the annotated data.
Also Read: Starters Guide to Sentiment Analysis using Natural Language Processing
Tips to Improve Data Annotation
- Clear Annotation Guidelines : Well-defined guidelines ensure annotators have a precise understanding of the task, promoting consistency and accuracy in annotations.
- Multiple Annotators and Quality Control: Using multiple annotators and implementing quality control processes helps identify and resolve discrepancies, ensuring dataset reliability.
- Iterative Annotation Process: An iterative approach allows annotators to learn from feedback, enhancing performance and adapting to evolving requirements over time.
- Consistent Annotation Tools: Standardizing annotation tools maintains uniformity and facilitates collaboration, while features for version control enhance dataset management.
- Consideration of Ambiguity: Addressing ambiguous cases in guidelines and providing a mechanism for clarification ensures consistent handling of challenging instances.
- Inter-annotator Agreement: Measuring inter-annotator agreement assesses consistency among annotators, enabling resolution of discrepancies through discussions or third-party involvement.
- Annotator Training: Providing training sessions familiarizes annotators with guidelines and the task, contributing to improved annotation quality.
- Data Privacy and Security Measures: Implementing measures to protect sensitive information during annotation upholds data privacy guidelines.
- Regular Validation of Annotations: Periodic validation of annotated data ensures ongoing quality, with validation metrics quantifying the performance of the annotation process.
- Project Management and Scalability Planning: Effective project management practices, coupled with scalability planning, facilitate efficient resource allocation and timely completion of annotation tasks.
Careers and Roles
Data annotation offers various career opportunities, each with its own set of responsibilities and requirements.
- Data Annotator : A data annotator is responsible for accurately labeling and annotating data according to the given guidelines. They play a crucial role in ensuring the quality and reliability of the annotated data.
- Annotation Team Lead: An annotation team lead oversees a team of annotators, providing guidance, training, and support. They ensure that the annotation process is efficient, consistent, and meets the required standards.
- Annotation Project Manager: An annotation project manager is responsible for managing the entire annotation project, including planning, resource allocation, and coordination. They ensure the timely delivery of high-quality annotated data within the specified budget and timeline.
- Annotation Quality Control Specialist: An annotation quality control specialist is responsible for monitoring and maintaining the quality of the annotated data. They conduct regular checks, provide feedback to annotators, and implement quality improvement measures.
Opportunities across Industries
Data annotation offers a wide range of opportunities across various industries and job markets.
- Industry Applications: Data annotation finds applications in industries such as healthcare, autonomous vehicles, e-commerce, agriculture, and finance. It enables the development of innovative solutions and technologies that rely on machine learning.
- Job Market Trends: The demand for data annotators and roles is on the rise, driven by the increasing adoption of machine learning and AI technologies. Job opportunities are available in both established companies and startups, offering diverse and rewarding career paths.
- Freelancing and Remote Work: Data annotation also provides opportunities for freelancers and remote workers. Many companies outsource their annotation tasks to independent contractors, allowing individuals to work from anywhere and have flexible working hours.
Salary Breakup
According to Glassdoor, the projected annual compensation for a Data Annotation position in the United States is approximately $64,010, with an average salary of $60,547. These figures are derived from our proprietary Total Pay Estimate model, utilizing median values based on salary data collected from our user community.
Additional pay, amounting to an estimated $3,463 per year, may encompass cash bonuses, commissions, tips, and profit sharing. The “Most Likely Range” signifies values within the 25th and 75th percentiles of all available pay data for this role.
Factors such as experience, expertise, location, and the complexity of the annotation task can influence the salary of data annotators. Those with specialized skills or domain knowledge may command higher salaries.
Data annotation plays a vital role in machine learning, enabling the development of accurate and reliable models. It offers diverse career opportunities, industry applications, and growth potential. As the field continues to evolve, addressing challenges and embracing future advancements will be crucial for the success of data annotation. So, whether you are considering a career in data annotation or exploring its potential in your industry, understanding its scope, opportunities, and salaries is essential.
Want to learn more about machine learning concepts? Enroll in our Blackbelt Plus program and become an AI/ML expert!
Frequently Asked Questions
A. It involves labeling or tagging data, such as images or text, to train machine learning models. It’s a crucial process for creating labeled datasets used in various AI applications.
A. Yes, Data Annotation Specialists earn a competitive salary. According to ZipRecruiter (as of December 2023), the average annual salary for this role in the United States is $72,947, aligning with the national average (source).
A. The hourly rate for data annotation varies but is often competitive. Rates depend on factors like expertise, project complexity, and geographic location, with averages ranging from $15 to $30.
A. Data annotation is the process of labeling or tagging data to train machine learning models. It involves adding metadata to datasets, enabling algorithms to learn patterns and make accurate predictions in tasks like image recognition or natural language processing.
By Analytics Vidhya , December 27, 2023.
Sign Up For Daily Newsletter
Be keep up get the latest breaking news delivered straight to your inbox..

Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Latest News

Vanessa Feltz, 62, is teased by This Morning co-stars as she hints at romantic weekend away after enjoying outing with ‘Mr Tinder’, 33

SVM One-Class Classifier For Anomaly Detection

Sign in to your account
Username or Email Address
Remember Me

What is Data Annotation in Machine Learning?
In today’s increasingly world, the need for accurate and reliable data annotation has never been greater. From self-driving cars to virtual assistants, machine learning models rely on annotated data to function effectively. Without proper annotation, even the most advanced algorithms would struggle to make sense of the vast amounts of unstructured data available. Data annotation plays a crucial role in machine learning, enabling computers to understand and process vast amounts of information.
What is Data Annotation?
In simple terms, data annotation involves labeling data to make it intelligible for machines. By annotating data, we provide context and meaning to raw information, allowing machine learning algorithms to recognize patterns, make predictions, and perform complex tasks. Computers lack the inherent ability to process and comprehend visual information as humans do.
Therefore, data annotation serves as the bridge between the raw data and the AI algorithms, enabling machines to make informed predictions and decisions. By assigning labels, tags, or metadata to specific elements within the dataset, it provides the necessary context for machines to learn and analyze patterns.
Importance of data annotation in machine learning
The process of data annotation is vital for training machine learning models. By labeling data with relevant tags, categories, or attributes, we create a ground truth dataset that serves as the basis for teaching algorithms how to interpret new, unseen data. This labeled data allows machine learning models to learn from examples and generalize their knowledge to make accurate predictions or classifications.
Accurate data annotation is crucial for ensuring the performance and reliability of machine learning models. The quality of the annotated data directly affects the model’s ability to learn, adapt, and make informed decisions. Without accurate annotations, models may produce inaccurate or biased results, leading to serious consequences in real-world applications.
Types of data annotation techniques
There are various techniques used for data annotation, each suited for different types of machine-learning tasks. Some common types of data annotation techniques include:
- Image Annotation: In image annotation, objects or regions of interest within an image are identified and labeled. This technique is commonly used in computer vision tasks such as object detection, image segmentation, and facial recognition .
- Text Annotation: Text annotation involves labeling textual data, such as documents, sentences, or words, with relevant tags or categories. This technique is widely used in natural language processing tasks, including sentiment analysis, named entity recognition, and text classification.
- Audio Annotation: Audio annotation involves transcribing and labeling audio data, such as speech or sound events. This technique is essential for speech recognition, audio classification, and sound event detection applications.
- Video Annotation: Video annotation involves labeling objects, actions, or events within video sequences. This technique is crucial for video analysis tasks, such as action recognition, object tracking, and surveillance systems.
Choosing the appropriate data annotation technique depends on the specific requirements of the machine learning task at hand.
Common challenges in data annotation
While data annotation is a crucial step in machine learning, it is not without its challenges. Some common challenges in data annotation include:
- Subjectivity: Data annotation can be subjective, as different annotators may interpret and label data differently. This subjectivity can introduce inconsistencies and affect the overall quality of the annotated data.
- Scale: Annotating large datasets can be time-consuming and resource-intensive. As the volume of data increases, the annotation process becomes more complex and requires efficient tools and methodologies to ensure accuracy and efficiency.
- Labeling Ambiguity: Some data may be inherently ambiguous or require domain-specific knowledge to label accurately. Annotators must possess the necessary expertise and context to interpret and label such data correctly.
Addressing these challenges requires a combination of expertise, efficient annotation tools, and well-defined annotation guidelines to ensure consistent and accurate annotations.
How to become a data annotator ?
Becoming a data annotator requires a combination of domain knowledge, attention to detail, and proficiency in annotation tools. Here are some steps to become a data annotator:
- Develop domain expertise: Gain knowledge and understanding in the domain you wish to annotate data for. This could be in fields such as computer vision, natural language processing, or audio processing.
- Familiarize yourself with annotation tools: Learn to use popular annotation tools and software, such as Labelbox or Supervisory. Practice using these tools to annotate sample datasets and familiarize yourself with their features and functionalities.
- Stay updated: Keep up with the latest trends and developments in the field of data annotation and machine learning. Attend conferences, read research papers, and participate in online communities to stay informed about new techniques and best practices.
- Build a portfolio: Create a portfolio of annotated datasets that showcase your skills and expertise. This will help you demonstrate your capabilities to potential clients or employers.
- Seek opportunities: Look for freelance or job opportunities in data annotation. Online platforms and marketplaces like Upwork or Kaggle often have projects available for data annotators.
By following these steps, you can establish yourself as a skilled data annotator and contribute to the development of machine learning models.
Best practices for data annotation
To ensure accurate and reliable annotations, it is essential to follow best practices in data annotation. Here are some key guidelines to consider:
- Annotation guidelines: Develop clear and concise annotation guidelines that define the criteria for labeling data. These guidelines should be comprehensive, and unambiguous, and provide examples to ensure consistency among annotators.
- Quality control: Implement quality control measures to evaluate the accuracy and consistency of annotations. This can involve regular reviews, inter-annotator agreement checks, or using gold-standard datasets for benchmarking.
- Iterative process: It is an iterative process, and annotations may need refinement over time. Encourage feedback and collaboration among annotators to improve the quality of annotations.
- Data augmentation: Consider using data augmentation techniques to increase the diversity and variability of annotated data. This can improve the model’s ability to generalize and perform well on unseen data.
By following these best practices, data annotation can be performed efficiently and consistently, leading to high-quality annotated datasets .
Case studies showcasing the impact of accurate data annotation
Accurate data annotation has a significant impact on the performance and reliability of machine learning models. Here are two case studies that highlight its importance:
1. Autonomous Driving: In the field of autonomous driving, accurate data annotation is crucial for training models to recognize and respond to various objects and scenarios on the road. Through accurate annotation of millions of images and video frames, machine learning models can learn to identify pedestrians, vehicles, traffic signs, and other critical elements, enabling safe and efficient autonomous driving.
2. Medical Diagnosis: In medical diagnosis, accuracy is essential for training models to detect and classify diseases from medical images or patient records. By annotating large datasets of medical images with precise labels, machine learning models can assist doctors in diagnosing conditions such as cancer, cardiovascular diseases, or neurological disorders, leading to early detection and better patient outcomes.
These case studies demonstrate the transformative impact of accurate data annotation in real-world applications, making it an integral part of the machine-learning pipeline.
Outsourcing data annotation services
For organizations looking to leverage the benefits of data annotation without the resources or expertise to perform annotation in-house, outsourcing data annotation services can be a viable option. Outsourcing allows businesses to access a global pool of skilled annotators, scale annotation efforts, and benefit from specialized tools and expertise.
When considering outsourcing data annotation services, it is essential to ensure data privacy and confidentiality, establish clear communication channels, and define quality control measures to maintain the accuracy and consistency of annotations.
As machine learning continues to advance and find applications in various industries, the importance of data annotation will only grow. Accurate and reliable annotated data is the foundation on which machine learning models are built, enabling them to understand and interpret complex information.
The future of this lies in the development of more sophisticated annotation techniques and tools that can handle diverse data types and improve efficiency. Additionally, advancements in artificial intelligence and automation may further streamline the annotation process, reducing the time and effort required.
By understanding its significance, we can unlock the full potential of machine learning and drive innovation in various domains. With accurate annotations, we can create intelligent systems that revolutionize industries, improve decision-making, and enhance our daily lives.
If you’re interested in learning more about data annotation or need custom data annotation services, get in touch with our team today.
Harness Twine’s established global community of over 400,000 freelancers from 190+ countries to scale your dataset collection quickly. We have systems to record, annotate and verify custom video datasets at an order of magnitude lower cost than existing methods.
You may also like

Best Data Collection Companies for AI
In an era dominated by artificial intelligence (AI), the demand for specialised data collection companies has escalated. The quality and quantity of data you feed your models directly influence their performance. While web scraping might seem like a...

Best Datasets for Semantic Segmentation Models in 2024
Let me tell you, when I first stumbled upon the world of semantic segmentation, I was blown away. It felt like a superpower – the ability to teach computers to not only see but truly understand what's in an image. Pixel superpowers? Yes, please! But...
13+ Image Classification Datasets for Machine Learning
Image classification, the cornerstone of computer vision, unlocks a world of possibilities. Imagine AI systems that diagnose diseases from medical scans, robots navigating environments seamlessly, or self-driving cars recognising traffic signs...
Need AI training data?
Twine AI can help with data collection , data annotation , off-the-shelf audio datasets , video datasets , and more.
Or if you would like to speak to the Twine AI team:
Recent Posts

The 10 Best Alternatives to Upwork

IR35 Advice and Compliance: What Every Contractor Needs to Know

Securing Your Freelance Finances – The Intouch Path to Stability and Growth
- Hire a Freelancer
: Uncaught Error: Call to undefined function Smush\Core\Parser\str_starts_with() in /var/www/html/wordpress/wp-content/plugins/wp-smush-pro/core/parser/class-image-url.php:119 Stack trace: #0 /var/www/html/wordpress/wp-content/plugins/wp-smush-pro/core/parser/class-image-url.php(98): Smush\Core\Parser\Image_URL->is_scheme_missing_from_original() #1 /var/www/html/wordpress/wp-content/plugins/wp-smush-pro/core/parser/class-image-url.php(91): Smush\Core\Parser\Image_URL->prepare_absolute_url() #2 /var/www/html/wordpress/wp-content/plugins/wp-smush-pro/core/lazy-load/class-lazy-load-transform.php(352): Smush\Core\Parser\Image_URL->get_absolute_url() #3 /var/www/html/wordpress/wp-content/plugins/wp-smush-pro/core/lazy-load/class-lazy-load-transform.php(312): Smush\Core\Lazy_Load\Lazy_Load_Transform->maybe_lazy_load_image_element() #4 /var/www/html/wordpress/wp-content/plugins/wp-smush-pro/core/lazy-load/class-lazy-load-transform.php(304): Smush\Core\Lazy_Load\Lazy_Load_Transform->transform_image_element() #5 /var/ww in /var/www/html/wordpress/wp-content/plugins/wp-smush-pro/core/parser/class-image-url.php on line 119
Data Labeling
- Accelerated Annotation AI-powered labeling technology for 2-D images and video integrated with expert annotators and optimized processes
- Workforce Plus Our Managed Workforce bundled with tooling for video, LiDAR, and more
- Managed Workforce Workforce services for Vision AI use cases
- Human-in-the-Loop Automation
- Managed Workforce Support workflows and fill gaps in AI and automation
- Aerial and Geospatial
- Autonomous Vehicles
- Explore All Use Cases
Popular Guides
- Data Labeling Guide Mastering data labeling for ML in 2024: A comprehensive guide
- Computer Vision Guide Vision AI Applications, Data Quality, and Your Workforce
- NLP Guide Natural Language Processing Techniques, Workforces, and Use Cases
- Data Processing Guide Outsourcing Data Cleansing, Transcription, and Enrichment at Scale
Key Resources
- Explore All Resources
Company Info
- Leadership Team
- Partnerships
- Certifications and Compliance
- Privacy Policy
- Data Security
Data Annotation Tools for Machine Learning (Evolving Guide)
Choosing the Best Data Annotation Tool for Your Project
The data annotation tools you use to enrich your data for training and deploying machine learning models can determine success or failure for your AI project. Your tools play an important role in whether you can create a high-performing model that powers a disruptive solution or solves a painful, expensive problem - or end up investing time and resources on a failed experiment.
Choosing your tool may not be a fast or easy decision. The data annotation tool ecosystem is changing quickly as more providers offer options for an increasingly diverse array of use cases. Tooling advancements happen by the month, sometimes by the week. These changes bring improvements to existing tools and new tools for emerging use cases.
The challenge is thinking strategically about your tooling needs now and into the future. New tools, more advanced features, and changes in options, such as storage and security, make your tooling choices more complex. And, an increasingly competitive marketplace makes it challenging to discern hype from real value.
We’ve called this an evolving guide because we will update it regularly to reflect changes in the data annotation tool ecosystem. So be sure to check back regularly for new information, and you can bookmark this page.

Read the full guide below, or download a PDF version of the guide you can reference later.
In this guide, we’ll cover data annotation tools for computer vision and NLP (natural language processing) for supervised learning .
First, we’ll explain the idea of data annotation tools in more detail, introducing you to key terms and concepts. Next, we will explore the pros and cons of building your own tool versus purchasing a commercially available tool or leveraging open source options.
We’ll give you considerations for choosing your tool and share our short list of the best data annotation tools available. You’ll also get a short list of critical questions to ask your tool provider.
Table of Contents
Introduction: will this guide be helpful to me, the basics: data annotation tools and machine learning, a critical choice: build vs. buy, how to choose a data annotation tool, the best data annotation tools: commercial and open source, iteration & evolution: changing data annotation needs, new tools, questions to ask your data annotation tool provider, tool agnostic: the cloudfactory advantage.
- Introduction
- Build vs. Buy
- How to Choose
- Best Data Annotation Tools
- Iteration & Evolution
- Questions to Ask
- CloudFactory Advantage
This guide will be helpful if :
- You are beginning a machine learning project and have data you want to clean and annotate to train, test, and validate your model.
- You are working with a new data type and need to understand the best tools available for annotating that data.
- Your data annotation needs have evolved (e.g., you need to add features to your annotation) and want to learn about tools that can handle what you’re doing today and what you’re adding to your process.
- You are in the production stage and must verify models using human-in-the-loop .
What’s data annotation?
In machine learning, data annotation is the process of labeling data to show the outcome you want your machine learning model to predict. You are marking - labeling, tagging, transcribing, or processing - a dataset with the features you want your machine learning system to learn to recognize. Once your model is deployed, you want it to recognize those features on its own and make a decision or take some action as a result.
Annotated data reveals features that will train your algorithms to identify the same features in data that has not been annotated. Data annotation is used in supervised learning and hybrid, or semi-supervised, machine learning models that involve supervised learning.
What’s a data annotation tool?
A data annotation tool is a cloud-based, on-premise, or containerized software solution that can be used to annotate production-grade training data for machine learning. While some organizations take a do-it-yourself approach and build their own tools, there are many data annotation tools available via open source or freeware.
They are also offered commercially, for lease and purchase. Data annotation tools are generally designed to be used with specific types of data, such as image, video, text, audio, spreadsheet, or sensor data. They also offer different deployment models, including on-premise, container, SaaS (cloud), and Kubernetes.

6 Important Data Annotation Tool Features
1) dataset management.
Annotation begins and ends with a comprehensive way of managing the dataset you plan to annotate. As a critical part of your workflow, you need to ensure that the tool you are considering will actually import and support the high volume of data and file types you need to label. This includes searching, filtering, sorting, cloning, and merging of datasets.
Different tools can save the output of annotations in different ways, so you’ll need to make sure the tool will meet your team’s output requirements. Finally, your annotated data must be stored somewhere. Most tools will support local and network storage, but cloud storage - especially your preferred cloud vendor - can be hit or miss, so confirm support-file storage targets.
2) Annotation methods
This is obviously the core feature of data annotation tools - the methods and capabilities to apply labels to your data. But not all tools are created equal in this regard. Many tools are narrowly optimized to focus on specific types of labeling, while others offer a broad mix of tools to enable various types of use cases.
Nearly all offer some type of data or document classification to guide how you identify and sort your data. Depending on your current and anticipated future needs, you may wish to focus on specialists or go with a more general platform. The common types of annotation capabilities provided by data annotation tools include building and managing ontologies or guidelines, such as label maps, classes, attributes, and specific annotation types.
Here are just a few examples:
- Image or video: Bounding boxes, polygons, polylines, classification, 2-D and 3-D points, or segmentation (semantic or instance), tracking, transcription, interpolation, or transcription.
- Text: Transcription, sentiment analysis, net entity relationships (NER), parts of speech (POS), dependency resolution, or coreference resolution.
- Audio: Audio labeling, audio to text, tagging, time labeling
An emerging feature in many data annotation tools is automation, or auto-labeling . Using AI, many tools will assist your human labelers to improve their annotations (e.g. automatically convert a four-point bounding box to a polygon), or even automatically annotate your data without a human touch. Additionally, some tools can learn from the actions taken by your human annotators, to improve auto-labeling accuracy.
Some annotation tasks are ripe for automation. For example, if you use pre-annotation to tag images, a team of data labelers can determine whether to resize or delete a bounding box. This can shave time off the process for a team that needs images annotated at pixel-level segmentation. Still, there will always be exceptions, edge cases, and errors with automated annotations, so it is critical to include a human-in-the-loop approach for both quality control and exception handling.
Automation also can refer to the availability of developer interfaces to run the automations. That is, an application programming interface (API) and software development kit (SDK) that allow access to and interaction with the data.
3) Data quality control
The performance of your machine learning and AI models will only be as good as your data. Data annotation tools can help manage the quality control (QC) and verification process. Ideally, the tool will have embedded QC within the annotation process itself.
For example, real-time feedback and initiating issue tracking during annotation is important. Additionally, workflow processes such as labeling consensus, may be supported. Many tools will provide a quality dashboard to help managers view and track quality issues, and assign QC tasks back out to the core annotation team or to a specialized QC team.
4) Workforce management
Every data annotation tool is meant to be used by a human workforce - even those tools that may lead with an AI-based automation feature. You still need humans to handle exceptions and quality assurance as noted before. As such, leading tools will offer workforce management capabilities, such as task assignment and productivity analytics measuring time spent on each task or sub-task.
Your data labeling workforce provider may bring their own technology to analyze data that is associated with quality work. They may use technology, such as webcams, screenshots, inactivity timers, and clickstream data to identify how they can support workers in delivering quality data annotation.
Most importantly, your workforce must be able to work with and learn the tool you plan to use. Further, your workforce provider should be able to monitor worker performance and work quality and accuracy . It’s even better when they offer you direct visibility, such as a dashboard view, into the productivity of your outsourced workforce and the quality of the work performed.
5) Security
Whether annotating sensitive protected personal information (PPI) or your own valuable intellectual property (IP), you want to make sure that your data remains secure. Tools should limit an annotator’s viewing rights to data not assigned to her, and prevent data downloads. Depending on how the tool is deployed, via cloud or on-premise, a data annotation tool may offer secure file access (e.g., VPN).
For use cases that fall under regulatory compliance requirements, many tools will also log a record of annotation details, such as date, time, and the annotation author. However, if you are subject to HIPAA, SOC 1, SOC 2, PCI DSS, or SSAE 16 regulations, it is important to carefully evaluate whether your data annotation tool partner can help you maintain compliance.
6) Integrated labeling services
As mentioned earlier, every tool requires a human workforce to annotate data, and the people and technology elements of data annotation are equally important. As such, many data annotation tool providers offer a workforce network to provide annotation as a service. The tool provider either recruits the workers or provides access to them via partnerships with workforce providers.
While this feature makes for convenience, any workforce skill and capability should be evaluated separately from the tool capability itself. The key here is that any data annotation tool should offer the flexibility to use the tool vendor’s workforce or the workforce of your choice, such as a group of employees or a skilled, professionally managed data annotation team.

Download the PDF version here
Just a few years ago, there weren’t many data annotation tools available to buy. Most early movers had to use what was available via open source or build their own tools if they wanted to apply AI to solve a painful business problem or create a disruptive product.
Starting in about 2018, a wave of commercial data annotation tools became available, offering full-featured, complete-workflow commercial tools for data labeling. The emergence of these third-party, professionally developed tools began to force a discussion within data science and AI project teams around whether to continue to take a DIY approach and build their own tools or purchase one. And if the answer was to purchase a data annotation tool, they still needed to decide how to select the right tool for their project.
When to build your own data annotation tool
Even though there are third-party tools available to purchase, it may still make business sense to build a data annotation tool. Building your own tool provides you with the ultimate level of control - from the end-to-end workflow of the annotation process, to the type of data you can label and the resulting outputs.
And, as you continue to iterate your business processes and your machine learning models, you can make changes quickly, using your own developers and setting your own priorities. You also can apply technical controls to meet your company’s unique security requirements. And finally, an organization may want to include all of their AI tooling in their intellectual property, and building a data annotation tool internally allows them to do that.
However, when you’re building a tool, you often face many unknowns at the beginning, and the scope of tool requirements can quickly shift and evolve, causing teams to lose time. There is also the additional overhead of standing up the infrastructure needed to develop and run the tooling, as well as development resources required to maintain the data annotation tool.
When to buy a data annotation tool
Generally, buying a tool that is commercially available can be less expensive because you avoid the upfront development and ongoing direct support expenses. This allows you to focus your time and resources on your core project:
- Without the distraction of supporting and expanding features and capabilities for an in-house tool that is custom-built; and
- Without bearing the ongoing burden of funding the tool to ensure its continued success.
Buying an existing data annotation tool can accelerate your project timeline, enabling you to get started more quickly with an enterprise-ready, tested data labeling tool. Additionally, tooling vendors work with many different customers and can incorporate industry best practices into their data annotation tools. Finally, when it comes to features, you can usually configure a commercial tool to meet your needs, and there are more than one of these kinds of tools available for any data annotation workload.
Of course, a third-party data annotation tool is not typically built with your specific use case or workflow in mind, so you may sacrifice some level of control and customization. And as your project or product evolves, you may find that your data annotation tool requirements change over time. If the tool you originally bought doesn’t support your new requirements, you will need to build or buy integrations or separate tools to meet your new needs.
The open source option for data annotation tools
There are open source data annotation tools available. You can use an open source tool and support it yourself, or use it to jump-start your own build effort. There are many open source projects for tooling related to image, video, natural language processing, and transcription, and such a tool can be a great option for a one-time project.
But often an open source tool will present challenges when you try to scale your project into production, as these tools are typically designed around a single user and offer poor or insufficient workflow options for a team of data labelers. Additionally, you need to have the technical expertise on hand to deploy and maintain the tool. Many people are lured by open source being “free” and forget to factor in the total cost of ownership - the time and expense required to develop the workflows, workforce management, and quality assurance management that are necessary and inherently present in commercial data annotation tools.
Growth stage as an indicator for buy vs. build
Another helpful way to look at the build versus buy question is to consider your stage of organizational growth.
- Start: In the early stages of growth, freeware or open source data annotation tools can make sense if you have development resources and you want to build your own tool. You also could choose a workforce that provides a data annotation tool. But be careful not to unnecessarily tie your data annotation tool to your workforce; you’ll want the flexibility to make changes later.
- Scale: If you’re at the growth stage, you might want the ability to customize commercial data annotation tools, and you can do that with little to no development resources. If you build, you’re going to need to allocate resources to maintain and improve your tool. Keep in mind to consider existing storage and, if you use a cloud vendor, make sure they can work with your requirements.
- Sustain: When you’re operating at scale, it’s likely to be important for you to have control, enhanced data security, or the agility to make changes, such as feature enhancements. In that case, open source tools that are self-built and managed might be your best bet.

There is a lot to consider in the build vs buy equation. If, after considering all of the factors, you conclude that the time and expense is not worth a DIY approach and the potential gain of customization and retaining IP, then the next decision you will need to make is about which commercial tool you choose to purchase. In this section we will explore some of those considerations.
1) What is your use case?
First and foremost, the type of data you want to annotate and your business processes for doing the work will influence your tool choice. There are tools for labeling text, image, and video. Some image labeling tools also have video labeling capabilities.
Of note, more and more data annotation tool providers are realizing they want to do more than provide a singular tool - they want to provide a holistic technology platform for data annotation for machine learning. A simple data annotation tool provides features that make it easy to enrich the data. A platform provides an environment that supports the data annotation and AI development process.
A platform may include features such as multiple annotation options (e.g., 2-D, 3-D, audio, text), more than one storage option (e.g., local, network, cloud), or quality control workflow. It also may be able to accept pre-annotated data or may include embedded neural networks that learn from manual annotations made using the platform. Considering a platform may be helpful if you anticipate your project or product needs evolving significantly over time, as a platform may provide greater flexibility in the future.
2) How will you manage quality control requirements?
How you want to measure and control quality is also an important consideration for your data annotation tool. Many commercially-available tools have quality control (QC) features built-in that can review, provide feedback, and correct tasks. For example, QC options might include:
- Consensus - Annotator agreement determines quality. For example, when annotators disagree on an edge case, the task is passed to a third annotator or more until a percentage of certainty is reached. Feedback can be provided to the workforce to learn how to correctly annotate those edge cases.
- Gold standard - The correct answer is known. The tool measures quality based on correct and incorrect tasks.
- Sample review - The tools reviews a random sample of completed tasks for accuracy.
- Intersection over union (IoU) - This is a consensus model used in object detection within images. It compares your hand-annotated, ground-truth images with the annotations your model predicts.
Some tools can even automate a portion of your QC. However, whenever you are using automation for a portion of your data labeling process, you will need people to perform QC on that work. For example, optical character recognition (OCR) software has an error rate of 1% to 3% per character. On a page with 1,800 characters, that’s 18-54 errors. For a 300-page book, that’s 5,400-16,200 errors. You will want a process that includes a QC layer performed by skilled labelers with context and domain expertise.
3) Who will be using the tool?
An often overlooked aspect of tool selection is workforce. Whether your data is annotated by employees or contractors, crowdsourcing, or an outsourcing provider, your workforce will need access to and training to use your data annotation tool, with specific task instructions unique to your use case. Make sure you take into account the answers to these questions:
- Do you have access to a workforce that has pre-existing knowledge of viable commercial tools for your project?
- Does that team have prior experience using the tool(s) you are considering?
- If not, do you have detailed documentation and a proven training approach to bring the workforce up to speed?
- Do you have a process by which you can ensure the required level of quality for your project?
4) Do you need a vendor or a partner?
The company you buy a data annotation tool from can be just as important as the tool itself. Here, you’ll want to consider how easy it is to do business with the company that’s providing the tool and their openness for collaboration. AI development is an iterative process, and you will need to make changes along the way. Are they willing to consider feedback or ideas for new features for their tool that would make your tasks easier or make your AI models run cleaner and with better results? Aim to find a partner who is willing to work with you on such things, not simply a vendor to provide a tool.
As you research your workforce options, you may discover some data labeling services that provide their own tool. However, be careful not to tie your tool to your workforce unnecessarily. You’ll want the flexibility to change either your workforce or your tool, based on your business needs and the solutions available to you, especially as new tools and workforce options emerge. A data labeling service should be able to provide best practices and share recommendations for choosing your tool based on their workforce strategy.
Also, keep in mind that your annotation tasks are likely to change over time. Every machine learning modeling task is different. The set of instructions you are using to collect, clean, and annotate your data today may change in the coming weeks - even days. Anticipating those changes is helpful, and you’ll want to consider that when you’re making the decision about the data annotation tool you select and the workforce that will use it to label your data.
Here’s a closer look at some of the data annotation tools we consider to be among the best available on the market today.
Commercial Data Annotation Tools
Commercially-viable data annotation tools are likely your best choice, particularly if your company is at the growth or enterprise stage. If you are operating at scale and want to sustain that growth over time, you can get commercially-available tools and customize them with few development resources of your own.
Open Source Data Annotation Tools
Open source data annotation tools allow you to use or modify the source code. You can change or customize features to fit your needs. Developers who use open source tools are part of a collaborative community of users who can share use cases, best practices, and feature improvements made by altering the original source code.
Open source tools can give you more control over features and can provide great flexibility as your tasks and data operations evolve. However, using open source tools comes with the same commitment as building your own tool. You will have to make investments to maintain the platform over time, which can be costly.
While open source tools can be good for learning or testing early versions of a commercial application, they often present barriers to scale. This is because most open source tools are not comprehensive labeling solutions and lack robust dataset management, label automation, or other features that drive efficiency (like data clustering). In addition, few open source tools provide quality assurance workflows or accuracy analytics which can hinder data quality.
It’s important to know that open source communities provide support mostly via on-line documentation, FAQs, and tutorials. There are no support numbers to call and some open source tools don’t provide data privacy and security measures needed to comply with GDPR and HIPAA.
There are several open source data annotation tools available, many of which have been available for years and have improved over time.
You will uncover buy vs. build implications throughout your product development lifecycle. From sourcing the data to labeling, modeling, deployment, and improvements - your data annotation tool plays a key role in your project’s success. That’s why your tool choice is so important - because it affects your workflow from the beginning stages of model development through model testing and into production.
With a market size of USD $805.6 million in 2022 , data annotation tools will expand as adoption of data annotation tools increases in the automotive, retail, and healthcare industries. As new options emerge, you may want to consider what is available to you.
Why change data annotation tools?
As you train, test, and validate your model - and even as you tune it in production, your data annotation needs may change. A tool that was built for your first purpose might not serve you as well in the future as your use case, tasks, and business rules evolve. That’s why it’s important to avoid getting into a long-term contract with a single tool or workforce provider - or tying your tool to your workforce.
Here are a few examples of reasons you might want to change your tool during a project:
- You began building a tool but are now considering buying because commercial tools have added new features that meet your needs.
- The tool doesn’t have the automation or the automation features you want.
- Your cost increases for access to the commercial tool.
How do I change data annotation tools?
When you change your data annotation tool in the middle of training or production, you’ll likely ask the same questions you’d ask if you were buying the tool for a new project. However, there will be considerations regarding the ease of transferring your data into a new tool and resuming data annotation in the new tool.
For example, you will have to anticipate and manage details related to:
- Introducing a different data ingestion pipeline
- How data is stored
- Output format
- Use of a new tool - and training your data workers to use it
- Your workforce provider’s technology to track the quality and productivity of its workers, and how they capture the data required to do it.
While we know it’s important to be flexible when it comes to your data annotation tool, we have yet to learn how long one tool can meet your needs and how long you should wait before evaluating your options again. The data annotation tool ecosystem is just gathering steam, and those who were among the first teams to monetize their data annotation tools are just starting to renew contracts with their earliest adopters.
This is one aspect of the market we’re watching so we can provide exceptional consultative service to our clients and ensure they are using the best-fit tool for their needs.
Here are questions to keep in mind when you’re speaking with a data annotation tool provider:
Strategic Approach
- Of all of the features available with your tool, what does your team consider to be your tool’s specialty - and why?
- How long have you been building, maintaining, and supporting this data annotation tool?
- How is your tool different from other commercially-available tools?
- Do you consider your product to be a tool or a platform? What other aspects of the machine learning data labeling process does your tool support?
- Is your team open to receiving feedback about your data annotation tool, its features, and ways it could be improved to better serve the needs of our use case?
- What are your pricing methods? (e.g., monthly, annual, by annotation, by worker)
Key Features
- Do you offer dataset management?
- Where can files be stored? What capacity does the tool support, in terms of how much data can be moved into the tool? Can I upload pre-annotated images into the tool?
- Do you offer an API and/or SDK? If so, how robust are they?
- Do you offer data management?
- Can I bulk upload classes and attributes into the tool?
- Does your tool allow us to deploy a large and growing workforce to use it?
- What security compliance or certifications does your tool have?
- Is quality control (QC) built into your tooling platform? What does that workflow look like?
- What kind of quality assurance (QA) do you provide?
Machine Learning
- Have you built any AI into your tool?
- Can I bring my own algorithm and plug it into your tool?
Though the specific tools suggested above are a great place to start, it’s best to avoid dependence on any single platform for your data annotation needs. After all, no two datasets present exactly the same challenges, and no particular tool will be the best option in all circumstances. Because training data challenges are unique and dynamic in nature, tying your workforce to one tool can be a strategic liability.
For a more flexible approach to labeling text, images, and video, you’ll need to develop a versatile team that can adapt to new tools. At CloudFactory, this emphasis on versatility guides how we select and train our cloud workers. We hire team members with the skills to work on any platform our clients prefer. No matter the tool you use or the type of training data you need, we have workers ready and able to get started.
The People + Process Component
The maturity of your data annotation tool and its features impact how you and your data workforce will design workflow, quality control, and many other aspects of your data work. A tool that doesn’t take your workforce and your processes into consideration will cost you time and efficiency in building workarounds for things that you’ll wish were native within the tool.
CloudFactory delivers the people and the process, and we know data annotation because we’ve been doing it for the better part of a decade, working remotely for our clients. Our data annotation teams are vetted, trained, and actively managed to deliver higher engagement, accountability, and quality.
- Work from anywhere - We work how you work, as an extension of your team. We can use any tool and follow the rules you set. Using our proprietary platform, you have direct communication with a team leader to provide feedback. Workers can share their observations to drive improved processes, higher productivity, and better quality.
- Scale the work - We can flex up or down, based on your business requirements.
- Select and train top-notch workers - Our workforce strategy values people, and we make sure workers understand the importance of the tasks they are doing for your business. We monitor worker performance for productivity and quality, and our team leaders come alongside workers to train and encourage them.
- Flexible pricing model - You can scale work up or down without renegotiating your contract. We do not lock you into a long-term contract or tie our workforce to your tool.
Are you ready to select the right data annotation tool? Find out how we can help you save time and money.
Reviewers Anthony Scalabrino , sales engineer at CloudFactory , a provider of professionally managed teams for data annotation for machine learning.
Nir Buschi , Co-founder & Chief Business Officer at Dataloop AI , an enterprise-grade data platform for AI systems in development and in production, providing an end-to-end data workflow including data annotation, quality control, data management, automation pipelines and autoML.
Contact Sales
Frequently asked questions, what is annotated data.
In supervised or semi-supervised machine learning, annotated data is labeled, tagged, or processed for the features you want your machine learning system to learn to recognize. An example of annotated data is sensor data from an autonomous vehicle, where the data has been enriched to show exactly where there are pedestrians and other vehicles.
What is a data annotator?
A data annotator is: 1) someone who works with data and enriches it for use with machine learning; or 2) an auto labeling feature, or automation, that is built into a data annotation tool to enrich data. That automation is powered by machine learning that makes predictions about your annotations based on the training data it has consumed and the tuning of the model during testing and validation.
What is data annotation?
In supervised or semi-supervised machine learning, data annotation is the process of labeling data to show the outcome you want your machine learning model to predict. You are enriching - also known as labeling, tagging, transcribing, or processing - a dataset with the features you want your machine learning system to learn to recognize. Ideally, once you deploy your model, the machine will be able to recognize those features on its own and make a decision or take some action as a result.
What are data annotation tools?
Data annotation tools are cloud-based, on-premise, or containerized software solutions that can be used to label or annotate production-grade training data for machine learning. They can be available via open source or freeware, or they may be offered commercially, for lease. Data annotation tools are designed to be used with specific types of data, such as image, text, audio, spreadsheet, sensor, photogrammetry, or point-cloud data.
What is an image annotation tool?
An image annotation tool is a cloud-based, on-premise or containerized software solution that can be used to label, tag, or annotate images or frame-by-frame video for production-grade training data for machine learning. Features may include bounding boxes, polygons, 2-D and 3-D points, or segmentation (semantic or instance), or transcription. Some image annotation tools include quality control features such as intersection over union (IoU), a consensus model used in object detection within images. It compares your hand-annotated, ground-truth images with the annotations your model predicts.
What’s the best image annotation tool?
The best image annotation tool will depend on your use case, data workforce, size and stage of your organization, and quality requirements. Dataloop , Encord , Hasty , Labelbox , Pix4D , Pointly , and Segments.ai offer commercial annotation tools to label images that are used to train, test, and validate machine learning algorithms. CVAT and QGIS are open source tools you can use and customize for your own image annotation needs.
What is a video annotation tool?
A video annotation tool is a cloud-based, on-premise or containerized software solution that can be used to label or annotate video or frame-by-frame images from video for production-grade training data for machine learning. It can be available via open source or freeware, or it may be offered commercially, for lease. Features may include bounding boxes, polygons, 2-D and 3-D points, or segmentation (semantic or instance).
What’s an online annotation tool?
An online annotation tool is a cloud-based, on-premise, or containerized software solution that can be used to label or annotate production-grade training data for machine learning. It can be available via open source or freeware, or it may be offered commercially. Online annotation tools are designed to be used with specific types of data, such as image, text, video, audio, spreadsheet, or sensor data.
What are text annotation tools?
Text annotation tools are cloud-based, on-premise, or containerized software solutions that can be used to annotate production-grade training data for machine learning. This process also can be called labeling, tagging, transcribing, or processing. Text annotation tools can be available via open source or freeware, or they may be offered commercially.
Is there a list of video annotation tools?
Dataloop , Encord , Hasty , Labelbox , and Segments.ai offer commercial annotation tools that can be used to label video to train, test, and validate machine learning algorithms. CVAT is an open source video annotation tool you can use or customize for your own video annotation needs. The best video annotation tool will depend on your use case, data workforce, size and stage of your organization, and quality requirements.
What’s the best text annotation tool?
The best text annotation tool will depend on your use case, data workforce, size and stage of your organization, and quality requirements. DatasaurAI and Labelbox offer commercial annotation tools that can be used to analyze language and sentiment to train, test, and validate machine learning algorithms.
- Accelerated Annotation
- Workforce Plus
- Data Labeling Managed Workforce
- Data Labeling Guide
- Training Data Guide
- Data Processing Guide
- Image Annotation Guide
- Data Annotation Tools Guide
- Human in the Loop Guide
- +1 (888) 809-0229 (US)
- Book a Meeting
© 2010-2024 CloudFactory Limited | Privacy Policy

- Generative AI and LLMs
- ML Business & Strategy
- ML Basics & Principles
- Advanced ML Development
- ML Tools, APIs & Frameworks
- ML Strategy Day
- Advisory Board
- Call For Papers
- Online Conference
- Business & Strategy
- Machine Learning Basics & Principles
- Tools, APIs & Frameworks
- ML STRATEGY DAY
- On-site Tickets
- Remote Tickets
- Student Ticket
- On-site tickets
- Remote tickets
- Program Munich
- Program New York
- Become a Sponsor
- Sponsors & Exhibitors
- Location / Hotel Booking
- Join our Newsletter
- Conference App
- Code of Conduct
- Register Now »
ONLY UNTIL APRIL 18: ✓ Save up to 440 € ✓ Huawei Band 8 for free ✓ Access to devmio
Limited Time offer: ✓ Save up to $950 ✓ Free ML Strategy Day ✓ Access to devmio
COMING UP NEXT: MLCon Munich | June 25 – 28, 2024
ML CONFERENCE Blog
What is data annotation and how is it used in machine learning, answering key ml questions.

Modern businesses are operating in highly competitive markets, and finding new business opportunities is even harder. Customer experiences are constantly changing, finding the right talent to work on common business goals is also an enormous challenge, yet businesses want to perform the way the market demands. So what are these companies doing to create a sustainable competitive advantage? This is where Artificial Intelligence (AI) solutions come in and are prioritized. With AI, it is easier to automate business processes and smoothen decision-making. But, what exactly defines a successful Machine Learning (ML) project? The answer is simple, the quality of training datasets that work with your ML algorithms.
Having that in mind, what amounts to a high-quality training dataset? Data annotation. What is data annotation? And how is data annotation applied in ML?
In this article, we are delving deep to answer these key questions, and is particularly helpful if:
- You are seeking to understand what data annotation is in ML and why it is so important.
- You are a data scientist curious to know the various data annotation types out there and their unique applications.
- You want to produce high-quality datasets for your ML model’s top performance, and have no idea where to find professional data annotation services.
- You have huge chunks of unlabeled data , have no time to gather, organize, and label them, and in dire need of a data labeler to do the job for you, ultimately meet your training and deploying goals for your models.
What is Data Annotation?
In ML, data annotation refers to the process of labeling data in a manner that machines can recognize either through computer vision or natural language processing (NLP). In other words, data labeling teaches the ML model to interpret its environment, make decisions and take action in the process.
Data scientists use massive amounts of datasets when building an ML model, carefully customizing them according to the model training needs. Thus, machines are able to recognize data annotated in different, understandable formats such as images, texts, and videos.
This explains why AI and ML companies are after such annotated data to feed into their ML algorithm, training them to learn and recognize recurring patterns, eventually using the same to make precise estimations and predictions.
The data annotation types
Data annotation comes in different types, each serving different and unique use cases. Although data annotation is broad and wide, there are common annotation types in popular machine learning projects which we are looking at in this section to give you the gist in this field:
Semantic Annotation
Semantic annotation entails annotation of different concepts within text, such as names, objects, or people. Data annotators use semantic annotation in their ML projects to train chatbots and improve search relevance.
Image and Video Annotation
Let’s say this, image annotation enables machines to interpret content in pictures. Data experts use various forms of image annotation, including bounding boxes displayed on images, to pixels assigned a meaning individually, a process called semantic segmentation. This type of annotation is commonly used in image recognition models for various tasks like facial recognition and recognizing and blocking sensitive content.
Video annotation, on the other hand, uses bounding boxes, or polygons on video content. The process is simple, developers use video annotation tools to place these bounding boxes, or stick together video frames to track the movement of annotated objects. Either way deemed fit by the developer, this type of data becomes handy when developing computer vision models for localization of object tracking tasks.
Text categorization
Text categorization, also called text classification or text tagging is where a set of predefined categories are assigned to documents. A document can contain tagged paragraphs or sentences by topic using this type of annotation, thus making it easier for users to search for information within a document, an application, or a website.
Why is Data Annotation so Important in ML
Whether you think of search engines’ ability to improve on the quality of results, developing facial recognition software, or how self-driving automobiles are created, all these are made real through data annotation. Living examples include how Google manages to give results based on the user’s geographical location or sex, how Samsung and Apple have improved the security of their smartphones using facial unlocking software, how Tesla brought into the market semi-autonomous self-driving cars, and so on.
Annotated data is valuable in ML in giving accurate predictions and estimations in our living environments. As aforesaid, machines are able to recognize recurring patterns, make decisions, and take action as a result. In other words, machines are shown understandable patterns and told what to look for – in image, video, text, or audio. There is no limit to what similar patterns a trained ML algorithm cannot find in any new datasets fed into it.
Data Labeling in ML
In ML, a data label, also called a tag, is an element that identifies raw data (images, videos, or text), and adds one or more informative labels to put into context what an ML model can learn from. For example, a tag can indicate what words were said in an audio file, or what objects are contained in a photo.
Data labeling helps ML models learn from numerous examples given. For example, the model will spot a bird or a person easily in an image without labels if it has seen adequate examples of images with a car, bird, or a person in them.
Data annotation is valuable to ML and has contributed immensely to some of the cutting-edge technologies we enjoy today. Data annotators, or the invisible workers in the ML workforce, are needed more now than ever before. The growth of the AI and ML industry as a whole depends solely on the continued creation of nuanced datasets needed to create some of ML’s complex problems.
There is no better “fuel” for training ML algorithms than annotated data in images, videos, or texts – and that is when we arrive at some of the autonomous ML models we can possibly and proudly have.
Now you understand why data annotation is essential in ML, its various and common types, and where to find data annotators to do the job for you. You are in a position to make informed choices for your enterprise and level up your operations.

Melanie Johnson, AI and computer vision enthusiast with a wealth of experience in technical writing. Passionate about innovation and AI-powered solutions loves sharing expert insights and educating individuals on tech.
Cheat Sheet: Natural Language Processing (NLP) in Python

Behind the Tracks
Machine learning & principles, advanced ml development, business & strategy, tools, apis & frameworks, don’t miss any ml conference news.
What Is Data Annotation In Machine Learning

- Technology & Innovation
- AI & Machine Learning

Introduction
Machine learning has revolutionized various industries, enabling computers to learn and make decisions without explicit programming. One of the key aspects that drives the success of machine learning algorithms is high-quality and accurately labeled data. Data annotation plays a pivotal role in this process.
Data annotation is the process of labeling and categorizing data to create training datasets for machine learning models. It involves adding relevant metadata, tags, and annotations to raw data, enabling the models to recognize patterns and make accurate predictions. By providing labeled data, data annotation assists the algorithm in understanding and identifying specific features or patterns, which are crucial for accurate predictions and decision-making.
The importance of data annotation cannot be understated. It serves as the building block for training machine learning models and directly impacts their performance and effectiveness. High-quality and well-annotated datasets lead to accurate models, while low-quality or incorrectly labeled data can introduce biases, errors, and inefficiencies into the learning process.
Data annotation is not limited to a specific industry or field. It is utilized in various sectors, such as healthcare, finance, autonomous vehicles, natural language processing, and computer vision, to name a few. With the growing adoption of machine learning across industries, the demand for accurate and reliable data annotation services has skyrocketed.
In this article, we will explore the importance of data annotation in machine learning and delve into the various types of data annotation methods. We will also discuss the challenges faced in the data annotation process and highlight best practices for ensuring high-quality annotations. By the end, you will have a solid understanding of the crucial role data annotation plays in the success of machine learning algorithms and the steps involved in the annotation process.
What is Data Annotation?
Data annotation, also known as labeling or tagging, is the process of assigning meaningful and relevant information to raw data. This annotation provides context and organizes the data in a structured manner, making it usable for training machine learning models. The labeled data acts as a reference for the algorithm, enabling it to understand patterns and make accurate predictions.
In data annotation, humans or automated systems add annotations to various types of data, such as text, images, videos, or audio. These annotations can range from simple labels or tags to more complex data attributes, like bounding boxes, keypoints, segmentation masks, sentiment scores, or named entity recognition.
The process of data annotation involves understanding the specific requirements of the machine learning task and designing a structured annotation schema. This schema defines the categories, classes, or labels that the data will be annotated with. For example, in an image classification task, the schema might include labels such as “cat,” “dog,” or “car.”
Data annotation can be a manual process performed by human annotators or an automated process using machine learning techniques. Manual annotation involves trained annotators carefully reviewing and labeling the data based on the annotation schema. Automated annotation methods leverage pre-existing models or algorithms to automatically assign annotations. However, manual annotation is typically preferred for tasks that require high accuracy and precision.
Data annotation is essential in machine learning as it directly influences the performance and effectiveness of the models. Accurate and high-quality annotations ensure that the models learn from reliable and relevant data. Conversely, incorrect or inconsistent annotations can introduce biases, errors, and hinder the model’s ability to generalize and make accurate predictions.
In the next section, we will explore the importance of data annotation in machine learning and examine how it contributes to the success of machine learning models.
Importance of Data Annotation in Machine Learning
Data annotation plays a crucial role in the success of machine learning models by providing labeled data that helps them learn and make accurate predictions. Here are some key reasons why data annotation is essential in machine learning:
1. Training Machine Learning Models: Machine learning models rely on labeled data to learn patterns and make predictions. Data annotation provides the necessary information for the models to understand the underlying structure and relationships within the data, enabling them to make accurate predictions.
2. Improving Model Performance: High-quality annotations ensure that the models are trained on accurate and relevant data. Well-annotated datasets reduce the risk of introducing biases, errors, and inconsistencies, leading to improved performance and more reliable predictions.
3. Enabling Supervised Learning: Supervised learning, where models learn from labeled examples, is a widely used approach in machine learning. Data annotation provides the labeled examples needed for training the models in a supervised manner.
4. Enhancing Generalization: Data annotation helps models generalize patterns from the labeled data to new, unseen data. By exposing the models to a diverse range of annotated examples, they can learn to recognize and predict patterns in real-world scenarios.
5. Domain-specific Insights: Data annotation allows domain experts to add contextual information and insights to the labeled data. This domain expertise can be crucial in enhancing the accuracy and relevance of the annotations, especially in specialized fields such as healthcare, finance, or natural language processing.
6. Scaling Machine Learning Projects: Data annotation allows for the creation of large-scale annotated datasets, which are essential for training complex machine learning models. By annotating large volumes of data, organizations can build robust models that can handle diverse and real-world scenarios.
7. Continuous Model Improvement: Data annotation is an iterative process. As models make predictions and encounter new data, the feedback loop of data annotation helps refine and improve the models over time. This continuous improvement ensures that the models adapt to changing trends and patterns.
In the next section, we will explore the different types of data annotation methods used in machine learning.
Types of Data Annotation
Data annotation involves various methods and techniques to assign annotations to different types of data. Here are some common types of data annotation used in machine learning:
1. Image Annotation: Image annotation involves labeling objects, regions, or attributes within an image. It can include bounding box annotations, where a rectangular box is drawn around an object of interest, or polygon annotations for more complex shapes. Other types of image annotation include semantic segmentation, where each pixel is labeled with a specific class, and landmark annotation, which marks specific points of interest within an image.
2. Text Annotation: Text annotation involves labeling or tagging specific elements within textual data. This can include Named Entity Recognition (NER), where entities such as names, locations, or organizations are identified and labeled within the text. Sentiment analysis annotation involves evaluating the sentiment expressed in the text, such as positive, negative, or neutral. Text classification annotation assigns predefined categories or labels to the text, enabling classification tasks.
3. Audio Annotation: Audio annotation involves labeling or transcribing audio data. This can include speech recognition annotation, where spoken words are transcribed into text, or speaker diarization, which identifies and segments different speakers in the audio. Other audio annotation tasks include emotion recognition, music genre classification, or sound event detection.
4. Video Annotation: Video annotation involves labeling and annotating objects, actions, or events within a video. This can include object tracking, where objects are annotated over time to track their movement. Activity recognition annotation involves labeling specific actions or activities performed in the video. Video annotation is crucial in applications such as surveillance, autonomous vehicles, and video-based analysis.
5. Geospatial Annotation: Geospatial annotation involves labeling or tagging geographic and spatial data. This can include annotating points of interest, land cover types, or routes on maps. Geospatial annotation is pivotal in applications such as mapping, geolocation services, and GIS-based analysis.
6. Sensor Data Annotation: Sensor data annotation involves labeling or annotating data collected from sensors or IoT devices. This can include annotating sensor readings, sensor fusion data, or environmental data. Sensor data annotation is crucial in applications such as smart cities, environmental monitoring, and industrial automation.
These are just a few examples of the types of data annotation used in machine learning. Depending on the specific use case and requirements, different annotation methods can be employed to provide the necessary information for training and modeling purposes.
In the next section, we will explore the processes of manual data annotation and automated data annotation.
Manual Data Annotation
Manual data annotation involves human annotators carefully reviewing and labeling the data based on predefined annotation guidelines or schema. It is a labor-intensive process that requires domain expertise and attention to detail. Here are the key steps involved in manual data annotation:
1. Annotation Guidelines: Before starting the annotation process, clear and detailed annotation guidelines are established. These guidelines define the annotation schema, the specific categories or labels to be assigned, and any specific instructions or guidelines for handling complex cases.
2. Selection of Annotators: Annotators with relevant domain knowledge and expertise are selected for the annotation task. These annotators should be familiar with the annotation guidelines and have a good understanding of the data to ensure accurate and consistent annotations.
3. Annotation Process: Annotators carefully review the data and assign the appropriate labels, annotations, or tags according to the defined guidelines. They follow the annotation schema and consider the context and nuances of the data to ensure accurate and meaningful annotations.
4. Quality Assurance: To maintain accuracy and consistency, a quality assurance process is implemented. This involves regular checks on the annotated data to identify any errors, inconsistencies, or discrepancies. Feedback and clarifications are provided to annotators to ensure high-quality annotations throughout the process.
5. Iterative Refinement: Manual annotation is an iterative process that involves continuous feedback and refinement. As annotators gain more experience and encounter challenging cases, the annotation guidelines may be updated to provide clearer instructions or guidelines. This iterative refinement ensures that the annotations align with the desired quality and accuracy.
6. Annotator Collaboration: Collaboration and communication among annotators are crucial for maintaining consistency and resolving any doubts or ambiguities. Regular meetings or discussions can help address any challenges, share insights, and ensure a common understanding of the annotation guidelines.
7. Time and Resource Management: Manual data annotation can be time-consuming and resource-intensive. Proper management of time, resources, and workloads is essential to maintain productivity and meet project deadlines. This can involve effective task allocation, workload balancing, and careful scheduling.
Manual data annotation allows for human expertise and contextual understanding to be incorporated into the annotation process. It is particularly suitable for tasks that require a high level of accuracy, nuanced interpretation of data, or domain-specific knowledge. However, it can be challenging to scale manual annotation for large-scale datasets or when tight deadlines are present.
In the next section, we will explore automated data annotation methods and their benefits and limitations.
Automated Data Annotation
Automated data annotation techniques leverage machine learning algorithms and pre-existing models to assign annotations to data automatically. These methods aim to reduce the manual effort and time required for data annotation. Here are some common automated data annotation methods:
1. Pre-trained Models: Automated data annotation can utilize pre-trained models that have been trained on large annotated datasets. These models can automatically assign annotations to new, unlabeled data based on the patterns and features they have learned from the training data. Pre-trained models are particularly useful for tasks such as image classification, object detection, or text classification.
2. Transfer Learning: Transfer learning involves using a pre-trained model as a starting point and fine-tuning it with a smaller annotated dataset specific to the target task. This approach leverages the knowledge learned from a larger, more diverse dataset to make faster and more accurate annotations on the target data.
3. Active Learning: Active learning techniques involve an iterative process where the machine learning algorithm selects the most valuable or uncertain instances in the unlabeled data for annotation by human annotators. This minimizes the amount of manual annotation required while maximizing the accuracy and efficiency of the annotation process.
4. Weak Supervision: Weak supervision techniques leverage noisy or imperfect labels to annotate data automatically. Instead of relying solely on human annotators, weak supervision uses heuristics, expert rules, or other sources of information to generate annotations. While not as accurate as manual annotation, weak supervision can still provide useful annotations at a larger scale.
5. Crowdsourcing: Crowdsourcing platforms allow multiple annotators to collaborate and collectively annotate large datasets. These platforms provide annotation tasks to a crowd of human workers who follow specific guidelines or annotation rules. The collective effort of multiple annotators helps ensure accuracy and diversity in the annotations.
6. Active Learning with Human in the Loop: This approach combines the benefits of active learning with human intervention. The machine learning algorithm initially selects the most valuable instances for annotation, but these instances are then reviewed and corrected by human annotators. This iterative process helps refine the annotations and improve the overall quality of the data.
Automated data annotation methods offer several advantages, including increased annotation efficiency, scalability for large datasets, and reduced cost. However, they also come with limitations, such as the dependency on pre-existing models, the risk of introducing biases, and the challenge of handling complex or ambiguous cases that may require human judgment and expertise.
In the next section, we will discuss the challenges faced in the data annotation process and how to overcome them.
Challenges in Data Annotation
Data annotation is a complex and challenging process that comes with its own set of difficulties. Here are some common challenges faced in the data annotation process:
1. Ambiguity and Subjectivity: Data can often contain ambiguous or subjective elements that make it challenging to assign clear annotations. Annotators may interpret data differently, leading to inconsistencies and variations in the annotations. Clear annotation guidelines and regular communication among annotators can help address these challenges.
2. Domain Expertise: Certain domains require specialized knowledge and expertise to accurately annotate the data. Annotators need to understand the context, nuances, and domain-specific terminology to provide meaningful annotations. Collaborating with domain experts or providing specific training to annotators can help overcome this challenge.
3. Scalability: Scaling the annotation process to handle large volumes of data can be a significant challenge. Manual annotation processes may not be feasible when dealing with massive datasets. In such cases, automated annotation methods or leveraging crowdsourcing platforms can help increase scalability and efficiency.
4. Time and Cost Constraints: Data annotation can be time-consuming and costly, especially when manual annotation is involved. Meeting project deadlines and managing annotation budgets can be challenging. Efficient planning, resource management, and automation can help address these constraints.
5. Quality Control: Ensuring the quality and consistency of annotations is critical for training reliable machine learning models. Inconsistencies, errors, or biases in annotations can negatively impact model performance. Implementing a thorough quality control process, including regular checks, feedback loops, and inter-annotator agreement assessments, helps maintain annotation quality.
6. Bias and Annotation Errors: Bias can be introduced during the annotation process, which can lead to biased models and algorithmic discrimination. Annotators’ subjective judgments, personal biases, or inconsistent annotation guidelines can contribute to bias. Providing explicit guidelines, diverse annotator teams, and regular quality checks can help mitigate bias and minimize annotation errors.
7. Ever-changing Data: Data annotation can be a continuous process, particularly when dealing with dynamic datasets or evolving tasks. As new data becomes available or annotation requirements change, the annotations need to be updated or refined to adapt to the evolving needs. Flexibility and adaptability in the annotation process are crucial to overcome this challenge.
Addressing these challenges requires careful planning, effective communication, thorough annotation guidelines, quality control measures, and leveraging technology and automation where possible. Overcoming these challenges ensures the production of high-quality, reliable annotations that contribute to accurate and effective machine learning models.
In the next section, we will explore best practices for data annotation to ensure high-quality annotations and successful machine learning models.
Best Practices for Data Annotation
Data annotation is a critical step in developing accurate and reliable machine learning models. Here are some best practices to follow when performing data annotation:
1. Clear Annotation Guidelines: Develop clear and detailed annotation guidelines that define the annotation schema, labeling conventions, and any specific instructions or edge cases. Clear guidelines ensure consistency and accuracy during the annotation process.
2. Training and Calibration: Provide thorough training and calibration sessions to annotators to ensure a common understanding of the annotation guidelines and the desired annotation quality. Regular calibration exercises can help maintain consistency among the annotators.
3. Quality Control Measures: Implement quality control checks throughout the annotation process to identify and rectify any errors, inconsistencies, or biases. Conduct regular checks and feedback sessions with annotators to address any issues and maintain annotation quality.
4. Inter-Annotator Agreement: Assess the agreement levels between different annotators for the same set of data to ensure consistency. Employ techniques such as measuring inter-annotator agreement scores, like Cohen’s kappa, to quantify the degree of agreement between annotators.
5. Continuous Feedback Loop: Establish a feedback loop with annotators to address their questions, challenges, and clarifications promptly. Regular communication and feedback help enhance the annotation process and ensure the accuracy and quality of the annotations.
6. Collaboration and Communication: Foster collaboration and communication among annotators to address any doubts or ambiguities. Encourage annotators to share insights, seek clarification, and discuss challenging cases to ensure a common understanding and consistent annotations
7. Documentation: Maintain comprehensive documentation of the annotation process, including guidelines, feedback, and any updates or modifications made along the way. Detailed documentation ensures transparency, reproducibility, and ease of onboarding for new annotators.
8. Understanding Data Bias: Be aware of potential biases in the data and annotations. Take steps to mitigate biases by ensuring diverse annotator teams, examining potential sources of bias, and implementing measures to address them.
9. Iterative Refinement: Treat data annotation as an iterative process and embrace continuous improvement. As models learn from annotations and encounter new data, refine the annotation guidelines and processes to adapt to changing requirements and improve annotation quality.
10. Use Automation Where Applicable: Leverage automated annotation methods, such as pre-trained models or active learning, to increase annotation efficiency and scalability. Automating repetitive or less subjective annotation tasks can free up time for annotators to focus on more complex cases.
By following these best practices, organizations can achieve high-quality annotations, resulting in more accurate and reliable machine learning models. The process of data annotation requires attention to detail, collaboration, and adherence to best practices to ensure successful outcomes.
In the next section, we will summarize the key points discussed and highlight the importance of data annotation in the machine learning workflow.
Data annotation plays a vital role in the success of machine learning models by providing labeled data that enables the models to learn and make accurate predictions. It involves assigning annotations, labels, or metadata to raw data, creating structured and meaningful datasets for training. Whether performed manually by human annotators or utilizing automated techniques, data annotation is crucial for building accurate and reliable machine learning models.
Throughout this article, we explored the importance of data annotation in machine learning, discussing its role in training models, improving performance, and enabling supervised learning. We also examined the different types of data annotation, including image annotation, text annotation, audio annotation, video annotation, geospatial annotation, and sensor data annotation.
We delved into the challenges faced in the data annotation process, such as ambiguity, scalability, time constraints, quality control, bias, and ever-changing data. It is crucial to address these challenges using best practices, including clear annotation guidelines, training and calibration, quality control measures, continuous feedback, and effective collaboration.
While manual data annotation allows for human expertise and domain understanding, automated data annotation methods provide scalability, efficiency, and cost savings. Employing a combination of manual and automated techniques can yield optimal results, ensuring accurate annotations while managing large-scale datasets.
Data annotation is a continuous and iterative process that requires regular evaluation, refinement, and adaptation. By following best practices and staying attuned to data biases and emerging trends, organizations can produce high-quality annotations and develop robust machine learning models that deliver reliable predictions and insights.
In conclusion, data annotation is a crucial step in the machine learning workflow, enabling models to learn from labeled data and make accurate predictions. It fosters the growth and development of machine learning algorithms, accelerating their deployment and impact across various industries. By investing time, effort, and resources in data annotation, organizations can unlock the full potential of machine learning technology and drive innovation in an increasingly data-driven world.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Crowdfunding
- Cryptocurrency
- Digital Banking
- Digital Payments
- Investments
- Console Gaming
- Mobile Gaming
- VR/AR Gaming
- Gadget Usage
- Gaming Tips
- Online Safety
- Software Tutorials
- Tech Setup & Troubleshooting
- Buyer’s Guides
- Comparative Analysis
- Gadget Reviews
- Service Reviews
- Software Reviews
- Mobile Devices
- PCs & Laptops
- Smart Home Gadgets
- Content Creation Tools
- Digital Photography
- Video & Music Streaming
- Online Security
- Online Services
- Web Hosting
- WiFi & Ethernet
- Browsers & Extensions
- Communication Platforms
- Operating Systems
- Productivity Tools
- AI & Machine Learning
- Cybersecurity
- Emerging Tech
- IoT & Smart Devices
- Virtual & Augmented Reality
- Latest News
- AI Developments
- Fintech Updates
- Gaming News
- New Product Launches
- Designing for Flexibility Materials and Manufacturing Techniques in Flexible Hybrid Electronics
- Icse Chemistry Exams 2024 How Did The Paper Go Here8217s What Students Mentioned
Related Posts

12 Amazing Psu Computer For 2024

3 Best Dissertation Writing Services To Use If You Want To Get A Degree In 2024

Flint’s Paper Batteries: A Potential Disruptor In The Battery Industry

How To Cheat In Lockdown Browser

11 Best Medical Coding Books for 2024

12 Amazing Augmented Reality Food Science Lab for 2024

Can You Transfer Money From PayPal to Cash App? (And Vice Versa)

Top 7 Essay Writing Services: Boost Grades and Build Confidence
Recent stories.

Designing for Flexibility: Materials and Manufacturing Techniques in Flexible Hybrid Electronics

Icse Chemistry Exams 2024: How Did The Paper Go? Here’s What Students Mentioned

How Sustainable Is Bitcoin’s Current Price Rally?

What Are the Most Common Challenges in AI Development?

When Does Metroid Dread Come Out

Where To Go After Ice Missile Metroid Dread

Where To Go After First Boss Metroid Dread

How Much Is Metroid Dread
- Privacy Overview
- Strictly Necessary Cookies
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.
Please enable JavaScript to view this site.
The Complete Guide to Data Annotation [2024 Review]
What is data annotation, faqs: how to annotate and label different image and video datasets for machine learning .
Data annotation is integral to the process of training a machine learning (ML) or computer vision model (CV). Datasets often include many thousands of images, videos, or both, and before an algorithmic-based model can be trained, these images or videos need to be labeled and annotated accurately.
Creating training datasets is a widely used process across dozens of sectors, from healthcare to manufacturing, to smart cities and national defense projects.
In the medical sector, annotation teams are labeling and annotating medical images (usually delivered as X-rays, DICOM, or NIfTI files ) to accurately identify diseases and other medical issues. With satellite images (usually delivered in the Synthetic Aperture Radar format), annotators could be spending time identifying coastal erosion and other signs of human damage to the planet.
In every use case, data labeling and annotation are designed to ensure images and videos are labeled according to the project outcome, goals, objectives, and what the training model needs to learn before it can be put into production.
In this article, we cover the complete guide to data annotation, including the different types of data annotation, use cases, and how to annotate images and videos.
Data annotation is the process of taking raw images and videos within datasets and applying labels and annotations to describe the content of the datasets. Machine learning algorithms can’t see. It doesn’t matter how smart they are.
We, human annotators and annotation teams, need to show AI models (artificial intelligence) what’s in the images and videos within a dataset.
Annotations and labels are the methods that are used to show, explain, and describe the content of image and video-based datasets. This is the way models are trained for an AI project; how they learn to extrapolate and interpret the content of images and videos across an entire dataset.
With enough iterations of the training process (where more data is fed into the model until it starts generating the sort of results, at the level of accuracy required), accuracy increases, and a model gets closer to achieving the project outcomes when it goes into the production phase.
At the start, the first group of annotated images and videos might produce an accuracy score of around 70%. Naturally, the aim is to increase and improve that, and therefore more training data is required to further train the model. Another key consideration is data-quality - the data has to be labeled as clearly and accurately as possible to get the best results out of the model.

Image segementation in Encord
What’s AI-assisted Annotation?
Manual annotation is time-consuming. Especially when tens of thousands of images and videos need to be annotated and labeled within a dataset. As we’ve mentioned in this article, annotation in computer vision models always involves human teams.
Fortunately, there are now tools with AI-labeling functionality to assist with the annotation process. Software and algorithms can dramatically accelerate annotation tasks, supporting the work of human annotation teams. You can use open-source tools, or premium customizable AI-based annotation tools that run on proprietary software, depending on your needs, budget, goals, and nature of the project.
Human annotators are often still needed to draw bounding boxes or polygons and label objects within images. However, once that input and expertise is provided in the early stages of a project, annotation tools can take over the heavy lifting and apply those same labels and annotations throughout the dataset.
Expert reviewers and quality assurance workflows are then required to check the work of these annotators to ensure they’re performing as expected and producing the results needed. Once enough of a dataset has been annotated and labeled, these images or videos can be fed into the CV or ML model to start training it on the data provided.
What Are The Different Types of Data Annotation?
There are numerous different ways to approach data annotation for images and videos.
Before going into more detail on the different types of image and video annotation projects , we also need to consider image classification and the difference between that and annotation. Although classification and annotation are both used to organize and label images to create high-quality image data, the processes and applications involved are somewhat different.
Classification is the act of automatically classifying objects in images or videos based on the groupings of pixels. Classification can either be “supervised” — with the support of human annotators, or “unsupervised” — done almost entirely with image labeling tools.
Alongside classification, there is a range of approaches that can be used to annotate images and videos:
- Multi-Object Tracking (MOT) in video annotation for computer vision models, is a way to track multiple objects from frame to frame in videos once an object has been labeled. For example, it could be a series of cars moving from one frame to the next in a video dataset. Using MOT, an automated annotation feature, it’s easier to keep track of objects, even if they change speed, direction, or light levels change.
- Interpolation in automated video annotation is a way of filling in the gaps between keyframes in a video. Once labels and annotations have been applied at the start and end of a series of videos, interpolation is an automation tool that applies those labels throughout the rest of the video(s) to accelerate the process.
- Auto Object Segmentation and detection is another type of automated data annotation tool. You can use this for recognizing and localizing objects in images or videos with vector labels. Types of segmentation include instance segmentation and semantic segmentation .
- Model-assisted labeling (MAL) or AI-assisted labeling (AAL) is another way of saying that automated tools are used in the labeling process. It’s far more complex than applying ML to spreadsheets or other data sources, as the content itself is either moving, multi-layered (in the case of various medical imaging datasets) or involves numerous complex objects, increasing the volume of labels and annotations required.
- Human Pose Estimation (HPE) and tracking is another automation tool that improves human pose and movement tracking in videos for computer vision models.
- Bounding Boxes: A way to draw a box around an object in an image or video, and then label that object so that automation tools can track it and similar objects throughout a dataset.
- Polygons and Polylines : These are ways of drawing lines and labeling either static or moving objects within videos and images, such as a road or railway line.
- Keypoints and Primitives (aka skeleton templates): Keypoints are useful for pinpointing and identifying features of countless shapes and objects, such as the human face. Whereas, primitives, also known as skeleton templates are for specialized annotations to templatize specific shapes, e.g. 3D cuboids, or the human body.
Of course, there are numerous other types of data annotations and labels that can be applied. However, these are amongst some of the most popular and widely used CV and ML models.

How Do I Annotate an Image Dataset For Machine Learning?
Annotation work is time-consuming, labor intensive, and often doesn’t require a huge amount of expertise. In most cases, manual image annotation tasks are implemented in developing countries and regions, with oversight from in-house expert teams in developed economies. Data operations and ML teams ensure annotation workflows are producing high-quality outputs.
To ensure annotation tasks are complete on time and to the quality and accuracy standards required, automation tools often play a useful role in the process. Automation software ensures a much larger volume of images can be labeled and annotated, while also helping managers oversee the work of image annotation teams.
Different Use Cases for Annotated Images
Annotated images and image-based datasets are widely used in dozens of sectors, in computer vision and machine learning models, for everything from cancer detection to coastal erosion, to finding faults in manufacturing production lines.
Annotated images are the raw material of any CV, ML, or AI-based model. How and why they’re used and the outcomes these images generate depends on the model being used, and the project goals and objectives.
How Do I Annotate a Video Dataset For Machine Learning?
Video annotation is somewhat more complicated. Images are static, even when there’s a layer of images and data, as is often the case with medical imaging files.
However, videos are made up of thousands of frames, and within those moving frames are thousands of objects, most of which are moving. Light levels, backgrounds, and numerous other factors change within videos.
Within that context, human annotators and automated tools are deployed to annotate and label objects within videos to train a machine learning model on the outputs of that annotation work.
Different Use Cases for Annotated Videos
Similar to annotated images, videos are the raw materials that train algorithmic models (AI, CV, ML, etc.) to interpret, understand, and analyze the content and context of video-based datasets.
Annotated videos are used in dozens of sectors with thousands of practical commercial use cases, such as disease detection, smart cities, manufacturing, retail, and numerous others.
At Encord, our active learning platform for computer vision is used by a wide range of sectors - including healthcare, manufacturing, utilities, and smart cities - to annotate 1000s of images and accelerate their computer vision model development.
Experience Encord in action. Dramatically reduce manual video annotation tasks, generating massive savings and efficiencies.
Sign-up for an Encord Free Trial : The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today .
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Join our Discord channel to chat and connect.
How are DICOM and NIfTI Images Annotated for Machine Learning?
DICOM and NIfTI images are two of the most widely used medical imaging formats. Both are annotated using human teams, supported by automated annotation tools and software. In the case of DICOM files, labels and annotations need to be applied across numerous layers of the images, to ensure the right level of accuracy is achieved.
How are Medical Images Used in Machine Learning?
In most cases, medical images are used in machine learning models to more accurately identify diseases, and viruses, and to further the medical professions' (and researchers') understanding of the human body and more complex edge cases.
How are SAR (Synthetic Aperture Radar) Images Annotated for Machine Learning?
SAR images ( Synthetic Aperture Radar ) come from satellites, such as the Copernicus Sentinel-1 mission of the European Space Agency (ESA) and the EU Copernicus Constellation . Private satellite providers also sell images, giving projects that need them a wide variety of sources of imaging datasets of the Earth from orbit.
SAR images are labeled and annotated in the same way as other images before these datasets are fed into ML-based models to train them.
What Are The Uses of SAR Images for Machine Learning?
SAR images are used in machine learning models to advance our understanding of the human impact of climate change, human damage to the environment, and other environmental fields of research. SAR images also play a role in the shipping, logistics, and military sectors.

Build better ML models with Encord
Discuss this blog on slack.
Join the Encord Developers community to discuss the latest in computer vision, machine learning, and data-centric AI
Related Blogs

What is a Data Lake? A data lake is a centralized repository where you can store all your structured, semi-structured, and unstructured data types at any scale for processing, curation, and analytics. It supports batch and real-time streams to combine raw data from diverse sources (databases, IoT devices, mobile apps, etc.) into the repository without a predefined schema. It has been 12 years since the New York Times published an interesting article on ‘The Age of Big Data,’ in which most of the talk and tooling were centered around analytics. Fast-forward to today, and we are continuously grappling with the influx of data at the petabyte (PB) and zettabyte (ZB) scales, which is getting increasingly complex in dimensions (images, videos, point cloud data, etc.). It is clear that solutions that can help manage the size and complexity of data are needed for organizational success. This has urged data, AI, and technology teams to look towards three pivotal data management solutions: data lakes, data warehouses, and cloud services. This article focuses on understanding data lakes as a data management solution for machine learning (ML) teams. You will learn: What a data lake is and how it differs from a data warehouse. Benefits and limitations of a data lake for ML teams. The data lake architecture. Best practices for setting up a data lake. On-premise vs. cloud-based data lakes. Computer vision use cases of data lakes. TL; DR A data lake is a centralized repository for diverse, structured, and unstructured data. Key architecture components include Data Sources, Data Ingestion, Data Persistence and Storage, Data Processing Layer, Analytical Sandboxes, Data Lake Zones, and Data Consumption. Best practices for data lakes involve defining clear objectives, robust data governance, scalability, prioritizing security, encouraging a data-driven culture, and quality control. On-premises data lakes offer control and security; cloud-based data lakes provide scalability and cost efficiency. Data lakes are evolving with advanced analytics and computer vision use cases, emphasizing the need for adaptable systems and adopting forward-thinking strategies. Overview: Data Warehousing, Data Lake, and Cloud Storage Data Warehouses A data warehouse is a single location where an organization's structured data is consolidated, transformed, and stored for query and analysis. The structured data is ideal for generating reports and conducting analytics that inform business decisions. Limitations Limited agility in handling unstructured or semi-structured data. Can create data silos, hindering cross-departmental data sharing. Data Lakes A data lake stores vast amounts of raw datasets in their native format until needed, which includes structured, semi-structured, and unstructured data. This flexibility supports diverse applications, from computer vision use cases to real-time analytics. Challenges Risk of becoming a "data swamp" if not properly managed, with unclear, unclean, or redundant data. Requires robust metadata and governance practices to ensure data is findable and usable. Cloud Storage and Computing Cloud computing encompasses a broad spectrum of services beyond storage, such as processing power and advanced analytics. Cloud storage refers explicitly to storing data on the internet through a cloud computing provider that manages and operates data storage as a service. Risks Security concerns, requiring stringent data access controls and encryption. Potential for unexpected costs if usage is not monitored. Dependence on the service provider's reliability and continuity. Data lake overview with the data being ingested from different sources. Most ML teams misinterpret the role of data lakes and data warehouses, choosing an inappropriate management solution. Before delving into the rest of the article, let’s clarify how they differ. Data Lake vs. Data Warehouse Understanding the strengths and use cases of data lakes and warehouses can help your organization maximize its data assets. This can help create an efficient data infrastructure that supports various analytics, reporting, and ML needs. Let’s compare a data lake to a data warehouse based on specific features. Choosing Between Data Lake and Data Warehouse The choice between a data lake and a warehouse depends on the specific needs of the analysis. For an e-commerce organization analyzing structured sales data, a data warehouse offers the speed and efficiency required for such tasks. However, a data lake (or a combination of both solutions) might be more appropriate for applications that require advanced computer vision (CV) techniques and large visual datasets (images, videos). Benefits of a Data Lake Data lakes offer myriad benefits to organizations using complex datasets for analytical insights, ML workloads, and operational efficiency. Here's an overview of the key benefits: Single Source of Truth: When you centralize data in data lakes, you get rid of data silos, which makes data more accessible across the whole organization. So, data lakes ensure that all the data in an organization is consistent and reliable by providing a single source of truth. Schema on Read: Unlike traditional databases that define data structure at write time (schema on write), data lakes allow the structure to be imposed at read time to offer flexibility in data analysis and utilization. Scalability and Cost-Effectiveness: Data lakes' cloud-based nature facilitates scalable storage solutions and computing resources, optimizing costs by reducing data duplication. Decoupling of Storage and Compute: Data lakes let different programs access the same data without being dependent on each other. This makes the system more flexible and helps it use its resources more efficiently. Architectural Principles for Data Lake Design When designing a data lake, consider these foundational principles: Decoupled Architecture: Data ingestion, processing, curation, and consumption should be independent to improve system resilience and adaptability. Tool Selection: Choose the appropriate tools and platforms based on data characteristics, ingestion, and processing requirements, avoiding a one-size-fits-all approach. Data Temperature Awareness: Classify data as hot (frequently accessed), warm (less frequently accessed), or cold (rarely accessed but retained for compliance) to optimize storage strategies and access patterns based on usage frequency. Leverage Managed Services: Use managed or serverless services to reduce operational overhead and focus on value-added activities. Immutability and Event Journaling: Design data lakes to be immutable, preserving historical data integrity and supporting comprehensive data analysis. They should also store and version the data labels. Cost-Conscious Design: Implement strategies (balancing performance, access needs, budget constraints) to manage and optimize costs without compromising data accessibility or functionality. Data Lake Architecture A robust data lake architecture is pivotal for harnessing the power of large datasets so organizations can store, process, and analyze them efficiently. This architecture typically comprises several layers dedicated to a specific function within the data management ecosystem. Below is an overview of these key components: Data Sources Diverse Producers: Data lakes can ingest data from a myriad of sources, including, but not limited to, IoT devices, cameras, weblogs, social media, mobile apps, transactional databases (SQL, NoSQL), and external APIs. This inclusivity enables a holistic view of business operations and customer interactions. Multiple Formats: They accommodate a wide range of data formats, from structured data in CSVs and databases to unstructured data like videos, images, DICOM files, documents, and multimedia files, providing a unified repository for all organizational data. This, of course, does not exclude semi-structured data like XML and JSON files. Data Ingestion Batch and Streaming: Data ingestion mechanisms in a data lake architecture support batch and real-time data flows. Use tools and services to auto-ingest the data so the system can effectively capture it. Validation and Metadata: Data is tagged with metadata during ingestion for easy retrieval, and initial validation checks are performed to ensure data quality and integrity. Data Governance Zone Access Control and Auditing: Implementing robust access controls, encryption, and auditing capabilities ensures data security and privacy, crucial for maintaining trust and compliance. Metadata Management: Documenting data origins, formats, lineage, ownership, and usage history is central to governance. This component incorporates tools for managing metadata, which facilitates data discovery, lineage tracking, and cataloging, enhancing the usability and governance of the data lake. Data Persistence and Staging Raw Data Storage: Data is initially stored in a staging area in raw, unprocessed form. This approach ensures that the original data is preserved for future processing needs and compliance requirements. Staging Area: Data may be staged or temporarily held in a dedicated area within the lake before processing. To efficiently handle the volume and variety of data, this area is built on scalable storage technologies, such as HDFS (Hadoop Distributed File System) or cloud-based storage services like Amazon S3. Data Processing Layer Transformation and Enrichment: This layer transforms data into a more usable format, often involving data cleaning, enrichment, deduplication, anonymization, normalization, and aggregation processes. It also improves data quality and ensures reliability for downstream analysis. Processing Engines: To cater to various processing needs, the architecture should support multiple processing engines, such as Hadoop for batch processing, Spark for in-memory processing, and others for specific tasks like stream processing. Data Indexing: This component indexes processed data to facilitate faster search and retrieval. It is crucial for supporting efficient data exploration and curation. Related: Interested in learning the techniques and best data cleaning and preprocessing practices? Check out one of our most-read guides, “Mastering Data Cleaning & Data Preprocessing.” Data Quality Monitoring Continuous Quality Checks: Implements automated processes for continuous monitoring of data quality, identifying issues like inconsistencies, duplications, or anomalies to maintain the accuracy, integrity, and reliability of the data lake. Quality Metrics and Alerts: Define and track data quality metrics, set up alert mechanisms for when data quality thresholds are breached, and enable proactive issue resolution. Related: Read how you can automate the assessment of training data quality in this article. Analytical Sandboxes Exploration and Experimentation: Computer vision engineers and data scientists can use analytical sandboxes to experiment with data sets, build models, and visually explore data (e.g., images, videos) and embeddings without impacting the integrity of the primary data (versioned data and labels). Tool Integration: These sandboxes support a wide range of analytics, data, and ML tools, giving users the flexibility and choice to work with their preferred technologies. Worth Noting: Building computer vision applications? Encord Active integrates with Annotate (with cloud platform integrations) and provides explorers with a way to explore image embeddings for any scale of data visually. See how to use it in the docs. Data Consumption Access and Integration: Data stored in the data lake is accessible to various downstream applications and users, including BI tools, reporting systems, computer vision platforms, or custom applications. This accessibility ensures that insights from the data lake can drive decision-making across the organization. APIs and Data Services: For programmatic access, APIs and data services enable developers and applications to query and retrieve data from the data lake, integrating data-driven insights into business processes and applications. Best Practices for Setting Up a Data Lake Implementing a data lake requires careful consideration and adherence to best practices to be successful and sustainable. Here are some suggested best practices to help you set up a data lake that can grow with your organization’s changing and growing data needs: #1. Define Clear Objectives and Scope Understand Your Data Needs: Before setting up a data lake, identify the types of data you plan to store, the insights you aim to derive, and the stakeholders who will consume this data. This understanding will guide your data lake's design, architecture, and governance model. Set Clear Objectives: Establish specific, measurable objectives for your data lake, such as improving data accessibility for analytics, supporting computer vision projects, or consolidating disparate data sources. These objectives will help prioritize features and guide decision-making throughout the setup process. #2. Ensure Robust Data Governance Implement a Data Governance Framework: A strong governance framework is essential for maintaining data quality, managing access controls, and ensuring compliance with regulatory standards. This framework should include data ingestion, storage, management, and archival policies. Metadata Management: Cataloging data with metadata is crucial for making it discoverable (indexing, filtering, sorting) and understandable. Implement tools and processes to automatically capture metadata, including data source, tags, format, and access permissions, during ingestion or at rest. Metadata can be technical (data design; schema, tables, formats, source documentation), business (docs on usage), and operational (events, access history, trace logs). #3. Focus on Scalability and Flexibility Choose Scalable Infrastructure: Whether on-premises or cloud-based, ensure your data lake infrastructure can scale to accommodate future data growth without significant rework or additional investment. Plan for Varied Data Types: Design your data lake to handle structured, semi-structured, and unstructured data. Flexibility in storing and processing different data types (images, videos, DICOM, blob files, etc.) ensures the data lake can support a wide range of use cases. #4. Prioritize Security and Compliance Implement Strong Security Measures: Security is paramount for protecting sensitive data and maintaining user trust. Apply encryption in transit and at rest, manage access with role-based controls, and regularly audit data access and usage. Compliance and Data Privacy: Consider the legal and regulatory requirements relevant to your data. Incorporate compliance controls into your data lake's architecture and operations, including data retention policies and the right to be forgotten. #5. Foster a Data-Driven Culture Encourage Collaboration: Promote collaboration between software engineers, CV engineers, data scientists, and analysts to ensure the data lake meets the diverse needs of its users. Regular feedback loops can help refine and enhance the data lake's utility. Education and Training: Invest in stakeholder training to maximize the data lake's value. Understanding how to use the data lake effectively can spur innovation and lead to new insights across the organization. #6. Continuous Monitoring and Optimization Monitor Data Lake Health: Regularly monitor the data lake for performance, usage patterns, and data quality issues. This proactive approach can help identify and resolve problems before they impact users. Iterate and Optimize: Your organization's needs will evolve, and so will your data lake. Continuously assess its performance and utility, adjusting based on user feedback and changing business requirements. Cloud-based Data Lake Platforms Cloud-based data lake platforms offer scalable, flexible, and cost-effective solutions for storing and analyzing large amounts of data. These platforms provide Data Lake as a Service (DLaaS), which simplifies the setup and management of data lakes. This allows organizations to focus on deriving insights rather than infrastructure management. Let's explore the architecture of data lake platforms provided by AWS, Azure, Snowflake, GCP, and their applications in multi-cloud environments. AWS Data Lake Architecture Amazon Web Services (AWS) provides a comprehensive and mature set of services to build a data lake. The core components include: Ingestion: AWS Glue for ETL processes and AWS Kinesis for real-time data streaming. Storage: Amazon S3 for scalable and secure data storage. Processing and Analysis: Amazon EMR is used for big data processing, AWS Glue for data preparation and loading, and Amazon Redshift for data warehousing. Consumption: Send your curated data to AWS SageMaker to run ML workloads or Amazon QuickSight to build visualizations, perform ad-hoc analysis, and quickly get business insights from data. Security and Governance: AWS Lake Formation automates the setup of a secure data lake, manages data access and permissions, and provides a centralized catalog for discovering and searching for data. Azure Data Lake Architecture Azure's data lake architecture is centered around Azure Data Lake Storage (ADLS) Gen2, which combines the capabilities of Azure Blob Storage and ADLS Gen1. It offers large-scale data storage with a hierarchical namespace and a secure HDFS-compatible data lake. Ingestion: Azure Data Factory for ETL operations and Azure Event Hubs for real-time event processing. Storage: ADLS Gen2 for a highly scalable data lake foundation. Processing and Consumption: Azure Databricks for big data analytics running on Apache Spark, Azure Synapse Analytics for querying (SQL serverless) and analysis (Notebooks), and Azure HDInsight for Hadoop-based services. Power BI can connect to ADLS Gen2 directly to create interactive reports and dashboards. Security and Governance: Azure provides fine-grained access control with Azure Role-Based Access Control (RBAC) and secures data with Microsoft Entra ID. Snowflake Data Lake Architecture Snowflake's unique architecture separates compute and storage, allowing users to scale them independently. It offers a cloud-agnostic solution operating across AWS, Azure, and GCP. Ingestion: Within Snowflake, Snowpipe Streaming runs on top of Apache Kafka for real-time ingestion. Apache Kafka acts as the messaging broker between the source and Snowlake. You can run batch ingestion with Python scripts and the PUT command. Storage: Uses cloud provider's storage (S3, ADLS, or Google Cloud Storage) or internal (i.e., Snowflake) stages to store structured, unstructured, and semi-structured data in their native format. Processing and Curation: Snowflake's Virtual Warehouses provide dedicated compute resources for data processing for high performance and concurrency. Snowpark can implement business logic within existing programming languages. Data Sharing and Governance: Snowflake enables secure data sharing between Snowflake accounts with governance features for managing data access and security. Consumption: Snowflake provides native connectors for popular BI and data visualization tools, including Google Analytics and Looker. Snowflake Marketplace provides users access to a data marketplace to discover and access third-party data sets and services. Snowpark helps with features for end-to-end ML. High-level architecture for running data lake workloads using Snowpark in Snowflake Google Cloud Data Lake Architecture In addition to various processing and analysis services, Google Cloud Platform (GCP) bases its data lake solutions on Google Cloud Storage (GCS), the primary data storage service. Ingestion: Cloud Pub/Sub for real-time messaging Storage: GCS offers durable and highly available object storage. Processing: Cloud Data Fusion offers pre-built transformations for batch and real-time processing, and Dataflow is for serverless stream and batch data processing. Consumption and Analysis: BigQuery provides serverless, highly scalable data analysis with an SQL-like interface. Dataproc runs Apache Hadoop and Spark jobs. Vertex AI provides machine learning capabilities to analyze and derive insights from lake data. Security and Governance: Cloud Identity and Access Management (IAM) controls resource access, and Cloud Data Loss Prevention (DLP) helps discover and protect sensitive data. Data Lake Architecture on Multi-Cloud Multi-cloud data lake architectures leverage services from multiple cloud providers, optimizing for performance, cost, and regulatory compliance. This approach often involves: Cloud-Agnostic Storage Solutions: Storing data in a manner accessible across cloud environments, either through multi-cloud storage services or by replicating data across cloud providers. Cross-Cloud Services Integration: This involves using best-of-breed services from different cloud providers for ingestion, processing, analysis, and governance, facilitated by data integration and orchestration tools. Unified Management and Governance: Implement multi-cloud management platforms to ensure consistent monitoring, security, and governance across cloud environments. Implementing a multi-cloud data lake architecture requires careful planning and robust data management strategies to ensure seamless operation, data consistency, and compliance across cloud boundaries. On-Premises Data Lakes and Cloud-based Data Lakes Organizations looking to implement data lakes have two primary deployment models to consider: on-premises and cloud-based (although more recent approaches involve a hybrid of both solutions). Cost, scalability, security, and accessibility affect each model's advantages and disadvantages. On-Premises Data Lakes: Advantages Control and Security: On-premises data lakes offer organizations complete control over their infrastructure, which can be crucial for industries with stringent regulatory and compliance requirements. This control also includes data security, so security measures can be tailored to each organization's needs. Performance: With data stored locally, on-premises solutions can provide faster data access and processing speeds, which is beneficial for time-sensitive applications that require rapid data retrieval and analysis. On-Premises Data Lakes: Challenges Cost and Scalability: Establishing an on-premises data lake requires a significant upfront investment in hardware and infrastructure. Scaling up can also require additional hardware purchases and be time-consuming. Maintenance: On-premises data lakes necessitate ongoing maintenance, including hardware upgrades, software updates, and security patches, which require dedicated IT staff and resources. Cloud-based Data Lakes: Advantages Scalability and Flexibility: Cloud-based data lakes can change their storage and computing power based on changing data volumes and processing needs without changing hardware. Cost Efficiency: A pay-as-you-go pricing model allows organizations to avoid substantial upfront investments and only pay for their storage and computing resources, potentially reducing overall costs. Innovative Features: Cloud service providers always add new technologies and features to their services, giving businesses access to the most advanced data management and analytics tools. Cloud-based Data Lakes: Challenges Data Security and Privacy: While cloud providers implement robust security measures, organizations may have concerns about storing sensitive data off-premises, particularly in industries with strict data sovereignty regulations. Dependence on Internet Connectivity: Access to cloud-based data lakes relies on stable internet connectivity. Any disruptions in connectivity can affect data access and processing, impacting operations. Understanding these differences enables organizations to select the most appropriate data lake solution to support their data management strategy and business objectives. Computer Vision Use Cases of Data Lakes Data lakes are pivotal in powering computer vision applications across various industries by providing a scalable repository for storing and analyzing vast large image and video datasets in real-time. Here are some compelling use cases where data lakes improve computer vision applications: Healthcare: Medical Imaging and Diagnosis In healthcare, data lakes store vast collections of medical images (e.g., X-rays, MRIs, CT scans, PET) that, combined with data curation tools, can improve image quality, detect anomalies, and provide quantitative assessments. CV algorithms analyze these images in real time to diagnose diseases, monitor treatment progress, and plan surgeries. Case Study: Viz.ai uses artificial intelligence to speed care and improve patient outcomes. In this case study, learn how they ingest, annotate, curate, and consume medical data. Autonomous Vehicles: Navigation and Safety Autonomous vehicle developers use data lakes to ingest and curate diverse datasets from vehicle sensors, including cameras, LiDAR, and radar. This data is crucial for training computer vision algorithms that enable autonomous driving capabilities, such as object detection, automated curb management, traffic sign recognition, and pedestrian tracking. Case Study: Automotus builds real-time curbside management automation solutions. Learn how they ingested raw, unlabeled data into Encord via Annotate and curated a balanced, diverse dataset with Active in this case study. How Automotus increased mAP 20% by reducing their dataset size by 35% with visual data curation Agriculture: Precision Farming In the agricultural sector, data lakes store and curate visual data (images and videos) captured by drones or satellites over farmland. Computer vision techniques analyze this data to assess crop health, identify pest infestations, and evaluate water usage, so farmers can make informed decisions and apply treatments selectively. Case Study: Automated harvesting and analytics company Four Growers uses Encord’s platform and annotators to help build its training datasets from scratch, labeling millions of instances of greenhouses and plants. Learn how the platform has halved the time it takes for them to build training data in this case study. Security and Surveillance: Threat Detection Government and private security agencies use data lakes to compile video feeds from CCTV cameras in public spaces, airports, and critical infrastructure. Real-time analysis with computer vision helps detect suspicious activities, unattended objects, and unauthorized entries, triggering immediate responses to potential security threats. ML Team's Data Lake Guide: Key Takeaways Data lakes have become essential for scalable storage and processing of diverse data types in modern data management. They facilitate advanced analytics, including real-time applications like computer vision. Their ability to transform sectors ranging from finance to agriculture by enhancing operational efficiencies and providing actionable insights makes them invaluable. As we look ahead: The continuous evolution of data lake architectures, especially within cloud-native and multi-cloud contexts, promises to bring forth advanced tools and services for improved data handling. This progression presents an opportunity for enterprises to transition from viewing data lakes merely as data repositories to leveraging them as strategic assets capable of building advanced CV applications. To maximize data lakes, address the problems associated with data governance, security, and quality. This will ensure that data remains a valuable organizational asset and a catalyst for data-driven decision-making and strategy formulation.

Dimensionality reduction is a fundamental technique in machine learning (ML) that simplifies datasets by reducing the number of input variables or features. This simplification is crucial for enhancing computational efficiency and model performance, especially as datasets grow in size and complexity. High-dimensional datasets, often comprising hundreds or thousands of features, introduce the "curse of dimensionality." This effect slows down algorithms by making data scarceness (sparsity) and computing needs grow exponentially. Dimensionality reduction changes the data into a simpler, lower-dimensional space that is easier to work with while keeping its main features. This makes computation easier and lowers the risk of overfitting. This strategy is increasingly indispensable in the era of big data, where managing vast volumes of information is a common challenge. This article provides insight into various approaches, from classical methods like principal component analysis (PCA) and linear discriminant analysis (LDA) to advanced techniques such as manifold learning and autoencoders. Each technique has benefits and works best with certain data types and ML problems. This shows how flexible and different dimensionality reduction methods are for getting accurate and efficient model performance when dealing with high-dimensional data. Here are the Twelve (12) techniques you will learn in this article: Manifold Learning (t-SNE, UMAP) Principal Component Analysis (PCA) Independent Component Analysis (ICA) Sequential Non-negative Matrix Factorization (NMF) Linear Discriminant Analysis (LDA) Generalized Discriminant Analysis (GDA) Missing Values Ratio (MVR): Threshold Setting Low Variance Filter High Correlation Filter Forward Feature Construction Backward Feature Elimination Autoencoders Classification of Dimensionality Reduction Techniques Dimensionality reduction techniques preserve important data, make it easier to use in other situations, and speed up learning. They do this using two steps: feature selection, which preserves the most important variables, and feature projection, which creates new variables by combining the original ones in a big way. Feature Selection Techniques Techniques classified under this category can identify and retain the most relevant features for model training. This approach helps reduce complexity and improve interpretability without significantly compromising accuracy. They are divided into: Embedded Methods: These integrate feature selection within model training, such as LASSO (L1) regularization, which reduces feature count by applying penalties to model parameters and feature importance scores from Random Forests. Filters: These use statistical measures to select features independently of machine learning models, including low-variance filters and correlation-based selection methods. More sophisticated filters involve Pearson’s correlation and Chi-Squared tests to assess the relationship between each feature and the target variable. Wrappers: These assess different feature subsets to find the most effective combination, though they are computationally more demanding. Feature Projection Techniques Feature projection transforms the data into a lower-dimensional space, maintaining its essential structures while reducing complexity. Key methods include: Manifold Learning (t-SNE, UMAP). Principal Component Analysis (PCA). Kernel PCA (K-PCA). Linear Discriminant Analysis (LDA). Quadratic Discriminant Analysis (QDA). Generalized Discriminant Analysis (GDA). 1. Manifold Learning Manifold learning, a subset of non-linear dimensionality reduction techniques, is designed to uncover the intricate structure of high-dimensional data by projecting it into a lower-dimensional space. Understanding Manifold Learning At the heart of Manifold Learning is that while data may exist in a high-dimensional space, the intrinsic dimensionality—representing the true degrees of freedom within the data—is often much lower. For example, images of faces, despite being composed of thousands of pixels (high-dimensional data points), might be effectively described with far fewer dimensions, such as the angles and distances between key facial features. Core Techniques and Algorithms t-Distributed Stochastic Neighbor Embedding (t-SNE): t-SNE is powerful for visualizing high-dimensional data in two or three dimensions. It converts similarities between data points to joint probabilities and minimizes the divergence between them in different spaces, excelling in revealing clusters within data. Uniform Manifold Approximation and Projection (UMAP): UMAP is a relatively recent technique that balances the preservation of local and global data structures for superior speed and scalability. It's computationally efficient and has gained popularity for its ability to handle large datasets and complex topologies. Isomap (Isometric Mapping): Isomap extends classical Multidimensional Scaling (MDS) by incorporating geodesic distances among points. It's particularly effective for datasets where the manifold (geometric surface) is roughly isometric to a Euclidean space, allowing global properties to be preserved. Locally Linear Embedding (LLE): LLE reconstructs high-dimensional data points from their nearest neighbors, assuming the manifold is locally linear. By preserving local relationships, LLE can unfold twisted or folded manifolds. t-SNE and UMAP are two of the most commonly applied dimensionality reduction techniques. At Encord, we use UMAP to generate the 2D embedding plots in Encord Active. 2. Principal Component Analysis (PCA) The Principal Component Analysis (PCA) algorithm is a method used to reduce the dimensionality of a dataset while preserving as much information (variance) as possible. As a linear reduction method, PCA transforms a complex dataset with many variables into a simpler one that retains critical trends and patterns. What is variance? Variance measures the data spread around the mean, and features with low variance indicate little variation in their values. These features often need to be more formal for subsequent analysis and can hinder model performance. What is Principal Component Analysis (PCA)? PCA identifies and uses the principal components (directions that maximize variance and are orthogonal to each other) to effectively project data into a lower-dimensional space. This process begins with standardizing the original variables, ensuring their equal contribution to the analysis by normalizing them to have a zero mean and unit variance. Step-by-Step Explanation of Principal Component Analysis Standardization: Normalize the data so each variable contributes equally, addressing PCA's sensitivity to variable scales. Covariance Matrix Computation: Compute the covariance matrix to understand how the variables of the input dataset deviate from the mean and to see if they are related (i.e., correlated). Finding Eigenvectors and Eigenvalues: Find the new axes (eigenvectors) that maximize variance (measured by eigenvalues), making sure they are orthogonal to show that variance can go in different directions. Sorting and Ranking: Prioritize eigenvectors (and thus principal components) by their ability to capture data variance, using eigenvalues as the metric of importance. Feature Vector Formation: Select a subset of eigenvectors based on their ranking to form a feature vector. This subset of eigenvectors forms the principal components. Transformation: Map the original data into this principal component space, enabling analysis or further machine learning in a more tractable, less noisy space. Dimensionality reduction using PCA Applications PCA is widely used in exploratory data analysis and predictive modeling. It is also applied in areas like image compression, genomics for pattern recognition, and financial data for uncovering latent patterns and correlations. PCA can help visualize complex datasets by reducing data dimensionality. It can also make machine learning algorithms more efficient by reducing computational costs and avoiding overfitting with high-dimensional data. 3. Independent Component Analysis (ICA) Independent Component Analysis (ICA) is a computational method in signal processing that separates a multivariate signal into additive, statistically independent subcomponents. Statistical independence is critical because Gaussian variables maximize entropy given a fixed variance, making non-Gaussianity a key indicator of independence. Originating from the work of Hérault and Jutten in 1985, ICA excels in applications like the "cocktail party problem," where it isolates distinct audio streams amid noise without prior source information. Example of the cocktail party problem The cocktail party problem involves separating original sounds, such as music and voice, from mixed signals recorded by two microphones. Each microphone captures a different combination of these sounds due to its varying proximity to the sound sources. ICA is distinct from methods like PCA because it focuses on maximizing statistical independence between components rather than merely de-correlating them. Principles Behind Independent Component Analysis The essence of ICA is its focus on identifying and separating independent non-Gaussian signals embedded within a dataset. It uses the fact that these signals are statistically independent and non-Gaussian to divide the mixed signals into separate parts from different sources. This demixing process is pivotal, transforming seemingly inextricable data (impossible to separate) into interpretable components. Two main strategies for defining component independence in ICA are the minimization of mutual information and non-Gaussianity maximization. Various algorithms, such as infomax, FastICA, and kernel ICA, implement these strategies through measures like kurtosis and negentropy. Algorithmic Process To achieve its goals, ICA incorporates several preprocessing steps: Centering adjusts the data to have a zero mean, ensuring that analyses focus on variance rather than mean differences. Whitening transforms the data into uncorrelated variables, simplifying the subsequent separation process. After these steps, ICA applies iterative methods to separate independent components, and it often uses auxiliary methods like PCA or singular value decomposition (SVD) to lower the number of dimensions at the start. This sets the stage for efficient and robust component extraction. By breaking signals down into basic, understandable parts, ICA provides valuable information and makes advanced data analysis easier, which shows its importance in modern signal processing and beyond. Let’s see some of its applications. Applications of ICA The versatility of ICA is evident across various domains: In telecommunications, it enhances signal clarity amidst interference. Finance benefits from its ability to identify underlying factors in complex market data, assess risk, and detect anomalies. In biomedical signal analysis, it dissects EEG or fMRI data to isolate neurological activity from artifacts (such as eye blinks). 4. Sequential Non-negative Matrix Factorization (NMF) Nonnegative matrix Factorization (NMF) is a technique in multivariate analysis and linear algebra in which a matrix V is factorized into two lower-dimensional matrices, W (basis matrix) and H (coefficient matrix), with the constraint that all matrices involved have no negative elements. This factorization works especially well for fields where the data is naturally non-negative, like genetic expression data or audio spectrograms, because it makes it easy to understand the parts. The primary aim of NMF is to reduce dimensionality and uncover hidden/latent structures in the data. Principle of Sequential Non-negative Matrix Factorization The distinctive aspect of Sequential NMF is its iterative approach to decomposing matrix V into W and H, making it adept at handling time-series data or datasets where the temporal evolution of components is crucial. This is particularly relevant in dynamic datasets or applications where data evolves. Sequential NMF responds to changes by repeatedly updating W and H, capturing changing patterns or features important in online learning, streaming data, or time-series analysis. In text mining, for example, V denotes a term-document matrix over time, where W represents evolving topics and H indicates their significance across different documents or time points. This dynamic representation allows the monitoring of trends and changes in the dataset's underlying structure. Procedure of feature extraction using NMF Applications The adaptability of Sequential NMF has led to its application in a broad range of fields, including: Medical Research: In oncology, Sequential NMF plays a pivotal role in analyzing genetic data over time, aiding in the classification of cancer types, and identifying temporal patterns in biomarker expression. Audio Signal Processing: It is used to analyze sequences of audio signals and capture the temporal evolution of musical notes or speech. Astronomy and Computer Vision: Sequential NMF tracks and analyzes the temporal changes in celestial bodies or dynamic scenes. 5. Linear Discriminant Analysis (LDA) Linear Discriminant Analysis (LDA) is a supervised machine learning technique used primarily for pattern classification, dimensionality reduction, and feature extraction. It focuses on maximizing class separability. Unlike PCA, which optimizes for variance regardless of class labels, LDA aims to find a linear combination of features that separates different classes. It projects data onto a lower-dimensional space using class labels to accomplish this. Imagine, for example, a dataset of two distinct groups of points spread in space; LDA aims to find a projection where these groups are as distinct as possible, unlike PCA, which would look for the direction of highest variance regardless of class distinction. This method is highly efficient in scenarios where the division between categories of data is to be accentuated. PCA Vs. LDA: What's the Difference? Assumptions of LDA Linear Discriminant Analysis (LDA) operates under assumptions essential for effectively classifying observations into predefined groups based on predictor variables. These assumptions, elaborated below, play a critical role in the accuracy and reliability of LDA's predictions. Multivariate Normality: Each class must follow a multivariate normal distribution (multi-dimensional bell curve). You can asses this through visual plots or statistical tests before applying LDA. Homogeneity of Variances (Homoscedasticity): Ensuring uniform variance across groups helps maintain the reliability of LDA's projections. Techniques like Levene's test can assess this assumption. Absence of Multicollinearity: LDA requires predictors to be relatively independent. Techniques like variance inflation factors (VIFs) can diagnose multicollinearity issues. Working Methodology of Linear Discriminant Analysis LDA transforms the feature space into a lower-dimensional one that maximizes class separability by: Calculating mean vectors for each class. Computing within-class and between-class scatter matrices to understand the distribution and separation of classes. Solving for the eigenvalues and eigenvectors that maximize the between-class variance relative to the within-class variance. This defines the optimal projection space to distinguish the classes. Tools like Python's Scikit-learn library simplify applying LDA with functions specifically designed to carry out these steps efficiently. Applications LDA's ability to reduce dimensionality while preserving as much of the class discriminatory information as possible makes it a powerful feature extraction and classification tool applicable across various domains. Examples: In facial recognition, LDA enhances the distinction between individual faces to improve recognition accuracy. Medical diagnostics benefit from LDA's ability to classify patient data into distinct disease categories, aiding in early and accurate diagnosis. In marketing, LDA helps segment customers for targeted marketing campaigns based on demographic and behavioral data. 6. Generalized Discriminant Analysis (GDA) Generalized Discriminant Analysis (GDA) extends linear discriminant analysis (LDA) into a nonlinear domain. It uses kernel functions to project input data vectors into a higher-dimensional feature space to capture complex patterns that LDA, limited to linear boundaries, might miss. These functions project data into a higher-dimensional space where inseparable classes in the original space can be distinctly separated. Step-by-step Explanation of Generalized Discriminant Analysis The core objective of GDA is to find a low-dimensional projection that maximizes the between-class scatter while minimizing the within-class scatter in the high-dimensional feature space. Let’s examine the GDA algorithm step by step: 1. Kernel Function Selection: First, choose an appropriate kernel function (e.g., polynomial, radial basis function (RBF)) that transforms the input data into a higher-dimensional space. 2. Kernel Matrix Computation: Compute the kernel matrix K, representing the high-dimensional dot products between all pairs of data points. This matrix is central to transforming the data into a feature space without explicitly performing the computationally expensive mapping. 3. Scatter Matrix Calculation in Feature Space: In the feature space, compute the within-class scatter matrix SW and the between-class scatter matrix SB, using the kernel matrix K to account for the data's nonlinear transformation. 4. Eigenvalue Problem: Solving this problem in the feature space identifies the projection vectors that best separate the classes by maximizing the SB/SW ratio. This step is crucial for identifying the most informative projections for class separation. 5. Projection: Use the obtained eigenvectors to project the input data onto a lower-dimensional space that maximizes class separability to achieve GDA's goal of improved class recognition. Applications GDA has been applied in various domains, benefiting from its ability to handle nonlinear patterns: Image and Video Recognition: GDA is used for facial recognition, object detection, and activity recognition in videos, where the data often exhibit complex, nonlinear relationships. Biomedical Signal Processing: In analyzing EEG, ECG signals, and other biomedical data, GDA helps distinguish between different physiological states or diagnose diseases. Text Classification and Sentiment Analysis: GDA transforms text data into a higher-dimensional space, effectively separating documents or sentiments that are not linearly separable in the original feature space. 7. Missing Values Ratio (MVR): Threshold Setting Datasets often contain missing values, which can significantly impact the effectiveness of dimensionality reduction techniques. One approach to addressing this challenge is to utilize a missing values ratio (MVR) thresholding technique for feature selection. Process of Setting Threshold for Missing Values The MVR for a feature is calculated as the percentage of missing values for data points. The optimal threshold is dependent on several factors, including the dataset’s nature and the intended analysis: Determining the Threshold: Use statistical analyses, domain expertise, and exploratory data analysis (e.g., histograms of missing value ratios) to identify a suitable threshold. This decision balances retaining valuable data against excluding features that could introduce bias or noise. Implications of Threshold Settings: A high threshold may retain too many features with missing data, complicating the analysis. Conversely, a low threshold could lead to excessive data loss. Regularly, thresholds between 20% to 60% are considered, but this range varies widely based on the data context and analysis goals. Contextual Considerations: The dataset's specific characteristics and the chosen dimensionality reduction technique influence the threshold setting. Methods sensitive to data sparsity or noise may require a lower MVR threshold. Example: In a dataset with 100 observations, a feature with 75 missing values has an MVR of 75%. If the threshold is set at 70%, this feature would be considered for removal. Applications High-throughput Biological Data Analysis: Technical limitations often render Gene expression data incomplete. Setting a conservative MVR threshold may preserve crucial biological insights by retaining genes with marginally incomplete data. Customer Data Analysis: Customer surveys may have varying completion rates across questions. MVR thresholding identifies which survey items provide the most complete and reliable data, sharpening customer insights. Social Media Analysis: Social media data can be sparse, with certain users' entries missing. MVR thresholding can help select informative features for user profiling or sentiment analysis. 8. Low Variance Filter A low variance filter is a straightforward preprocessing technique aimed at reducing dimensionality by eliminating features with minimal variance, focusing analysis on more informative aspects of the dataset. Steps for Implementing a Low Variance Filter Calculate Variance: For each feature in the dataset, compute the variance. Prioritize scaling or normalizing data to ensure variance is measured on a comparable basis across all features. Set Threshold: Define a threshold for the minimum acceptable variance. This threshold often depends on the specific dataset and analysis objectives but typically ranges from a small percentage of the total variance observed across features. Feature Selection: Exclude features with variances below the threshold. Tools like Python's `pandas` library or R's `caret` package can efficiently automate this process. Applications of Low Variance Filter Across Domains Sensor Data Analysis: Sensor readings might exhibit minimal fluctuation over time, leading to features with low variance. Removing these features can help focus on the sensor data's more dynamic aspects. Image Processing: Images can contain features representing background noise. These features often have low variance and can be eliminated using the low variance filter before image analysis. Text Classification: Text data might contain stop words or punctuation marks that offer minimal information for classification. The low variance filter can help remove such features, improving classification accuracy. 9. High Correlation Filter The high correlation filter is a crucial technique for addressing feature redundancy. Eliminating highly correlated features optimizes datasets for improved model accuracy and efficiency. Steps for Implementing a High Correlation Filter Compute Correlation Matrix: Assess the relationship between all feature pairs using an appropriate correlation coefficient, such as Pearson for continuous features (linear relationships) and Spearman for ordinal (monotonic relationships). Define Threshold: Establish a correlation coefficient threshold above highly correlated features. A common threshold of 0.8 or 0.9 may vary based on specific model requirements and data sensitivity. Feature Selection: Identify sets of features whose correlation exceeds the threshold. From each set, retain only one feature based on criteria like predictive power, data completeness, or domain relevance and remove the others. Applications Financial Data Analysis: Stock prices or other financial metrics might exhibit a high correlation, often reflecting market trends. The high correlation filter can help select a representative subset of features for financial modeling. Bioinformatics: Gene expression data can involve genes with similar functions, leading to high correlation. Selecting a subset of uncorrelated genes can be beneficial for identifying distinct biological processes. Recommendation Systems: User profiles often contain correlated features like similar purchase history or browsing behavior. The high correlation filter can help select representative features to build more efficient recommendation models. While the Low Variance Filter method removes features with minimal variance, discarding data points that likely don't contribute much information, the High Correlation Filter approach identifies and eliminates highly correlated features. This process is crucial because two highly correlated features carry similar information, increasing redundancy within the model. 10. Forward Feature Construction Forward Feature Construction (FFC) is a methodical approach to feature selection, designed to incrementally build a model by adding features that offer the most significant improvement. This technique is particularly effective when the relationship between features and the target variable is complex and needs to be fully understood. Algorithm for Forward Feature Construction Initiate with a Null Model: Start with a baseline model without any predictors to establish a performance benchmark. Evaluation Potential Additions: For each candidate feature outside the model, assess potential performance improvements by adding that feature. Select the Best Feature: Incorporate the feature that significantly improves performance. Ensure the model remains interpretable and manageable. Iteration: Continue adding features until further additions fail to offer significant gains, considering computational efficiency and the risk of diminishing returns. Practical Considerations and Implementation Performance Metrics: To gauge improvements, use appropriate metrics, such as the Akaike Information Criterion (AIC) for regression or accuracy and the F1 score for classification, adapting the choice of metric to the model's context. Challenges: Be mindful of computational demands and the potential for multicollinearity. Implementing strategies to mitigate these risks, such as pre-screening features or setting a cap on the number of features, can be crucial. Tools: Leverage software tools and libraries (e.g., R's `stepAIC` or Python's `mlxtend.SequentialFeatureSelector`) that support efficient FFC application and streamline feature selection. Applications of FFC Across Domains Clinical Trials Prediction: In clinical research, FFC facilitates the identification of the most predictive biomarkers or clinical variables from a vast dataset, optimizing models for outcome prediction. Financial Modeling: In financial market analysis, this method distills a complex set of economic indicators down to a core subset that most accurately forecasts market movements or financial risk. 11. Backward Feature Elimination Backward Feature Elimination (BFE) systematically simplifies machine learning models by iteratively removing the least critical features, starting with a model that includes the entire set of features. This technique is particularly suited for refining linear and logistic regression models, where dimensionality reduction can significantly improve performance and interpretability. Algorithm for Backward Feature Elimination Initialize with Full Model: Construct a model incorporating all available features to establish a comprehensive baseline. Identify and Remove Least Impactful Feature: Determine the feature whose removal least affects or improves the model's predictive performance. Use metrics like p-values or importance scores to eliminate it from the model. Performance Evaluation: After each removal, assess the model to ensure performance remains robust. Utilize cross-validation or similar methods to validate performance objectively. Iterative Optimization: Continue this evaluation and elimination process until further removals degrade model performance, indicating that an optimal feature subset has been reached. Learn how to validate the performance of your ML model in this guide to validation model performance with Encord Active. Practical Considerations for Implementation Computational Efficiency: Given the potentially high computational load, especially with large feature sets, employ strategies like parallel processing or stepwise evaluation to simplify the Backward Feature Elimination (BFE) process. Complex Feature Interactions: Special attention is needed when features interact or are categorical. Consider their relationships to avoid inadvertently removing significant predictors. Applications Backward Feature Elimination is particularly useful in contexts like: Genomics: In genomics research, BFE helps distill large datasets into a manageable number of significant genes to improve understanding of genetic influences on diseases. High-dimensional Data Analysis: BFE simplifies complex models in various fields, from finance to the social sciences, by identifying and eliminating redundant features. This could reduce overfitting and improve the model's generalizability. While Forward Feature Construction is beneficial for gradually building a model by adding one feature at a time, Backward Feature Elimination is advantageous for models starting with a comprehensive set of features and needing to identify redundancies. 12. Autoencoders Autoencoders are a unique type of neural network used in deep learning, primarily for dimensionality reduction and feature learning. They are designed to encode inputs into a compressed, lower-dimensional form and reconstruct the output as closely as possible to the original input. This process emphasizes the encoder-decoder structure. The encoder reduces the dimensionality, and the decoder attempts to reconstruct the input from this reduced encoding. How Does Autoencoders Work? They achieve dimensionality reduction and feature learning by mimicking the input data through encoding and decoding. 1. Encoding: Imagine a bottle with a narrow neck in the middle. The data (e.g., an image) is the input that goes into the wide top part of the bottle. The encoder acts like this narrow neck, compressing the data into a smaller representation. This compressed version, often called the latent space representation, captures the essential features of the original data. The encoder is typically made up of multiple neural network layers that gradually reduce the dimensionality of the data. The autoencoder learns to discard irrelevant information and focus on the most important characteristics by forcing the data through this bottleneck. 2. Decoding: Now, imagine flipping the bottle upside down. The decoder acts like the wide bottom part, trying to recreate the original data from the compressed representation that came through the neck. The decoder also uses multiple neural network layers, but this time, it gradually increases the data's dimensionality, aiming to reconstruct the original input as accurately as possible. Variants and Advanced Applications Sparse Autoencoders: Introduce regularization terms to enforce sparsity in the latent representation, enhancing feature selection. Denoising Autoencoders: Specifically designed to remove noise from data, these autoencoders learn to recover clean data from noisy inputs, offering superior performance in image and signal processing tasks. Variational Autoencoders (VAEs): VAEs make new data samples possible by treating the latent space as a probabilistic distribution. This opens up new ways to use generative modeling. Training Nuances Autoencoders use optimizers like Adam or stochastic gradient descent (SGD) to improve reconstruction accuracy by improving their weights through backpropagation. Overfitting prevention is integral and can be addressed through methods like dropout, L1/L2 regularization, or a validation set for early stopping. Applications Autoencoders have a wide range of applications, including but not limited to: Dimensionality Reduction: Similar to PCA but more powerful (as non-linear alternatives), autoencoders can perform non-linear dimensionality reductions, making them particularly useful for preprocessing steps in machine learning pipelines. Image Denoising: By learning to map noisy inputs to clean outputs, denoising autoencoders can effectively remove noise from images, surpassing traditional denoising methods in efficiency and accuracy. Generative modeling: Variational autoencoders (VAEs) can make new data samples similar to the original input data by modeling the latent space as a continuous probability distribution. (e.g., Generative Adversarial Networks (GANs)). Impact of Dimensionality Reduction in Smart City Solutions Automotus is a company at the forefront of using AI to revolutionize smart city infrastructure, particularly traffic management. They achieve this by deploying intelligent traffic monitoring systems that capture vast amounts of video data from urban environments. However, efficiently processing and analyzing this high-dimensional data presents a significant challenge. This is where dimensionality reduction techniques come into play. The sheer volume of video data generated by Automotus' traffic monitoring systems necessitates dimensionality reduction techniques to make data processing and analysis manageable. PCA identifies the most significant features in the data (video frames in this case) and transforms them into a lower-dimensional space while retaining the maximum amount of variance. This allows Automotus to extract the essential information from the video data, such as traffic flow patterns, vehicle types, and potential congestion points, without analyzing every pixel. Partnering with Encord, Automotus led to a 20% increase in model accuracy and a 35% reduction in dataset size. This collaboration focused on dimensionality reduction, leveraging Encord Annotate’s flexible ontology, quality control capabilities, and automated labeling features. That approach helped Automotus reduce infrastructure constraints, improve model performance to provide better data to clients, and reduce labeling costs. Efficiency directly contributes to Automotus's business growth and operational scalability. The team used Encord Active to visually inspect, query, and sort their datasets to remove unwanted and poor-quality data with just a few clicks, leading to a 35% reduction in the size of the datasets for annotation. This enabled the team to cut their labeling costs by over a third. Interested in learning more? Read the full story on Encord's website for more details. Dimensionality Reduction Technique: Key Takeaways Dimensionality reduction techniques simplify models and enhance computational efficiency. They help manage the "curse of dimensionality," improving model generalizability and reducing overfitting risk. These techniques are used for feature selection and extraction, contributing to better model performance. They are applied in various fields, such as image and speech recognition, financial analysis, and bioinformatics, showcasing their versatility. By reducing the number of input variables, these methods ensure models are computationally efficient and capture essential data patterns for more accurate predictions.

In computer vision, you cannot overstate the importance of data quality. It directly affects how accurate and reliable your models are. This guide is about understanding why high-quality data matters in computer vision and how to improve your data quality. We will explore the essential aspects of data quality and its role in model accuracy and reliability. We will discuss the key steps for improving quality, from selecting the right data to detecting outliers. We will also see how Encord Active helps us do all this to improve our computer vision models. This is an in-depth guide; feel free to use the table of contents on the left to navigate each section and find one that interests you. By the end, you’ll have a solid understanding of the essence of data quality for computer vision projects and how to improve it to produce high-quality models. Let’s dive right into it! Introduction to Data Quality in Computer Vision Defining the Attributes of High-Quality Data High-quality data includes several attributes that collectively strengthen the robustness of computer vision models: Accuracy: Precision in reflecting real-world objects is vital; inaccuracies can lead to biases and diminished performance. Consistency: Uniformity in data, achieved through standardization, prevents conflicts and aids effective generalization. Data Diversity: By incorporating diverse data, such as different perspectives, lighting conditions, and backgrounds, you enhance the model's adaptability, making it resilient to potential biases and more adept at handling unforeseen challenges. Relevance: Data curation should filter irrelevant data, ensuring the model focuses on features relevant to its goals. Ethical Considerations: Data collected and labeled ethically, without biases, contributes to responsible and fair computer vision models. By prioritizing these data attributes, you can establish a strong foundation for collecting and preparing quality data for your computer vision projects. Next, let's discuss the impact of these attributes on model performance. Impact of Data Quality on Model Performance Here are a few aspects of high-quality data that impact the model's performance: Accuracy Improvement: Curated and relevant datasets could significantly improve model accuracy. Generalization Capabilities: High-quality data enables models to apply learned knowledge to new, unseen scenarios. Increased Model Robustness: Robust models are resilient to variations in input conditions, which is perfect for production applications. As we explore enhancing data quality for training computer vision models, it's essential to underscore that investing in data quality goes beyond mere accuracy. It's about constructing a robust and dependable system. By prioritizing clean, complete, diverse, and representative data, you establish the foundation for effective models. Considerations for Training Computer Vision Models Training a robust computer vision model hinges significantly on the training data's quality, quantity, and labeling. Here, we explore the key considerations for training CV models: Data Quality The foundation of a robust computer vision model rests on the quality of its training data. Data quality encompasses the accuracy, completeness, reliability, and relevance of the information within the dataset. Addressing missing values, outliers, and noise is crucial to ensuring the data accurately reflects real-world scenarios. Ethical considerations, like unbiased representation, are also paramount in curating a high-quality dataset. Data Diversity Data diversity ensures that the model encounters many scenarios. Without diversity, models risk being overly specialized and may struggle to perform effectively in new or varied environments. By ensuring a diverse dataset, models can better generalize and accurately interpret real-world situations, improving their robustness and reliability. Data Quantity While quality takes precedence, an adequate volume of data is equally vital for comprehensive model training. Sufficient data quantity contributes to the model's ability to learn patterns, generalize effectively, and adapt to diverse situations. The balance of quality and quantity ensures a holistic learning experience for the model, enabling it to navigate various scenarios. It's also important to balance the volume of data with the model's capacity and computational efficiency to avoid issues like overfitting and unnecessary computational load. Label Quality The quality of its labels greatly influences the precision of a computer vision model. Consistent and accurate labeling with sophisticated annotation tools is essential for effective training. Poorly labeled data can lead to biases and inaccuracies, undermining the model's predictive capabilities. Read How to Choose the Right Data for Your Computer Vision Project to learn more about it. Data Annotation Tool A reliable data annotation tool is equally essential to ensuring high-quality data. These tools facilitate the labeling of images, improving the quality of the data. By providing a user-friendly interface, efficient workflows, and diverse annotation options, these tools streamline the process of adding valuable insights to the data. Properly annotated data ensures the model receives accurate ground truth labels, significantly contributing to its learning process and overall performance. Selecting the Right Data for Your Computer Vision Projects The first step in improving data quality is data curation. This process involves defining criteria for data quality and establishing mechanisms for sourcing reliable datasets. Here are a few key steps to follow when selecting the data for your computer vision project: Criteria for Selecting Quality Data The key criteria for selecting high-quality data include: Accuracy: Data should precisely reflect real-world scenarios to avoid biases and inaccuracies. Completeness: Comprehensive datasets covering diverse situations are crucial for generalization. Consistency: Uniformity in data format and preprocessing ensures reliable model performance. Timeliness: Regular updates maintain relevance, especially in dynamic or evolving environments. Evaluating and Sourcing Reliable Data The process of evaluating and selecting reliable data involves: Quality Metrics: Validating data integrity through comprehensive quality metrics, ensuring accuracy, completeness, and consistency in the dataset. Ethical Considerations: Ensuring data is collected and labeled ethically without introducing biases. Source Reliability: Assessing and selecting trustworthy data sources to mitigate potential biases. Case Studies: Improving Data Quality Improved Model Performance by 20% When faced with challenges managing and converting vast amounts of images into labeled training data, Autonomous turned to Encord. The flexible ontology structure, quality control capabilities, and automated labeling features of Encord were instrumental in overcoming labeling obstacles. The result was twofold: improved model performance and economic efficiency. With Encord, Autonomous efficiently curated and reduced the dataset by getting rid of data that was not useful. This led to a 20% improvement in mAP (mean Average Precision), a key metric for measuring the accuracy of object detection models. This was not only effective in addressing the accuracy of the model but also in reducing labeling costs. Efficient data curation helped prioritize which data to label, resulting in a 33% reduction in labeling costs. Thus, improving the accuracy of the models enhanced the quality of the data that Autonomous delivered to its customers. Read the case study on how Automotus increased mAP by 20% by reducing their dataset size by 35% with visual data curation to learn more about it. Following data sourcing, the next step involves inspecting the quality of the data. Let's learn how to explore data quality with Encord Active. Exploring Data Quality using Encord Active Encord Active provides a comprehensive set of tools to evaluate and improve the quality of your data. It uses quality metrics to assess the quality of your data, labels, and model predictions. Data Quality Metrics analyzes your images, sequences, or videos. These metrics are label-agnostic and depend only on the image content. Examples include image uniqueness, diversity, area, brightness, sharpness, etc. Label Quality Metrics operates on image labels like bounding boxes, polygons, and polylines. These metrics can help you sort data, filter it, find duplicate labels, and understand the quality of your annotations. Examples include border proximity, broken object tracks, classification quality, label duplicates, object classification quality, etc. Read How to Detect Data Quality Issues in a Torchvision Dataset Using Encord Active for a more comprehensive insight. In addition to the metrics that ship with Encord Active, you can define custom quality metrics for indexing your data. This allows you to customize the evaluation of your data according to your specific needs. Here's a step-by-step guide to exploring data quality through Encord Active: Create an Encord Active Project Initiating your journey with Encord Active begins with creating a project in Annotate, setting the foundation for an efficient and streamlined data annotation process. Follow these steps for a curation workflow from Annotate to Active: Create a Project in Annotate. Add an existing dataset or create your dataset. Set up the ontology of the annotation project. Customize the workflow design to assign tasks to annotators and for expert review. Start the annotation process! Read the documentation to learn how to create your annotation project on Encord Annotate. Import Encord Active Project Once you label a project in Annotate, transition to Active by clicking Import Annotate Project. Read the documentation to learn how to import your Encord Annotate project to Encord Active Cloud. Using Quality Metrics After choosing your project, navigate to Filter on the Explorer page >> Choose a Metric from the selection of data quality metrics to visually analyze the quality of your dataset. Great! That helps you identify potential issues such as inconsistencies, outliers, etc., which helps make informed decisions regarding data cleaning. Guide to Data Cleaning Data cleaning involves identifying and rectifying errors, inconsistencies, and inaccuracies in datasets. This critical phase ensures that the data used for computer vision projects is reliable, accurate, and conducive to optimal model performance. Understanding Data Cleaning and Its Benefits Data cleaning involves identifying and rectifying data errors, inconsistencies, and inaccuracies. The benefits include: Improved Data Accuracy: By eliminating errors and inconsistencies, data cleaning ensures that the dataset accurately represents real-world phenomena, leading to more reliable model outcomes. Increased Confidence in Model Results: A cleaned dataset instills confidence in the reliability of model predictions and outputs. Better Decision-Making Based on Reliable Data: Organizations can make better-informed decisions to build more reliable AI. Read How to Clean Data for Computer Vision to learn more about it. Selecting the right tool is essential for data cleaning tasks. In the next section, you will see criteria for selecting data cleaning tools to automate repetitive tasks and ensure thorough and efficient data cleansing. Selecting a Data Cleaning Tool Some criteria for selecting the right tools for data cleaning involve considering the following: Diversity in Functionality: Assess whether the tool specializes in handling specific data issues such as missing values or outlier detections. Understanding the strengths and weaknesses of each tool enables you to align them with the specific requirements of their datasets. Scalability and Performance: Analyzing the performance of tools in terms of processing speed and resource utilization helps in selecting tools that can handle the scale of the data at hand efficiently. User-Interface and Accessibility: Tools with intuitive interfaces and clear documentation streamline the process, reducing the learning curve. Compatibility and Integration: Compatibility with existing data processing pipelines and integration capabilities with popular programming languages and platforms are crucial. Seamless integration ensures a smooth workflow, minimizing disruptions during the data cleaning process. Once a suitable data cleaning tool is selected, understanding and implementing best practices for effective data cleaning becomes imperative. These practices ensure you can optimally leverage the tool you choose to achieve desired outcomes. Best Practices for Effective Data Cleaning Adhering to best practices is essential for ensuring the success of the data cleaning process. Some key practices include: Data Profiling: Understand the characteristics and structure of the data before initiating the cleaning process. Remove Duplicate and Irrelevant Data: Identify and eliminate duplicate or irrelevant images/videos to ensure data consistency and improve model training efficiency. Anomaly Detection: Utilize anomaly detection techniques to identify outliers or anomalies in image/video data, which may indicate data collection or processing errors. Documentation: Maintain detailed documentation of the cleaning process, including the steps taken and the rationale behind each decision. Iterative Process: Treat data cleaning as an iterative process, revisiting and refining as needed to achieve the desired data quality. For more information, read Mastering Data Cleaning & Data Preprocessing. Overcoming Challenges in Image and Video Data Cleaning Cleaning image and video data presents unique challenges compared to tabular data. Issues such as noise, artifacts, and varying resolutions require specialized techniques. These challenges need to be addressed using specialized tools and methodologies to ensure the accuracy and reliability of the analyses. Visual Inspection Tools: Visual data often contains artifacts, noise, and anomalies that may not be immediately apparent in raw datasets. Utilizing tools that enable visual inspection is essential. Platforms allowing users to view images or video frames alongside metadata provide a holistic understanding of the data. Metric-Based Cleaning: Implementing quantitative metrics is equally vital for effective data cleaning. You can use metrics such as image sharpness, color distribution, blur, and object recognition accuracy to identify and address issues. Tools that integrate these metrics into the cleaning process automate the identification of outliers and abnormalities, facilitating a more objective approach to data cleaning. Using tools and libraries streamlines the cleaning process and contributes to improved insights and decision-making based on high-quality visual data. Watch the webinar From Data to Diamonds: Unearth the True Value of Quality Data to learn how tools help. Using Encord Active to Clean the Data Let’s take an example of the COCO 2017 dataset imported to Encord Active. Upon analyzing the dataset, Encord Active highlights both severe and moderate outliers. While outliers bear significance, maintaining a balance is crucial. Using Filter, Encord Active empowers users to visually inspect outliers and make informed decisions regarding their inclusion in the dataset. Taking the Area metric as an example, it reveals numerous severe outliers. We identify 46 low-resolution images with filtering, potentially hindering effective training for object detection. Consequently, we can select the dataset, click Add to Collection, remove these images from the dataset, or export them for cleaning with a data preprocessing tool. Encord Active facilitates visual and analytical inspection, allowing users to detect datasets for optimal preprocessing. This iterative process ensures the data is of good quality for the model training stage and improves performance on computer vision tasks. Watch the webinar Big Data to Smart Data Webinar: How to Clean and Curate Your Visual Datasets for AI Development to learn how to use tools to efficiently curate your data.. Case Studies: Optimizing Data Cleaning for Self-Driving Cars with Encord Active Encord Active (EA) streamlines the data cleaning process for computer vision projects by providing quality metrics and visual inspection capabilities. In a practical use case involving managing and curating data for self-driving cars, Alex, a DataOps manager at self-dr-AI-ving, uses Encord Active's features, such as bulk classification, to identify and curate low-quality annotations. These functionalities significantly improve the data curation process. The initial setup involves importing images into Active, where the magic begins. Alex organizes data into collections, an example being the "RoadSigns" Collection, designed explicitly for annotating road signs. Alex then bulk-finds traffic sign images using the embeddings and similarity search. Alex then clicks Add to a Collection, then Existing Collection, and adds the images to the RoadSigns Collection. Alex categorizes the annotations for road signs into good and bad quality, anticipating future actions like labeling or augmentation. Alex sends the Collection of low-quality images to a new project in Encord Annotate to re-label the images. After completing the annotation, Alex syncs the Project data with Active. He heads back to the dashboard and uses the model prediction analytics to gain insights into the quality of annotations. Encord Active's integration and efficient workflows empower Alex to focus on strategic tasks, providing the self-driving team with a streamlined and improved data cleaning process that ensures the highest data quality standards. Data Preprocessing What is Data Preprocessing? Data preprocessing transforms raw data into a format suitable for analysis. In computer vision, this process involves cleaning, organizing, and using feature engineering to extract meaningful information or features. Feature engineering helps algorithms better understand and represent the underlying patterns in visual data. Data preprocessing addresses missing values, outliers, and inconsistencies, ensuring that the image or video data is conducive to accurate analyses and optimal model training. Data Cleaning Vs. Data Preprocessing: The Difference Data cleaning involves identifying and addressing issues in the raw visual data, such as removing noise, handling corrupt images, or correcting image errors. This step ensures the data is accurate and suitable for further processing. Data preprocessing includes a broader set of tasks beyond cleaning, encompassing operations like resizing images, normalizing pixel values, and augmenting data (e.g., rotating or flipping images). The goal is to prepare the data for the specific requirements of a computer vision model. Techniques for Robust Data Preprocessing Image Standardization: Adjusting images to a standardized size facilitates uniform processing. Cropping focuses on relevant regions of interest, eliminating unnecessary background noise. Normalization: Scaling pixel values to a consistent range (normalization) and ensuring a standardized distribution enhances model convergence during training. Data Augmentation: Introduces variations in training data, such as rotations, flips, and zooms, and enhances model robustness. Data augmentation helps prevent overfitting and improves the model's generalization to unseen data. Dealing with Missing Data: Addressing missing values in image datasets involves strategies like interpolating or generating synthetic data to maintain data integrity. Noise Reduction: Applying filters or algorithms to reduce image noise, such as blurring or denoising techniques, enhances the clarity of relevant information. Color Space Conversion: Converting images to different color spaces (e.g., RGB to grayscale) can simplify data representation and reduce computational complexity. Now that we've laid the groundwork with data preprocessing, let's explore how to further elevate model performance through data refinement. Enhancing Models with Data Refinement Unlike traditional model-centric approaches, data refinement represents a paradigm shift, emphasizing nuanced and effective data-centric strategies. This approach empowers practitioners to leverage the full potential of their models through informed data selection and precise labeling, fostering a continuous cycle of improvement. By emphasizing input data refinement, you can develop a dataset that optimally aligns with the model's capabilities and enhances its overall performance. Model-centric vs Data-centric Approaches Model-Centric Approach: Emphasizes refining algorithms and optimizing model architectures. This approach is advantageous in scenarios where computational enhancements can significantly boost performance. Data-Centric Approach: Prioritizes the quality and relevance of training data. It’s often more effective when data quality is the primary bottleneck in achieving higher model accuracy. The choice between these approaches often hinges on the specific challenges of a given task and the available resources for model development. Download the free whitepaper How to Adopt a Data-Centric AI to learn how to make your AI strategy data-centric and improve performance. Data Refinement Techniques: Active Learning and Semi-Supervised Learning Active Learning: It is a dynamic approach that involves iteratively selecting the most informative data points for labeling. For example, image recognition might prioritize images where the model's predictions are most uncertain. This method optimizes labeling efforts and enhances the model's learning efficiency. Semi-Supervised Learning: It tackles scenarios where acquiring labeled data is challenging. This technique combines labeled and unlabeled data for training, effectively harnessing the potential of a broader dataset. For instance, in a facial recognition task, a model can learn general features from a large pool of unlabeled faces and fine-tune its understanding with a smaller set of labeled data. With our focus on refining data for optimal model performance, let's now turn our attention to the task of identifying and addressing outliers to improve the quality of our training data. Improving Training Data with Outlier Detection Outlier detection is an important step in refining machine learning models. Outliers, or abnormal data points, have the potential to distort model performance, making their identification and management essential for accurate training. Understanding Outlier Detection Outliers, or anomalous data points, can significantly impact the performance and reliability of machine learning models. Identifying and handling outliers is crucial to ensuring the training data is representative and conducive to accurate model training. Outlier detection involves identifying data points that deviate significantly from the expected patterns within a dataset. These anomalies can arise due to errors in data collection, measurement inaccuracies, or genuine rare occurrences. For example, consider a scenario where an image dataset for facial recognition contains rare instances with extreme lighting conditions or highly distorted faces. Detecting and appropriately addressing these outliers becomes essential to maintaining the model's robustness and generalization capabilities. Implementing Outlier Detection with Encord Active The outlier detection feature in Encord Active is robust. It can find and label outliers using predefined metrics, custom metrics, label classes, and pre-calculated interquartile ranges. It’s a systematic approach to debugging your data. This feature identifies data points that deviate significantly from established norms. In a few easy steps, you can efficiently detect outliers: Accessing Data Quality Metrics: Navigate to the Analytics > Data tab within Encord Active. Quality metrics offer a comprehensive overview of your dataset. In a practical scenario, a data scientist working on traffic image analysis might use Encord Active to identify and examine atypical images, such as those with unusual lighting conditions or unexpected objects, ensuring these don’t skew the model’s understanding of standard traffic scenes. Read the blog Improving Training Data with Outlier Detection to learn how to use Encord Active for efficient outlier detection. Understanding and Identifying Imbalanced Data Addressing imbalanced data is crucial for developing accurate and unbiased machine learning models. An imbalance in class distribution can lead to models that are skewed towards the majority class, resulting in poor performance in minority classes. Strategies for Achieving Balanced Datasets Resampling Techniques: Techniques like SMOTE for oversampling minority classes or Tomek Links for undersampling majority classes can help achieve balance. Synthetic Data Generation: Using data augmentation or synthetic data generation (e.g., GANs, generative models) to create additional examples for minority classes. Ensemble Methods: Implement ensemble methods that assign different class weights, enabling the model to focus on minority classes during training. Cost-Sensitive Learning: Adjust the misclassification cost associated with minority and majority classes to emphasize the significance of correct predictions for the minority class. When thoughtfully applied, these strategies create balanced datasets, mitigate bias, and ensure models generalize well across all classes. Balancing Datasets Using Encord Active Encord Active can address imbalanced datasets for a fair representation of classes. Its features facilitate an intuitive exploration of class distributions to identify and rectify imbalances. Its functionalities enable class distribution analysis. Automated analysis of class distributions helps you quickly identify imbalance issues based on pre-defined or custom data quality metrics. For instance, in a facial recognition project, you could use Encord Active to analyze the distribution of different demographic groups within the dataset (custom metric). Based on this analysis, apply appropriate resampling or synthetic data generation techniques to ensure a fair representation of all groups. Understanding Data Drift in Machine Learning Models What is Data Drift? Data drift is the change in statistical properties of the data over time, which can degrade a machine learning model's performance. Data drift includes changes in user behavior, environmental changes, or alterations in data collection processes. Detecting and addressing data drift is essential to maintaining a model's accuracy and reliability. Strategies for Detecting and Addressing Data Drift Monitoring Key Metrics: Regularly monitor key performance metrics of your machine learning model. Sudden changes or degradation in metrics such as accuracy, precision, or recall may indicate potential data drift. Using Drift Detection Tools: Tools that utilize statistical methods or ML algorithms to compare current data with training data effectively identify drifts. Retraining Models: Implement a proactive retraining strategy. Periodically update your model using recent and relevant data to ensure it adapts to evolving patterns and maintains accuracy. Continuous Monitoring and Data Feedback: Establish a continuous monitoring and adaptation system. Regularly validate the model against new data and adjust its parameters or retrain it as needed to counteract the effects of data drift. Practical Implementation and Challenges Imagine an e-commerce platform that utilizes a computer vision-based recommendation system to suggest products based on visual attributes. This system relies on constantly evolving image data for products and user interaction patterns. Identifying and addressing data drift Monitoring User Interaction with Image Data: Regularly analyzing how users interact with product images can indicate shifts in preferences, such as changes in popular colors, styles, or features. Using Computer Vision Drift Detection Tools: Tools that analyze changes in image data distributions are employed. For example, a noticeable shift in the popularity of particular styles or colors in product images could signal a drift. Retraining the recommendation model Once a drift is detected, you must update the model to reflect current trends. This might involve retraining the model with recent images of products that have gained popularity or adjusting the weighting of visual features the model considers important. For instance, if users start showing a preference for brighter colors, the recommendation system is retrained to prioritize such products in its suggestions. The key is to establish a balance between responsiveness to drift and the practicalities of model maintenance. Read the blog How To Detect Data Drift on Datasets for more information. Next, let's delve into a practical approach to inspecting problematic images to identify and address potential data quality issues. Inspect the Problematic Images Encord Active provides a visual dataset overview, indicating duplicate, blurry, dark, and bright images. This accelerates identifying and inspecting problematic images for efficient data quality enhancement decisions. Use visual representations for quick identification and targeted resolution of issues within the dataset. Severe and Moderate Outliers In the Analytics section, you can distinguish between severe and moderate outliers in your image set, understand the degree of deviation from expected patterns, and address potential data quality concerns. For example, below is the dataset analysis of the COCO 2017 dataset. It shows the data outliers in each metric and their severity. Blurry Images in the Image Set The blurry images in the image set represent instances where the visual content lacks sharpness or clarity. These images may exhibit visual distortions or unfocused elements, potentially impacting the overall quality of the dataset. You can also use the filter to exclude blurry images and control the quantity of retained high-quality images in the dataset. Darkest Images in the Image Set The darkest images in the image set are those with the lowest overall brightness levels. Identifying and managing these images is essential to ensure optimal visibility and clarity within the dataset, particularly in scenarios where image brightness impacts the effectiveness of model training and performance analysis. Duplicate or Nearly Similar Images in the Set Duplicate or nearly similar images in the set are instances where multiple images exhibit substantial visual resemblance or share identical content. Identifying and managing these duplicates is important for maintaining dataset integrity, eliminating redundancy, and ensuring that the model is trained on diverse and representative data. Next Steps: Fixing Data Quality Issues Once you identify problematic images, the next steps involve strategic methods to enhance data quality. Encord Active provides versatile tools for targeted improvements: Re-Labeling Addressing labeling discrepancies is imperative for dataset accuracy. Use re-labeling to rectify errors and inconsistencies in low-quality annotation. Encord Active simplifies this process with its Collection feature, selecting images for easy organization and transfer back for re-labeling. This streamlined workflow enhances efficiency and accuracy in the data refinement process. Active Learning Leveraging active learning workflows to address data quality issues is a strategic move toward improving machine learning models. Active learning involves iteratively training a model on a subset of data it finds challenging or uncertain. This approach improves the model's understanding of complex patterns and improves predictions over time. In data quality, active learning allows the model to focus on areas where it exhibits uncertainty or potential errors, facilitating targeted adjustments and continuous improvement. Quality Assurance Integrate quality assurance into the data annotation workflow, whether manual or automated. Finding and fixing mistakes and inconsistencies in annotations is possible by using systematic validation procedures and automated checks. This ensures that the labeled datasets are high quality, which is important for training robust machine learning models.
Software To Help You Turn Your Data Into AI
Forget fragmented workflows, annotation tools, and Notebooks for building AI applications. Encord Data Engine accelerates every step of taking your model into production.
Kickoff a Project
Progress 33%.
- Step 1 of 3
Let’s get started
- Name (Required) Name Last Name
- Hidden Source utm_source utm_campaign
- Hidden Medium utm_medium utm_term
- Position (Required)
- Company (Required)
- New / Starting
- Recurring / Growing
- Step 2 of 3
About your project
- Name of your project (Required)
- Background (Required)
- Stage of development
- Looking for full project consulting services
- We know what we want but would require guidance
- We’re already advanced in our project development
- Labeling expert, not my first rodeo
- We have built our own custom platform
- Help me to find out which one is the best for my project
- 3rd party platform (if selected, please specify)
- General Classification
- Bounding Box Annotation
- Polygon Segmentation
- Keypoint Annotation
- Polyline Annotation
- Text Transcription
- Key-Value Extraction
- Sentiment Classification
- Semantic Segmentation
- Panoptic Segmentation
- Entity Classification
- Audio Transcription
- Topic Categorization
- Entity Linking
- Summarization
- Content Creation
- 15,000 to 50,000
- 50,000 to 100,000
- >100,000
- Estimated number of annotations per "audio/image/doc/…" (Required)
- Tell us a date
- I'm flexible
- Date MM slash DD slash YYYY
- Upload Raw Data Example (.pdf, .jpg or .doc) Max. file size: 100 MB.
- Upload Annotated Sample (.pdf, .jpg or .doc) Max. file size: 100 MB.
- Upload Your Labelling Sample Guidelines (.pdf, .jpg or .doc) Max. file size: 100 MB.
- Upload Any Ontology Info (.pdf, .jpg or .doc) Max. file size: 100 MB.
- Upload Your Preferred Workflow (.pdf, .jpg or .doc) Max. file size: 100 MB.
- Step 3 of 3
Looking forward to chatting with you!
- Phone number (Required)
- Email Address (Required)
- Select a date and time that you’re available (Required) MM slash DD slash YYYY
- View All Services SmartOne’s customized data-labelling services will help form the foundation for cutting-edge AI projects which scale. Services

- Learn About Us One of the world-leading and pioneering data labeling and AI advisory pure players About

- FREE Project Estimate
The Comprehensive Guide to AI Data Annotations
In the rapidly evolving landscape of Artificial Intelligence (AI) and Machine Learning (ML), data annotation stands as a cornerstone, pivotal to the advancement of these technologies. As we delve into the realm of AI, it’s imperative to recognize the role of data annotation in teaching machines to interpret and understand the world around them. At SmartOne, we specialize in transforming raw data into valuable insights through our comprehensive Data Annotation Services , catering to a diverse range of AI applications.
The essence of AI lies in its remarkable ability to learn, adapt, and evolve. Unlike static, code-dependent software, AI systems thrive on their capability to assimilate and apply knowledge, a process in which data annotation plays an integral role. High-quality annotated data is the lifeblood of AI, laying the foundation for building representative, successful, and unbiased models. Whether it’s powering sophisticated language models or enabling precision in autonomous vehicles, data annotation is the unseen hero, shaping the future of AI and ML.
Table of Contents
What is ai data annotation, benefits of ai data annotation, types of ai data annotation, the process of ai data annotation, addressing common questions in ai data annotation, challenges and future of ai data annotation, faq: ai data annotation.
AI Data Annotation is the systematic practice of tagging or labeling data to train AI models, enabling them to process and interpret information as a human would. This data could be anything from text in documents, objects in images, sequences in videos, or snippets in audio files. Just as a teacher guides a student, data annotation guides AI models, teaching them to recognize patterns, make predictions, and ultimately, understand the nuances of human language and behavior.
The process of AI Data Annotation is not merely operational; it’s transformative. By enhancing data with contextual tags, AI can navigate complex environments, interact with users through virtual assistants, and process visual and auditory information with a level of sophistication previously unattainable. In every industry, from healthcare’s diagnostic algorithms to the precision of self-driving cars, data annotation is the unsung hero, the bridge between raw data and actionable intelligence.
The advent of AI Data Annotation has heralded a new era in machine learning, unlocking a trove of benefits that propel AI from concept to application. At its core, data annotation enriches machine learning models with the acumen to discern, learn, and make decisions that mirror human intelligence. This meticulous process of tagging data across various formats—images, texts, videos, and audio—serves as the critical training regime for AI to accurately interpret the world.
Through the lens of data annotation, AI gains the precision to transform industries. In healthcare, it aids in the early detection of diseases, while in autonomous driving, it provides the situational awareness necessary to navigate roads safely. Retailers use annotated data to understand customer sentiments and personalize shopping experiences, demonstrating how data annotation is an investment in AI’s capacity to enhance our daily lives.
AI Data Annotation is not a monolith but a spectrum of diverse techniques, each tailored to specific data forms and AI functionalities. Understanding these types of annotation is crucial for harnessing AI’s full potential.
- Image Annotation: The cornerstone of computer vision, image annotation, involves identifying and labeling visual elements in images. From facial recognition in security systems to product categorization in e-commerce, image annotation is indispensable.
- Video Annotation: This extends the principles of image annotation to moving footage, crucial for dynamic analysis in scenarios like traffic monitoring and sports analytics.
- Audio Annotation: Here, audio files are transcribed and tagged, forming the basis for advancements in voice recognition and speech recognition technologies .
- Semantic Segmentation: A sophisticated form of image annotation, semantic segmentation partitions an image into segments for a granular understanding of scenes and objects.
- Object Detection and Localization: Essential for applications requiring precision, such as inventory tracking and autonomous vehicle navigation, this type of annotation identifies and locates objects within an image.
- Semantic Annotation: Crucial for text-based AI, semantic annotation links data to its semantic meaning, facilitating context-aware NLP applications.
- Natural Language Processing (NLP): NLP annotation involves parsing and tagging textual data to teach machines language understanding, driving the intelligence behind chatbots and virtual assistants.
- Sentiment Analysis: This type of annotation assesses the emotional tone behind text data, providing insights into customer opinions and behaviors across digital platforms.
Each type of data annotation plays a distinct role in building robust AI models, and SmartOne.ai is adept at providing customized annotation services that meet the unique needs of your AI projects, ensuring that your machine learning models are trained on datasets annotated for precision and relevance.
Demystifying the process behind AI Data Annotation unveils a structured, methodical approach that is as detail-oriented as it is critical for the success of AI models. Let’s break down the essential steps that SmartOne.ai follows to ensure the highest quality in data annotation:
- Defining the Task and Labeling Guidelines: The initial step is to establish clear objectives and comprehensive guidelines. This ensures that every piece of data, be it a pixel in an image or a phoneme in speech, is annotated with precision, serving a specific purpose in the larger AI model.
- Gathering High-Quality Training Data Sets: The fuel for any AI engine is its data. Gathering diverse, accurate, and relevant datasets is paramount. This involves not only sourcing data but also curating it to represent real-world scenarios that AI is expected to navigate.
- Choosing the Right Tools for Labeling: Equipping annotators with state-of-the-art tools is a must for SmartOne.ai. From machine learning algorithms that automate parts of the annotation process to sophisticated platforms that enable precision tagging, the right tools make all the difference.
Integral to this process is the recognition of human intervention . While AI has made leaps in automation, the discerning eye of skilled annotators is irreplaceable, especially when it comes to understanding context, nuance, and the subtleties of human communication.
The arena of AI Data Annotation is ripe with inquiry. To shed light on this crucial aspect of AI development, we answer a broader spectrum of common questions:
- What is data annotation in AI? It is the meticulous task of labeling data to train AI models, providing them with the necessary context to interpret and interact with the world.
- What are the different types of data annotations? Ranging from image and video annotation for visual understanding to audio and text annotation for language and sound processing, the variety of data annotation types caters to the diverse needs of AI applications.
- Why is data annotation important for machine learning? It’s vital for the development of accurate and efficient machine learning models, essentially teaching them to ‘think’ and ‘understand’ like humans.
- What are skills of data annotation? Precision, attention to detail, and a deep understanding of the subject matter are essential. Annotators often require a blend of technical and domain-specific knowledge to effectively label data.
- Can data annotation be automated? While automation can assist the annotation process, the nuanced understanding and contextual awareness provided by human annotators remain irreplaceable for ensuring high-quality data.
- What is the impact of data annotation? Quality data annotation can drastically enhance the performance of AI systems, leading to more accurate, reliable, and sophisticated applications across industries.
- What is the main purpose of data annotation? Its primary goal is to create datasets that can be used to train and evaluate machine learning models, ensuring they function correctly when deployed in real-world scenarios.
These are just a few of the questions that surface in the complex world of AI Data Annotation. For a deeper exploration and expert insights, we invite you to peruse our detailed Whitepaper on Large Language Models .
AI Data Annotation is a dynamic field, one that’s evolving as quickly as the technologies it supports. It faces unique challenges but also promises an exciting future. Here’s an overview of the hurdles and horizons of data annotation:
- Ensuring Quality and Accuracy: The precision of data annotation significantly impacts AI performance. Achieving high accuracy levels is a challenge, especially when dealing with vast datasets. Continuous efforts in refining tools and techniques are essential to maintain the integrity of annotated data.
- Cost and Time Efficiency: Data annotation is traditionally resource-intensive. Innovations in AI-assisted labeling are making strides in reducing both the time and cost associated with the annotation process.
- Scalability: As AI applications expand, so does the need for data. Scaling annotation efforts to meet the demands of complex, data-hungry AI systems is a pressing challenge for the industry.
- Handling Sensitive Data: Annotating data that contains personal or sensitive information requires strict adherence to privacy and ethical standards, adding another layer of complexity to the process.
- The Rise of Automated Data Annotation: Machine learning and AI are beginning to play more significant roles in automating data annotation tasks. However, the need for human oversight remains to ensure that automated systems maintain quality standards.
Looking to the future, AI Data Annotation is expected to become more sophisticated with advancements in automation and machine learning. The development of more intelligent annotation tools promises to streamline processes and unlock new potentials in AI and ML. The vision of fully automated, highly accurate data annotation is on the horizon, but human expertise will continue to be the guiding force behind the scenes, ensuring that AI systems serve our needs with the utmost precision and care.
In the intricate world of AI, data annotation is a subject of endless curiosity. Below, we answer some frequently asked questions to further demystify this essential process.
The role of a data annotator in machine learning
- Link to current page

- Data Labeling & ML

What is data annotation and why is data important?
Data annotation in machine learning models, ai-based applications: why do we need a machine learning model, data annotation methods and types, crowdsourced data annotation, being a crowd contributor: what is data annotator job, types of data annotation tasks, data annotation analysts and csas, become a data annotator.
Subscribe to Toloka News
The two synonymous terms “data annotator” and “data labeler” seem to be everywhere these days. But who is a data annotator? Many know that annotators are somehow connected to the fields of Artificial Intelligence (AI) and Machine Learning (ML), and they probably have important roles to play in the data labelling market. But not everyone fully understands what data labelers actually do. If you want to find out once and for all is data annotation a good job, especially if you’re considering a data labeling career – read on!
Get high-quality data. Fast.

Data annotation is the process of labeling elements of data ( images , videos, text , or any other format) by adding contextual information which ML models can learn from. It helps ML models understand what exactly is important about each piece of data.
To fully grasp and appreciate everything data labelers do and what data annotation skills they need, we need to start with the basics by explaining data annotation and data usage in the field of machine learning. So, let’s begin with something broad to give us appropriate context and then dive into more narrow processes and definitions.
Data comes in many different forms – from images and videos to text and audio files – but in almost all cases, this data has to be processed to render itself usable. What it means is that this data has to be organized and made “clear” to whomever is using it, or as we say, it has to be “labeled”.
If, for example, we have a dataset full of geometric shapes (data points), to prepare this dataset for further use, we need to make sure that every circle is labeled as “circle,” every square as “square,” every triangle as “triangle,” and so on. This turns a random collection of items in the dataset into something with a system that can be picked up and inserted into a real-life project, a bunch of training data for a machine learning algorithm. The opposite of it is “raw” data, which is essentially a mass of disorganized information. And this is where the data annotator role comes in: these people turn “raw data” into “ labeled data ”.
This processing and organization of raw unstructured data – “ data labeling ” or “data annotation” – is even more important in business. When your business relies on data in any way (which is becoming more and more common today), you simply cannot afford for your data to be messy, or else your business will likely run into serious troubles or fail altogether.
Labeled data can assist many different companies, both big and small, whether these companies rely on ML technologies, or have nothing to do with AI. For instance, a real-estate developer or a hotel executive may need to make an expansion decision about building a new facility. But before investing, they need to perform an in-depth analysis in order to understand what types of accommodation get booked, how quickly, during which months, and so on. All of that implies highly organized and “labeled” data (whether it’s called that or not) that can be visualized and used in decision-making.
A training algorithm (also referred to as machine learning algorithm or ML model) is basically clever code written by software engineers that tells an AI solution how to use the data it encounters. The process of training machine learning models involves several stages that we won’t go into right now.
But the main point is this: each and every machine learning model requires adequately labeled data at multiple points in its life cycle. And normally not just some high-quality training data – lots of it! Such ground truth data is used to train an ML model initially, as well as to monitor that it continues to produce accurate results over time.
Today, AI products are no longer the stuff of fiction or even something niche and unique. Most people use AI products on a regular basis, perhaps without even realizing that they’re dealing with an ML-backed solution. Probably one of the best examples is when we use Google Translate or a similar web service.
Think ML models, think data annotations, think training and test data. Feel like asking Siri or Alexa something? It’s the same deal again with virtual assistants: training algorithms, labeled data. Driving somewhere and having an online map service lay out and narrate a route for you? Yes, you guessed it!
Some other examples of disrupting AI technologies include self-driving vehicles, online shopping and product cataloging (e-commerce), cyber security, moderating reviews on social media, financial trading, legal assistance, interpretation of medical results, nautical and space navigation, gaming, and even programming among many others. Regardless of what industry an AI solution is made for or what domain it falls under (for instance, Computer Vision that deals with visual imagery or Natural Language Processing/NLP that deals with speech) – all of them imply continuous data annotation at almost every turn. And, of course, that means having people at hand who can carry out human powered data annotation.
Data annotation can be carried out in a number of ways by utilizing different “approaches”:
- Data can be labeled by human annotators.
- It can be labeled synthetically (using machine intelligence).
- Or it can be labeled in a “hybrid” manner (having both human and machine features).
As of right now, human-handled data annotation remains the most sought-after approach, because it tends to deliver the highest quality datasets. ML processes that involve human-handled data annotation are often referred to as being or having “human-in-the-loop pipelines.”
When it comes to the data annotation process, methodologies of acquiring manually annotated training data differ. One of them is to label the data “internally,” that is, to use an “in-house” team. In this scenario, as usual, the company has to write code and build an ML model at the core of their AI product. But then it also has to prepare training datasets for this machine learning model, often from scratch. While there are advantages to this setup (mainly having full control over every step), the main downside is that this track is normally extremely costly and time-consuming. The reason is that you have to do everything yourself, including training your staff, finding the right data annotation software, learning quality control techniques, and so on.
The alternative is to have your data labeled “externally,” which is known as “outsourcing.” Creators of AI products may outsource to individuals or whole companies to carry out their data annotation for them, which may involve different levels of supervision and project management. In this case, the tasks of annotating data are tackled by specialized groups of human annotators with relevant experience who often work within their chosen paradigm (for example, transcribing speech or working with image annotation).
In a way, outsourcing is a bit like having your own external in-house team that you hire temporarily, except that this team already comes with its own set of data annotation tools. While appealing to some, this method can also be very expensive for AI product makers. What’s more, data quality can often fluctuate wildly from project to project and team to team; after all, the whole data annotation process is handled by a third party. And when you spend so much, you want to be sure you’re getting your money’s worth.
There’s also a type of large-scale outsourcing known as “crowdsourcing” or “crowd-assisted labeling,” which is what we do at Toloka . The logic here is simple: rather than relying on fixed teams of data labelers with fixed skill sets (who are often based in one place), instead, crowdsourcing relies on a large and diverse network of data annotators from all over the globe.
In contrast to other data labeling methodologies, annotators from the “global crowd” choose what exactly they’re going to do and when exactly they wish to contribute. Another big difference between crowdsourcing and all other approaches, both internal and external, is that “crowd contributors” (or “Tolokers” as we call them) do not have to be experts or even have any experience at all. This is possible because:
A short, task-oriented training course takes place before each project in labeling data – only those who perform test tasks at a satisfactory level are allowed to proceed to actual project tasks.
Crowdsourcing utilizes advanced “aggregation techniques,” which means that it’s not so much about individual efforts of crowd contributors, but rather about the “accumulated effort” of everyone on the data annotation project.
To understand this better, think of it as painting a giant canvas. While in-house or outsourced teams gradually paint a complete picture, relying on their knowledge and tenacity, crowd contributors instead paint a tiny brush stroke each. In fact, the same brush stroke in terms of its position on the canvas is painted by several contributors. This is the reason why an individual mistake isn’t detrimental to the final result. A “data annotation analyst” (a special type of ML engineer) then does the following:
- They take each contributor’s input and discard any “noisy” (i.e., low-quality) responses.
- They aggregate the results by putting all of the overlapping brush strokes together (to get the best version of each brush stroke).
They then merge different brush strokes together to receive a complete image. Voila – here’s our ready canvas!
This methodology serves those who need annotated data very well, but it also makes data annotation a lot less tedious for human annotators. Probably the best thing about being a data annotator for a crowdsourcing platform like Toloka is that you can work any time you want, from any location you desire – it’s completely up to you. You can also work in any language, so speaking your native tongue is more than enough. If you speak English together with another language (native or non-native), that’s even better – you’ll be able to participate in more labeling projects.
Another great thing is that all you need is internet access and a device such as a smartphone, a tablet, or a laptop/desktop computer. Nothing else is required, and no prior experience is needed, because, as we've explained already, task-specific training is provided before every labeling project. Certainly, if you have expertise in some field, this will only help you, and you may even be asked to evaluate other contributors’ submissions based on your performance. What you produce may also be treated as a “golden” set (or “honeypot” as we say at Toloka), which is a high-quality standard that the others will be judged against.
All annotation tasks at Toloka are relatively small, because ML engineers decompose large labeling projects into more manageable segments. As a result, no matter how difficult the actual request to label data made by our client, as a crowd contributor, you’ll only ever have to deal with micro tasks. The main thing is following your instructions to the word. You have to be careful and diligent when you label the data. The tasks are normally quite easy, but to do them well, one needs to remain focused throughout the entire labeling process and avoid distractions.
There are many different labeling tasks for crowd contributors to choose from, but they all fall into these two categories:
- Online tasks (you complete everything on your device without traveling anywhere in person)
- Offline tasks, also known as “field” or “feet-on-street” tasks (you travel to target locations to complete labeling assignments).
When you choose to participate in a field task, you’re asked to go to a specific location in your area (normally your town or your neighborhood) to complete a short on-site assignment. This assignment could involve taking photos of all bus stops in the area, monuments, or coffee shops. It can also be something more elaborate like following a specific route within a shopping mall to determine how long it takes or counting and marking benches in a park. The results of these tasks are used to improve web mapping services, as well as brick-and-mortar retail (i.e., physical stores).
Online assignments have a variety of applications, some of which we mentioned earlier, and they may include text, audio, video, or image annotation. Each ML application contains several common task formats that our clients (or “requesters” as we say at Toloka) often ask for.
Text annotation
Text annotation tasks usually require annotators to extract specific information from natural language data. Such labeled data is used for training NLP (natural language processing) models. NLP models are used in search engines, voice assistants, automated translators, parsing of text documents, and so on.
Text classification
In such tasks (also called text categorization) you may need to answer whether the text you see matches the topic provided. For example, to see if a search query matches search engine results — such data helps improve search relevance . It can also be a simple yes/no questionnaire, or you may need to assign the text a specific category. For example, to decide whether the text contains a question or a purchase intent (this is also called intent annotation).

Text generation
In this type of text annotation, you may need to come up with your best description of an image/video/audio or a series of them (normally in 2-3 sentences).

Side-by-side comparison
You may need to compare two texts provided next to each other and decide which one is more informative or sounds better in your native tongue.
Named entity recognition
You may need to identify parts of text, classify proper nouns, or label any other entities. This type of text entity annotation is also called semantic annotation or semantic segmentation.

Sentiment Annotation
This is an annotation task which requires the annotator to determine the sentiment of a text. Such datasets are used in sentiment analysis, for example, to monitor customer feedback, or in content moderation. ML algorithms have to rely on human-labeled datasets to provide reliable sentiment analysis, especially in such a complicated area as human emotions.

Image annotation
Training data produced by performing image annotation is usually used to train various computer vision models. Such models are used, for example, in self-driving cars or in face recognition technologies. Image annotation tasks include working with images: identifying objects, bounding box annotation, deciding whether an image fits a specified topic, and so on.
Object recognition and detection
You may be asked to select and/or draw the edges (bounding boxes) of certain items within an image, such as street signs or human faces. A computer vision model needs an image with a distinct object marked by labelers, so that it can provide accurate results.

Image classification
You may be asked whether what you see in an image contains something specific, such as an animal, an item of clothing, or a kitchen appliance.

Side-by-side
You may be given two images and asked which one you think looks better, either in your own view or based on a particular characteristic outlined in the task. Later, these annotated images can be used to improve recommender systems in online shops.

Audio annotation
Audio classification.
In this audio annotation task, you may need to listen to an audio recording and answer whether it contains a particular feature, such as a mood, a certain topic, or a reference to some event.

Audio transcription
You may need to listen to some audio data and write or “transcribe” what you hear. Such labeled data can be used, for example, in speech recognition technologies.

Video annotation
Image and video annotation tasks quite often overlap. It's common to divide videos into single frames and annotate specific data in these frames.
Video classification
You may have to watch a video and decide whether it belongs to a certain category, such as “content for children,” “advertising materials,” “sporting event,” or “mature content with drug references or nudity”.

Video collection
This is not exactly a video annotation task, but rather a data collection one. You may be asked to produce your own short videos in various formats containing specified features, such as hand gestures, items of clothing, facial expressions, etc. Video data produced by annotators is also often used to improve computer vision models.

When we explained how crowdsourcing works using our example of a painted canvas, we mentioned a “data annotation analyst” (who are also sometimes data scientists). Without these analysts, none of it is possible. This special breed of ML engineers specializes in processing and analyzing labeled data. They play a vital role in any AI product creation. In the context of human-handled labeling, it’s precisely data annotation analysts who “manage” human labelers by providing them with specific tasks. They also supervise data annotation processes and – together with more colleagues – feed all of the data they receive into training models.
It’s up to data annotation analysts to find the most suitable data annotators to carry out specific labeling tasks and also set quality control mechanisms in place to ensure adequate quality. Crucially, data annotation analysts should be able to clearly explain everything to their data annotators. This is an important aspect of their job, as any confusion or misinterpretation at any point in the annotation process will lead to improperly labeled data and a low-quality AI product.
At Toloka, data annotation analysts are known as Crowd Solutions Architects (CSAs). They differ from other data annotation analysts in that they specialize in crowdsourced data and human-in-the-loop pipelines involving global crowd contributors.
As you can see, labeling data has an essential role to play in both AI-based products and modern business in general. Without high-quality annotated data, an ML algorithm cannot run and AI solutions cannot function. As our planet continues to go through exceedingly more digitization, traditional businesses are beginning to show their need for annotated data, too.
With that in mind, human annotators – people who annotate data – are in high demand all over the world. What’s more, crowdsourced data annotators are at the forefront of the global AI movement with the support they provide. If you feel like becoming a Toloker by joining our global crowd of data annotators, follow this link to sign up and find out more. As a crowd contributor at Toloka, you’ll be able to complete micro tasks online and offline whenever it suits you best.
Recent articles

Have a data labeling project?
What we do best
AI Data Services
Data Collection Create & collect audio, images, text & video from across the globe.
Data Annotation & Labeling Accurately annotate data to make AI & ML think faster & smarter.
Data Transcription AI-driven, cloud-based transcription supporting 150+ languages.
Healthcare AI Harness the power to transform complex data into actionable insight.
Conversational AI Localize AI-enabled speech models with rich structured multi-lingual datasets.
Computer Vision Train ML models with best-in-class AI data to make sense of the visual world.
Generative AI Harness the power to transform complex data into actionable insight.
- Question & Answering Pairs
- Text Summarization
- LLM Data Evaluation
- LLM Data Comparison
- Synthetic Dialogue Creation
- Image Summarization, Rating & Validation
Off-the-shelf Data Catalog & Licensing
Medical Datasets Gold standard, high-quality, de-identified healthcare data.
Physician Dictation Datasets
Transcribed Medical Records
Electronic Health Records (EHR)
CT Scan Images Datasets
X-Ray Images Datasets
Computer Vision Datasets Image and Video datasets to accelerate ML development.
Bank Statement Dataset
Damaged Car Image Dataset
Facial Recognition Datasets
Landmark Image Dataset
Pay Slips Dataset
Speech/Audio Datasets Source, transcribed & annotated speech data in over 50 languages.
New York English | TTS
Chinese Traditional | Utterance/Wake Word
Spanish (Mexico) | Call-Center
Canadian French | Scripted Monologue
Arabic | General Conversation
Banking & Finance Improve ML models to create a secure user experience.
Automotive Highly accurate training & validation data for Autonomous Vehicles.
eCommerce Improve shopping experience with AI to increase Conversion, Order Value, & Revenue.
Named Entity Recognition Unlock critical information in unstructured data with entity extraction in NLP.
Facial Recognition Auto-detect one or more human faces based on facial landmarks.
Search Queries Optimization Improving online store search results for better customer traffic.
Text-To-Speech (TTS) Enhance interactions with precise global language TTS datasets.
Content Moderation Services Power AI with data-driven content moderation & enjoy improved trust & brand reputation.
Optical Character Recognition (OCR) Optimize data digitization with high-quality OCR training data.
AI innovation in Healthcare
- Healthcare AI
Medical Annotation
Data De-identification
Clinical Data Codification
Clinical NER
- Generative AI
Off-the-Shelf Datasets
- Events & Webinar
- Security & Compliance
- Buyer’s Guide
- Infographics
- In The Media
- Sample Datasets

- July 4, 2023
Text Annotation in Machine Learning: A Comprehensive Guide
What is text annotation in machine learning.
Text annotation in machine learning refers to adding metadata or labels to raw textual data to create structured datasets for training, evaluating, and improving machine learning models. It is a crucial step in natural language processing (NLP) tasks, as it helps algorithms understand, interpret, and make predictions based on textual inputs.
Text annotation is important because it helps bridge the gap between unstructured textual data and structured, machine-readable data. This enables machine learning models to learn and generalize patterns from the annotated examples.
High-quality annotations are vital for building accurate and robust models. This is why careful attention to detail, consistency, and domain expertise is essential in text annotation.
Types of Text Annotation

Text Classification – Importance, Use Cases, and Process

AI-Based Document Classification – Benefits, Process, and Use-cases
- Data Annotation
- Data Collection
- Data De-Identification
- Conversational AI
- Computer Vision
- Automotive AI
- Banking & Finance
- ShaipCloud™ Platform
(US): (866) 473-5655
[email protected] [email protected] [email protected]
Vendor Enrollment Form
© 2018 – 2024 Shaip | All Rights Reserved
- Client Login
What is Text Annotation in Machine Learning?
By Appen. September 16, 2020
Everything You Need to Know About Text Annotation with Yao Xu
What is text annotation, types of text annotation, sentiment annotation, intent annotation, semantic annotation, relationship annotation, how is text annotated, appen’s text annotation expert – yao xu.
- What kind of data do you need
- How much data do you need and how soon
- Is your data in a specialized domain or non-English languages
- What resources do you have
- Look beyond text-based data
What Appen Can Do For You
More articles like this, the impending data crisis in the ai economy, deciphering ai from human generated text: the behavioral approach, building ai we can trust, appen and the ungc: defining sustainability and ethics in the ai era, how the human element balances ai and contributor efforts for optimal outcomes, appen's benchmarking solution: confidently choosing the right llm for your application , request a consult.
If you have any questions or would like more information about our services, please don’t hesitate to reach out. Our team is here to help and answer any questions you may have. Interested in joining our crowd? Click Here
Request a consult
- Our Products
- Case Studies
What is Text Annotation in Machine Learning?

Everything You Need to Know About Text Annotation with Yao Xu
Every day, we interact with different media (such as text, audio, images, and video), relying on our brain to process what media we are seeing and make meaning out of it to influence what we do. One of the most common types of media is text, which makes up the languages we use to communicate. Because it is so commonly used, text annotation needs to be done with accuracy and comprehensiveness.With machine learning (ML), machines are taught how to read, understand, analyze, and produce text in a valuable way for technological interactions with humans. Per the 2020 State of AI and Machine Learning report, 70% of companies reported that text is a type of data they use as part of their AI solutions. Understandably so, as the cost-savings and revenue-generating implications of text-based solutions across all industries are enormous.As machines improve their ability to interpret human language, the importance of training using high-quality text data becomes increasingly indisputable. In all cases, preparing accurate training data must begin with accurate, comprehensive text annotation.
What is Text Annotation?

Algorithms use large amounts of annotated data to train AI models, which is part of a larger data labeling workflow. During the annotation process, a metadata tag is used to mark up characteristics of a dataset. With text annotation, that data includes tags that highlight criteria such as keywords, phrases, or sentences. In certain applications, text annotation can also include tagging various sentiments in text, such as “angry” or “sarcastic” to teach the machine how to recognize human intent or emotion behind words.The annotated data, known as training data , is what the machine processes. The goal? Help the machine understand the natural language of humans. This procedure, combined with data pre-processing and annotation, is known as natural language processing, or NLP.These tags must be accurate and comprehensive. Poorly done text annotations will lead a machine to exhibit grammatical errors or issues with clarity or context. If you ask your bank’s chatbot, “How do I put a hold on my account?” and it responds with, “Your account does not have a hold on it,” then clearly the machine misunderstood the question and needs retraining on more accurately-annotated data.A machine will learn to communicate efficiently enough in natural language after being trained on accurately annotated text data. It can carry out the more repetitive and mundane tasks humans would otherwise do. This frees up time, money, and resources in an organization to enable focus on more strategic endeavors.The applications of natural language-based AI systems are endless: smart chatbots , e-commerce experience improvements, voice assistants, machine translators, more efficient search engines, and more. The ability to streamline transactions by leveraging high-quality text data has far-reaching implications for customer experience and organizations’ bottom line across all major industries.
Types of Text Annotation
Annotations for text include a wide range of types, such as sentiment, intent, semantic, and relationship. These options are available across a wide array of human languages.
Sentiment Annotation
Sentiment annotation evaluates attitudes and emotions behind a text by labeling that text as positive, negative, or neutral.
Intent Annotation
Intent annotation analyzes the need or desire behind a text, classifying it into several categories, such as request, command, or confirmation.
Semantic Annotation
Semantic annotation attaches various tags to text that reference concepts and entities, such as people, places, or topics.
Relationship Annotation
Relationship annotation seeks to draw various relationships between different parts of your document. Typical tasks include dependency resolution and coreference resolution.The type of project and associated use cases will determine which text annotation technique should be selected.
How is Text Annotated?
Most organizations seek out human annotators to label text data. Human annotators are especially valuable in analyzing sentiment data, as this can often be nuanced and is dependent on modern trends in slang and other uses of language.Still, large-scale text annotation and classification tools out there can help you achieve the deployment of your AI model quickly and more inexpensively. The route you take will depend on the complexity of the problem you’re trying to solve, as well as the resources and financial commitment your organization is willing to make.Refer to data labeling methods for a comprehensive look at the annotation options available to your organization.
Appen’s Text Annotation Expert - Yao Xu
At Appen, we rely on our team of experts to help provide text annotation for our customers’ machine learning tools. Yao Xu, one of our product managers, helps ensure the Appen Data Annotation Platform exceeds industry standards in providing high-quality text annotation services. She came from a science and linguistic academic background, speaks three languages, and has extensively studied ML and NLP. Her top insights when evaluating and fulfilling your text annotation needs include: Know your current goal and long-term vision
- What kind of data do you need
Define what types of annotation are needed as your model’s training data - whether it’s document level labeling or token level labeling, whether it’s collecting data from scratch or labeling data or reviewing machine prediction. It’s an essential first step to have your goal defined.
- How much data do you need and how soon
The volume data and your required data throughput is a significant factor in deciding your data annotation strategy. When your needs are low, it may be a good idea to start from open-source annotation tools or subscribe to self-serve platforms. But if you foresee a fast-growing need in annotated text data in your team, it might be a good idea to spend time to evaluate your options and choose a platform or service partner that could work in the long run.
- Is your data in a specialized domain or non-English languages
Text data in specialized domains or non-English languages may require annotators to have relevant knowledge and skills. This may pose a constraint when you’re scaling your data annotation effort. Choosing the right partner that could fulfill these special needs becomes essential in this case.
- What resources do you have
You may have an experienced engineering team to process your data and build models. You may already have a team of expert annotators. You may even have your own annotation tools. Whatever resources you have, you want to maximize their value when acquiring external resources.
- Look beyond text-based data
Text data can also be extracted from images, audio, and video files. If such needs occur, you’d need your annotation platform or service provider to be able to handle the transcription task from these non-text data. This is also something that you should take into consideration when choosing your annotation solutions.
What Appen Can Do For You
At Appen, our data annotation experience spans over 20 years, over which time we have acquired advanced resources and expertise on the best formula for successful annotation projects. By combining our intelligent annotation platform, a team of annotators tailored for your projects, and meticulous human supervision by our AI crowd-sourcing specialists, we give you the high-quality training data you need to deploy world-class models at scale. Our text annotation, image annotation, audio annotation, and video annotation capabilities will cover the short-term and long-term demands of your team and your organization. Whatever your data annotation needs may be, our platform, our crowd, and managed services team are standing by to assist you in deploying and maintaining your AI and ML projects.Learn more about what solutions are available to help you with your text annotation projects, or contact us today to speak with someone directly.
Related posts
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Data Annotation for Machine Learning Models
Data annotation is a crucial process in training machine learning models. It involves labeling individual elements of training data, such as text, images, audio, or video, to help machines understand what the data contains. Annotated data is used to train models and is also important for quality control in the data collection process . Teaching machines through annotation requires large volumes of correctly annotated data. There are different types of data annotation , including text annotation , image annotation , and video annotation , each serving a specific purpose. Humans play an integral role in the data annotation process to ensure accuracy and provide valuable context.
Key Takeaways:
- Data annotation is a crucial process in training machine learning models.
- It involves labeling individual elements of training data to help machines understand the data.
- Different types of data annotation include text annotation , image annotation , and video annotation .
- Humans play an integral role in the data annotation process to ensure accuracy and provide context.
- Annotated data is used to train models and improve the quality of the data collection process .
The Types of Data Annotation: Text Annotation
Text annotation is a fundamental process in data annotation that involves segmenting and labeling textual data to help machines recognize individual elements within the text. This type of annotation plays a crucial role in various natural language processing tasks, including information extraction, sentiment analysis, and text classification.

Named Entity Tagging
Named Entity Tagging (NET) and Named Entity Recognition (NER) are commonly used techniques in text annotation. They focus on identifying specific entities such as "person," "sport," or "country" within the text. By labeling these entities, machines can understand the different elements present in the text and perform tasks like entity extraction or relation extraction.
Sentiment Tagging
Sentiment Tagging is another important aspect of text annotation. It involves determining the sentiment behind a phrase or sentence, whether it is positive, negative, or neutral. Sentiment analysis is widely used in various applications, such as social media monitoring, customer feedback analysis, and brand reputation management.
Semantic Annotation
Semantic Annotation provides contextual information and domain-specific meaning to words within the text. It helps machines understand the intent behind the text and disambiguate terms with multiple meanings. Semantic annotation is essential for tasks like natural language understanding, question answering systems, and chatbots.
"Named Entity Tagging, Sentiment Tagging, and Semantic Annotation are crucial components of text annotation, enabling machines to comprehend and analyze textual data with accuracy and context."
Text annotation is a labor-intensive task that requires expertise in language understanding and domain-specific knowledge. It often involves a combination of manual annotation by human annotators and automated techniques to improve efficiency and scalability.
Text annotation is a vital step in generating quality training data for machine learning models. It enables machines to understand and interpret textual data, paving the way for various applications such as chatbots, question answering systems, and sentiment analysis tools.
The Types of Data Annotation: Image Annotation
Image annotation plays a crucial role in training machine learning models to understand the elements present in an image. By labeling and annotating the different objects and features within an image, machines can accurately interpret and analyze visual information. There are several methods of image annotation that facilitate this process, including:
Image Bounding Boxes
One popular technique in image annotation is Image Bounding Boxes . This method involves drawing bounding boxes around specific elements within an image, such as objects, regions of interest, or areas that require further analysis. Each bounding box provides detailed information about the position, size, and shape of the annotated object, allowing machines to recognize and differentiate various elements in an image.
Object Tagging
Another approach to image annotation is Object Tagging . With object tagging , specific objects within an image are labeled using descriptive tags or keywords. By assigning relevant labels to each object, machines can understand the presence and identity of certain objects in an image. Object tagging enhances the accuracy of object detection and recognition algorithms, enabling machines to perform tasks like counting, tracking, or segmenting specific objects.
Image Classification
Image annotation also involves Image Classification , where images are annotated based on single or multi-level categories. Through this technique, machines can classify images into different predefined classes or categories, providing valuable insights and understanding of the content. Image classification aids in tasks such as content categorization, filtering, or organizing large image datasets.
Image annotation, through techniques like image bounding boxes , object tagging , and image classification , enables computer vision tasks such as object detection, image segmentation, and content categorization. This aids in the development of accurate and robust machine learning models that can interpret and analyze visual data with precision.
Image annotation is an essential process in training machine learning models to understand and interpret visual data. These annotation techniques provide the necessary context and understanding for machines to analyze images accurately and perform complex computer vision tasks. By employing these methods, organizations can harness the potential of machine learning and artificial intelligence to gain valuable insights from visual information.
The Types of Data Annotation: Video Annotation
Video annotation is an essential aspect of data annotation, similar to image annotation. It involves the process of identifying and labeling various elements that appear within the frames of a video. Through video annotation, bounding boxes and other annotation methods are utilized to accurately identify, classify, and track objects across multiple frames.
One of the primary techniques employed in video annotation is the use of bounding boxes. This annotation method entails drawing boxes around objects or elements of interest within each frame of the video. These bounding boxes provide a visual representation of the object's location and serve as a reference for applications such as object recognition and tracking.
Object tracking is another critical aspect of video annotation. This technique involves tracing specific objects across successive frames to track their movement and behavior. By tracking objects within a video, it becomes possible to analyze interactions between objects, predict their trajectories, and derive valuable insights.
"Video annotation enables us to annotate objects within a continuous stream of frames, allowing us to better understand the visual context and dynamics within a video." - Dr. Jane Thompson, Computer Vision Expert
Video annotation plays a vital role in various domains, including object recognition and surveillance videos. In the field of autonomous vehicles , video annotation is particularly pivotal. By accurately labeling objects such as pedestrians, vehicles, traffic signs, and road markings, autonomous vehicles can make informed decisions and navigate safely and efficiently.
Benefits of Video Annotation for Autonomous Vehicles:
- Enhanced object recognition and tracking capabilities
- Improved accuracy and reliability of object detection algorithms
- Enhanced situational awareness and decision-making for autonomous vehicles
- Higher levels of safety and reliability in self-driving systems
Video annotation provides the necessary training data to enable autonomous vehicles to accurately identify and understand objects within their surroundings, contributing to the seamless integration of self-driving technologies into our daily lives.
Human vs. Machine in Data Annotation
When it comes to data annotation, humans and machines each bring their own advantages and limitations to the table. While machines have the potential to automate certain aspects of the annotation process, the expertise and insights provided by humans are crucial for accurate and meaningful annotations. Human annotation not only ensures accuracy but also provides valuable context, domain expertise , and a deeper understanding of intent.
One of the key contributions of human annotation is the creation of ground truth datasets . These datasets serve as a benchmark for measuring the performance of machine learning models. By meticulously labeling data with human expertise, ground truth datasets provide a reference against which machine-annotated data can be compared. This evaluation helps in refining and improving the accuracy of models.
The data collection process can greatly benefit from the involvement of human annotators. They play a vital role in understanding the nuances of the data, ensuring that even subtle features are correctly annotated. In domains where subjectivity and ambiguity are common, human expertise becomes invaluable. Human annotators can apply their nuanced understanding of the data to make critical decisions and provide accurate annotations, enabling machines to learn from the same.
Organizations often face the choice of performing data annotation in-house or outsourcing it to third-party services. In-house annotation gives organizations greater control over the process, allowing them to tailor it to their specific needs. On the other hand, outsourcing annotation to specialized service providers can be cost-effective and efficient, leveraging the expertise and scalability of dedicated teams.
In summary, while machines can automate parts of the data annotation process, their contributions are complemented and enhanced by human annotators. The combined efforts of humans and machines lead to accurate and reliable annotations, enabling machine learning models to make informed decisions and perform effectively.
Challenges in Data Annotation
Data annotation is not without its challenges. Several factors contribute to the complexity of the annotation process, including subjectivity , scale , and labeling ambiguity . These challenges can impact the accuracy and consistency of annotations, requiring careful consideration and effective strategies.
Subjectivity
One of the main challenges in data annotation is subjectivity. Humans have their own perspectives and interpretations, which can lead to inconsistencies in annotation decisions. Different annotators may label the same data differently based on their individual understanding or biases. This subjectivity introduces a level of uncertainty and can affect the overall quality of annotations.
The scale of data annotation can be a significant challenge. Training machine learning models requires large volumes of accurately annotated data. The process of manually labeling each element within a dataset can be time-consuming and resource-intensive. As the size of datasets grows, managing the annotation process becomes increasingly complex, requiring efficient workflows and tools to handle the scale effectively.
Labeling Ambiguity
Labeling ambiguity is another challenge in data annotation. Some data may contain elements that require domain-specific knowledge or have inherent ambiguity. Annotators may struggle to assign precise labels when faced with complex or context-dependent information. This ambiguity can result in inconsistent annotations and difficulty in training machine learning models to accurately interpret the data.
To overcome these challenges, clear annotation guidelines are essential. Detailed instructions and examples can help reduce subjectivity and ensure consistent annotations. Quality control measures, such as regular reviews and cross-validation, can help identify and address potential inconsistencies. Efficient annotation tools that provide contextual information and guidelines can also improve the accuracy and efficiency of the annotation process.
Summary of Data Annotation Challenges
Overcoming these challenges is crucial to ensure accurate and reliable annotations. By addressing subjectivity, scale, and labeling ambiguity, organizations can enhance the quality of training data and improve the performance of machine learning models.
How to Become a Data Annotator
Becoming a data annotator requires domain expertise in specialized fields such as computer vision or natural language processing. It is essential to have a deep understanding of the subject matter to accurately annotate data. Familiarity with annotation tools and software is also crucial in this role. Data annotators must be proficient in using annotation tools that help label and annotate various types of data effectively.
Staying updated with the latest trends and developments in data annotation is essential for a data annotator's professional growth. The field of data annotation is constantly evolving, and new tools and techniques are being introduced regularly. By staying informed, data annotators can adopt the latest practices and enhance their skills to provide quality annotations.
Building a portfolio of annotated datasets is a valuable way to showcase skills and expertise as a data annotator . Having a diverse range of datasets that demonstrate proficiency in different annotation techniques can help attract potential employers or clients. A well-curated portfolio validates the data annotator's abilities and can serve as a testament to their expertise.
Opportunities for data annotators can be found through freelance platforms or job postings from organizations seeking annotation services. Freelance platforms provide a gateway for data annotators to find projects and gain experience in various domains. Job postings from companies that require data annotation services can offer long-term opportunities and career growth.
Skills Needed to become a Data Annotator
1. Domain Expertise: Deep knowledge and understanding of the subject matter, such as computer vision or natural language processing, to provide accurate annotations.
2. Familiarity with Annotation Tools: Proficiency in using various annotation tools and software to label and annotate different types of data effectively.
3. Attention to Detail: Ability to carefully analyze and annotate data with precision, ensuring high-quality annotations.
4. Critical Thinking: Capacity to interpret and understand data within the context of the specified domain, allowing for informed and accurate annotations.
5. Communication Skills: Clear communication is necessary to effectively relay annotations and any specific requirements to clients or team members.
6. Time Management: Efficiently managing time to meet deadlines and handle multiple annotation tasks concurrently.
7. Continuous Learning: Remaining updated with the latest advancements in data annotation techniques and tools to enhance skills and stay relevant in the field.
By acquiring the required domain expertise, mastering annotation tools, and staying updated with the latest developments, individuals can unlock a career as a data annotator . It is a challenging yet rewarding role that contributes to the advancement of machine learning and AI technologies.
Best Practices for Data Annotation
Accurate and reliable annotations in data annotation are achieved by following best practices. These practices ensure that annotated data is of high quality, consistent, and provides valuable insights for machine learning models. Here are some essential best practices to consider:
Create Clear and Comprehensive Annotation Guidelines
Annotation guidelines serve as a roadmap for annotators, providing clear instructions on how to label and annotate data. These guidelines should be comprehensive, covering all relevant aspects and specific requirements for each annotation task. By maintaining clarity and avoiding ambiguity, annotators can accurately understand and execute the annotation tasks.
Implement Regular Quality Control Measures
Quality control is critical in data annotation to verify the accuracy and consistency of annotations. Regularly reviewing and evaluating annotated data ensures that it meets predefined quality standards. Quality control measures may involve cross-checking annotations by multiple annotators, conducting periodic audits, and comparing annotations against ground truth datasets. By implementing quality control measures, organizations can maintain the integrity and reliability of annotated data.
Utilize Data Augmentation Techniques
Data augmentation techniques can enhance the diversity and quantity of annotated data. By applying various transformations or modifications, such as image rotations, flips, or adding noise, the dataset can be expanded, allowing models to generalize better. Data augmentation helps prevent overfitting and improves model performance by exposing it to a wider range of variations in the annotated data.
Promote Collaboration and Refinement
Collaboration between annotators, domain experts, and data scientists is crucial for refining annotations. Regular communication and feedback loops enable the annotation process to evolve and improve over time. Collaborative efforts help address challenges, clarify guidelines, and resolve any ambiguities or disagreements in annotations. Continuous refinement results in higher-quality annotations and ultimately improves the overall performance of machine learning models.
"Following best practices in data annotation ensures accurate and reliable annotations, leading to more effective machine learning models."
By implementing these best practices, organizations can optimize their data annotation processes and generate high-quality annotated datasets. These datasets serve as valuable training material for machine learning models, contributing to their accurate predictions and improved performance.
Data annotation is an essential process in machine learning, enabling models to make accurate predictions and informed decisions. The quality of annotations directly impacts the performance and reliability of these models. As the field of machine learning continues to advance, the demand for accurate and scalable data annotation services is expected to grow rapidly.
Looking towards the future, technological advancements will play a significant role in shaping the data annotation landscape. Smart labeling tools, powered by artificial intelligence, can streamline and automate the annotation process, reducing human effort and increasing efficiency. Reporting frameworks will provide valuable insights and metrics to assess annotation quality and drive continuous improvement.
The global data annotation market is projected to witness substantial growth in the coming years. The increasing adoption of machine learning across various industries, including healthcare, automotive, and retail, contributes to this surge in demand. Organizations are recognizing the importance of high-quality annotated data to train robust models for improved decision-making.
As machine learning techniques and algorithms continue to evolve, the role of data annotation will remain critical. Accurate and reliable annotations provide the foundation for successful machine learning applications. By embracing technological advancements and adopting best practices, organizations can harness the full potential of data annotation to drive innovation and achieve optimal outcomes in the era of intelligent machines.
What is data annotation for machine learning?
Data annotation for machine learning involves labeling individual elements of training data to help machines understand the data. It is crucial for training machine learning models and ensuring accuracy.
What are the types of data annotation?
There are different types of data annotation, including text annotation, image annotation, and video annotation. Each type serves a specific purpose in training machine learning models.
What is text annotation?
Text annotation involves segmenting and labeling textual data to help machines recognize individual elements within the text. It includes tasks such as named entity tagging , sentiment tagging , and semantic annotation .
What is image annotation?
Image annotation is used to help machines understand the elements present in an image. It includes tasks such as image bounding boxes , object tagging, and image classification.
What is video annotation?
Video annotation involves identifying and labeling elements within video frames. It includes tasks such as bounding boxes, object tracking , and assisting autonomous vehicles in identifying objects on the road.
What is the role of humans in data annotation?
Humans play a crucial role in data annotation by providing context, domain expertise, and a deeper understanding of intent. Human annotation helps create ground truth datasets and ensures accurate and meaningful annotations.
What are the challenges in data annotation?
Data annotation comes with challenges such as subjectivity in annotations, time-consuming scale, and labeling ambiguity. Clear guidelines, quality control measures, and efficient annotation tools are needed to address these challenges.
How can one become a data annotator?
Becoming a data annotator requires domain expertise in a specific field, familiarity with annotation tools, and staying updated with the latest trends. Opportunities can be found through freelance platforms or job postings.
What are the best practices for data annotation?
Best practices for data annotation include clear and comprehensive annotation guidelines , regular quality control measures, and the use of data augmentation techniques to increase diversity. Collaboration and refinement of annotations also improve overall quality.
What is the future of data annotation?
The future of data annotation lies in technological advancements such as smart labeling tools and reporting frameworks. The global data annotation market is projected to grow significantly, highlighting the increasing demand for accurate and scalable data annotation services .
Source Links
- https://resources.defined.ai/blog/machine-learning-essentials-what-is-data-annotation/
- https://www.habiledata.com/blog/why-data-annotation-is-important-for-machine-learning-ai/
- https://www.twine.net/blog/data-annotation-in-machine-learning/
Recommended for you
Overcoming ai model deployment challenges, understanding the cost of developing an ai model, transforming healthcare with ai model applications, how to improve your ai model's accuracy: expert tips, advanced ai model training techniques explained.
No results for your search, please try with something else.
This Week in AI: Let us not forget the humble data annotator

Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of recent stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
This week in AI, I’d like to turn the spotlight on labeling and annotation startups — startups like Scale AI, which is reportedly in talks to raise new funds at a $13 billion valuation. Labeling and annotation platforms might not get the attention flashy new generative AI models like OpenAI’s Sora do. But they’re essential. Without them, modern AI models arguably wouldn’t exist.
The data on which many models train has to be labeled. Why? Labels, or tags, help the models understand and interpret data during the training process. For example, labels to train an image recognition model might take the form of markings around objects, “ bounding boxes ” or captions referring to each person, place or object depicted in an image.
The accuracy and quality of labels significantly impact the performance — and reliability — of the trained models. And annotation is a vast undertaking, requiring thousands to millions of labels for the larger and more sophisticated data sets in use.
So you’d think data annotators would be treated well, paid living wages and given the same benefits that the engineers building the models themselves enjoy. But often, the opposite is true — a product of the brutal working conditions that many annotation and labeling startups foster.
Companies with billions in the bank, like OpenAI, have relied on annotators in third-world countries paid only a few dollars per hour . Some of these annotators are exposed to highly disturbing content, like graphic imagery, yet aren’t given time off (as they’re usually contractors) or access to mental health resources.
Workers that made ChatGPT less harmful ask lawmakers to stem alleged exploitation by Big Tech
An excellent piece in NY Mag peels back the curtains on Scale AI in particular, which recruits annotators in countries as far-flung as Nairobi and Kenya. Some of the tasks on Scale AI take labelers multiple eight-hour workdays — no breaks — and pay as little as $10. And these workers are beholden to the whims of the platform. Annotators sometimes go long stretches without receiving work, or they’re unceremoniously booted off Scale AI — as happened to contractors in Thailand, Vietnam, Poland and Pakistan recently .
Some annotation and labeling platforms claim to provide “fair-trade” work. They’ve made it a central part of their branding in fact. But as MIT Tech Review’s Kate Kaye notes , there are no regulations, only weak industry standards for what ethical labeling work means — and companies’ own definitions vary widely.
So, what to do? Barring a massive technological breakthrough, the need to annotate and label data for AI training isn’t going away. We can hope that the platforms self-regulate, but the more realistic solution seems to be policymaking. That itself is a tricky prospect — but it’s the best shot we have, I’d argue, at changing things for the better. Or at least starting to.
Here are some other AI stories of note from the past few days:
- OpenAI builds a voice cloner: OpenAI is previewing a new AI-powered tool it developed, Voice Engine, that enables users to clone a voice from a 15-second recording of someone speaking. But the company is choosing not to release it widely (yet), citing risks of misuse and abuse.
- Amazon doubles down on Anthropic: Amazon has invested a further $2.75 billion in growing AI power Anthropic, following through on the option it left open last September .
- Google.org launches an accelerator: Google.org, Google’s charitable wing, is launching a new $20 million, six-month program to help fund nonprofits developing tech that leverages generative AI.
- A new model architecture: AI startup AI21 Labs has released a generative AI model, Jamba, that employs a novel, new(ish) model architecture — state space models, or SSMs — to improve efficiency.
- Databricks launches DBRX: In other model news, Databricks this week released DBRX, a generative AI model akin to OpenAI’s GPT series and Google’s Gemini. The company claims it achieves state-of-the-art results on a number of popular AI benchmarks, including several measuring reasoning.
- Uber Eats and UK AI regulation : Natasha writes about how an Uber Eats courier’s fight against AI bias shows that justice under the UK’s AI regulations is hard won.
- EU election security guidance: The European Union published draft election security guidelines Tuesday aimed at the around two dozen platforms regulated under the Digital Services Act, including guidelines pertaining to preventing content recommendation algorithms from spreading generative AI-based disinformation (aka political deepfakes).
- Grok gets upgraded: X’s Grok chatbot will soon get an upgraded underlying model, Grok-1.5 — at the same time all Premium subscribers on X will gain access to Grok. (Grok was previously exclusive to X Premium+ customers.)
- Adobe expands Firefly: This week, Adobe unveiled Firefly Services , a set of more than 20 new generative and creative APIs, tools and services. It also launched Custom Models, which allows businesses to fine-tune Firefly models based on their assets — a part of Adobe’s new GenStudio suite.
More machine learnings
How’s the weather? AI is increasingly able to tell you this. I noted a few efforts in hourly, weekly, and century-scale forecasting a few months ago, but like all things AI, the field is moving fast. The teams behind MetNet-3 and GraphCast have published a paper describing a new system called SEEDS , for Scalable Ensemble Envelope Diffusion Sampler.
Animation showing how more predictions creates a more even distribution of weather predictions.
SEEDS uses diffusion to generate “ensembles” of plausible weather outcomes for an area based on the input (radar readings or orbital imagery perhaps) much faster than physics-based models. With bigger ensemble counts, they can cover more edge cases (like an event that only occurs in 1 out of 100 possible scenarios) and be more confident about more likely situations.
Fujitsu is also hoping to better understand the natural world by applying AI image handling techniques to underwater imagery and lidar data collected by underwater autonomous vehicles. Improving the quality of the imagery will let other, less sophisticated processes (like 3D conversion) work better on the target data.
Image Credits: Fujitsu
The idea is to build a “digital twin” of waters that can help simulate and predict new developments. We’re a long way off from that, but you gotta start somewhere.
Over among the LLMs, researchers have found that they mimic intelligence by an even simpler than expected method: linear functions. Frankly the math is beyond me (vector stuff in many dimensions) but this writeup at MIT makes it pretty clear that the recall mechanism of these models is pretty… basic.
Even though these models are really complicated, nonlinear functions that are trained on lots of data and are very hard to understand, there are sometimes really simple mechanisms working inside them. This is one instance of that,” said co-lead author Evan Hernandez. If you’re more technically minded, check out the paper here .
One way these models can fail is not understanding context or feedback. Even a really capable LLM might not “get it” if you tell it your name is pronounced a certain way, since they don’t actually know or understand anything. In cases where that might be important, like human-robot interactions, it could put people off if the robot acts that way.
Disney Research has been looking into automated character interactions for a long time, and this name pronunciation and reuse paper just showed up a little while back. It seems obvious, but extracting the phonemes when someone introduces themselves and encoding that rather than just the written name is a smart approach.

Image Credits: Disney Research
Lastly, as AI and search overlap more and more, it’s worth reassessing how these tools are used and whether there are any new risks presented by this unholy union. Safiya Umoja Noble has been an important voice in AI and search ethics for years, and her opinion is always enlightening. She did a nice interview with the UCLA news team about how her work has evolved and why we need to stay frosty when it comes to bias and bad habits in search.
Why it’s impossible to review AIs, and why TechCrunch is doing it anyway
Log in with your Pace credentials for access to all the resources (click the " Sign In with your School Credentials " button).
- Faculty & Staff
- What is a Community?
- Accounting & Financial Services
- Arts and Design, Writing and Journalism, & Film, TV, and Music Production
- Counseling, Therapy, & Support and Community Services
- Data Science, Data Analytics, Data Engineering, & Machine Learning
- Education & Academia
- Government, Policy, Legal & Advocacy
- Healthcare Services (Clinical)
- Healthcare Services (Non-Clinical)
- Human Resources, Operations, Project Management, & Hospitality
- IT Systems Support & Cybersecurity
- Marketing, Social Media, PR, & Account Management
- Product Management, UX/UI Research and Design, & Technology Consulting
- Scientific Research: Biology, Chemistry, Forensics, Environmental Fieldwork, & Neuroscience
- Software Engineering, Web Development, & Game Design
- Undecided: Career Exploration
- About to Graduate Student Community
- Black Student Community
- First Generation Student Community
- International Student Community
- Latinx Student Community
- LGBTQIA+ Student Community
- Military & Veterans Student Community
- Neurodiversity Student Community
- Student-Athlete Community
- Students with Disabilities
- Women Student Community
- International Student Guide to Gaining Experience
- Pitch and Interviewing
- LinkedIn and Handshake Profiles
- Cover Letters and Professional Writing
- Build Skills Employers Want
- Grow your Network
- Connect with Employers
- Search for Internships and Jobs
- On-Campus Employment
- Pace-Funded Internships
- Unleash Your Inner Professional
- Achieve and Announce
- Aspire Program (Accelerated Success Professional Readiness Education)
- Inspire Program (International Student Professional Readiness Education)
- Customer Service Program for Students
- Resume Worded
- Big Interview
- Interstride
- Career Community Finder and Entry Portal
- Alumni Mentoring Program
- On-Campus Internships and Jobs
- Interview Room Finder
- LinkedIn Learning Courses
- About Career Services
- Meet the Directors
- Meet Our Career Counseling Teams
- Employer Relations Team
- Operations and Front Desk Team

Hands-On Data Annotation: Applied Machine Learning
- Share This: Share Hands-On Data Annotation: Applied Machine Learning on Facebook Share Hands-On Data Annotation: Applied Machine Learning on LinkedIn Share Hands-On Data Annotation: Applied Machine Learning on X
Instructor: Wuraola Oyewusi
Are you curious how data powers machine learning and data science? In this course, Wuraola Oyewusi dives into the intricacies of data annotation for machine learning and shows how data is prepared and used for training of machine learning models. Wuraola starts with a big-picture look at the principles, types, and importance of data annotation in machine learning pipelines. She then dives into hands-on use cases for data annotation in natural language processing, computer vision, and general data science using different tools. Other topics include using both open-source and proprietary tools such for data notation, as well as labeling data on major cloud platforms like AWS, Azure, and GCP.
Help | Advanced Search
Computer Science > Machine Learning
Title: an interactive human-machine learning interface for collecting and learning from complex annotations.
Abstract: Human-Computer Interaction has been shown to lead to improvements in machine learning systems by boosting model performance, accelerating learning and building user confidence. In this work, we aim to alleviate the expectation that human annotators adapt to the constraints imposed by traditional labels by allowing for extra flexibility in the form that supervision information is collected. For this, we propose a human-machine learning interface for binary classification tasks which enables human annotators to utilise counterfactual examples to complement standard binary labels as annotations for a dataset. Finally we discuss the challenges in future extensions of this work.
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .

A.I. Is Learning What It Means to Be Alive
Given troves of data about genes and cells, A.I. models have made some surprising discoveries. What could they teach us someday?
Credit... Doug Chayka
Supported by
- Share full article

By Carl Zimmer
- Published March 10, 2024 Updated March 12, 2024
In 1889, a French doctor named Francois-Gilbert Viault climbed down from a mountain in the Andes, drew blood from his arm and inspected it under a microscope. Dr. Viault’s red blood cells, which ferry oxygen, had surged 42 percent. He had discovered a mysterious power of the human body: When it needs more of these crucial cells, it can make them on demand.
In the early 1900s, scientists theorized that a hormone was the cause. They called the theoretical hormone erythropoietin, or “red maker” in Greek. Seven decades later, researchers found actual erythropoietin after filtering 670 gallons of urine .
And about 50 years after that, biologists in Israel announced they had found a rare kidney cell that makes the hormone when oxygen drops too low. It’s called the Norn cell , named after the Norse deities who were believed to control human fate.
It took humans 134 years to discover Norn cells. Last summer, computers in California discovered them on their own in just six weeks.
The discovery came about when researchers at Stanford programmed the computers to teach themselves biology. The computers ran an artificial intelligence program similar to ChatGPT, the popular bot that became fluent with language after training on billions of pieces of text from the internet. But the Stanford researchers trained their computers on raw data about millions of real cells and their chemical and genetic makeup.
The researchers did not tell the computers what these measurements meant. They did not explain that different kinds of cells have different biochemical profiles. They did not define which cells catch light in our eyes, for example, or which ones make antibodies.
The computers crunched the data on their own, creating a model of all the cells based on their similarity to each other in a vast, multidimensional space. When the machines were done, they had learned an astonishing amount . They could classify a cell they had never seen before as one of over 1,000 different types. One of those was the Norn cell.
“That’s remarkable, because nobody ever told the model that a Norn cell exists in the kidney,” said Jure Leskovec, a computer scientist at Stanford who trained the computers.
The software is one of several new A.I.-powered programs, known as foundation models, that are setting their sights on the fundamentals of biology. The models are not simply tidying up the information that biologists are collecting. They are making discoveries about how genes work and how cells develop.
As the models scale up, with ever more laboratory data and computing power, scientists predict that they will start making more profound discoveries. They may reveal secrets about cancer and other diseases. They may figure out recipes for turning one kind of cell into another.
“A vital discovery about biology that otherwise would not have been made by the biologists — I think we’re going to see that at some point,” said Dr. Eric Topol, the director of the Scripps Research Translational Institute.
Just how far they will go is a matter of debate. While some skeptics think the models are going to hit a wall, more optimistic scientists believe that foundation models will even tackle the biggest biological question of them all: What separates life from nonlife?
Heart Cells and Mole Rats

Biologists have long sought to understand how the different cells in our bodies use genes to do the many things we need to stay alive.
About a decade ago, researchers started industrial-scale experiments to fish out genetic bits from individual cells. They recorded what they found in catalogs, or “ cell atlases ,” that swelled with billions of pieces of data.
Dr. Christina Theodoris, a medical resident at Boston Children’s Hospital, was reading about a new kind of A.I. model made by Google engineers in 2017 for language translations. The researchers provided the model with millions of sentences in English, along with their translations into German and French. The model developed the power to translate sentences it hadn’t seen before. Dr. Theodoris wondered if a similar model could teach itself to make sense of the data in cell atlases.
In 2021, she struggled to find a lab that might let her try to build one. “There was a lot of skepticism that this approach would work at all,” she said.
Shirley Liu, a computational biologist at the Dana-Farber Cancer Institute in Boston, gave her a shot. Dr. Theodoris pulled data from 106 published human studies, which collectively included 30 million cells, and fed it all into a program she created called GeneFormer.
The model gained a deep understanding of how our genes behave in different cells. It predicted, for example, that shutting down a gene called TEAD4 in a certain type of heart cell would severely disrupt it. When her team put the prediction to the test in real cells called cardiomyocytes, the beating of the heart cells grew weaker.
In another test, she and her colleagues showed GeneFormer heart cells from people with defective heartbeat rhythms as well as from healthy people. “Then we said, Now tell us what changes we need to happen to the unhealthy cells to make them healthy,” said Dr. Theodoris, who now works as a computational biologist at the Gladstone Institutes in San Francisco.
GeneFormer recommended reducing the activity of four genes that had never before been linked to heart disease. Dr. Theodoris’s team followed the model’s advice, knocking down each of the four genes. In two out of the four cases, the treatment improved how the cells contracted.
The Stanford team got into the foundation-model business after helping to build one of the biggest databases of cells in the world, known as CellXGene . Beginning in August, the researchers trained their computers on the 33 million cells in the database, focusing on a type of genetic information called messenger RNA. They also fed the model the three-dimensional structures of proteins, which are the products of genes.
From this data, the model — known as Universal Cell Embedding, or U.C.E. — calculated the similarity among cells, grouping them into more than 1,000 clusters according to how they used their genes. The clusters corresponded to types of cells discovered by generations of biologists.
U.C.E. also taught itself some important things about how the cells develop from a single fertilized egg. For example, U.C.E. recognized that all the cells in the body can be grouped according to which of three layers they came from in the early embryo.
“It essentially rediscovered developmental biology,” said Stephen Quake, a biophysicist at Stanford who helped develop U.C.E.
The model was also able to transfer its knowledge to new species. Presented with the genetic profile of cells from an animal that it had never seen before — a naked mole rat, say — U.C.E. could identify many of its cell types.
“You can bring a completely new organism — chicken, frog, fish, whatever — you can put it in, and you will get something useful out,” Dr. Leskovec said.
After U.C.E. discovered the Norn cells, Dr. Leskovec and his colleagues looked in the CellXGene database to see where they had come from. While many of the cells had been taken from kidneys, some had come from lungs or other organs. It was possible, the researchers speculated, that previously unknown Norn cells were scattered across the body.
Dr. Katalin Susztak, a physician-scientist at the University of Pennsylvania who studies Norn cells, said that the finding whetted her curiosity. “I want to check these cells,” she said.
She is skeptical that the model found true Norn cells outside the kidneys, since the erythropoietin hormone hasn’t been found in other places. But the new cells may sense oxygen as Norn cells do.
In other words, U.C.E. may have discovered a new type of cell before biologists did.
An ‘Internet of Cells’
Just like ChatGPT , biological models sometimes get things wrong. Kasia Kedzierska, a computational biologist at the University of Oxford, and her colleagues recently gave GeneFormer and another foundation model , scGPT, a battery of tests . They presented the models with cell atlases they hadn’t seen before and had them perform tasks such as classifying the cells into types. The models performed well on some tasks, but in other cases they fared poorly compared with simpler computer programs.
Dr. Kedzierska said she had great hopes for the models but that, for now, “they should not be used out of the box without a proper understanding of their limitations.”
Dr. Leskovec said that the models were improving as scientists trained them on more data. But compared with ChatGPT’s training on the entire internet, the latest cell atlases offer only a modest amount of information. “I’d like an entire internet of cells,” he said.
More cells are on the way as bigger cell atlases come online. And scientists are gleaning different kinds of data from each of the cells in those atlases. Some scientists are cataloging the molecules that stick to genes, or taking photographs of cells to illuminate the precise location of their proteins. All of that information will allow foundation models to draw lessons about what makes cells work.
Scientists are also developing tools that let foundation models combine what they’re learning on their own with what flesh-and-blood biologists have already discovered. The idea would be to connect the findings in thousands of published scientific papers to the databases of cell measurements.
With enough data and computing power, scientists say, they may eventually create a complete mathematical representation of a cell.
“That’s going to be hugely revolutionary for the field of biology,” said Bo Wang, a computational biologist at the University of Toronto and the creator of scGPT. With this virtual cell, he speculated, it would be possible to predict what a real cell would do in any situation. Scientists could run entire experiments on their computers rather than in petri dishes.
Dr. Quake suspects that foundation models will learn not just about the kinds of cells that currently reside in our bodies but also about kinds of cells that could exist. He speculates that only certain combinations of biochemistry can keep a cell alive. Dr. Quake dreams of using foundation models to make a map showing the realm of the possible, beyond which life cannot exist.
“I think these models are going to help us get some really fundamental understanding of the cell, which is going to provide some insight into what life really is,” Dr. Quake said.
Having a map of what’s possible and impossible to sustain life might also mean that scientists could actually create new cells that don’t yet exist in nature. The foundation model might be able to concoct chemical recipes that transform ordinary cells into new, extraordinary ones. Those new cells might devour plaque in blood vessels or explore a diseased organ to report back on its condition.
“It’s very ‘Fantastic Voyage ’- ish,” Dr. Quake admitted. “But who knows what the future is going to hold?”
If foundation models live up to Dr. Quake’s dreams, they will also raise a number of new risks. On Friday, more than 80 biologists and A.I. experts signed a call for the technology to be regulated so that it cannot be used to create new biological weapons. Such a concern might apply to new kinds of cells produced by the models.
Privacy breaches could happen even sooner. Researchers hope to program personalized foundation models that would look at an individual’s unique genome and the particular way that it works in cells. That new dimension of knowledge could reveal how different versions of genes affect the way cells work. But it could also give the owners of a foundation model some of the most intimate knowledge imaginable about the people who donated their DNA and cells to science.
Some scientists have their doubts about how far foundational models will make it down the road to “Fantastic Voyage,” however. The models are only as good as the data they are fed. Making an important new discovery about life may depend on having data on hand that we haven’t figured out how to collect. We might not even know what data the models need.
“They might make some new discoveries of interest,” said Sara Walker, a physicist at Arizona State University who studies the physical basis of life. “But ultimately they are limited when it comes to new fundamental advances.”
Still, the performance of foundation models has already led their creators to wonder about the role of human biologists in a world where computers make important insights on their own. Traditionally, biologists have been rewarded for creative and time-consuming experiments that uncover some of the workings of life. But computers may be able to see those workings in a matter of weeks, days or even hours by scanning billions of cells for patterns we can’t see.
“It’s going to force a complete rethink of what we consider creativity,” Dr. Quake said. “Professors should be very, very nervous.”
Carl Zimmer covers news about science for The Times and writes the Origins column . More about Carl Zimmer
Explore Our Coverage of Artificial Intelligence
News and Analysis
Amazon said it had added $2.75 billion to its investment in Anthropic , an A.I. start-up that competes with companies like OpenAI and Google.
Gov. Bill Lee of Tennessee signed a bill to prevent the use of A.I. to copy a performer’s voice. It is the first such measure in the United States.
French regulators said Google failed to notify news publishers that it was using their articles to train its A.I. algorithms, part of a wider ruling against the company for its negotiating practices with media outlets.
Apple is in discussions with Google about using Google’s generative A.I. model called Gemini for its next iPhone.
The Age of A.I.
The Caribbean island Anguilla made $32 million last year, more than 10 percent of its G.D.P., from companies registering web addresses that end in .ai .
When it comes to the A.I. that powers chatbots like ChatGPT, China trails the United States. But when it comes to producing the scientists behind a new generation of humanoid technologies, China is pulling ahead . Silicon Valley leaders are lobbying Congress on the dangers of falling behind .
By interacting with data about genes and cells, A.I. models have made some surprising discoveries and are learning what it means to be alive. What could they teach us someday ?
Covariant, a robotics start-up, is using the technology behind chatbots to build robots that learn skills much like ChatGPT does.
Advertisement
IMAGES
VIDEO
COMMENTS
The purpose of annotating data is to tell machine learning models exactly what we want them to know. Teaching a machine to learn through annotation can be likened to teaching a toddler shapes and colors using flashcards, where the annotations are the flashcards and annotators are the teacher. Of course, this is a simplified example of how AI ...
In machine learning, the task of data annotation usually falls into the category of supervised learning, where the learning algorithm associates input with the corresponding output, and optimizes itself to reduce errors. Types of data annotations. Here are various types of data annotation and their characteristics. Image annotation
Data annotation for machine learning is the process of labeling or tagging data to make it understandable and usable for machine learning algorithms. This involves adding metadata, such as categories, tags, or attributes, to raw data, making it easier for algorithms to recognize patterns and learn from the data.
Different annotation techniques, such as image annotation, text annotation, video annotation, and audio annotation, are used to train machine learning models in various domains. The challenges associated with data annotation, including annotation quality , scalability, subjectivity , consistency, and privacy and security , must be addressed to ...
Data labeling, or data annotation, is part of the preprocessing stage when developing a machine learning (ML) model. Data labeling requires the identification of raw data (i.e., images, text files, videos), and then the addition of one or more labels to that data to specify its context for the models, allowing the machine learning model to make ...
What is the Importance of Data Annotation in Machine Learning? Data annotation is a critical component in machine learning as it serves as the foundation for training models. Without properly annotated data, machine learning algorithms would struggle to understand and interpret the input. Accurate and comprehensive data annotation ensures that ...
As machine learning continues to advance and find applications in various industries, the importance of data annotation will only grow. Accurate and reliable annotated data is the foundation on which machine learning models are built, enabling them to understand and interpret complex information.
In machine learning, data annotation is the process of labeling data to show the outcome you want your machine learning model to predict. You are marking - labeling, tagging, transcribing, or processing - a dataset with the features you want your machine learning system to learn to recognize. Once your model is deployed, you want it to ...
In machine learning, data annotation is the process of detecting raw data i.e. images, videos, text files, etc. and tagging them. Tags i.e. labels are identifiers that give meaning and context to the data. That's what helps the machine learning model learn from it. In other words, data labeling is the process of creating training data for a ...
Although data annotation is broad and wide, there are common annotation types in popular machine learning projects which we are looking at in this section to give you the gist in this field: Semantic Annotation. Semantic annotation entails annotation of different concepts within text, such as names, objects, or people.
In the world of machine learning, both data labeling and annotation are indispensable. They transform raw data into a structured format that machine learning algorithms can interpret and learn from. This structured data acts as a guide, helping algorithms understand patterns and make predictions. For a clearer picture, consider a self-driving car.
Data annotation stands as the cornerstone of AI and machine learning, entailing the crucial task of labeling data for accurate classification. This process is instrumental in not only enhancing ...
Data annotation plays a crucial role in the success of machine learning models by providing labeled data that helps them learn and make accurate predictions. Here are some key reasons why data annotation is essential in machine learning: 1. Training Machine Learning Models: Machine learning models rely on labeled data to learn patterns and make ...
The Complete Guide to Data Annotation [2024 Review] Data annotation is integral to the process of training a machine learning (ML) or computer vision model (CV). Datasets often include many thousands of images, videos, or both, and before an algorithmic-based model can be trained, these images or videos need to be labeled and annotated accurately.
Twinkle, Twinkle, Little Star: The Best Annotation Tools for Machine Learning. Now that we discussed the "how", let's look at "what". We compiled a list of the best annotation tools out on the market considering their pros and cons, as well as all the criteria we've talked about above, from pricing to the high quality to functionality.
To be precise, Data annotation helps the machine to recognize data in its correct form. Hence, it becomes an essential and important step in any machine learning model.
The advent of AI Data Annotation has heralded a new era in machine learning, unlocking a trove of benefits that propel AI from concept to application. At its core, data annotation enriches machine learning models with the acumen to discern, learn, and make decisions that mirror human intelligence. This meticulous process of tagging data across ...
Data annotation is the process of labeling elements of data ( images, videos, text, or any other format) by adding contextual information which ML models can learn from. It helps ML models understand what exactly is important about each piece of data. To fully grasp and appreciate everything data labelers do and what data annotation skills they ...
Text annotation in machine learning refers to adding metadata or labels to raw textual data to create structured datasets for training, evaluating, and improving machine learning models. It is a crucial step in natural language processing (NLP) tasks, as it helps algorithms understand, interpret, and make predictions based on textual inputs. ...
Because it is so commonly used, text annotation needs to be done with accuracy and comprehensiveness. With machine learning (ML), machines are taught how to read, understand, analyze, and produce text in a valuable way for technological interactions with humans. Per the 2020 State of AI and Machine Learning report, 70% of companies reported ...
Because it is so commonly used, text annotation needs to be done with accuracy and comprehensiveness.With machine learning (ML), machines are taught how to read, understand, analyze, and produce text in a valuable way for technological interactions with humans. Per the 2020 State of AI and Machine Learning report, 70% of companies reported that ...
In image segmentation machine learning models require both human and machine intelligence. This is called a human-in-the-loop model, where human judgment is used to continuously improve the performance of a machine learning model. Likewise, the process of data annotation needs humans. Human-annotated data powers machine learning.
Data annotation is a crucial process in training machine learning models. It involves labeling individual elements of training data, such as text, images, audio, or video, to help machines understand what the data contains.
Labeling and annotation platforms might not get the attention flashy new generative AI models like OpenAI's Sora do. But they're essential. Without them, modern AI models arguably wouldn't ...
In this course, Wuraola Oyewusi dives into the intricacies of data annotation for machine learning and shows how data is prepared and used for training of machine learning models. Wuraola starts with a big-picture look at the principles, types, and importance of data annotation in machine learning pipelines.
Human-Computer Interaction has been shown to lead to improvements in machine learning systems by boosting model performance, accelerating learning and building user confidence. In this work, we aim to alleviate the expectation that human annotators adapt to the constraints imposed by traditional labels by allowing for extra flexibility in the form that supervision information is collected. For ...
Bansal said Allen-Blanchette's code is a good example of the typical project where he and Acharya can take machine learning code and make it more reproducible, maintainable, and sustainable. "Between Skinnider's code and Christine's code, we have codes in shape where we can be almost 100 percent sure there's no bugs in the code ...
Anomaly detection in machine learning is the process of using machine learning models to identify anomalies rapidly. This serves several purposes, whether to maintain clean, high-quality data that you will use for processing or specific business purposes. By ensuring quality data, organizations can have trust in their analysis, leading to ...
What is a model card in machine learning? A model card is a type of documentation that is created for, and provided with, machine learning models. A model card functions as a type of data sheet, similar in principle to the consumer safety labels, food nutritional labels, a material safety data sheet or product spec sheets.
Just like ChatGPT, biological models sometimes get things wrong.Kasia Kedzierska, a computational biologist at the University of Oxford, and her colleagues recently gave GeneFormer and another ...