
Precision and recall at K in ranking and recommendations
on this page
Precision and Recall at K are common metrics that help evaluate the performance of ranking algorithms. If you are familiar with classification models, the approach is very similar.
In this guide, we’ll explain them in detail.
We also introduce Evidently , an open-source Python library for ML model evaluation and monitoring.
- Precision and Recall at K help evaluate the quality of recommender and ranking systems.
- Precision at K measures how many items with the top K positions are relevant.
- Recall at K measures the share of relevant items captured within the top K positions.
- You can also use the F-score to get a balanced measure of Precision and Recall at K.
- Precision, Recall, and F-score can take values from 0 to 1. Higher values mean better performance.
- However, Precision and Recall only reflect the number of relevant items in the top K without evaluating the ranking quality inside a list.

Want to keep tabs on your production ML models? Try Evidently, an open-source ML monitoring tool with 5m+ downloads.
Imagine you're doing your usual weekly online grocery shop. As you are about to check out, you see a list of items conveniently presented with a suggestion to add to your cart. You might see fresh produce like avocados, spinach, and tomatoes. Another user might get a recommendation to buy ice cream, chocolate, and cheese.
Which set of recommendations is a better one? And, if you are developing the system to produce these suggestions for each and every user – how do you know if you are doing a good job?
Precision and Recall are the two classic metrics to evaluate the quality of recommendations. They behave the same as Precision and Recall in classification.
Let’s unpack them step by step.

Precision at K
Precision at K is the ratio of correctly identified relevant items within the total recommended items inside the K-long list. Simply put, it shows how many recommended or retrieved items are genuinely relevant.
Here is a formula:

You calculate Precision at K by taking the number of relevant items within the top-k recommendations and dividing it by K.
The K is the arbitrary cut-off rank you can choose to limit your evaluation. This is often practical when you expect the user to engage only with a limited number of items shown to them. Suppose you only display top-6 recommendations in the recommendation block next to the basket checkout on the e-commerce website. In that case, you can evaluate the recall and precision for the first six recommendations and set the "K" to 6.
The relevance is a binary label that is specific to your use case. For example, you might consider the items the user clicked on, added to the cart, or purchased to be relevant.
In our example above, we might see that the user bought two of the suggested items. The Precision at six would be 2/6 = 0.33.

Precision answers the question: Out of the top-k items suggested, how many are actually relevant to the user?
Once you compute Precision for the individual user lists or queries, you can average it across all users or queries to get the overall system performance assessment.
Precision example
Let's take another simple example . Suppose you're dealing with a top-10 recommendation scenario. Out of 10 recommended items, the user interacted with 6 items – we will treat this as a binary signal of relevance. In this case, the Precision at 10 is 60%. Out of 10 recommendations, 6 were good ones. The system is doing a decent job.
What if we zoom in on the top 5 recommendations only? In this subset, the user interacted with 4 out 5 items. The Precision at 5 is then 80%.

As you can notice, the specific choice of K affects the calculation result – sometimes significantly.
What is K, and what is the relevance? Check out the introduction to evaluating recommendation systems .
Pros and cons
Choosing Precision at K as an evaluation metric has its pros and cons.
Interpretability. It’s easy to understand Precision. This makes it a suitable metric for communicating the system quality to stakeholders and users.
Focus on accuracy. Precision effectively conveys the correctness of recommendations. Choose this metric to track how many recommended items inside K are relevant, regardless of the order.
No rank awareness. On the downside, Precision does not help much if you care about ranking quality inside the list. It does not consider which exact positions relevant items occupy. Precision will yield the same result as long as the total number of relevant items in K is the same.
Let’s take two lists with the same number of relevant results (5 out of 10). In the first list, the relevant items are at the very top. In the second, they are at the very bottom of the list. The Precision will be 50% in both cases.

This behavior is often not optimal. You might expect the system to be able to place more relevant items on top. In this case, you can choose a different evaluation metric that rewards such behavior: for example, rank-aware evaluation metrics like NDCG or MAP.
Want an introduction to rank-aware metrics? Check out the deep dive into NDCG and a guide to MAP .
Sensitivity to the number of relevant items. The Precision value at K may vary across different lists since it depends on the total number of relevant items in each. You might have a few relevant items for some users while lots for others. Because of this, averaging the Precision across lists might be unpredictable and won’t accurately reflect the ability of the system to make suitable recommendations.
In addition, it is impossible to reach perfect Precision when the K is larger than the total number of relevant items in the dataset. Say you look at the top 10 recommendations while the total number of relevant items in the dataset is 3. Even if the system can find them all and correctly place them at the top of the list, the Precision at ten will be only 30%.
At the same time, this is the maximum achievable Precision for this list – and you can consider it a great result! Metrics like MAP and NDCG can address this limitation: in the case of perfect ranking, the MAP and NDCG at K will be 1.
Summing up. Precision at K is a good measure when you want to check how accurate the model recommendations are without getting into the details of how well the items are ranked.
Precision is usually suitable when the expected number of relevant items is large, but the user's attention is limited. For instance, if you have thousands of different products but plan to show only the top 5 recommendations to the user, Precision at K helps evaluate how good your shortlist is.
Recall at K
Recall at K measures the proportion of correctly identified relevant items in the top K recommendations out of the total number of relevant items in the dataset. In simpler terms, it indicates how many of the relevant items you could successfully find.

You can calculate the Recall at K by dividing the number of relevant items within the top-k recommendations by the total number of relevant items in the entire dataset. This way, it measures the system's ability to retrieve all relevant items in the dataset.
As with Precision, the K represents a chosen cut-off point of the top ranks you consider for evaluation. Relevance is a binary label specific to the use case, such as click, purchase, etc.
Recall at K answers the question: Out of all the relevant items in the dataset, how many could you successfully include in the top-K recommendations?
Recall example
Let's use a simple example to understand Recall at K. Imagine you have a list of top 10 recommendations, and there are a total of 8 items in the dataset that are actually relevant.

If the system includes 5 relevant items in the top 10, the Recall at 10 is 62.5% (5 out of 8).
Now, let's zoom in on the top 5 recommendations. In this shorter list, we have only 3 relevant suggestions. The Recall at 5 is 37.5% (3 out of 8). This means the system captured less than half of the relevant items within the top 5 recommendations.

Here are some pros and cons of the Recall at K metric.
Interpretability. Recall at K is easy to understand. This makes it accessible to non-technical users and stakeholders.
Focus on coverage. If you want to know how many relevant items (out of their total possible number) the system captures in the top K results, Recall effectively communicates this.
There are scenarios when you prefer Recall to Precision. For example, if you deal with search engines where you expect many possible good results, Precision is a great metric to focus on. But if you deal with more narrow information retrieval, like legal search or finding a document on your laptop, Recall (the ability to detect all relevant documents that match a given query) could be more critical, even at the course of lower precision.
No rank awareness . Like precision, Recall is indifferent to the order of relevant items in the ranking. It cares about capturing as many relevant items as possible within the top K, regardless of their specific order.
Requires knowing the number of all relevant items. To compute Recall, you need to know all the actual ranks for items in the list. You cannot always do this; for example, you do not know the true relevance score for items the user did not see.
Sensitivity to the total number of relevant items. Similar to Precision, the achievable Recall at K varies based on the total number of relevant items in the dataset. If the total number of relevant items is larger than K, you cannot reach the perfect Recall.
Say you look at the top 5 recommendations for a dataset with 10 relevant items. Even if all of the recommendations in the top 5 are relevant, the Recall will be at most 50%. In such cases, choosing a metric like precision could be more appropriate.
Additionally, this variability of Recall can also cause issues when averaging Recall across users and lists with varying numbers of relevant items.
Summing up. Recall at K is a valuable measure to help assess how many relevant items the system successfully captured in the top K. It does not consider their rankings. Recall is well-suited for situations with a finite number of relevant items you expect to capture in the top results. For example, in information retrieval, when there is a small number of documents that match a specific user query, you might be interested in tracking that all of them appear in the top system responses.
As explained above, Precision and Recall at K help capture different aspects of the ranking or recommender system performance. Precision focuses on how accurate the system is when it recommends items, while recall emphasizes capturing all relevant items, even if it means recommending some irrelevant ones.
Sometimes, you want to account for both at the same time.
The F Beta score at K combines these two metrics into a single value to provide a balanced assessment. The Beta parameter allows you to adjust the importance given to recall relative to precision.
Here is the formula:

A Beta greater than 1 prioritizes recall, whereas a Beta less than 1 favors precision. When Beta is 1, it becomes a traditional F1 score, a harmonic mean of precision and recall.
The resulting score ranges from 0 to 1. A higher F Beta at K means better overall performance, considering both false positives and false negative errors.
Want to understand other metrics? Start with this overview guide .
Evaluating ranking with Evidently
Evidently is an open-source Python library that helps evaluate, test and monitor machine learning models, including ranking and recommendations. Evidently computes and visualizes 15+ different ranking metrics, from Precision and Recall to behavioral metrics like serendipity and diversity.
By passing your dataset, you can quickly generate a comprehensive report with multiple metrics and interactive visualizations out of the box.

You can also use Evidently to run CI/CD tests, for example, to evaluate the model quality after retraining and deploy a live monitoring dashboard to keep track of the model metrics and test results over time.
Would you like to learn more? Check out the open-source Getting Started tutorials .
[fs-toc-omit]Try Evidently Cloud
Don’t want to deal with deploying and maintaining the ML monitoring service? Sign up for the Evidently Cloud, a SaaS ML observability platform built on top of Evidently open-source. Get early access ⟶
Mean Average Precision (MAP)
Mean Average Precision (MAP) at K reflects both the share of relevant recommendations and how good the system is at placing more relevant items at the top of the list. You can compute it as the mean of Average Precision (AP) across all users or queries.

Normalized Discounted Cumulative Gain (NDCG)
Normalized discounted cumulative gain (NDCG) at K reflects the ranking quality by comparing it to an ideal order where all relevant items are at the top. Unlike other ranking metrics, NDCG can work for both binary and graded relevance scores.

Machine Learning Interviews
Tools to crack your data science Interviews
MAP at K : An evaluation metric for Ranking
This video talks about the Mean Average Precision at K (popularly called the MAP@K) metric that is commonly used for evaluating recommender systems and other ranking related problems.
Why do we need Mean Average Precision@K metric?
Traditional classification metrics such as precision, in the context of recommender systems can be used to see how many of the recommended items are relevant. But precision fails to capture the order in which items are recommended.
Customers have a short attention span – and it is important to check if the right items are being recommended at the top!
For a more detailed post on evaluating recommender systems in general, checkout out this post on evaluation metrics for recommender systems.
How does MAP@K metric work?
The MAP@K metric stands for the Mean Average Precision at K and evaluates the following aspects:
- Are the predicted items relevant?
- Are the most relevant items at the top?
What is Precision ?
Precision in the context of a recommender system measures what percent of the recommended items are relevant.
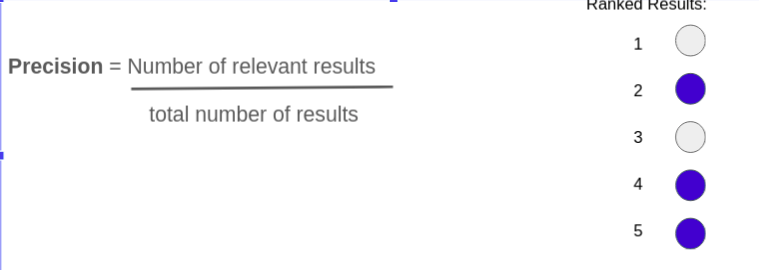
What is precision@K?
Precision@K is the fraction of relevant items in the top K recommended results.
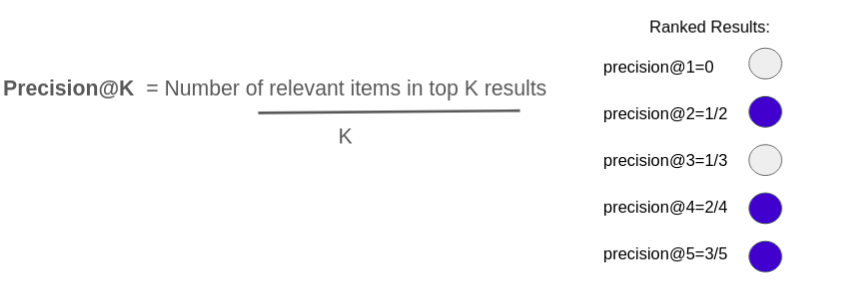
What is Average Precision@K ?
AP@K is the sum of precision@K for different values of K divided by the total number of relevant items in the top K results.

Mean Average Precision@K
The mean average precision@K measures the average precision@K averaged over all queries (for the entire dataset). For instance, lets say a movie recommendation engine shows a list of relevant movies that the user hovers over or not.
The MAP@K metric measures the AP@K for recommendations shown for different users and averages them over all queries in the dataset.
The MAP@K metric is the most commonly used metric for evaluating recommender systems.
Another popular metric that overcomes some of the shortcomings of the MAP@K metric is the NDCG metric – click here for more on NDCG metric for evaluating recommender systems.
Related References for Mean Average Precision
Wikipedia page on metrics based on Average Precision for recommender systems
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Notify me of follow-up comments by email.
Notify me of new posts by email.
Sign-In With Your Social ID
We hope you enjoy going through our content as much as we enjoy making it !
More high-quality content once you subscribe
Evaluating Recommendation Systems - Precision@k, Recall@k, and R-Precision
Imagine you’re given three movie recommendations from separate algorithms. In the first one (A) you’re given: The Terminator, James Bond, and Star Wars. In the second (B) you’re given: Cars, Toy Story, and Iron Man -- Which recommendation is more relevant to you?

If someone had previously watched movies like: Avengers, Top Gun, and Star Wars, they’re probably going to enjoy the movies on the first list more. We assume this because our prior understanding of the movies (e.g. genre, cast, set) allows us to evaluate which list is most similar to the historical watch list. However, imagine you knew a majority of people that previously watched the same movies and happened to also enjoy the movies on the second recommendation list, you might conclude that the second recommendation list is actually more relevant. These two ways of deciding relevance are what recommendation systems aim to learn from your data [1].

How can we objectively measure which recommendation algorithm is best to serve to your user? One way to evaluate the algorithms offline [2] is through a process called ”cross-validation”, where the historical watch list (i.e. the list of relevant items) is chronologically split [3] into train and test sets. The recommendation algorithms are trained on the train set and performance metrics are evaluated on the test set. These performance metrics can then be used to objectively measure which algorithm is more relevant. Continuing on with the example, let’s assume that the test set for the user in question contains: The Terminator, James Bond, Iron Man, and 3 other unrelated movies. We can measure performance by comparing the matches between the evaluation set and both recommendation lists. Two classic metrics that are used are: Precision@k and Recall@k .
Precision@k
Precision@k measures the proportion of relevant recommended items in a recommendation list of size k . For the first recommendation list (The Terminator, James Bond, and Love Actually), we can see that there are 2 matches out of the 3 items. For the second list, there is 1 matches out of the 3 items. Therefore:
- Algorithm A, Precision@3 = 2/3 = 0.666
- Algorithm B, Precision@3 = 1/3 = 0.333

Recall@k The other way we can define matches is based on the proportion of relevant recommended items (in the recommendation list of size k) and the total number of relevant items. This metric is called recall@k . For example, the user has watched 6 movies, and in the first recommendation list, 2 of them are relevant. In the second list, 1 of them are relevant. Therefore:
- Algorithm A, Recall@3 = 2/6 = 0.333
- Algorithm B, Recall@3 = 1/6 = 0.166

In our example, algorithm A is more relevant because it has higher Recall@k and Precision@k. We didn’t really need to compute both to understand this, if you look closely you’ll notice that if one of these metrics is comparatively higher to another algorithm then the other metric will be equal or higher too. Regardless, it’s typically worthwhile looking at both of these metrics for the interpretable understanding they provide. Precision@k gives us an interpretable understanding of how many items are actually relevant in the final k recommendations we show to a user. If you are confident on your choice of k, it typically maps to the final recommendation well and it’s easy to communicate. The problem is that it’s strongly influenced by how many relevant items the user has. For example, imagine our user only watched 2 relevant items, the maximum Precision@3 they could achieve with a perfect recommendation system is capped at: Precision@3 = 2/3 = 0.666. This causes issues when averaging the result across multiple users. The best of both worlds: R-Precision A metric that solves these issues with Precision is called R-Precision. It adjusts k to the length of the user’s relevant items. For our example in the last paragraph (where the user has only watched 2 movies), this means that we have R-Precision=2/2=1, for a perfect recommendation system, which is what we’d expect.
R-Precision = (number of relevant recommended top-r items) / r Where r is the total number of relevant items.
Note that when r = k, Precision@k, Recall@k and R-Precision are all equal. When we have a fixed budget of recommendations k, like in the example we’re running with, you probably want to cap k. This capped metric, R-Precision@k, can be thought of as Recall@r when the number of relevant items is less than k and Precision@k when it’s greater than k. It gives us a best of both worlds of the two metrics and averages well across users.

What’s next The metrics we’ve gone over today: Precision@k, Recall@k, R-Precision, are classic ways of evaluating the accuracy of two unordered sets of recommendations with fixed k. However, ranking order can be crucial to evaluate the quality of recommendations to your users, particularly for recommendation use-cases where there’s minimal surface area to show your recommendations and every rank position matters. Alternate objectives such a diversity and bias also need to be considered beyond the relevance accuracy metrics we talked about today. Finally, all these metrics are great for offline evaluation with cross-validation but it’s important not to forget about online evaluation — that is, measuring the results after you’ve started surfacing the recommendations directly to users. In the next posts, we’ll discuss each of these recommendation evaluation topics. Stay tuned!
Written in collaboration with Nina Shenker-Tauris. Footer:
1. The first method, where similarity of content is used to determine what’s relevant is called “Content-based filtering”. The second method, where the people’s shared interests are used to determine what’s most relevant is called “Collaborative filtering”.
2. As opposed to online, where we surface the recommendations directly to the users
3. We use a chronological split to ensure that information about historic data isn’t leaked in the test set.
4. Note we define all metrics for a specific user but in practice they’re often defined as averages across every user in the test set.
Get up and running in just 1 sprint 🏃
For developers.

For companies 🏢
Related posts.

Embracing Embeddings: From fragmented insights to unified understanding

RAG for RecSys: a magic formula?

Search the way you think: how personalized semantic search is disrupting traditional search
Precision@k and Recall@k Made Easy with 1 Python Example For those who prefer a video presentation, you can see me work through the material in this post here: What are Precision@k and Recall@K ?
Precision@k and Recall@k are metrics used to evaluate a recommender model. These quantities attempt to measure how effective a recommender is at providing relevant suggestions to users.
The typical workflow of a recommender involves a series of suggestions that will be offered to the end user by the model. Examples of these suggestions could consist of movies to watch, search engine results, potential cases of fraud, etc. These suggestions could number in the 100’s or 1000’s; far beyond the abilities of a typical user to cover in their entirety. The details for how recommenders work is beyond the scope of this article.
Instead of looking at the entire set of possible recommendations, with precision@k and recall@k we’ll only consider the top k suggested items. Before defining these metrics, let’s clarify a few terms:
- Recommended items are items that our model suggests to a particular user
- Relevant items are items that were actually selected by a particular user
- @k , literally read “at k “, where k is the integer number of items we are considering
Now let’s define precision@k and recall@k:
\text{precision@k} = \frac{\text{number of recommended items that are relevant @k}}{\text{number of recommended items @k}} (1)
\text{recall@k} = \frac{\text{number of recommended items that are relevant @k}}{\text{number of all relevant items}} (2)
It is apparent that precision@k and recall@k are binary metrics , meaning they are defined in terms of relevant and non-relevant items with respect to the user. They can only be computed for items that a user has actually rated. Precision@k measures what percentage of recommendations produced were actually selected by the user . Conversely, recall@k measures the fraction of all relevant items that were suggested by our model .
In a production setting, recommender performance can be measured with precision@k and recall@k once feedback is obtained on at least k items. Prior to deployment, the recommender can be evaluated on a held-out test set.
Python Example
Let’s work through a simple example in Python, to illustrate the concepts discussed. We can begin by considering a simple example involving movie recommendations . Imagine we have a pandas dataframe containing actual user movie ratings ( y_actual ), along with predicted ratings from a recommendation model ( y_recommended ). These ratings can range from 0.0 (very bad) to 4.0 (very good):

Because ratings are an ordeal quantity , we will be primarily interested in the most highly recommended items first. As such, the following preprocessing steps will be required:
- Sort the dataframe by y_recommended in descending order
- Remove rows with missing values
- Convert ratings into a binary quantity ( not-relevant , relevant )
We can write some code to implement these steps. I will be considering all ratings of 2.0 or greater to be ‘ relevant ‘. Conversely, ratings below this threshold will be termed ‘ non-relevant ‘:

Great, we can now work through an implementation of precision@k and recall@k:
We can try out these implementations for k = 3 , k = 10 , and k = 15 :
We can see the results for k = 3 , k = 10 , and k = 15 above. For k = 3 , it is apparent that 67% of our recommendations are relevant to the user, and captures 18% of the total relevant items present in the dataset. For k = 10 , 80% of our recommendations are relevant to the user, and captures 73% of all relevant items in the dataset. These quantities increase yet further for the k = 15 case.
Note that our sorting and conversion preprocessing steps are only required when dealing with a ordeal label, like ratings. For problems like fraud detection or lead scoring , where the labels are already binary, these steps are not needed. In addition, I have implemented the precision and recall functions to return None if the denominator is 0, since a sensible calculation cannot be made in this case.
These metrics become useful in a live production environment, where capacity to measure the performance of a recommendation model is limited. For example, imagine a scenario where a movie recommender is deployed that can provide 100 movie recommendations per user, per week. However, we are only able to obtain 10 movie ratings from the user during the same time period. In this case, we can measure the weekly performance of our model by computing precision@k and recall@k for k = 10 .
Related Posts
- 6 Methods to Measure Performance of a Classification Model
- Build a Bagging Classifier in Python from Scratch
- A Complete Introduction to Cross Validation in Machine Learning

Privacy Overview
Euclidean embedding with preference relation for recommender systems
- Published: 02 April 2024
Cite this article
- V Ramanjaneyulu Yannam 1 ,
- Jitendra Kumar 1 ,
- Korra Sathya Babu 2 na1 &
- Bidyut Kumar Patra 1 na1
Recommender systems (RS) help users pick the relevant items among numerous items that are available on the internet. The items may be movies, food, books, etc. The Recommender systems utilize the data that is fetched from the users to generate recommendations. Usually, these ratings may be explicit or implicit. Explicit ratings are absolute ratings that are generally in the range of 1 to 5. While implicit ratings are derived from information like purchase history, click-through rate, viewing history, etc. Preference relations are an alternative way to represent the users’ interest in the items. Few recent research works show that preference relations yield better results compared to absolute ratings. Besides, in RS, the latent factor models like Matrix Factorization (MF) give accurate results especially when the data is sparse. Euclidean Embedding (EE) is an alternative latent factor model that yields similar results as MF. In this work, we propose a Euclidean embedding with preference relation for the recommender system. Instead of using the inner product of items and users’ latent factors, Euclidean distances between them are used to predict the rating. Preference Relations with Matrix Factorization (MFPR) produced better recommendations compared to that of traditional matrix factorization. We present a collaborative model termed EEPR in this work. The proposed framework is implemented and tested on two real-world datasets, MovieLens-100K and Netflix-1M to demonstrate the effectiveness of the proposed method. We utilize popular evaluation metric for recommender systems as precision@K. The experimental outcomes show that the proposed model outperforms certain state-of-the-art existing models such as MF, EE, and MFPR.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price excludes VAT (USA) Tax calculation will be finalised during checkout.
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
https://www.kaggle.com/datasets/netflix-inc/netflix-prize-data
https://grouplens.org/datasets/movielens/
Shambour Q (2021) A deep learning based algorithm for multi-criteria recommender systems. Knowl-Based Syst 211:106545
Article Google Scholar
Desarkar MS, Saxena R, Sarkar S (2012) Preference relation based factorization for recommender systems. International Conference on user modeling, adaptation, and personalization, pp 63–75
Khoshneshin M, Street WN (2010) Collaborative filtering via euclidean embedding. Proceedings of the Fourth ACM Conference on Recommender systems, and personalization, pp 87–94
Koren Y, Bell R, Volinsky C (2009) Matrix factorization techniques for recommender systems. Computer 42:30–37
Desarkar MS, Sarkar S (2012) Rating prediction using preference relations based matrix factorization. UMAP Workshops
Valdiviezo-Diaz P, Ortega F, Cobos E, Lara-Cabrera R (2019) A collaborative filtering approach based on Naïve Bayes classifier. IEEE Access 7:108581–108592
He X, Liao L, Zhang H, Nie L, Hu X, Chua T-S (2017) Neural collaborative filtering. Proceedings of the 26th international conference on world wide web, pp 173–182
Lara-Cabrera R, González-Prieto Á, Ortega F (2020) Deep matrix factorization approach for collaborative filtering recommender systems. Appl Sci 10:4926
Candillier L, Meyer F, Boullé M (2007) Comparing state-of-the-art collaborative filtering systems. International workshop on machine learning and data mining in pattern recognition, pp 548–562
Jones N, Brun A, Boyer A (2011) Comparisons instead of ratings: towards more stable preferences. 2011 IEEE/WIC/ACM International conferences on Web intelligence and intelligent agent technology, vol 1, pp 451–456
Basalaj W (1999) Incremental multidimensional scaling method for database visualization. Visual Data Exploration and Analysis VI 3643:149–158
DeSarbo WS, Howard DJ, Jedidi K (1991) MULTICLUS: a new method for simultaneously performing multidimensional scaling and cluster analysis. Psychometrika 56:121–136
Zhang L, Chen Z, Zheng M, He X (2011) Robust non-negative matrix factorization. Front Electr Electron Eng China 6:192–200
Hernando A, Bobadilla J, Ortega F (2016) A non negative matrix factorization for collaborative filtering recommender systems based on a Bayesian probabilistic model. Knowl-Based Syst 97:188–202
Brun, A, Hamad A, Buffet O, Boyer A (2010) Towards preference relations in recommender systems. Preference learning (PL 2010) ECML/PKDD 2010 workshop
Villegas NM, Sánchez C, Díaz-Cely J, Tamura G (2018) Characterizing context-aware recommender systems: a systematic literature review. Knowl-Based Syst 140:173–200
Thakker U, Patel R, Shah M (2021) A comprehensive analysis on movie recommendation system employing collaborative filtering. Multimed Tools Appl, pp 1–26
Forouzandeh S, Berahmand K, Rostami M (2021) Presentation of a recommender system with ensemble learning and graph embedding: a case on MovieLens. Multimed Tools Appl 80(5):7805–7832
Cai L, Xu J, Liu J, Pei T (2017) Integrating spatial and temporal contexts into a factorization modelCentrality Prediction in Temporally Evolving Networks for POI recommendation. Int J Geogr Inf Sci 32:1–23
Google Scholar
Bueno S, Salmeron JL (2009) Benchmarking main activation functions in fuzzy cognitive maps. Expert Syst Appl 36:5221–5229
Pereira N, Varma S (2016) Survey on content based recommendation system. Int J Comput Sci Inf Technol 7:281–284
Lops P, De Gemmis M, Semeraro G (2011) Content-based recommender systems: state of the art and trends. Recommender systems handbook, pp 73–105
Tewari AS, Kumar A, Barman AG (2014) Book recommendation system based on combine features of content based filtering, collaborative filtering and association rule mining. IEEE International advance computing conference (IACC), pp 500–503
Anwar T, Uma V (2021) Comparative study of recommender system approaches and movie recommendation using collaborative filtering. Int J Syst Assur Eng Manag 12:426–436
Yang Y, Yao H, Li R, Wang S (2021) A collaborative filtering recommendation algorithm based on user clustering with preference types. J Phys: Conf Ser 1848:012–043
Nahta R, Meena YK, Gopalani D, Chauhan GS (2021) Embedding metadata using deep collaborative filtering to address the cold start problem for the rating prediction task. Multimed Tools Appl 80:18553–18581
Sreepada RS, Patra BK, Chakrabarty A, Chandak S (2018) Revisiting tendency based collaborative filtering for personalized recommendations. Proceedings of the ACM India joint international conference on data science and management of data, pp 230–239
Isinkaye FO, Folajimi YO, Ojokoh BA (2015) Recommendation systems: principles, methods and evaluation. Egypt Inform J 16:261–273
Ghazarian S, Nematbakhsh MA (2015) Enhancing memory-based collaborative filtering for group recommender systems. Expert systems with applications, pp 3801–3812
Bobadilla J, Ortega F, Hernando A, Gutiérrez A (2013) Recommender systems survey. Knowledge-based systems, pp 109–132
Yannam VR, Kumar J, Babu KS, Sahoo B (2023) Improving group recommendation using deep collaborative filtering approach. Int J Inf Technol 15:1489–1497
Mehta R, Rana K (2017) A review on matrix factorization techniques in recommender. 2nd International conference on communication systems, computing and IT applications (CSCITA) systems, pp 269–274
Ahn HJ (2008) A new similarity measure for collaborative filtering to alleviate the new user cold-starting problem. Inf Sci 178:37–51
Kannan R, Ishteva M, Park H (2014) Bounded matrix factorization for recommender system. Knowl Inf Syst 39:491–511
Liu H, Hu Z, Mian A, Tian H, Zhu X (2014) A new user similarity model to improve the accuracy of collaborative filtering. Knowl-Based Syst 56:156–166
Ali K, Van Stam W (2004) TiVo: making show recommendations using a distributed collaborative filtering architecture. Proceedings of the tenth ACM SIGKDD international conference on knowledge discovery and data mining, pp 394–401
Kwon H-J, Hong K-S (2011) Personalized smart TV program recommender based on collaborative filtering and a novel similarity method. IEEE Trans Consum Electron 57:1416–1423
Barragáns-Martínez AB, Costa-Montenegro E, Burguillo JC, Rey-López M, Mikic-Fonte FA, Peleteiro A (2010) A hybrid content-based and item-based collaborative filtering approach to recommend TV programs enhanced with singular value decomposition. Inf Sci 180:4290–4311
Zimmerman J, Kauapati K, Buczak A, Schaffer D, Gutta S, Martino J (2004) TV personalization system, Personalized Digital Television
Alhamid MF, Rawashdeh M, Al Osman H, El Saddik A (2013) Leveraging biosignal and collaborative filtering for context-aware recommendation. Proceedings of the 1st ACM international workshop on multimedia indexing and information retrieval for healthcare, pp 41–48
Jha GK, Gaur M, Thakur HK (2022) A trust-worthy approach to recommend movies for communities. Multimedia Tools and Applications, Springer, pp 1–28
Anwar Taushif VU, Hussain MI, Pantula M (2022) Collaborative filtering and kNN based recommendation to overcome cold start and sparsity issues: a comparative analysis. Multimed Tools Appl 81(25):35693–35711
Chen Y-C, Hui L, Thaipisutikul T (2021) A collaborative filtering recommendation system with dynamic time decay. J Supercomput 77:244–262
Thaipisutikul T, Shih TK (2021) A novel context-aware recommender system based on a deep sequential learning approach (CReS). Neural Comput Appl 33:11067–11090
Bobadilla J, Dueñas J, Gutiérrez A, Ortega F (2022) Deep variational embedding representation on neural collaborative filtering recommender systems. Appl Sci 12(9):4168
Thaipisutikul T (2022) An adaptive temporal-concept drift model for sequential recommendation. ECTI Transactions on Computer and Information Technology (ECTI-CIT) 16(2):222–236
Ni J, Huang Z, Hu Y, Lin C (2022) A two-stage embedding model for recommendation with multimodal auxiliary information. Inf Sci 582:22–37
Article MathSciNet Google Scholar
Thaipisutikul T, Chen Y-N (2023) An improved deep sequential model for context-aware POI recommendation. Multimed Tools Appl, pp 1–26
Thaipisutikul T, Shih TK, Enkhbat A, Aditya W (2021) Exploiting long-and short-term preferences for deep context-aware recommendations. IEEE Trans Comput Soc Syst 9(4):1237–1248
Download references
This research received no specific grant from any funding agency in the public, commercial sectors.
Author information
Korra Sathya Babu and Bidyut Kumar Patra contributed equally to this work.
Authors and Affiliations
National Institute of Technology Rourkela, Rourkela, India
V Ramanjaneyulu Yannam, Jitendra Kumar & Bidyut Kumar Patra
Indian Institute of Information Technology, Design and Manufacturing, Kurnool, India
Korra Sathya Babu
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to V Ramanjaneyulu Yannam .
Ethics declarations
The authors declare that there is no conflict of interest regarding the publication of this paper.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Yannam, V.R., Kumar, J., Babu, K.S. et al. Euclidean embedding with preference relation for recommender systems. Multimed Tools Appl (2024). https://doi.org/10.1007/s11042-024-18885-7
Download citation
Received : 16 January 2022
Revised : 08 March 2024
Accepted : 11 March 2024
Published : 02 April 2024
DOI : https://doi.org/10.1007/s11042-024-18885-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Recommender system (RS)
- Collaborative filtering (CF)
- Cold start problem
- Preference relation
- Matrix factorization (MF)
- Euclidean Embedding (EE)
- Find a journal
- Publish with us
- Track your research

Harry Potter eat your heart out! Scientists develop a 6ft 'invisibility megashield' that can hide multiple people by bending light - and you can buy one for just £699
- The £699 megashield uses a precision engineered lens array to bend light
- And unlike Harry Potter's cloak, it is big enough to conceal multiple people
Most people who grew up reading the Harry Potter book series have dreamed of owning their very own invisibility cloak.
Now, that dream can become a reality, as scientists have developed an 'invisibility megashield.'
The £699 shield uses a precision engineered lens array to bend light, rendering objects behind it almost invisibile.
And unlike Harry Potter's cloak, the megashield is big enough to conceal multiple people standing side by side.
'Want to experience the power of invisibility? We've got you covered,' said the Invisibility Shield Co.
READ MORE: Thermal Camouflage Jacket features graphene panels that can be adjusted to conceal you from infrared cameras
The megashield is the brainchild of the London-based Invisibility Shield Co, which came up with the initial idea back in 2022 .
Since then, the firm has developed and tested various cloaking devices, before landing on the latest design.
The megashield measures 6ft tall and 4ft wide, and is constructed from a high grade polycarbonate.
Using a precision engineered lens array, light reflected from the person standing behind the shield is directed away from the person in front of it.
'The lenses in this array are oriented so that the vertical strip of light reflected by the standing/crouching subject becomes diffuse when spread out horizontally on passing through the back of the shield,' the Invisibility Shield Co explained on its Kickstarter page.
'In contrast, the strip of light reflected from the background is much wider, so when it passes through the back of the shield, far more of it is refracted both across the shield and towards the observer.
'From the observer's perspective, this background light is effectively smeared horizontally across the front face of the shield, over the area where the subject would ordinarily be seen.'
According to the team, the shields are most effective against uniform backgrounds, including grass, foliage, sand and sky.
' Backgrounds with defined horizontal lines work extremely well too and these can be natural features such as the horizon or man made features like walls, rails or painted lines,' they added.
A previous version of the shield was released in 2022, but was only big enough to fit one person squatting down.
What's more, users were forced to prop the sheild up themselves.
'Our new shields have been completely redesigned to be more stable when left free-standing, easy to hold and easy to take wherever you want to go,' the Invisibility Shield Co said.
'New ergonomic handles make holding and carrying the shield far more comfortable, whilst keeping your body in the optimum position to stay hidden.'
The company is now crowdfunding on Kickstarter , where you can purchased the Megashield for the early bird price of £699.

'Target No. 1 for ISIS-K': Terror group that hit Moscow nightclub has sights set on US

WASHINGTON − ISIS-K, the terrorist organization that killed more than 140 Russians March 22 in Moscow, would like to replicate the attack in the United States, but it lacks the capability, current and former senior U.S. officials say.
“The U.S. remains target No. 1 for ISIS-K,” said Mark Quantock, a retired two-star Army general who oversaw intelligence operations for U.S. Central Command . “They clearly would like to strike the homeland, but their challenge is penetrating our security, which has proven to be quite resilient in recent years.”
Known for its brutality, ISIS-K considers Russia and many Western countries anti-Muslim. Russia has sided with Syrian President Bashar Assad in its civil war , launching airstrikes for years that that have killed Islamic militants and displaced hundreds of thousands of Syrians. The group also regards even hard-line Muslim regimes like the Taliban to be insufficiently devout. It once targeted a maternity clinic in Afghanistan and was responsible for the attack in August 2021 in Kabul that killed 13 U.S. troops and 170 Afghans during the chaotic retreat of Americans and Afghans.
The K in ISIS-K stands for Khorasan, a region in and around Afghanistan. ISIS-K is an even more violent offshoot of the Islamic State group, or ISIS, which gained strength in 2014 and seized swaths of territory in Iraq and Syria. Sustained military operations by U.S.-backed forces have since sapped its strength, yet it still strives to strike inside America.
Looking beyond Afghanistan for places to attack, but with limited reach
The attack in Russia on a concert hall, and ISIS-K suicide bombers in Iran in January who killed about 100 worshipers, shows the group retains the ability to export attacks, said one official, who was not authorized to speak publicly. But the attacks also show the limits of ISIS-K’s reach with no recent assaults in Western Europe. One of the Islamic State group's last major attacks in Western Europe took place almost eight years ago, killing 17 people. That type of attack appears beyond ISIS-K’s current capability, the official said. The group does, however, seek to inspire disaffected people in the west to mount their own terror attacks, the official said.
In congressional testimony, senior military officials have said pressure on ISIS-K by the ruling Taliban in Afghanistan have “temporarily” disrupted the group’s ability to strike in the United States and other Western nations.
Army Gen. Erik Kurilla, commander of U.S. Central Command, said the Taliban had targeted key ISIS-K leaders in 2023 but have not shown the ability to sustain pressure on the group, which allowed it to regenerate. He said ISIS-K could attack U.S. and Western interests abroad in as little as six months “with little to no warning.”
Before the ISIS-K attacks in Iran and Russia, U.S. officials had sent warnings to those governments. White House national security council spokesman John Kirby told reporters Thursday that officials had warned the Kremlin in writing March 7 of a planned attack on a public gathering like a concert.
When the U.S. intelligence community receives specific, credible information about a threat abroad, the information gets passed on to U.S. citizens through local embassies, the senior U.S. official said. The information also is passed on to the foreign government, in this case Russia, so it can take action to disrupt an attack.
More: Biden and Trump administrations didn't miss ISIS-K threat – they ignored it, experts say
'Duty to warn'
“Duty to warn” is an internal U.S. government policy, one official explained. Its chief aim is to protect Americans abroad and to prompt foreign governments to prevent attacks. Russia, typically, does not reciprocate by providing similar information to the U.S. government, the official said.
Since 9/11, the federal government has taken several steps, including no-fly lists to prevent terrorists from entering the country, the official said.
Coordination among agencies such as Customs and Border Patrol and the FBI, along with the Pentagon and the intelligence community, is at an all-time high, said Quantock, the former intelligence official.
That shouldn’t prompt anybody to get complacent, he said.
“ISIS has proven to be a pretty patient foe, '' Quantock said. "And the U.S. attention span is notably short . ”
- Facebook Logo
- Copy Link Icon
J.K. Dobbins Eyes Chiefs as Landing Spot for Contract After Ravens Sign Derrick Henry

The reigning Super Bowl champions may be adding another playmaker to their offense in the near future.
ESPN's Adam Schefter reported Tuesday that former Baltimore Ravens running back J.K. Dobbins is visiting the Kansas City Chiefs and "is expected to have a home very soon." Dobbins is searching for a new team as a free agent after tearing his Achilles in the season opener in 2023 and watching Baltimore sign Derrick Henry this offseason.
Marquise "Hollywood" Brown, who signed with the Chiefs this offseason, took to social media to do some recruiting:
Hollywood Brown @ Primetime_jet <a href="https://twitter.com/Jkdobbins22?ref_src=twsrc%5Etfw">@Jkdobbins22</a> Think Diamonds 🤭💯
NFL Network's Tom Pelissero reported on March 26 that the Ohio State product was cleared for football activities. Dr. Neal ElAttrache even wrote a letter to some teams and said the running back looks "outstanding" in his recovery.
That is surely welcome news for the Chiefs and any other team looking to sign him, as Dobbins has been limited by injuries throughout his career.
He missed the entire 2021 campaign with a knee injury and played just eight games in 2022 before making a single appearance last year. His rookie season in 2020 was the only time he appeared in double-digit contests, and he ran for 805 yards and nine touchdowns in 15 games.
NFL @ NFL JK DOBBINS! 2 first-quarter touchdowns!<br><br>📺: <a href="https://twitter.com/hashtag/BUFvsBAL?src=hash&ref_src=twsrc%5Etfw">#BUFvsBAL</a> on CBS<br>📱: Stream on NFL+ <a href="https://t.co/cByfmcze7G">https://t.co/cByfmcze7G</a> <a href="https://t.co/8feRf0PEbw">pic.twitter.com/8feRf0PEbw</a>
Baltimore surely envisioned him as a building block after that rookie season, but the injuries prevented that from becoming a reality. Notably, the Ravens added the running back who led the league in carries in four of the last five seasons in Henry.
A team such as Kansas City would be an ideal landing spot for Dobbins.
He wouldn't be expected to be the clear-cut featured back thanks to the presence of Isiah Pacheco, which should allow him to work his way back into a rotation as he returns to the field. What's more, defenses will hardly ever stack the box against him since Patrick Mahomes is under center, which should create plenty of running lanes.
Explosiveness and the ability to take advantage of those lanes has never been the issue for Dobbins, who has averaged 5.8 yards per carry in 24 games.
Adding someone who has posted nearly six yards per rushing attempt to an offense that already features Mahomes, Travis Kelce, Brown and Pacheco could be quite the issue for the rest of the league as the Chiefs attempt to win a third straight Lombardi Trophy.
- Order Status
- Shipping & Delivery
- Order Cancellation
- Size Charts
- Promotions & Discounts
- Product Advice
- Send Us Feedback
Popular Search Terms
- Air Force 1
Top Suggestions
Members: Free Shipping on Orders $50+
Spring Sale: Use code SPRING for up to 50% off.
Look for Store Pickup at Checkout
Nike Precision 6
Women's basketball shoes.
Spring Sale: use code SPRING for 20% off

Select Size
Create space, stop on a dime, shoot off the dribble—do it all with the Nike Precision 6. It's designed to help enable you to shift speeds and change direction while staying in control. From the plush collar and tongue to the modified herringbone traction, this agile low-top helps you make the most of your skills while pushing the tempo of the game.
- Shown: Rugged Orange/Ice Peach/Sail/Light Lemon Twist
- Style: FV1894-800
Shipping & Returns
Reviews (0).
Have your say. Be the first to review the Nike Precision 6.
Write a Review
Complete the Look
Comfort in Key Areas
Plush foam on the collar and tongue enhances the feeling of comfort around the ankle and over the top of the foot—areas where you want no distractions.
Sculpted for Speed
The sculpted foam midsole feels soft and supportive, providing cushioning for the game's nonstop movement.
Traction for Quick Cuts
Herringbone traction provides multidirectional grip, ideal for players who rely on their quickness and cutting ability. The rubber wraps up the sides in the forefoot to give you traction on your edges.
Secure Your Fit
Updated lace positioning from the 5 and midfoot webbing loops help you stay secure.
More Benefits
- Low-cut collar helps provide mobility at the ankle.
- Visible cutout in the foam helps reduce weight.
Product Details
- No-sew overlays

An official website of the United States government
Here’s how you know
The .gov means it’s official.
Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure.
The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
Russia-related Designations, Updates and Removal; Counter Terrorism Designation Update; Issuance of Russia-related General Licenses
The Department of the Treasury's Office of Foreign Assets Control (OFAC) is issuing Russia-related General License 13G , "Authorizing Certain Administrative Transactions Prohibited by Directive 4 under Executive Order 14024"; Russia-related General License 74 , "Authorizing the Wind Down and Rejection of Transactions Involving East-West United Bank"; Russia-related General License 75 , "Authorizing Certain Transactions Related to Debt or Equity of, or Derivative Contracts Involving, Certain Entities Blocked on November 2, 2023"; and Russia-related General License 76 , "Authorizing the Wind Down of Transactions Involving Certain Entities Blocked on November 2, 2023."
Additionally, OFAC has updated its Specially Designated Nationals and Blocked Persons List:
The following deletions have been made to OFAC's SDN List:
PUBLIC JOINT STOCK COMPANY ODK SATURN (a.k.a. NPO SATURN JSC; a.k.a. "SATURN NGO"), 163 Lenina Ave, Rybinsk 152903, Russia; Tax ID No. 7610052644 (Russia); Registration Number 1027601106169 (Russia) [RUSSIA-EO14024]. NPO SATURN JSC (a.k.a. PUBLIC JOINT STOCK COMPANY ODK SATURN; a.k.a. "SATURN NGO"), 163 Lenina Ave, Rybinsk 152903, Russia; Tax ID No. 7610052644 (Russia); Registration Number 1027601106169 (Russia) [RUSSIA-EO14024]. "SATURN NGO" (a.k.a. NPO SATURN JSC; a.k.a. PUBLIC JOINT STOCK COMPANY ODK SATURN), 163 Lenina Ave, Rybinsk 152903, Russia; Tax ID No. 7610052644 (Russia); Registration Number 1027601106169 (Russia) [RUSSIA-EO14024].
Unrelated Administrative List Updates:
NOLAN (f.k.a. OSLO) Oil Products Tanker Panama flag; Secondary sanctions risk: section 1(b) of Executive Order 13224, as amended by Executive Order 13886; Vessel Registration Identification IMO 9179701; MMSI 354798000 (vessel) [SDGT] (Linked To: PONTUS NAVIGATION CORP.). -to- NOLAN (f.k.a. "OSLO") Oil Products Tanker Panama flag; Secondary sanctions risk: section 1(b) of Executive Order 13224, as amended by Executive Order 13886; Vessel Registration Identification IMO 9179701; MMSI 354798000 (vessel) [SDGT] (Linked To: PONTUS NAVIGATION CORP.).
Nanomedicine as a multimodal therapeutic paradigm against cancer: on the way forward in advancing precision therapy

* Corresponding authors
a Institute for NanoBioTechnology, Department of Chemical and Biomolecular Engineering, Johns Hopkins University, Baltimore, MD, 21218, USA E-mail: [email protected]
b Radiobiology, Department of Radiation Oncology & Homi Bhabha National Institute, Mumbai, India
Recent years have witnessed dramatic improvements in nanotechnology-based cancer therapeutics, and it continues to evolve from the use of conventional therapies (chemotherapy, surgery, and radiotherapy) to increasingly multi-complex approaches incorporating thermal energy-based tumor ablation ( e.g. magnetic hyperthermia and photothermal therapy), dynamic therapy ( e.g. photodynamic therapy), gene therapy, sonodynamic therapy ( e.g. ultrasound), immunotherapy, and more recently real-time treatment efficacy monitoring ( e.g. theranostic MRI-sensitive nanoparticles). Unlike monotherapy, these multimodal therapies (bimodal, i.e. , a combination of two therapies, and trimodal, i.e. , a combination of more than two therapies) incorporating nanoplatforms have tremendous potential to improve the tumor tissue penetration and retention of therapeutic agents through selective active/passive targeting effects. These combinatorial therapies can correspondingly alleviate drug response against hypoxic/acidic and immunosuppressive tumor microenvironments and promote/induce tumor cell death through various multi-mechanisms such as apoptosis, autophagy, and reactive oxygen-based cytotoxicity, e.g. , ferroptosis, etc. These multi-faced approaches such as targeting the tumor vasculature, neoangiogenic vessels, drug-resistant cancer stem cells (CSCs), preventing intra/extravasation to reduce metastatic growth, and modulation of antitumor immune responses work complementary to each other, enhancing treatment efficacy. In this review, we discuss recent advances in different nanotechnology-mediated synergistic/additive combination therapies, emphasizing their underlying mechanisms for improving cancer prognosis and survival outcomes. Additionally, significant challenges such as CSCs, hypoxia, immunosuppression, and distant/local metastasis associated with therapy resistance and tumor recurrences are reviewed. Furthermore, to improve the clinical precision of these multimodal nanoplatforms in cancer treatment, their successful bench-to-clinic translation with controlled and localized drug-release kinetics, maximizing the therapeutic window while addressing safety and regulatory concerns are discussed. As we advance further, exploiting these strategies in clinically more relevant models such as patient-derived xenografts and 3D organoids will pave the way for the application of precision therapy.

- This article is part of the themed collections: Recent Review Articles and Theranostic nanoplatforms for biomedicine
Article information
Download citation, permissions.
P. Sandbhor, P. Palkar, S. Bhat, G. John and J. S. Goda, Nanoscale , 2024, 16 , 6330 DOI: 10.1039/D3NR06131K
To request permission to reproduce material from this article, please go to the Copyright Clearance Center request page .
If you are an author contributing to an RSC publication, you do not need to request permission provided correct acknowledgement is given.
If you are the author of this article, you do not need to request permission to reproduce figures and diagrams provided correct acknowledgement is given. If you want to reproduce the whole article in a third-party publication (excluding your thesis/dissertation for which permission is not required) please go to the Copyright Clearance Center request page .
Read more about how to correctly acknowledge RSC content .
Social activity
Search articles by author, advertisements.
invisibility shield 2.0 hides people in plain sight using next generation cloaking technology
Second-generation invisibility shields launching on kickstarter.
Following the successful development of functional invisibility shields in 2022 , UK-based Invisibility Shield Co. has launched its second-generation invisibility shields on Kickstarter. Among the products is the ‘Megashield,’ claiming to be the largest shield ever created.
Over four years, the team focused on refining optical technologies to render people and objects invisible in broad daylight. The new shields prioritize convenience, featuring a compact design that collapses to 1/30th of their assembled size, facilitating easy transport. Available in three sizes – ‘Mini’ at 8 inches tall, ‘Full size’ at 3 feet tall, and ‘Megashield’ standing over 6 feet tall – the latter can conceal multiple individuals standing side by side. The larger models boast ergonomic handles for easy carrying and are freestanding, providing versatility in usage. Furthermore, each unit is fully waterproof, battery-free, and constructed from 100% recyclable materials.
new shields use large precision-engineered lens arrays
The team achieved its goal of bringing fictional superpowers to reality through ultra-large precision-engineered lens arrays. These arrays, forming the shield’s face, redirect light bouncing off the person behind the shield away from the observer, rendering them invisible. The lenses’ configuration causes background light from either side of the shield to spread over its face and be directed towards the observer, effectively cloaking what is behind it.
Designer Tristan Thompson emphasized the team’s motivation, stating, ‘The possibilities are endless, but most importantly, these shields are great fun. They’re fun to play around with and exciting for us to make. We wanted to see how far we could push this technology. A real working invisibility shield that you can just roll up and sling over your shoulder? Two years ago, nobody thought anyone could do that.’
The second-generation invisibility shields are available for pre-order on Kickstarter for 60 days, with backers receiving priority in receiving the new shields. Prices start at around $69.
larger models feature ergonomic handles and are freestanding for versatile usage
the second-gen shields are available for pre-order on Kickstarter
project info:
name: Invisibility Shield 2.0
designer: invisibility shield co. – Tristan Thompson | @invisibility_shield_co
full listing: here
designboom has received this project from our DIY submissions feature, where we welcome our readers to submit their own work for publication. see more project submissions from our readers here.
edited by: christina vergopoulou | designboom
PRODUCT LIBRARY
a diverse digital database that acts as a valuable guide in gaining insight and information about a product directly from the manufacturer, and serves as a rich reference point in developing a project or scheme.
- car design (791)
- electric automobiles (637)
- materials (63)
- recycling (321)
- car concept (357)
- space travel design (95)
- sculpture (351)
- turntable design (27)
designboom will always be there for you
IMAGES
VIDEO
COMMENTS
Learn how to calculate and interpret these evaluation metrics for ranking tasks in machine learning and recommendation systems. See examples, code, and comments from experts and users.
This means that 80% of the recommendation I make are relevant to the user. Mathematically precision@k is defined as follows: Precision@k = (# of recommended items @k that are relevant) / (# of ...
Figure 5. Precision@K example (image by author). The Precision@K column shows for each rank (1 to 6) the Precision@K value. The K stands for the number of ranks (1, 2, …, 6) we consider.. Precision@1. Assuming we would consider only the first rank (K=1), we would then have 0 relevant items divided by 1 (total items), which leads to 0 for Precision@1.. Precision@3
Learn how to calculate precision@k and recall@k, two evaluation metrics for ranking systems such as recommender systems. See definitions, examples, and references from experts and users.
Precision@k is not a stand-alone metric. But neither are any others. While precision's roots start in the early 1950's — where it was called the "pertinence factor" and "relevance ratio" before the named settled on precision — Precision@k started to really gain traction in 1992 with the creation of the above-mentioned TREC [2].
Precision at K measures how many items with the top K positions are relevant. Recall at K measures the share of relevant items captured within the top K positions. You can also use the F-score to get a balanced measure of Precision and Recall at K. Precision, Recall, and F-score can take values from 0 to 1. Higher values mean better performance.
AP@K is the sum of precision@K for different values of K divided by the total number of relevant items in the top K results. Mean Average Precision@K. The mean average precision@K measures the average precision@K averaged over all queries (for the entire dataset). For instance, lets say a movie recommendation engine shows a list of relevant ...
Learn how to measure the relevance of recommendation algorithms using Precision@k, Recall@k, and R-Precision metrics. See examples, formulas, and comparisons of these metrics with cross-validation.
For example, when we go from k=3 to k=4, precision@k decreases, but when we go from k=4 to k=5, it increases since the fifth top predicted label, which is label 3, is one of true labels.
Precision @K. Precision@K gives a measure of "out of K" items recommended to a user and how many are relevant, where K is the number of recommendations generated for a user.. For a recommendation system where we recommend 10 movies for every user. If a user has watched 5 movies and we are able to predict 3 out of them ( 3 movies are present ...
Precision@k: 0.83, Recall@k: 0.91 for k=15. We can see the results for k = 3 k = 3, k = 10 k = 10, and k = 15 k = 15 above. For k = 3 k = 3, it is apparent that 67% of our recommendations are relevant to the user, and captures 18% of the total relevant items present in the dataset.
Disadvantage of Precision@K: Precision at K has this disadvantage that the total number of relevant documents in the collection has a strong influence on this metric. For example, a perfect system, could only achieve a precision@20 of 0.4, if there were only 8 documents relevant to an information need.
How mAP@k works … Moving to our main topic, the mAP@k calculation. As the name suggests, the mean Average Precision is derived from the Average Precision (AP). Firstly, we need to compute the AP ...
Scenario 1: we choose k=10. Then, the precision at K can at most be 3/10 = 0.3. And, the recall at k will be 0.03 because there are 3 in the entire dataset of 100. Scenario 2: we choose k=3. Then, the precision at K would be 3/3 = 1.0 !!!And, the recall at k will STILL be 3/100 = 0.03. Even though our binary classifier is performing perfectly ...
I get stuck at some issues about evaluation metric Precision@K. precision@k is a metric which gives equal weight to the Stack Exchange Network Stack Exchange network consists of 183 Q&A communities including Stack Overflow , the largest, most trusted online community for developers to learn, share their knowledge, and build their careers.
P@10 or "Precision at 10" corresponds to the number of relevant results among the top 10 documents. The more relevant documents are at the front, the more influence it has and earn more points. So then we have greater Precision@k. So, if we swap ranks 8 and 9 we get the following results: Wikipedia says: Precision at k documents (P@k) is still ...
Precision takes all retrieved documents into account. It can also be evaluated considering only the topmost results returned by the system using Precision@k. Note that the meaning and usage of "precision" in the field of information retrieval differs from the definition of accuracy and precision within other branches of science and statistics.
Precision for top-K items can be found by the following equation: $$\begin{aligned} Precision@K = \frac{\#\,top-K\, recommended\, and\, relevant\, items}{\# \,top-K\, recommended\, items} \end{aligned}$$ (28) Here, relevant items represent those whose true rating is greater than or equal to the threshold. Recommended items are those generated ...
A Moscow city councilor was imprisoned Friday seven-year sentence for what Russian authorities described as spreading "fake information" on the war in Ukraine. Russia is bringing its reserve ...
The £699 shield uses a precision engineered lens array to bend light, rendering objects behind it almost invisibile. And unlike Harry Potter's cloak, the megashield is big enough to conceal ...
02:05 - Source: CNN. CNN —. Russia has been left reeling in the wake of the nation's worst terrorist attack in decades. ISIS has claimed responsibility for the massacre, which saw armed ...
M 18 / W 19.5. Add to Bag. Favorite. Create space, stop on a dime, shoot off the dribble—do it all with the Nike Precision 6. It's designed to enable quick players to shift speeds and change directions while staying in control. From the plush collar and tongue to the modified herringbone traction, the agile low-top lets you make the most of ...
add me on : Instagram:https://www.instagram.com/abdelali_bo...My email: [email protected] my PayPal : https://www.paypal.me/MRbadboy1 Subscribe to t...
ISIS-K is an even more violent offshoot of the Islamic State group, or ISIS, which gained strength in 2014 and seized swaths of territory in Iraq and Syria. Sustained military operations by U.S ...
Introduction of additives into aqueous electrolyte holds great potential in suppressing dendrite growth and improving the stability of Zn anode. However, no relevant theory or descriptor could effectively support the screen and design of suitable additives. Herein, desolvation activation energy was proposed
ESPN's Adam Schefter reported Tuesday that former Baltimore Ravens running back J.K. Dobbins is visiting the Kansas City Chiefs and "is expected to have a home very soon." Dobbins is searching for ...
19.5. Add to Bag. Favorite. Create space, stop on a dime, shoot off the dribble—do it all with the Nike Precision 6. It's designed to help enable you to shift speeds and change direction while staying in control. From the plush collar and tongue to the modified herringbone traction, this agile low-top helps you make the most of your skills ...
Unrelated Administrative List Updates: NOLAN (f.k.a. OSLO) Oil Products Tanker Panama flag; Secondary sanctions risk: section 1(b) of Executive Order 13224, as amended by Executive Order 13886; Vessel Registration Identification IMO 9179701; MMSI 354798000 (vessel) [SDGT] (Linked To: PONTUS NAVIGATION CORP.). -to- NOLAN (f.k.a. "OSLO") Oil Products Tanker Panama flag; Secondary sanctions risk ...
Furthermore, to improve the clinical precision of these multimodal nanoplatforms in cancer treatment, their successful bench-to-clinic translation with controlled and localized drug-release kinetics, maximizing the therapeutic window while addressing safety and regulatory concerns are discussed. As we advance further, exploiting these ...
each unit is fully waterproof, battery-free, and made from 100% recyclable materials. available in three sizes: 'Mini,' 'Full size,' and the towering 'Megashield'. ultra-large ...