Citing & publishing software: How to cite software
- Publishing research software
- How to cite software

Citing software
When should you cite software?
Cite the software that was used in your research, including all software that was used to generate and analyze data. The Force11 recommendations: "citation is partly a record of software important to a research outcome". "Software should be cited on the same basis as any other research product such as a paper or a book; that is, authors should cite the appropriate set of software products just as they cite the appropriate set of papers."
Where to put software citations?
Where software and data citations should go may vary from publisher to publisher; check with the author guidelines if writing for publication. Where no more specific guidance exists, consider following the Force11 recommendations to put software citations in the reference list: "Software citations should be accorded the same importance in the scholarly record as citations of other research products, such as publications and data, they should be included in the metadata of the citing work, for example in the reference list of a journal article, and should not be omitted or separated."
How to cite software?
If guidelines from your publisher or citation style exist, follow them, or if writing for publication check with your editor. Some guidelines on citing software from publishers and manuals of style are included here. Many software packages also give guidance on how they want to be cited. If no guidance exists, best practices for software citation elements are below.
Guidelines from style guides and publishers
- AAS journals (American Astronomical Society) As described in the AAS Journal's software policy, software can be cited in two ways: Citing the paper describing the software (e.g. "galpy: A python Library for Galactic Dynamics", Bovy 2015, ApJ, 216, 29); Citing a DOI for the software, for example, obtained via Zenodo or FigShare (e.g. Foreman-Mackey et al. 2014, corner.py, v0.1.1, Zenodo, doi:10.5281/zenodo.11020, as developed on GitHub). Ideally, both forms of citation should be included; alongside these formal references, authors may also want to include footnote URLs to appropriate code repositories, such as GitHub, or metadata indices, such as the Astrophysics Source Code Library.
- IEEE Example citations for manuals/software: [1] L. Breimann. (2003). Manual on Setting Up, Using, and Understanding Random Forests v4.0. [Online]. Available: http://oz.berkeley.edu/users/breiman/Using_random_forests_v4.0.pdf, Accessed on: Apr. 16, 2014. [2] M. Kuhn. The Caret Package. (2012) [Online]. Available: http://cranr-project.org/web/packages/caret /caret.pdf [3] Antcom, Torrance, CA, USA. Antenna Products.(2011) [Online]. Available: http://www.antcom.com /documents/catalogs /L1L2GPSAntennas.pdf, Accessed on: Feb. 12, 2014.
Further reading
- How to cite and describe software A guide to citing software, including publisher recommendations, by Mike Jackson and the Software Sustainability Institute
- Force11 Software Citation Principles
- Citations for Software: Providing Identification, Access, and Recognition for Research Software Laura Soito & Lorraine Hwang
Manage your references
Use these tools to help you organize and cite your references:
- Citation Management and Writing Tools
- << Previous: Publishing research software
- Last Updated: Dec 12, 2018 11:43 PM
- URL: https://libguides.mit.edu/software
Making code citable with Zenodo and GitHub
Megan Potter
Posted on 28 July 2015

For Open Science, it is important to cite the software you use in your research, as has been mentioned in previous articles on this blog . Particularly, you should cite any software that made a significant or unique impact on your work. Modern research relies heavily on computerised data analysis, and we should elevate its standing to a core research activity with data and software as prime research artefacts. Steps must be taken to preserve and cite software in a sustainable, identifiable and simple way. This is how digital repositories like Zenodo can help.
Best practice for citing a digital resource like code is to refer to a digital object identifier (DOI) for it whenever possible. This is because DOIs are persistent identifiers that can be obtained only by an agency that commits to the obligation to maintain a reliable level of consistency in and preservation of the resource. As a digital repository, Zenodo registers DOIs for all submissions through DataCite and preserves these submissions using the safe and trusted foundation of CERN’s data centre, alongside the biggest scientific dataset in the world, the LHC’s 100PB Big Data store. This means that the code preserved in Zenodo will be accessible for years to come, and the DOIs will function as perpetual links to the resources. DOI based citations remain valuable since they are future proofed against URL or even protocol changes, through resolvers such as doi which currently direct to URIs. DOIs also help discoverability tools, like search engines and indexing services, to track software usage through different citations, which in turn elevates the reputation of the programmer.
Long-term digital stewardship requires many auxiliary functions, such as tiered storage, caches and distributed access, as well as processes such as bit preservation, media migration, and data exercising. This is why most code hosting sites are not equipped to make the commitment to long-term storage and preservation. To provide flexible and focused services for collaborative coding, the nature of these sites is necessarily more short-term focused. Although it is possible to identify software uploaded to places like GitHub when citing it in a paper, these organisations do not issue DOIs and there is not a perpetual guarantee of access to older software. Citing the URL where the code is currently hosted can also work in theory, but again you are faced with preservation and versioning issues, e.g. how long will the programmer or organisation maintain the host website, which version of the code is being referenced, and is that version still available on the hosting website? These problems can be handled by publishing your code in a digital repository like Zenodo.
Submitting your code to Zenodo and receiving a DOI has never been easier thanks to the Zenodo and GitHub integration. Additionally, preservation is based on releases, so as the software changes each release can be cited with its own DOI as appropriate, giving precise traceability of the exact code used in a published analysis. Since releases are both archived and public, they are considered published, and can be described with rich metadata, an explanatory abstract and a meaningful author list. This means that you can skip the journal publication step , if you would prefer a more streamlined option for publication.
Zenodo allows you to sign up using your GitHub account to avoid creating yet another account and to facilitate the immediate interlinking of services. If you already have a Zenodo account, linking your GitHub account is still as easy as clicking 'Connect' on the GitHub page in your Zenodo account. Once linked, you simply flip the switch on the repository you would like to preserve. Subsequently, whenever you make a release of that repository in GitHub, Zenodo will archive it as well. This process gives you a new DOI for each release. GitHub has a helpful and succinct walk-through for how to do this in more detail.
Pro tip: if your research is funded by an EU grant, you can even directly connect your code to your grant by updating the grant section of the metadata on the repository’s Zenodo record – discoverability!
A little extra about Zenodo
Conceived within the OpenAIRE project to fill a need for a domain agnostic, free, open-access research repository, Zenodo targets the needs of the 'long tail' of research results. Launched at the CERN Data Centre in May 2013 with a grant from the European Commission, Zenodo has a special commitment to sharing, citing and preserving data and code. Based on the Invenio open-source software, Zenodo profits from and contributes to the foundation of code used to provide Open Data services to CERN and other initiatives around the world.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 26 September 2023
Journal Production Guidance for Software and Data Citations
- Shelley Stall ORCID: orcid.org/0000-0003-2926-8353 1 ,
- Geoffrey Bilder 2 ,
- Matthew Cannon ORCID: orcid.org/0000-0002-1496-8392 3 ,
- Neil Chue Hong ORCID: orcid.org/0000-0002-8876-7606 4 ,
- Scott Edmunds ORCID: orcid.org/0000-0001-6444-1436 5 ,
- Christopher C. Erdmann ORCID: orcid.org/0000-0003-2554-180X 6 ,
- Michael Evans 7 ,
- Rosemary Farmer 8 ,
- Patricia Feeney 2 ,
- Michael Friedman ORCID: orcid.org/0000-0002-2964-3777 9 ,
- Matthew Giampoala 1 ,
- R. Brooks Hanson 1 ,
- Melissa Harrison 10 ,
- Dimitris Karaiskos 11 ,
- Daniel S. Katz ORCID: orcid.org/0000-0001-5934-7525 12 ,
- Viviana Letizia 13 ,
- Vincent Lizzi 3 ,
- Catriona MacCallum 14 ,
- August Muench 15 ,
- Kate Perry 8 ,
- Howard Ratner ORCID: orcid.org/0000-0002-2123-6317 16 ,
- Uwe Schindler ORCID: orcid.org/0000-0002-1900-4162 17 ,
- Brian Sedora ORCID: orcid.org/0000-0003-0825-5967 1 ,
- Martina Stockhause ORCID: orcid.org/0000-0001-6636-4972 18 ,
- Randy Townsend 19 ,
- Jake Yeston 20 &
- Timothy Clark ORCID: orcid.org/0000-0003-4060-7360 21
Scientific Data volume 10 , Article number: 656 ( 2023 ) Cite this article
3998 Accesses
1 Citations
41 Altmetric
Metrics details
- Media formats
- Publication characteristics
Software and data citation are emerging best practices in scholarly communication. This article provides structured guidance to the academic publishing community on how to implement software and data citation in publishing workflows. These best practices support the verifiability and reproducibility of academic and scientific results, sharing and reuse of valuable data and software tools, and attribution to the creators of the software and data. While data citation is increasingly well-established, software citation is rapidly maturing. Software is now recognized as a key research result and resource, requiring the same level of transparency, accessibility, and disclosure as data. Software and data that support academic or scientific results should be preserved and shared in scientific repositories that support these digital object types for discovery, transparency, and use by other researchers. These goals can be supported by citing these products in the Reference Section of articles and effectively associating them to the software and data preserved in scientific repositories. Publishers need to markup these references in a specific way to enable downstream processes.
Introduction
Software and data citation are emerging best practices in academic and scientific communication that provide excellent support for results validation, reproducibility, credit, sharing and reuse of valuable tools and resources. Data citation has been possible with some rigor since the establishment of DataCite—a Registration Agency of the International DOI Foundation, which issues robust persistent identifiers for datasets and maintains a registry of associated rich metadata—in 2009 1 and was recommended by a comprehensive report of a CODATA-ICSTI task group in 2012 (available at: http://www.nap.edu/catalog.php?record_id=13564 ). CODATA-ICSTI is the international and interdisciplinary Committee on Data for Science and Technology (CODATA) and the International Council for Scientific and Technical Information (ICSTI) jointly-formed Task Group on Data Citation Standards and Practices ( https://codata.org/initiatives/task-groups/previous-tgs/data-citation-standards-and-practices/ ). It has become increasingly adopted since the introduction of the “Joint Declaration of Data Citation Principles” 2 in 2014 and its endorsement by 125 publishers, academic institutions, and funders (see https://force11.org/info/endorse-the-data-citation-principles/ ). The enthusiasm for these principles prompted an effort to provide a clear set of practical guidelines for publishers to begin to implement data citations. In 2018 “A data citation roadmap for scientific publishers” 3 was published, incorporating work from several groups via workshops and including major participation by representatives of Elsevier, Springer-Nature, PLOS, eLIFE, JISC, EMBO Press, CrossRef, and Wiley. However, even when following this guidance, several publishers were finding that machine-actionable software and data citations from their own published articles were not preserved intact when the article was published, and that downstream services and linking were not enabled. Furthermore, it should be noted that software usage and citation, while similar to data citation, has certain key differences that should be reflected in publication workflows 4 , 5 . These are complex and involve authors, reviewers, editors, and other infrastructure services. Here we provide updates on this guidance to enable automated attribution and credit for software and data used in published articles.
Funders and advisory groups are now beginning to require data and software citation in order to connect publications with their supporting software and data(see, for example, https://wellcome.org/grant-funding/guidance/data-software-materials-management-and-sharing-policy ). Notably, the Intergovernmental Panel on Climate Change (IPCC) enhanced the traceability of its recent Assessment by the implementation of the FAIR (Findable, Accessible, Interoperable, and Reusable) Guidelines 6 , 7 , which extends IPCC’s Assessment process by the documentation, long-term preservation, and citation of the assessed digital information, including both data and software. Recently, the White House Office of Science and Technology (OSTP) Memorandum “Ensuring Free, Immediate, and Equitable Access to Federally Funded Research” 8 has directed federal agencies to develop implementation plans around open access for research results attributed to grants, including to the software and data.
Recommended software citation practices have more recently been clarified by the FORCE11 Software Citation Implementation Working Group in “Recognizing the value of software: a software citation guide” 5 . FORCE11 is a community of scholars, librarians, archivists, publishers and research funders that has arisen organically to help facilitate the change toward improved knowledge creation and sharing ( https://force11.org/info/about-force11/ ). With the current intensive use of software including specialized tools and models for scientific research problems, software has evolved to become a key research resource requiring transparency and disclosure to the readers of any academic or scientific article. With work by the FORCE11 Software Citation Implementation Working Group, citation of software can now be consistently implemented by publishers who follow the guidelines in this article, establishing both data citation and software citation as important elements in peer-reviewed articles.
Long-term preservation and sharing of software and data that support research results in trustworthy scientific repositories, preferably domain-specific repositories 9 , provide for discovery, transparency, validation, and re-use by other researchers. Publishers should provide the means to associate these products to research articles through citation in the references section, using the structured implementation guidance for software and data citation in publishing workflows, provided in this article. Software citation, like data citation, provides a direct path to FAIRness for these essential research components 10 , 11 . The updated guidance provided here includes recent improvements in the practices, challenges publishers are encountering, and recommendations for addressing those challenges.
Journal publishers should make best efforts to undertake the following practices, on which we provide further detailed guidance in this article.
Software and Data Citations: Checklist of Best Practices for Journal Publishers
Instructions to Authors: Provide author instructions that define which software and datasets should be cited in their article, reinforce these instructions throughout the process including editorial actions. Additionally, include how to structure these citations and provide information on selecting the best possible scientific repositories to use for software and data, and what information to put in an Availability Statement.
Publication Policies: Update publication policies to include the importance of citing the software and datasets that support the transparency, integrity, and reproducibility of the research.
Education and Outreach: Educate editors, reviewers, and staff on the policy, requirements, areas of flexibility, and unique aspects of software and dataset citations.
Technical Updates: Put into place the necessary technical updates, as defined in this document, to ensure that the machine-actionable representation of the software and dataset citations is sustained throughout the publication workflow and properly formatted when registered to Crossref.
Production Teams: Define for publication production team members the unique aspects of software and dataset citations; work together to implement necessary changes.
Metrics: Establish quality metrics and measures to ensure consistent, accurate results for software and dataset citations.
This document is the product of working sessions of the FORCE11 Software Citation Implementation Working Group’s Journals Task Force, conducted over a period of 2 years. It reflects lessons learned from a project supported by an NSF Grant (2025364) to the American Geophysical Union to ensure that software and data citations were transferred reliably from publications to NSF’s Public Access Repository. It provides best practices to journals such that the machine-actionable representation of the software and dataset citations is sustained throughout the publication workflow and properly formatted when deposited to Crossref. This optimizes their ability to be properly linked as research objects in support of services provided by DataCite, Scholarly Link eXchange (Scholix), and others. The FORCE11 Journals Task Force includes both society and commercial publishers of all sizes, research infrastructure providers, and others interested in implementation challenges for software and data citations.
The guidance here is primarily intended for those who support the journal production process, including those engaged in copy editing, markup, and preparing the article for publication on various types of digital and print platforms. To implement these recommendations, coordination with journal submission systems, author guidelines, editors, reviewers, authors, and others involved with the front-end process of publications will also need to be included. Since journal production depends on a number of activities that take place both prior and subsequent to production in the publication workflow, we include brief descriptions of what is expected in those activities.
In this guide we describe a set of necessary journal-related activities, organized by role, along with what is needed for datasets and software that supports the article to be identified and cited. We provide use cases for journals to consider as they ensure that their production processes are handling data and software citations optimally.
Problem statement
Data and software citations have unique use cases and workflows that distinguish them from article or book citations. In particular, software and data are often registered by Digital Object Identifier (DOI) registration agencies other than Crossref.
We have discovered that at many publishers, when scripts in the journal production process attempt to validate these citations, they do not do so correctly, and as a result, the integrity of the machine-actionable link to the software or dataset is not maintained and not provided to Crossref. As a result, important downstream services are not supported.
The global research community is now advancing the importance of citing software and datasets in scholarly literature as a means to be more transparent and support steps towards better reproducibility and reusability of software and datasets. Data and software are research objects separate from the article with the potential of reuse and citation in later works. Tracking these citations accurately so that authors/creators of these objects receive recognition is important and ensures the scholarly record is more complete.
Journal practices are influenced by other participants in the research ecosystem and the processes and services they provide. For this set of recommendations, these include Crossref (or other DOI registration agencies), Event Data (a joint service by Crossref and DataCite), DataCite Commons, and Scholix. These work together to associate software and datasets with publications for many other uses.
Crossref provides DOI registration services for publishers of English language peer-reviewed articles, their journals, and other publications. Using the Reference Section of each registered article, Event Data (a joint service by Crossref and DataCite that captures online mentions of Crossref records, https://www.crossref.org/blog/event-data-now-with-added-references/ ) records the relationship between the software and datasets cited in the article with the article itself in a database that other services can use. Event Data can also be populated if a relationship is asserted (with an identifier) to software or datasets in the journal metadata. Crossref has encountered challenges in providing consistent support to Event Data. In 2021, Crossref completed updates that fixed and improved these processes; however, incorrect publisher markup of the software and dataset citations still prevents full implementation.
DataCite , like Crossref, provides DOI registration services. DataCite specializes in preserving scientific datasets, some preprint servers (e.g., arXiv.org), physical samples (e.g., International Generic Sample Numbers (IGSNs),), and software (e.g., Zenodo). DataCite is the preferred DOI registration agency for datasets and software because of its robust identifier system, metadata, and support services.
DataCite Commons uses Event Data as well as the metadata from both Crossref and DataCite’s APIs (Application Programming Interface), ORCIDs (Open Researcher and Contributor ID, https://orcid.org/ ), and RORs (Research Organization Registry, https://ror.org/ ) to visualize the connections between works (e.g., article, data, software), people, organizations, and repositories. For example, you can see the works that cite a particular dataset.
Scholix is an interoperability framework that collects and exchanges links between research data and literature 12 , 13 . Scholix is designed to support multiple types of persistent identifiers, although at the moment only DOIs are included. Both Crossref and DataCite feed DOIs to Scholix. If a data repository includes information about related publications that use a dataset, through the metadata included in the DOI registration process (as metadata property ‘relatedIdentifier’), DataCite will provide that information (linked to the newly created dataset DOI) to Scholix. Similarly, if an article includes a dataset in the Reference Section, Crossref will report that to Scholix. Scholix manages multiple entries when the same article-to-dataset link is provided by two different sources. Software is not supported at this time.
Workflow description
The following activities describe a typical publishing workflow, grouped by role, used to capture software and dataset citations properly in both human-readable and machine-actionable formats to support linking and automated attribution and credit. The order of activities may be slightly different for each publisher’s production process.
Author Preparation
Use scientific, trustworthy repositories that register data and software with persistent, globally unique and resolvable identifiers. Trustworthy repositories are key to helping authors make their data and software as well-documented, accessible, and reusable as possible. These qualities are embodied in the FAIR Guiding Principles. Datasets and software that are as FAIR and openly licensed as possible should be encouraged by journals, taking into consideration necessary protections and national laws. Trusted repositories provide long-term curation and preservation data and software services guided by the TRUST (Transparency, Responsibility, User focus, Sustainability and Technology) principles 14 . CoreTrustSeal — an international, community based, non-governmental, and non-profit organization promoting sustainable and trustworthy data infrastructures, and offers to any interested data repository a core level certification based on the Core Trustworthy Data Repositories Requirements — provides a list of certified repositories that follow those principles 15 . Specific dataset curation services may require time to review and prepare the data prior to publication. This is most common with repositories that specialize in a particular scientific domain or data type. The time needed for domain-specific data curation, the value-added process of making the dataset interoperable and more likely to be reused, may be up to several weeks or more. Generalist repositories such as Harvard Dataverse Repository, Dryad, and Zenodo are typically far quicker as they do not undertake domain-specific curation. However, domain-specific repositories may be the norm for certain disciplines. Journals should encourage researchers to be aware of this time constraint where applicable, and to plan accordingly. Well-curated data provides transparency and integrity to research. The repository landscape is growing to accommodate the needs of researchers. Tools like re3data.org , DataCite Commons (using both DataCite and re3data.org content), FAIRsharing.org , or the CoreTrustSeal website are well-managed and support authors in finding a trustworthy discipline-specific repository.
Software is best preserved in repositories that supports versioning. Researchers can use re3data.org to locate software preservation repositories. Those researchers that use GitHub.org as a development platform can use the integrated bridge to Zenodo.org to preserve a specific version for publication. When using the Zenodo bridge remind your authors to double-check author names, add in author ORCIDs, and make necessary corrections to citation information and metadata.
Include in the submitted article both an Availability Statement for software and datasets and citations in the Reference Section paired with in-text citations in the article. Publishers should provide support with author guidance and journal templates. All software and datasets can be described in the Availability Statement, but frequently the information needed for a complete citation is not fully available.
An Availability Statement is designed for the reader and states where the supporting datasets and software are located and any information about accessibility that is needed. Include an in-text citation that has a corresponding entry in the Reference Section. This is a statement on availability so that those looking to analyze or reuse datasets or software can easily find these objects. The information provided should lead the reader to the exact location where the software or dataset can be found. See Availability Statement Recommended Elements Section for more information.
Paired Citations and References
In-text citations in the Methods and/or Data Section that refer to corresponding entries (citations) in the Reference Section for the dataset or software. These in-text citations provide discrete linkage from research claims to the specific dataset or software supporting them and/or methods used in analysis similar to citations of research articles or other sources.
Citation (in Reference Section) for the dataset and software used in this research. These should be listed in the Reference Section. This allows for automated attribution and credit through Crossref’s Event Data. See section Techniques for Identifying a Data or Software Citation in your References Section Metadata for a suggestion on using a “bracketed description” in the citation format to make identification of data and software citations easier. Also, see Software and Data Citation Resources Section.
Be aware that reference tools used by many authors may not have an item type for datasets or software yet . In order to follow the best practices in this guide, further editing of the citation may be required. For example, Zotero does not support datasets, but does support software. Zotero provides a workaround to support datasets .
Journal staff review
Ensure the presence of a sufficiently descriptive Availability Statement with actionable DOI/URLs for both software and datasets supporting the research.
Ensure that for all software and datasets identified in the Availability Statement there is a supporting citation and the statement is complete . Journal review guidance is helpful (e.g., American Geophysical Union’s (AGU) Data and Software Availability and Citation Checklist ). The journal should promote the importance of a citation in the Reference Section as much as is feasible to encourage automated attribution and credit. Provide examples relevant to your journal. Citations should be to both newly created software and datasets as well as to software and datasets already deposited in repositories by other researchers and reused or referred to in the research by the authors. See Availability Statement Recommended Elements Section for more information.
Provide guidance to authors recommending that software and datasets in the Availability Statement be preserved for the long term in a trustworthy repository complying with the TRUST principles 14 including its inherent long-term commitment for sustainable operations. DataCite has enhanced their Commons tool to include repositories ; In addition, CoreTrustSeal provides a list of their certified repositories . Use keywords to discover potential repositories and review relevant characteristics like domain specialties, technical properties, governance, upload policies, and possible certifications 16 .
Ensure citation follows journal style guides. Journals use many different citation styles. Some styles are flexible enough to allow the author to assist with identifying the citation type by using a “bracketed description” to indicate the citation as a dataset, software, computational notebook, etc. This is important to inform automated and manual reference section review as well as accurate production markup. See Software and Data Citation Resources Section for more information.
Reviewer/editor evaluation
Review the submitted article to determine if the software and datasets referenced in the Methods and Data or Methods and Materials Section appears to fully support the research, such that all has been accounted for.
Review the Availability Statement to ensure all the software and datasets referenced are included. Use the information provided to locate and observe the software and datasets. Ensure that the links resolve and the content is as described. Request clarity as needed. Ensure the Availability Statement is complete. See Availability Statement Recommended Elements Section for more information.
Publisher responsibility
Ensure the entire production process team, such as copy editors, markup vendors, and staff, are aware of the uniqueness of software and dataset citations . This includes providing guidance, education, and support for questions. See the Software and Data Citation Resources Section for more information.
Ensure the publication policies are current using best practices of including software and dataset citations such as the Transparency and Openness Promotion Guidelines (TOP) Guidelines 17 and the Research Data Policy Framework for All Journals and Publishers 18 and those that extend this work to include software.
Implement quality assurance processes for measuring software and data citation accuracy.
Establish quality controls, measures and metrics to track consistency and establish thresholds for when to take action when the measures indicate a degradation in quality.
Automated verification activity - reference section (Publisher or third-party vendor responsibility)
Check software and dataset citations in the Reference Section . When checking citations, note that software and dataset citations formats can include repository names and version numbers. Guidance from FORCE11 and Research Data Alliance (RDA), a community-driven initiative by the European Commission, the United States Government’s National Science Foundation and National Institute of Standards and Technology, and the Australian Government’s Department of Innovation with the goal of building the social and technical infrastructure to enable open sharing and re-use of data ( https://www.rd-alliance.org/about-rda ) provides recommended formats. See the Software and Data Citation Resources Section for more information. The format for persistent identifiers for software and datasets can vary. DOIs are commonly registered through DataCite and potentially other DOI Registration Agencies. Consider using content negotiation to validate. Content Negotiation allows a user to request a particular representation of a web resource. DOI resolvers use content negotiation to provide different representations of metadata associated with DOIs. A content negotiated request to a DOI resolver is much like a standard HTTP request, except server-driven negotiation will take place based on the list of acceptable content types a client provides. ( https://citation.crosscite.org/docs.html ).
Ensure that software and dataset citations are tagged accurately . Avoid tagging them as “other”. Refer to JATS for Reuse (JATS4R) guidance for data citations 19 and software citations from The National Information Standards Organization (NISO) 20 .
Avoid removing citation information , especially the persistent identifier.
Copy editor review (re: language and style editing)
Check that the software and datasets mentioned in the Methods and Data Section have corresponding entries in the Availability Statement and citations in the Reference Section .
Note: not all data or software can be supported with a citation that includes a persistent identifier.
Production Markup Review (supports machine-actionable formats)
Methods/Data Section: Check that in-text citations and/or text in the Availability Statement link correctly to citations.
Availability Statement: This text should include availability statements for all software and datasets that support the research. Currently most journals do not mark up this text. However, JATS4R now has a specific recommendation to do so.
Citations: Journals should review and update the markup requirements for dataset citation 19 and software citation 20 . The persistent identifier or URL is an active link in the article to the reference. Some publishers provide visualization tools of the software or dataset. Consult the Software and Data Citation Resources Section of this article for information on formatting. Dataset and software research outputs should use the same journal citation style and treatment of the persistent identifier with slight adjustment to include software version information and bracketed descriptions.
Content hosting provider activities
Register the article with Crossref and ensure metadata is sent to Crossref , including the full reference list (and the Availability Statement when added to the Crossref schema). Ensure all citations are included in the file going to Crossref, and not being removed inadvertently. Use the Crossref Participation Report to check publisher metadata overview of what is provided to Crossref. Consult with Initiative for Open Citations (I4OC, https://i4oc.org/ ) for community recommendations on open citations.
Use the Software and Dataset Citation Use Cases provided below as a guide to ensure coverage of most variations .
Display the human readable citation correctly . Consult the Software and Data Citation Resources Section of this article for information on formatting. Dataset and software research outputs should use the same journal citation style and treatment of the persistent identifier with slight adjustment to include software version information and possibly bracketed descriptions.
Provide the machine-actionable citation correctly to downstream services (e.g., Crossref). It is important to note the guidance provided by Crossref in their blog (available at https://www.crossref.org/blog/how-do-you-deposit-data-citations/ ) has since been amended. If a journal implemented this guidance previously, there is a high probability that a correction is needed, using the information in this article. The Software and Dataset Citation Use Cases tables below (Tables 1 – 4 ), specifically the Crossref information, includes those corrections. In short, if there is a DOI, include the DOI XML tag.
Crossref activities
Receive the article XML from the Content Hosting Provider/Publisher and create the necessary Event Data entries for software and dataset citations included in the Reference Section.
We include below a list of specific software and dataset use cases with recommended JATS XML and Crossref submission record elements. JATS XML refers to Journal Article Tag Suite (JATS) Library, a standard publishers use to mark up journal article content in XML format. ( https://www.niso.org/standards-committees/jats )
Following the use cases are recommendations for techniques for identifying a software or dataset citation in the Reference Section.
Software and dataset citation use cases
Tables 1 – 4 list the common use cases for software (Tables 1 , 2 ) and dataset (Tables 3 , 4 ) citations, the corresponding JATS XML elements, and Crossref Metadata depository schema elements to assist publishers with creating the necessary adjustments to their production systems that result in proper machine-readable and actionable citations. The first use case for software citation (use case A in Table 1 ) and dataset citation (use case 1 in Table 3 ) represent the most desirable condition to support automated attribution and credit. Use cases not included are listed in text below. In each table, we show the desired outcome for JATS XML version 1.3, which is available at https://www.niso.org/publications/z3996-2021-jats . The example used is <element-citation> but <mixed-citation> is equally acceptable. We also show the desired outcome for Crossref Metadata depository schema 5.3.1, which is available at https://www.crossref.org/documentation/schema-library/metadata-deposit-schema-5-3-1/ .
Use cases not included in this guidance:
Citation to a physical location such as a museum.
Mixed content citation that includes, for example, software, data, and other digital objects where individual attribution to a specific item is difficult or not possible.
Physical samples using IGSN, RRID, or other persistent identifiers.
Executable environments, for example, MyBinder , Executable Research Article (ERA) 21 , and Code Ocean .
Datasets associated with different persistent identifiers, for example journal supplemental files for a journal article where the journal article DOI is used for citation.
Datasets and software together with an online software implementation associated with a publication are reviewed, published and preserved long-term, used data and software is cited and the provenance documented: IPCC Atlas Chapter with WGI Interactive Atlas and WGI Github Repository .
Software and Data Citation - Crossref Metadata Schema examples
Software citation example.
Published Article
Shumate A and Salzberg S. LiftoffTools: a toolkit for comparing gene annotations mapped between genome assemblies [version 1; peer review: 1 approved with reservations]. F1000Research 2022, 11:1230 ( https://doi.org/10.12688/f1000research.124059.1 )
Availability Statement (located in the ‘Software Availability’ Section in this article) Archived source code as at time of publication: https://doi.org/10.5281/zenodo.6967163 ( Shumate, 2022 )
Software Citation in Reference Section
Shumate, A. (2022). agshumate/LiftoffTools: (v0.4.3.2) [Computer software]. Zenodo. https://doi.org/10.5281/ZENODO.6967163
Crossref Metadata
{ "key": "ref6", "doi-asserted-by": "publisher", "unstructured": "Alaina Shumate, 2022, agshumate\/LiftoffTools: Version 0.4.3.2, zenodo, 10.5281\/zenodo.6967163", "DOI": "10.5281\/zenodo.6967163" },
Data citation example
Zhang, Y., Li, X., Liu, Z., Rong, X., Li, J., Zhou, Y., & Chen, S. (2022). Resolution Sensitivity of the GRIST Nonhydrostatic Model From 120 to 5 km (3.75 km) During the DYAMOND Winter. In Earth and Space Science (Vol. 9, Issue 9). American Geophysical Union (AGU). https://doi.org/10.1029/2022EA002401 .
Availability Statement (located in the Open Research Section in this article)
Data for supporting this study are available at: https://zenodo.org/record/6497071 (GRIST-Dev, 2022).
Data Citation in Reference Section
GRIST-Dev. (2022). DYAMOND winter of GRIST nonhydrostatic model (A21) [Dataset]. Zenodo. https://doi.org/10.5281/ZENODO.6497071 .
{ "key": "e_1_2_7_7_1", "doi-asserted-by": "publisher", "unstructured": "GRIST‐Dev. (2022).DYAMOND winter of GRIST nonhydrostatic model (A21)[Dataset].Zenodo.10.5281/ZENODO.6497071.", "DOI": "10.5281/ZENODO.6497071" },
Techniques for Identifying a Data or Software Citation to Properly Tag it in the Reference Section Metadata
Citations for data or software can be difficult to discern from journal citations. We offer these techniques for your consideration.
Request Authors to include Bracketed Descriptions in Data and Software Citations: As defined by the Publication Manual of the American Psychological Association, 7th Edition, bracketed descriptions “help identify works outside the peer-reviewed academic literature (i.e., works other than articles, books, reports, etc.), provide a description of the work in square brackets after the title and before the period.”
Benefit: Easier identification of data or software citations in the Reference Section. Bracketed descriptions can be added to any flexible journal style guide.
Challenge: At this time there is no broadly accepted standard list of terms and adding a bracketed description for data and software citations adds to the burden on authors and likely will not be consistent.
Request Authors to include Availability Statement as a Guide to Reviewing the Reference Section for Data and Software Citations .
Benefit: A complete Availability Statement that has been validated through journal staff and/or peer review can be used to determine which citations in the Reference Section are data or software.
Challenge: Staff, reviewers, and authors need clear guidance on what should be included in the Availability Statement and examples of data and software citations. The publication process should include steps to review and provide guidance to authors on completing or improving the Availability Statement. See the Availability Statement Recommendations Section for a list of elements to include.
Use Content Negotiation on machine-actionable metadata from the repository landing page .
Benefit: Crossref and DataCite provide a tool that validates Digital Object Identifiers ( https://citation.crosscite.org/docs.html ) and returns information that includes the “type” of content registered, such as “data set” or “software.” Content Negotiation often also works with references to URLs, especially when requesting Schema.org (“application/ld + json”) metadata. Many repositories also have machine-actionable metadata in Schema.org format on their landing page, which makes it a universal way to request metadata and type (data/software/creative work).
Challenge: Often, content negotiation only works for DOIs registered with Crossref or DataCite. Additionally, for generalist repositories, the “type” information might not be accurate. Researchers depositing their data without support from a Data Manager will usually select the default type, misidentifying the files. The metadata format of Crossref and DataCite is different, so an implementation for both formats is required. It may also be advisable to request Schema.org metadata.
Publishers today have a responsibility to the research community, to establish and provide digital connections between the published article and the software and datasets that support that article. This is critical for research transparency, integrity, and reproducibility in today’s data- and software-intensive science enterprise. Scientific communications that do not provide these connections can no longer be considered fully robust.
In implementing required changes to support these responsibilities many journals do not yet have policies and practices strong enough to ensure the necessary dataset and software citations are included in the references. Further, if such citations are included, the journal guidance has heretofore often been murky on how the machine-actionable citations should be digitally formatted for downstream services to provide automated attribution and credit.
This article provides the much-needed guidance to help journals review their production processes and work with their authors, editors, reviewers, staff, and production teams to ensure high-quality dataset and software citations that support automated attribution.
The authors of this article are members of the FORCE11 Journals Task force representing many society, institution, and commercial publishers world-wide. They encourage their peers to adopt these practices and help enable proper machine-actionable dataset and software citations.
Journals should use the Checklist of Best Practices for Journal Publishers located in the results section, to start their journey of improving machine-actionable dataset and software citations.
We strongly encourage our colleagues in academic publishing to adopt these practices. Colleagues with questions, or wishing to share success stories, should contact the lead author.
Software and data citation resources
This software and data citation resource list includes discipline-agnostic, community-developed and vetted guidance for scholarly publishers, scientific repositories, authors, software developers, and researchers. For a list of relevant software citation resources, see 5 , 22 , 23 , 24 , and relevant data citation resources, see 2 , 3
Availability statement recommended elements
This text is adapted from AGU’s Data and Software Availability and Citation Checklist (available at: https://data.agu.org/resources/availability-citation-checklist-for-authors ).
Description of the Type(s) of data and/or software - [Required] Examples:
Data - The facilities of IRIS Data Services were used for access to waveforms and related metadata from the International Geodynamics and Earth Tide Service (Network Of Superconducting Gravimeters, 1997)
Software - Figures were made with Matplotlib version 3.2.1 (Caswell et al ., 2020; Hunter, 2007)
Repository Name(s) where the data/software are deposited - [Best Practice]
URL/link to the data/software, preferably Persistent Identifier (e.g., DOI) and resolves - [Required] Examples:
Software - https://doi.org/10.5281/zenodo.3714460
Data - https://doi.org/10.7283/633E-1497
Access Conditions - [Best Practice] Examples:
Registration/fee required
Database where certain functionality, selections, or query need to be made. Provide the details.
English Translation - [Required] Examples:
Site includes translation functionality
Translation available via browser plug-in
Author guides the readers/makes translation available
Licensing - [Best Practice] Examples:
Software - MIT License ( others )
Data - CC-BY ( others )
In-text Citation where possible - [Best Practice] Examples:
Software - Figures were made with Matplotlib version 3.2.1 (Caswell et al ., 2020; Hunter, 2007), available under the Matplotlib license at https://matplotlib.org/ .
Data - Data from the KNMI archive with Federation of Digital Seismograph Networks (FDSN) network identifiers NL (KNMI, 1993) and NA (KNMI, 2006) were used in the creation of this manuscript.
If software, also include
Version (e.g., Version 3.2.1) - [Best Practice]
Link to publicly accessible Development Platform (e.g., GitHub) - [Best Practice] Examples:
Part of the software (version 1.0.0) associated with this manuscript for the calculation and storage of PSDs is licensed under MIT and published on GitHub https://github.com/Jollyfant/psd-module/ (Jollyfant, 2021).
Author, Project Name(s) instead of username(s) (e.g., username123)
Additional Context/Description beyond acronym or code name (e.g., Longhorn pipeline scripts for reducing data vs Longhorn)
Ethics declarations
This work was conducted as part of the FORCE11 Software Citation Implementation Working Group’s Journal Task Force. We follow the FORCE11 Code of Conduct, https://force11.org/info/code-of-conduct/ .
Data availability
This research did not use or result in a scientific dataset.
Code availability
This research did not use or result in software.
Brase, J. DataCite - A Global Registration Agency for Research Data. in 2009 Fourth International Conference on Cooperation and Promotion of Information Resources in Science and Technology https://doi.org/10.1109/coinfo.2009.66 (IEEE, 2009).
Data Citation Synthesis Group. Joint Declaration of Data Citation Principles. Martone M. (ed.) San Diego CA: FORCE11. https://doi.org/10.25490/a97f-egyk (2014).
Cousijn, H. et al . A data citation roadmap for scientific publishers. Scientific Data 5 , https://doi.org/10.1038/sdata.2018.259 (2018).
DataCite Metadata Working Group. DataCite Metadata Schema Documentation for the Publication and Citation of Research Data and Other Research Outputs. Version 4.4. DataCite e.V . https://doi.org/10.14454/3w3z-sa82 (2021).
Katz, D. S. et al . Recognizing the value of software: a software citation guide. F1000Research 9 , 1257, https://doi.org/10.12688/f1000research.26932.2 (2021).
Article PubMed Central Google Scholar
Wilkinson, M. et al . The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3 , 160018, https://doi.org/10.1038/sdata.2016.18 (2016).
Article PubMed PubMed Central Google Scholar
Pirani, A. et al . The implementation of FAIR data principles in the IPCC AR6 assessment process. Zenodo https://doi.org/10.5281/ZENODO.6504468 (2022).
Nelson, A. Ensuring Free, Immediate, and Equitable Access to Federally Funded Research . https://www.whitehouse.gov/wp-content/uploads/2022/08/08-2022-OSTP-Public-Access-Memo.pdf (2022).
Groth, P., Cousijn, H., Clark, T. & Goble, C. FAIR Data Reuse – the Path through Data Citation. Data Intelligence 2 , 78–86, https://doi.org/10.1162/dint_a_00030 (2020).
Article Google Scholar
Hanson, B., Kerstin Lehnert, K. L. & Cutcher-Gershenfeld, J. Committing to Publishing Data in the Earth and Space Sciences. Eos 96 , https://doi.org/10.1029/2015EO022207 (2015).
Stall, S. et al . Make scientific data FAIR. Nature 570 , 27–29, https://doi.org/10.1038/d41586-019-01720-7 (2019).
Article ADS PubMed CAS Google Scholar
Cousijn, H., Feeney, P., Lowenberg, D., Presani, E. & Simons, N. Bringing Citations and Usage Metrics Together to Make Data Count. Data Science Journal 18 , https://doi.org/10.5334/dsj-2019-009 (2019).
Khan, N., Pink, C. J. & Thelwall, M. Identifying Data Sharing and Reuse with Scholix: Potentials and Limitations. Patterns 1 , 100007, https://doi.org/10.1016/j.patter.2020.100007 (2020).
Lin, D. et al . The TRUST Principles for digital repositories. Scientific Data 7 , https://doi.org/10.1038/s41597-020-0486-7 (2020).
L’Hours, H., Kleemola, M. & De Leeuw, L. CoreTrustSeal: From academic collaboration to sustainable services. IASSIST Quarterly 43 , 1–17, https://doi.org/10.29173/iq936 (2019).
Murphy, F., Bar-Sinai, M. & Martone, M. E. A tool for assessing alignment of biomedical data repositories with open, FAIR, citation and trustworthy principles. PLOS ONE 16 , e0253538, https://doi.org/10.1371/journal.pone.0253538 (2021).
Article PubMed PubMed Central CAS Google Scholar
Nosek, B. A. et al . Promoting an open research culture. Science 348 , 1422–1425, https://doi.org/10.1126/science.aab2374 (2015).
Article ADS PubMed PubMed Central CAS Google Scholar
Hrynaszkiewicz, I., Simons, N., Hussain, A., Grant, R. & Goudie, S. Developing a Research Data Policy Framework for All Journals and Publishers. Data Science Journal 19 , 5, https://doi.org/10.5334/dsj-2020-005 (2020).
NISO JATS4R Data Citations Recommendation v2.0. https://doi.org/10.3789/niso-rp-36-2020 .
NISO JATS4R Software Citations v1.0. https://doi.org/10.3789/niso-rp-40-2021 .
Lasser, J. Creating an executable paper is a journey through Open Science. Communications Physics 3 , https://doi.org/10.1038/s42005-020-00403-4 (2020).
Chue Hong, NP. et al . Software Citation Checklist for Authors, Zenodo , https://doi.org/10.5281/zenodo.3479199 (2019).
Chue Hong, NP. et al . Software Citation Checklist for Developers, Zenodo , https://doi.org/10.5281/zenodo.3482769 (2019).
Smith, A. M., Katz, D. S. & Niemeyer, K. E. Software citation principles. PeerJ Computer Science 2 , e86, https://doi.org/10.7717/peerj-cs.86 (2016).
Download references
Acknowledgements
Shelley Stall and Brian Sedora are partially funded by the National Science Foundation (Grant ID 2025364). This article is a deliverable for that project. Neil Chue Hong’s contributions to this article were funded by the UK Research Councils through grant EP/S021779/1.
Author information
Authors and affiliations.
American Geophysical Union, 2000 Florida Ave. NW, Washington, DC, 20009, USA
Shelley Stall, Matthew Giampoala, R. Brooks Hanson & Brian Sedora
Crossref, Lynnfield, MA, 01940, USA
Geoffrey Bilder & Patricia Feeney
Taylor & Francis, London, UK
Matthew Cannon & Vincent Lizzi
SSI/University of Edinburgh, Edinburgh, UK
Neil Chue Hong
GigaScience Press, New Territories, Hong Kong SAR
Scott Edmunds
Michael J. Fox Foundation, New York, NY, 10163, USA
Christopher C. Erdmann
F1000Research, London, UK
Michael Evans
Wiley, Hoboken, NJ, 07030, USA
Rosemary Farmer & Kate Perry
American Meteorological Society, Boston, MA, 02108, USA
Michael Friedman
EMBL-EBI, Cambridgeshire, UK
Melissa Harrison
Atypon, 111 River Street, Hoboken, NJ, 07030, USA
Dimitris Karaiskos
University of Illinois at Urbana-Champaign, Urbana, IL, 61801, USA
Daniel S. Katz
Elsevier, Radarweg 29, 1043 NX, Amsterdam, The Netherlands
Viviana Letizia
Hindawi, 1 Fitzroy Square, London, W1T 5HF, UK
Catriona MacCallum
American Astronomical Society, Washington, DC, 20006, USA
August Muench
CHORUS, 72 Dreyer Avenue, Staten Island, NY, 10314, USA
Howard Ratner
PANGAEA, Bremen, Germany
Uwe Schindler
DKRZ/IPCC DDC German Climate Computing Center (DKRZ), Hamburg, Germany
Martina Stockhause
Plos, 1265 Battery Street, San Francisco, CA, 94111, USA
Randy Townsend
AAAS, 1200 New York Ave NW, Washington, DC, 20005, USA
Jake Yeston
University of Virginia, Charlottesville, VA, 22904, USA
Timothy Clark
You can also search for this author in PubMed Google Scholar
Contributions
Conceptualization - All authors. Writing - Original Draft - All authors. Writing - Review and Editing - All authors. Supervision - Shelley Stall, Daniel Katz, Timothy Clark, Brian Sedora.
Corresponding author
Correspondence to Shelley Stall .
Competing interests
Authors include representatives and editors from: American Astronomical Society, American Geophysical Union, American Meteorological Society, Atypon, CHORUS, Crossref, DKRZ/IPCC DDC, Elsevier, European Molecular Biology Laboratory - European Bioinformatics Institute, F1000Research, GigaScience Press, Hindawi (Wiley), Journal of Open Research Software (Ubiquity Press), Journal of Open Source Software (Open Journals), Michael J. Fox Foundation, PANGAEA/University of Bremen, Plos, Science/AAAS, Taylor & Francis, University of Edinburgh /Software Sustainability Institute, University of Illinois Urbana-Champagne, University of Virginia, Wiley.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Stall, S., Bilder, G., Cannon, M. et al. Journal Production Guidance for Software and Data Citations. Sci Data 10 , 656 (2023). https://doi.org/10.1038/s41597-023-02491-7
Download citation
Received : 12 April 2023
Accepted : 16 August 2023
Published : 26 September 2023
DOI : https://doi.org/10.1038/s41597-023-02491-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

Data Sources
- Search Strategies
- Quick Statistics
- Business & Economics This link opens in a new window
- Demographics
- Health, Nursing, Nutrition
- International/Area Studies
- Labor/Workforce
- Public Opinion
- U.S. Census ↗ This link opens in a new window
- Voting & Elections
- Gender & Sexuality
- Data Archives
- Data Portals
- GIS/Spatial Data ↗ This link opens in a new window
- Textual Data
- Software & Analysis
Citing data
More resources for citing data.
- Classes & Workshops
- Resources for Politics Honors Seminars
General Information
For assistance, please submit a request . You can also reach us via the chat below, email [email protected] , or join Discord server .
If you've met with us before, tell us how we're doing .
Service Desk and Chat
Bobst Library , 5th floor
Staffed Hours: Spring 2024
Mondays: 12pm - 5pm Tuesdays: 12pm - 5pm Wednesdays: 12pm - 5pm Thursdays: 12pm - 5pm Fridays: 12pm - 5pm
Data Services closes for winter break at the end of the day on Friday, Dec. 22, 2023. We will reopen on Wednesday, Jan. 3, 2024.

Data should be cited within our work for the same reasons journal articles are cited: to give credit where credit is due (original author/producer) and to help other researchers find the material. If you use data without citation, that is deeply problematic for academic integrity as well as reproducibility purposes. Pay attention to licenses (here's a page on those) and give attribution!
A data citation includes the typical components of other citations:
Author or creator: the entity/entities responsible for creating the data Date of publication: the date the data was published or otherwise released to the public Title: the title of the dataset or a brief description of it if it's missing a title Publisher: entity responsible for hosting the data (like a repository or archive) URL or preferably, a DOI: a link that points to the data Data Accessed: since most data are published without versions, it's important to note the time that you accessed the data in case newer releases are made over time.
Citation standards for data sets differ by journal, publisher, and conference, but you have a few options generally (depending on the situation):
- Use the format of a style manual as determined by a publisher or conference, such as IEEE or ACM. If you use a citation manager (highly recommended for organizing research reading!) like Zotero (which we support at NYU - check out our Zotero guide ), you can have them export your citations in whatever format you need.
- Use the author or repository's preferred citation that they list on the page where you downloaded the data initially.
Here's an example of how to find the citation information for a dataset hosted on Zenodo , a generalist repository that houses data, code, and more:
All scholarly or academic work requires that you cite your sources, whether you are writing a long paper or a quick report. Why is citing your research so important?
Researching and writing a paper ideally involves a process of exploring and learning. By citing your sources, you are showing your reader how you came to your conclusions and acknowledging the other people's work that brought you to your conclusions. Citing sources:
- Documents your research and scholarship
- Acknowledges the work of others whose scholarship contributed to your work
- Helps your reader understand the context of your argument
- Provides information for your reader to use to locate additional information on your topic
- Establishes the credibility of your scholarship
- Provides you with an opportunity to demonstrate your own integrity and understanding of academic ethics
Partially adapted from "When and Why to Cite Sources." SUNY Albany. 2008. Retrieved 14 Jan 2009.
- Data-Planet Data Basics Data Basics is a module in Data-Planet that provides resources and examples for citing datasets and statistics when incorporating them into research.
- IASSIST Quick Guide to Data Citation Includes examples from APA, MLA, and Chicago styles.
- How to Cite Data A comprehensive guide with examples from Michigan State University Libraries.
- << Previous: Software & Analysis
- Next: Classes & Workshops >>
- Last Updated: Mar 25, 2024 11:30 AM
- URL: https://guides.nyu.edu/datasources
Me doing stuff
Wednesday 28 february 2018, publishing datasets on zenodo and citing them with mendeley, no comments:, post a comment.
Note: only a member of this blog may post a comment.
Frequently Asked Questions
Tip : See also the OpenAIRE FAQ for general information on Open Science and European Commission funded research.
Usage statistics
Get started.
- Quick start
- Create an account
- Logging in and logging out
- Navigating Zenodo
- About records
- Create new upload
- Describe records
- Manage files
- Manage records
- Manage versions
Collaborate and share
- Link sharing
- Access requests
- Submit for review
- Submit to community
- Manage your submissions
- Membership invitations
Communities
- About communities
- Create new community
- View my communities
- Manage community settings
- Manage members
- Review submissions
- Curate records
- Edit profile
- Change password
- Reset password
- Change profile visibility
- Linking your GitHub/ORCID/OpenAIRE account
- Manage notification preferences
- View logged in devices
- What's new?
- What's changed?
Search guide
Nih data management and sharing plan guidance.
- Element 1: Data Types
- Element 2: Related Tools, Software and/or Code:
- Element 3: Standards
- Element 4: Data Preservation, Access, and Associated Timelines
- Element 5: Access, Distribution, and Reuse Considerations
- Element 6: Oversight of Data Management and Sharing
This site uses cookies. Find out more on how we use cookies
Referencing and citing content
You can use third-party tools to cite and reference content on GitHub.
In this article
Issuing a persistent identifier for your repository with zenodo.
To make your repositories easier to reference in academic literature, you can create persistent identifiers, also known as Digital Object Identifiers (DOIs). You can use the data archiving tool Zenodo to archive a repository on GitHub.com and issue a DOI for the archive.
- Zenodo can only access public repositories, so make sure the repository you want to archive is public .
- If you want to archive a repository that belongs to an organization, the organization owner may need to approve access for the Zenodo application.
- Make sure to include a license in your repository so readers know how they can reuse your work.
- Navigate to the login page for Zenodo.
- Click Log in with GitHub .
- Review the information about access permissions, then click Authorize zenodo .
- Navigate to the Zenodo GitHub page .
- To the right of the name of the repository you want to archive, toggle the button to On .
Zenodo archives your repository and issues a new DOI each time you create a new GitHub release . Follow the steps at " Managing releases in a repository " to create a new one.
Publicizing and citing research material with Figshare
Academics can use the data management service Figshare to publicize and cite research material. For more information, see Figshare's support site .
ODISSEI – Open Data Infrastructure for Social Science and Economic Innovations

A short practical guide for preparing and sharing your analysis code
Written by Erik-Jan van Kesteren
With the increasing popularity of open science practices, it is now more and more common to openly share data processing and analysis code along with more traditional scientific objects such as papers. There are many benefits to doing so: it makes your work more easily verifiable, reproducible, and reusable. But what are the best ways to create an understandable, openly accessible, findable, citable, and stable archive of your code? In this post, we look at what you need to do to prepare your code folder and then how to upload it to Zenodo. Note that this is one of many ways to achieve this goal, and if you’re starting a new project it is worth planning for code sharing ahead of time.

Prepare your code folder
To make code available, you will be uploading it to the internet as a single folder. The code you will upload will be openly accessible, and it will stay that way indefinitely. Therefore, it is necessary that you prepare your code folder (also called a “repository”) for publication. This requires time and effort, and for every project the requirements are different [1] . Below you can find a small checklist:
- Make a logical, understandable folder structure. For example, for a research project with data processing, visualization, and analysis I like the following structure:
- Make sure no privacy-sensitive information is leaked. Remove non-shareable data objects (raw and processed!), passwords hardcoded in your scripts, comments containing private information, and so on.
- Create a legible readme file in the folder that describes what the code does, where to find which parts of the code, and what needs to be done to run the code. For example, even if the code uses restricted-access data, a reference to the data should be included [2] . You can choose how elaborate to make the readme file! It could be a simple text file, a word document, a pdf, or a markdown document with images describing the structure. It is best if someone who does not know the project can understand the entire project based on the readme – this includes yourself in a few years from now!
Strong recommendations
- Reformat the code so that it is portable and easily reproducible. This means that when someone else downloads the folder, they do not need to change the code to run it. For example, this means that you do not read data with absolute paths (e.g., C:/my_name/Documents/PhD/projects/project_title/raw_data/questionnaire_data.csv ) on your computer, but only to relative paths on the project (e.g., raw_data/questionnaire_data.csv ). For example, if you use the R programming language it is good practice to use an R Project .
- Format your code so that it is legible by others. Write informative comments, split up your scripts in logical chunks, and use a consistent style (for R I like the tidyverse style )
Nice to have
- Record the software packages that you used to run the projects, including their versions. If a package gets updated, your code may no longer run! Your package manager may already do this, e.g., for python, you can use pip freeze > requirements.txt . In R, you can use the renv package for this.
- If you have privacy-sensitive data, it may still be possible to create a synthetic or fake version of this data for others to run the code on. This ensures maximum reproducibility.
Compressing the file folder
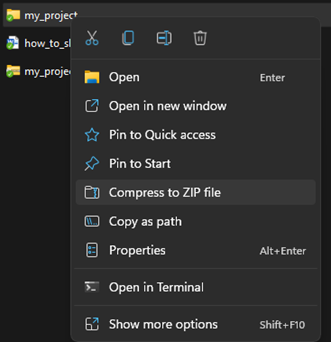
The last step before uploading the code repository to Zenodo is to compress the folder. This can be done in Windows 11 by right-clicking the folder and pressing “compress to zip file”. It’s a good idea to go into the compressed folder afterwards, check if everything is there, and remove any unnecessary files (such as .Rhistory files for R).
After compressing, your code repository is now ready to be uploaded!
Uploading to Zenodo
Zenodo [3] is a website where you can upload any kind of research object: papers, code, datasets, questionnaires, presentations, and much more. After uploading, Zenodo will create a page containing your research object and metadata about the object, such as publication date, author, and keywords. In the figure below you can see an example of a code repository uploaded to Zenodo.
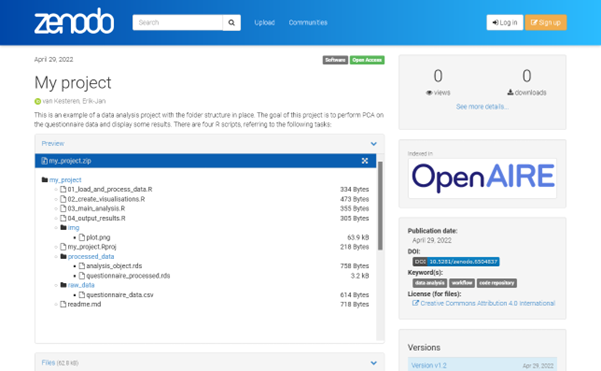
One of the key features of Zenodo is that you can get a Digital Object Identifier (DOI) for the objects you upload, making your research objects persistent and easy to find and cite. For example, in APA style I could cite the code as follows:
van Kesteren, Erik-Jan. (2022). My project (v1.2). Zenodo. https://doi.org/10.5281/zenodo.6504837
Zenodo itself is fully open source, hosted by CERN, and funded by the European Commission. These are exactly the kinds of conditions which make it likely to last for a long time! Hence, it is an excellent choice for uploading our code. So let’s get started!
Create an account
To upload anything to Zenodo, you need an account. If you already have an ORCID or a GitHub account, then you can link these immediately to your Zenodo login. I do recommend doing so as it will make it easy to link these services and use them together.
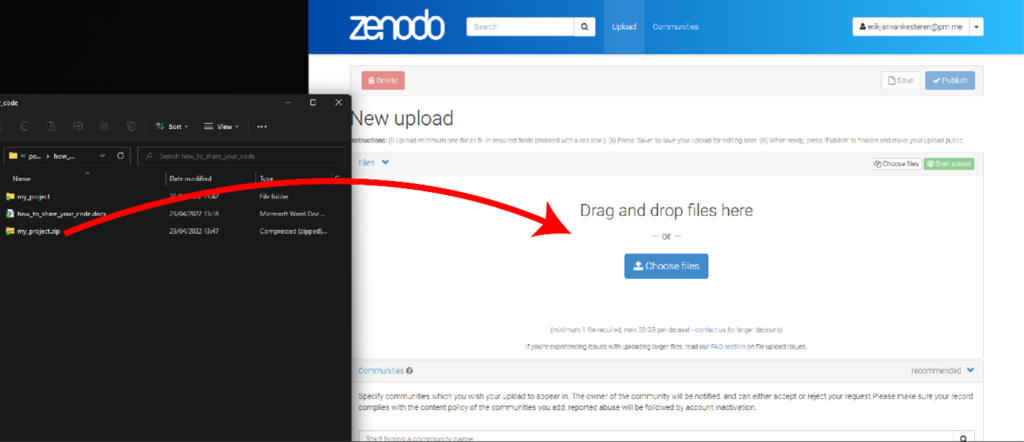
Start a new upload
When you click the “upload” button, you will get a page where you can upload your files, determine the type of upload, and create metadata for the research object. Now zip your prepared code folder and drag it to the upload window!
Fill out the metadata
Most of the metadata, such as author and institution, will be relatively simple to fill out. Here are some good defaults for a few of the remaining options:
- If the work is part of a community, you can associate the project with that community. For example, projects with support from the ODISSEI infrastructure should join that community: https://zenodo.org/communities/odissei .
- Another option you need to specify is the “upload type”. For code repositories, you can choose the “software” option.
- Pay close attention to the license: by default the CC-BY-4.0 license is selected. This is generally a good default, but for a short overview of what this means, see the creative commons website: https://creativecommons.org/licenses/by/4.0/ . You can opt for a different license by including a file called LICENSE in your repository.

The last step is to click “publish”. Your research code is now findable, citable, understandable, reproducible, and archived until the end of time! You can now show it to all your colleagues and easily cite it in your manuscript. If you get feedback and you want to change your code, you can also upload a new version of the same project on the Zenodo website.
In this post, I described a checklist for preparing your code folder for publication with a focus on understandability, and I have described one way in which you can upload your prepared code repository to an open-access archive. Zenodo is an easy, dependable and well-built option, but of course there are many alternatives, such as hosting it on your own website, on your University’s repository, using the Open Science Framework, GitHub, or using a publisher’s website; each has its own advantages and disadvantages. For instance, GitHub is advised if you want to keep track of versioning, whereas with OSF you can share anonymized data packages for blind peer-review. You should consider what is the best option for your research, and your community, and always check the funding and/or institutional requirements.
Relevant links
- Erik-Jan van Kesteren
- ODISSEI SoDa team
- ODISSEI community on Zenodo
[1] For requirements on sharing larger software projects, see https://fair-software.nl .
[2] Ideally, a citation recommended by the data provider including a DOI or other persistent identifier.
[3] According to https://about.zenodo.org/ , the name Zenodo is derived from Zenodotus, the first librarian of the ancient library of Alexandria and father of the first recorded use of metadata, a landmark in library history.
- Service Catalogue
- Open Science Primers
- Case studies
- Ask a Question
- Community of Practice
- Community Calls
- Open Science Corner
- JP Webinars
- OpenAIRE and EOSC
- EC Policies and mandates
- In practice
- EU+ member states
Organisation
- Become a member
- Partnerships
- Job opportunities
- Executive Board
- Management Office
- Standing Committees
- Working Groups
- Annual Reports
Open Positions
- Mid-Level Developer - Data Engineer Athens
Guides for OpenAIRE services
- Zenodo - A universal repository for all your research outcomes
What it does
How can i use it, technical requirements, need more information.

Share and preserve your publications, data, software and all other scholarship for free in OpenAIRE’s trusted repository hosted by CERN
Zenodo ( https://zenodo.org ) is an open repository for all scholarship, enabling researchers from all disciplines to share and preserve their research outputs, regardless of size or format. Free to upload and free to access, Zenodo makes scientific outputs of all kinds citable, shareable and discoverable for the long term.
Don’t have an appropriate institutional or thematic repository? Use Zenodo!
Zenodo is the name derived from Zenodotus , the first librarian of the ancient library of Alexandria and father of the first recorded use of metadata, a landmark in library history.
- Sharing and linking research: Zenodo provides a rich interface which enables linking research outputs to datasets and funding information.
- Citeable and discoverable: All uploads get a Digital Object Identifier (DOI) to make them easily and uniquely citeable. All open content is harvestable via OAI-PMH by third parties.
- Supports versioning: Via a top-level DOI you can support all the different versions of a file.
- Trusted, reliable, safe: Data is stored at CERN, which has considerable knowledge and experience operating large scale digital repositories. Data files and metadata are kept in multiple online and offline copies.
- Includes funding information and makes reporting easier: Zenodo allows you to link uploads to grants from more than 11 funders such as European Commission, National Science Foundation and Wellcome Trust. Zenodo is further integrated into reporting lines for research funded by the European Commission via OpenAIRE . Just upload your research to Zenodo, and we will take care of the reporting for you.
- Includes article level metrics: Tracks attention for scholarship uploaded.
- Flexible licensing: Zenodo encourages you to share your research as openly as possible to maximize use and re-use of your research results. However, we also acknowledge that one size does not fit all. Therefore, we allow for uploading under a variety of different licenses and access levels.
- Reviewing: Research materials can set to share with reviewers only, and also embargoed.
- Software preservation made simple: Zenodo is integrated with GitHub.
- Supports FAIR principles: Zenodo makes data Findable, Accessible, Interoperable and Reusable .
Zenodo is for all researchers, scientific communities and research institutions. It is open to all research outputs regardless of funding source.
Zenodo accepts any file format as well as both positive and negative results.
Zenodo does not impose any requirements on format, size, access restrictions or licence. Quite literally we wish there to be no reason for researchers not to share!
Data, software and other artefacts in support of publications may be the core, but equally welcome are the materials associated with conferences, projects or the institutions themselves, all of which are necessary to understand the scholarly process.
You are responsible for respecting applicable copyright and license conditions for the files you upload.
You can create and curate your own community for a workshop, project, department, journal, into which you can accept or reject uploads. Consider it your own complete digital repository!
Share your research output in 3 steps!
Zenodo offers simple and easy-to-use data archiving with maximum autonomy. The clear web interface allows you to easily upload your content in just a few steps.

Using GitHub? Check out our GitHub integration. Software Preservation Made Simple!
Content, Access and Reuse, Removal and Longevity policies are available here .
Total files size limit per record is 50GB (max 100 files). One-time 100GB quota can be requested and granted on a case-by-case basis.
Data stored in the CERN Data Center: Your research output is stored safely for the future in same cloud infrastructure as research data from CERN's Large Hadron Collider and using CERN's battle-tested repository software Invenio , which is used by some of the world's largest repositories such as INSPIRE HEP and CERN Document Server .
Open in every sense: Zenodo code is itself open source, and is built on the foundation of the Invenio digital library which is also open source. The work-in-progress, open issues, and roadmap are shared openly in GitHub , and contributions to any aspect are welcomed from anyone.
All meta data is openly available under a CC0 licence, and all open content is openly accessible through open APIs.
Check out our Zenodo presentation here .
And check out our Zotero group for articles mentioning or talking about Zenodo.
- Zenodo: open digital repository 7th December, 2022
Video Tutorial
Service factsheet

- Amnesia - Anonymize your data before publishing
- Argos - Plan and follow your data
- Episciences - Overlay Journal Platform
- CONNECT - Research Community Gateway
- EXPLORE - How to link a publication to your funding
- EXPLORE - How to report your publication and data to the EC
- EXPLORE - Link your work to ORCID
- OpenAPC - Aggregating, normalising and disseminating data on APC and BPC expenditures
- OpenCitations - Publication of open bibliographic and citation data
- PROVIDE - How to enrich research artifacts
- PROVIDE - How to validate and register your data source
- ScholExplorer - Literature & Data interlinking
- UsageCounts - How to track the usage activity of your repository
Still have questions?
- Español – América Latina
- Português – Brasil
- Tiếng Việt
Citing TensorFlow
TensorFlow publishes a DOI for the open-source code base using Zenodo.org: 10.5281/zenodo.4724125
TensorFlow's white papers are listed for citation below.
Large-Scale Machine Learning on Heterogeneous Distributed Systems
Access this white paper.
Abstract: TensorFlow is an interface for expressing machine learning algorithms and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.
In BibTeX format
If you use TensorFlow in your research and would like to cite the TensorFlow system, we suggest you cite this whitepaper.
Or in textual form:
TensorFlow: A System for Large-Scale Machine Learning
Abstract: TensorFlow is a machine learning system that operates at large scale and in heterogeneous environments. TensorFlow uses dataflow graphs to represent computation, shared state, and the operations that mutate that state. It maps the nodes of a dataflow graph across many machines in a cluster, and within a machine across multiple computational devices, including multicore CPUs, general purpose GPUs, and custom-designed ASICs known as Tensor Processing Units (TPUs). This architecture gives flexibility to the application developer: whereas in previous “parameter server” designs the management of shared state is built into the system, TensorFlow enables developers to experiment with novel optimizations and training algorithms. TensorFlow supports a variety of applications, with a focus on training and inference on deep neural networks. Several Google services use TensorFlow in production, we have released it as an open-source project, and it has become widely used for machine learning research. In this paper, we describe the TensorFlow dataflow model and demonstrate the compelling performance that TensorFlow achieves for several real-world applications.
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License , and code samples are licensed under the Apache 2.0 License . For details, see the Google Developers Site Policies . Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2022-01-21 UTC.
4 minute read
What is a CITATION.cff file?
CITATION.cff files are plain text files with human- and machine-readable citation information for software (and datasets). Code developers can include them in their repositories to let others know how to correctly cite their software.
This is an example of a simple CITATION.cff file:
The format of CITATION.cff files is the Citation File Format (CFF) .
Why you should add a CITATION.cff file to your repository!
It is very easy to correctly cite a paper: all the necessary information ( metadata ) can be found on the title page or the article website. Software and datasets have no title page, the relevant information is often less obvious.
People who want to cite your software may ask questions like:
What is the name of the software (it’s probably not my_scripts/run.m or analysis.py )?
What label should I use to uniquely identify the version of the software I have used?
What is the appropriate set of people that should be cited as authors?
The person who wants to cite your software will probably not be able to answer these questions accurately and consistently themselves, but you can! Give them all the right information in a CITATION.cff file, and they can cite your software correctly .
Also, if you publish your software in an archive or registry, they (or their systems) can re-use the citation metadata from your CITATION.cff file.
Supported by GitHub

Supported by Zenodo
Supported by zotero.

Create a CITATION.cff file now!
There are different options for getting started with the Citation File Format:
- Create a CITATION.cff file with ease using the form on the cffinit website .
- Copy and paste the example above into the root of your code repository, and adapt the information to your software.
To learn more about how to work with the Citation File Format, have a look at the documentation .
The Citation File Format is much more powerful than the minimal example above suggests. It also allows you to record the references for your software, for example, to make visible the work that your own work builds on. To find out what citation-relevant information you can provide in CITATION.cff files, have a look at the guide to the Citation File Format .
Tools for working with CITATION.cff files
Different tools exist to help you work with CITATION.cff files:
- The initializer can help you create a CITATION.cff file from scratch: https://citation-file-format.github.io/cff-initializer-javascript/ .
- The converter can convert a CITATION.cff to other formats (e.g., to BibTeX , RIS , CodeMeta , and others): https://github.com/citation-file-format/cff-converter-python .
There are further tools for specific use cases, and different environments. The documentation has a brief overview of available tools .
Have an idea? Found a problem?
We try to make contributing to CFF as easy as possible! Even tweeting a problem may be helpful, it’s that easy.
Better still, if you can think of something that would make CITATION.cff files better, or you have found something that didn’t work as you would have expected: Please check out how you can share your idea or bug report in the contribution guide on GitHub .
Acknowledgments
We would like to thank the following institutions for supporting the development of the Citation File Format:
- The Institute for Software Technology of the German Aerospace Center (DLR)
- The Netherlands eScience Center
- The Software Sustainability Institute
CERN Accelerating science
Zenodo is an open repository for all scholarship, enabling researchers from all disciplines to share and preserve their research outputs, regardless of size or format. Free to upload and free to access, Zenodo makes scientific outputs of all kinds citable, shareable and discoverable for the long term.
- Search & Read
- Online resources
- Privacy policy
- Cookie policy
- Terms of use
- General policies
- Infrastructure
About Zenodo
Passionate about open science.
Built and developed by researchers, to ensure that everyone can join in Open Science.
The OpenAIRE project, in the vanguard of the open access and open data movements in Europe was commissioned by the EC to support their nascent Open Data policy by providing a catch-all repository for EC funded research. CERN, an OpenAIRE partner and pioneer in open source, open access and open data, provided this capability and Zenodo was launched in May 2013.
In support of its research programme CERN has developed tools for Big Data management and extended Digital Library capabilities for Open Data. Through Zenodo these Big Science tools could be effectively shared with the long-tail of research.
Open Science knows no borders!
The need for a catch-all is not restricted to one funder, or one nation, so the concept caught on, and Zenodo rapidly started welcoming research from all over the world, and from every discipline.
The digital revolution has necessitated a retooling of the scholarly processes to handle data and software, but this is proceeding at varying speeds across different communities, disciplines, and nations. To ensure no one is left behind through lack of access to the necessary tools and resources, Zenodo makes the sharing, curation and publication of data and software a reality for all researchers.
Every last detail
To fully understand and reproduce research performed by others, it is necessary to have all the details. In the digital age, that means all the digital artefacts, which are all welcomed in Zenodo.
To be an effective catch-all, that eliminates barriers to adopting data sharing practices, Zenodo does not impose any requirements on format, size, access restrictions or licence. Quite literally we wish there to be no reason for researchers not to share!
Data, software and other artefacts in support of publications may be the core, but equally welcome are the materials associated with the conferences, projects or the institutions themselves, all of which are necessary to understand the scholarly process.
Don't wait until the publication date!
Publication may happen months or years after completion of the research, so collecting together all the research artefacts at that stage to publish openly is often challenging. Zenodo therefore offers the possibility to house closed and restricted content, so that artefacts can be captured and stored safely whilst the research is ongoing, such that nothing is missing when they are openly shared later in the research workflow.
Additionally, to help publishing, research materials for the review process can be safely uploaded to Zenodo in restricted records and then protected links can be shared with the reviewers. Content can also be embargoed and automatically opened when the associated paper is published.
To support all these use cases, the simple web interface is supplemented by a rich API which allows third party tools and services to use Zenodo as a backend in their workflow
Open Science Services
Zenodo helps researchers receive credit by making the research results citable and through OpenAIRE integrates them into existing reporting lines to funding agencies like the European Commission. Citation information is also passed to DataCite and onto the scholarly aggregators.
For future generations
The scholarly communication landscape is undergoing change, there are debates about the ideal services, the ideal business models, the ideal custodians, amidst which Zenodo aims to offer a viable and concrete alternative to commercial services from a memory institution for particle physics, CERN!
Zenodo is derived from Zenodotus , the first librarian of the Ancient Library of Alexandria and father of the first recorded use of metadata, a landmark in library history.
Open in every sense
Zenodo code is itself open source, and is built on the foundation of the Invenio digital library which is also open source. The work-in-progress, open issues, and roadmap are shared openly in GitHub , and contributions to any aspect are welcomed from anyone.
All meta data is openly available under CC0 licence, and all open content is openly accessible through open APIs.
Open to all suggestions for new features, via GitHub, and especially open to all contributions of code via pull requests!
Logo - 10th anniversary
Below logos are licensed under Creative Common Attribution Share-Alike 4.0 International (CC-BY-SA):
Zenodo Advocacy
Happy with Zenodo? Every little effort helps reach a global audience and spread the word about Open Science and how Zenodo makes it possible.
Feel free to use the following material to help present Zenodo. All material is licensed CC-BY.
- Presentation
In the press
Check out our Zotero group for articles mentioning or talking about Zenodo.
Know of an article not on the list? Contact us , so we can add it.
Citing Zenodo
To cite Zenodo, you can use the following BibTeX:
This site uses cookies. Find out more on how we use cookies
Preprint
- Preprint essd-2024-77
A flux tower site attribute dataset intended for land surface modeling
Abstract. Land surface models (LSMs) should have reliable forcing, validation, and surface attribute data as the foundation for effective model development and improvement. Eddy covariance flux tower data are considered the benchmarking data for LSMs. However, currently available flux tower datasets often require multiple aspects of processing to ensure data quality before application to LSMs. More importantly, these datasets lack site-observed attribute data, limiting their use as benchmarking data. Here, we conducted a comprehensive quality screening of the existing reprocessed flux tower dataset, including the proportion of gap-filled data, external disturbances, and energy balance closure (EBC), leading to 90 high-quality sites. For these sites, we collected vegetation, soil, topography information, and wind speed measurement height from literature, regional networks, and Biological, Ancillary, Disturbance, and Metadata (BADM) files. Then we obtained the final flux tower attribute dataset by global data product complement and plant functional types (PFTs) classification. This dataset is provided in NetCDF format complete with necessary descriptions and reference sources. Model simulations revealed substantial disparities in output between the attribute data observed at the site and the defaults of the model, underscoring the critical role of site-observed attribute data and increasing the emphasis on flux tower attribute data in the LSM community. The dataset addresses the lack of site attribute data to some extent, reduces uncertainty in LSMs data source, and aids in diagnosing parameter as well as process deficiencies. The dataset is available at https://doi.org/10.5281/zenodo.10939725 (Shi et al., 2024).
- Preprint (PDF, 1821 KB)
- Supplement (539 KB)
- Preprint (1821 KB)
- Metadata XML

Status : open (until 17 May 2024)
Report abuse
Please provide a reason why you see this comment as being abusive. You might include your name and email but you can also stay anonymous.
Please provide a reason why you see this comment as being abusive.
Please confirm reCaptcha.
https://doi.org/10.5194/essd-2024-77-supplement
A flux tower site attribute dataset intended for land surface modeling Jiahao Shi et al. https://doi.org/10.5281/zenodo.10939725
- Supplement: 4
Viewed (geographical distribution)
Wenzong dong, hongbin liang, jianxin zeng, haolin zhang, zhongwang wei, shupeng zhang, shaofeng liu, yongjiu dai.
IMAGES
VIDEO
COMMENTS
Tutorial of how to generate citation information, including DOI, for GitHub repositories using Zenodo. Making citable GitHub repositories is great for open s...
Cite the software that was used in your research, including all software that was used to generate and analyze data. The Force11 recommendations: "citation is partly a record of software important to a research outcome". "Software should be cited on the same basis as any other research product such as a paper or a book; that is, authors should ...
January 20, 2020. This document provides a simple, generic checklist that authors of academic work (papers, books, conference abstracts, blog posts, etc.) can use to ensure they are following good practice when referencing and citing software they have used, both created by themselves for their research as well as obtained from other sources.
Steps must be taken to preserve and cite software in a sustainable, identifiable and simple way. This is how digital repositories like Zenodo can help. Best practice for citing a digital resource like code is to refer to a digital object identifier (DOI) for it whenever possible. This is because DOIs are persistent identifiers that can be ...
Use the Software and Dataset Citation Use Cases provided below as a guide to ensure coverage of most variations. 3. Display the human readable citation correctly. Consult the Software and Data ...
A data citation includes the typical components of other citations: Author or creator: the entity/entities responsible for creating the data. Date of publication: the date the data was published or otherwise released to the public. Title: the title of the dataset or a brief description of it if it's missing a title.
Thus, in Mendeley, the free online citation manager, for Linux, Windows and Mac, with Bibtex, Endnote and RIS Import/Export support, I ended up creating a journal article entry, where the journal name is "Dataset on Zenodo". And most citation styles, such as MDPI IJGI, or Nature if you like, will nicely list your data this way (see above) in ...
How to cite software: current best practice. Chue Hong, Neil 1. Show affiliations. Introduction to the software citation principles, and how they can be applied, as part of the Software Citation Workshop organised by the Software Sustainability Institute, the British Library and The Alan Turing Institute.
Zenodo is a free and open digital archive built by CERN and OpenAIRE, enabling researchers to share and preserve research output in any size, format and from all fields of research. ... Zenodo is using a citation brokering software built for the Asclepias project called Asclepias Broker. The software is open sourced under the MIT license.
Main features of Zotero. •Web browser integration via plugin to capture references & online syncing •Generation of in-text citations, footnotes, and bibliographies •Integration with various word processors (MS Word, LibreOffice Writer, and Google Docs) •Styles of most academic journals are available •Users can create their own ...
Zenodo is a free and open digital archive built by CERN and OpenAIRE, enabling researchers to share and preserve research output in any size, format and from all fields of research.
Navigate to the Zenodo GitHub page. To the right of the name of the repository you want to archive, toggle the button to On. Zenodo archives your repository and issues a new DOI each time you create a new GitHub release. Follow the steps at "Managing releases in a repository" to create a new one. Publicizing and citing research material with ...
Uploading to Zenodo. Zenodo is a website where you can upload any kind of research object: papers, code, datasets, questionnaires, presentations, and much more. After uploading, Zenodo will create a page containing your research object and metadata about the object, such as publication date, author, and keywords.
OpenCitations - Publication of open bibliographic and citation data. PROVIDE - How to enrich research artifacts. PROVIDE - How to validate and register your data source. ScholExplorer - Literature & Data interlinking. UsageCounts - How to track the usage activity of your repository. Zenodo - A universal repository for all your research outcomes.
A. Manually. To download files from Zenodo, all one needs to do is to navigate to the entry they would like to download, scroll down to the Files section on the webpage, and press the button download next to each of the files they would like to download (highlighted in Figure 6).
TensorFlow publishes a DOI for the open-source code base using Zenodo.org: 10.5281/zenodo.4724125. TensorFlow's white papers are listed for citation below. ... If you use TensorFlow in your research and would like to cite the TensorFlow system, we suggest you cite this whitepaper. @misc{tensorflow2015-whitepaper, title={ {TensorFlow}: Large ...
Supported by Zenodo . When you have a CITATION.cff file in your GitHub repository, make a release and publish it on Zenodo via the Zenodo-GitHub integration, Zenodo will use the citation information you've provided to populate the publication entry! This makes it easier for software developers and maintainers to publish their software with ...
This video tutorial is a step-by-step guide on how to use Zenodo to upload research results.
Zenodo is an open repository for all scholarship, enabling researchers from all disciplines to share and preserve their research outputs, regardless of size or format. Free to upload and free to access, Zenodo makes scientific outputs of all kinds citable, shareable and discoverable for the long term. Access. Free. Type. Digital library. Subjects.
Citation information is also passed to DataCite and onto the scholarly aggregators. For future generations The scholarly communication landscape is undergoing change, there are debates about the ideal services, the ideal business models, the ideal custodians, amidst which Zenodo aims to offer a viable and concrete alternative to commercial ...
Safe — your research is stored safely for the future in CERN's Data Centre for as long as CERN exists.; Trusted — built and operated by CERN and OpenAIRE to ensure that everyone can join in Open Science.; Citeable — every upload is assigned a Digital Object Identifier (DOI), to make them citable and trackable.; No waiting time — Uploads are made available online as soon as you hit ...
Abstract. Land surface models (LSMs) should have reliable forcing, validation, and surface attribute data as the foundation for effective model development and improvement. Eddy covariance flux tower data are considered the benchmarking data for LSMs. However, currently available flux tower datasets often require multiple aspects of processing to ensure data quality before application to LSMs ...
No need to add the. author's. surname twice. Citation. Making reference to an idea pointed out by several authors (three or more authors): Jiménez Raya et al. (2007)have formulated perhaps one of the most comprehensive definitions of LA (and TA) to date.
In January 2019, the Asclepias Broker harvested citation links to Zenodo objects from three discovery systems: the NASA Astrophysics Datasystem (ADS), Crossref Event Data and Europe PMC. Each row of our dataset represents one unique link between a citing publication and a Zenodo DOI. Both endpoints are described by basic metadata. The second dataset contains usage metrics for every cited ...