How to Write Data Analysis Reports in 9 Easy Steps


Table of contents
Imagine a bunch of bricks. They don’t have a purpose until you put them together into a house, do they?
In business intelligence, data is your building material, and a quality data analysis report is what you want to see as the result.
But if you’ve ever tried to use the collected data and assemble it into an insightful report, you know it’s not an easy job to do. Data is supposed to tell a story about your performance, but there’s a long way from unprocessed, raw data to a meaningful narrative that you can use to create an actionable plan for making steady progress towards your goals.
This article will help you improve the quality of your data analysis reports and build them effortlessly and fast. Let’s jump right in.
What Is a Data Analysis Report?
Why is data analysis reporting important, how to write a data analysis report 9 simple steps, data analysis report examples.

A data analysis report is a type of business report in which you present quantitative and qualitative data to evaluate your strategies and performance. Based on this data, you give recommendations for further steps and business decisions while using the data as evidence that backs up your evaluation.
Today, data analysis is one of the most important elements of business intelligence strategies as companies have realized the potential of having data-driven insights at hand to help them make data-driven decisions.
Just like you’ll look at your car’s dashboard if something’s wrong, you’ll pull your data to see what’s causing drops in website traffic, conversions, or sales – or any other business metric you may be following. This unprocessed data still doesn’t give you a diagnosis – it’s the first step towards a quality analysis. Once you’ve extracted and organized your data, it’s important to use graphs and charts to visualize it and make it easier to draw conclusions.
Once you add meaning to your data and create suggestions based on it, you have a data analysis report.
A vital detail everyone should know about data analysis reports is their accessibility for everyone in your team, and the ability to innovate. Your analysis report will contain your vital KPIs, so you can see where you’re reaching your targets and achieving goals, and where you need to speed up your activities or optimize your strategy. If you can uncover trends or patterns in your data, you can use it to innovate and stand out by offering even more valuable content, services, or products to your audience.
Data analysis is vital for companies for several reasons.
A reliable source of information
Trusting your intuition is fine, but relying on data is safer. When you can base your action plan on data that clearly shows that something is working or failing, you won’t only justify your decisions in front of the management, clients, or investors, but you’ll also be sure that you’ve taken appropriate steps to fix an issue or seize an important opportunity.
A better understanding of your business
According to Databox’s State of Business Reporting , most companies stated that regular monitoring and reporting improved progress monitoring, increased team effectiveness, allowed them to identify trends more easily, and improved financial performance. Data analysis makes it easier to understand your business as a whole, and each aspect individually. You can see how different departments analyze their workflow and how each step impacts their results in the end, by following their KPIs over time. Then, you can easily conclude what your business needs to grow – to boost your sales strategy, optimize your finances, or up your SEO game, for example.
An additional way to understand your business better is to compare your most important metrics and KPIs against companies that are just like yours. With Databox Benchmarks , you will need only one spot to see how all of your teams stack up against your peers and competitors.
Instantly and Anonymously Benchmark Your Company’s Performance Against Others Just Like You
If you ever asked yourself:
- How does our marketing stack up against our competitors?
- Are our salespeople as productive as reps from similar companies?
- Are our profit margins as high as our peers?
Databox Benchmark Groups can finally help you answer these questions and discover how your company measures up against similar companies based on your KPIs.
When you join Benchmark Groups, you will:
- Get instant, up-to-date data on how your company stacks up against similar companies based on the metrics most important to you. Explore benchmarks for dozens of metrics, built on anonymized data from thousands of companies and get a full 360° view of your company’s KPIs across sales, marketing, finance, and more.
- Understand where your business excels and where you may be falling behind so you can shift to what will make the biggest impact. Leverage industry insights to set more effective, competitive business strategies. Explore where exactly you have room for growth within your business based on objective market data.
- Keep your clients happy by using data to back up your expertise. Show your clients where you’re helping them overperform against similar companies. Use the data to show prospects where they really are… and the potential of where they could be.
- Get a valuable asset for improving yearly and quarterly planning . Get valuable insights into areas that need more work. Gain more context for strategic planning.
The best part?
- Benchmark Groups are free to access.
- The data is 100% anonymized. No other company will be able to see your performance, and you won’t be able to see the performance of individual companies either.
When it comes to showing you how your performance compares to others, here is what it might look like for the metric Average Session Duration:
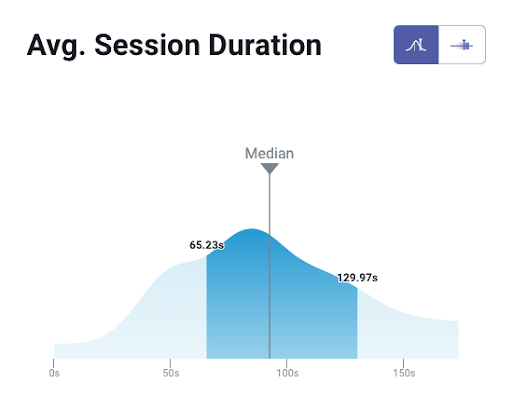
And here is an example of an open group you could join:

And this is just a fraction of what you’ll get. With Databox Benchmarks, you will need only one spot to see how all of your teams stack up — marketing, sales, customer service, product development, finance, and more.
- Choose criteria so that the Benchmark is calculated using only companies like yours
- Narrow the benchmark sample using criteria that describe your company
- Display benchmarks right on your Databox dashboards
Sounds like something you want to try out? Join a Databox Benchmark Group today!
It makes data accessible to everyone
Data doesn’t represent a magical creature reserved for data scientists only anymore. Now that you have streamlined and easy-to-follow data visualizations and tools that automatically show the latest figures, you can include everyone in the decision-making process as they’ll understand what means what in the charts and tables. The data may be complex, but it becomes easy to read when combined with proper illustrations. And when your teams gain such useful and accessible insight, they will feel motivated to act on it immediately.
Better collaboration
Data analysis reports help teams collaborate better, as well. You can apply the SMART technique to your KPIs and goals, because your KPIs become assignable. When they’re easy to interpret for your whole team, you can assign each person with one or multiple KPIs that they’ll be in charge of. That means taking a lot off a team leader’s plate so they can focus more on making other improvements in the business. At the same time, removing inaccurate data from your day-to-day operations will improve friction between different departments, like marketing and sales, for instance.
More productivity
You can also expect increased productivity, since you’ll be saving time you’d otherwise spend on waiting for specialists to translate data for other departments, etc. This means your internal procedures will also be on a top level.
Want to give value with your data analysis report? It’s critical to master the skill of writing a quality data analytics report. Want to know how to report on data efficiently? We’ll share our secret in the following section.
- Start with an Outline
- Make a Selection of Vital KPIs
- Pick the Right Charts for Appealing Design
- Use a Narrative
- Organize the Information
- Include a Summary
- Careful with Your Recommendations
- Double-Check Everything
- Use Interactive Dashboards
1. Start with an Outline
If you start writing without having a clear idea of what your data analysis report is going to include, it may get messy. Important insights may slip through your fingers, and you may stray away too far from the main topic. To avoid this, start the report by writing an outline first. Plan the structure and contents of each section first to make sure you’ve covered everything, and only then start crafting the report.
2. Make a Selection of Vital KPIs
Don’t overwhelm the audience by including every single metric there is. You can discuss your whole dashboard in a meeting with your team, but if you’re creating data analytics reports or marketing reports for other departments or the executives, it’s best to focus on the most relevant KPIs that demonstrate the data important for the overall business performance.
PRO TIP: How Well Are Your Marketing KPIs Performing?
Like most marketers and marketing managers, you want to know how well your efforts are translating into results each month. How much traffic and new contact conversions do you get? How many new contacts do you get from organic sessions? How are your email campaigns performing? How well are your landing pages converting? You might have to scramble to put all of this together in a single report, but now you can have it all at your fingertips in a single Databox dashboard.
Our Marketing Overview Dashboard includes data from Google Analytics 4 and HubSpot Marketing with key performance metrics like:
- Sessions . The number of sessions can tell you how many times people are returning to your website. Obviously, the higher the better.
- New Contacts from Sessions . How well is your campaign driving new contacts and customers?
- Marketing Performance KPIs . Tracking the number of MQLs, SQLs, New Contacts and similar will help you identify how your marketing efforts contribute to sales.
- Email Performance . Measure the success of your email campaigns from HubSpot. Keep an eye on your most important email marketing metrics such as number of sent emails, number of opened emails, open rate, email click-through rate, and more.
- Blog Posts and Landing Pages . How many people have viewed your blog recently? How well are your landing pages performing?
Now you can benefit from the experience of our Google Analytics and HubSpot Marketing experts, who have put together a plug-and-play Databox template that contains all the essential metrics for monitoring your leads. It’s simple to implement and start using as a standalone dashboard or in marketing reports, and best of all, it’s free!

You can easily set it up in just a few clicks – no coding required.
To set up the dashboard, follow these 3 simple steps:
Step 1: Get the template
Step 2: Connect your HubSpot and Google Analytics 4 accounts with Databox.
Step 3: Watch your dashboard populate in seconds.
3. Pick the Right Charts for Appealing Design
If you’re showing historical data – for instance, how you’ve performed now compared to last month – it’s best to use timelines or graphs. For other data, pie charts or tables may be more suitable. Make sure you use the right data visualization to display your data accurately and in an easy-to-understand manner.
4. Use a Narrative
Do you work on analytics and reporting ? Just exporting your data into a spreadsheet doesn’t qualify as either of them. The fact that you’re dealing with data may sound too technical, but actually, your report should tell a story about your performance. What happened on a specific day? Did your organic traffic increase or suddenly drop? Why? And more. There are a lot of questions to answer and you can put all the responses together in a coherent, understandable narrative.
5. Organize the Information
Before you start writing or building your dashboard, choose how you’re going to organize your data. Are you going to talk about the most relevant and general ones first? It may be the best way to start the report – the best practices typically involve starting with more general information and then diving into details if necessary.
6. Include a Summary
Some people in your audience won’t have the time to read the whole report, but they’ll want to know about your findings. Besides, a summary at the beginning of your data analytics report will help the reader get familiar with the topic and the goal of the report. And a quick note: although the summary should be placed at the beginning, you usually write it when you’re done with the report. When you have the whole picture, it’s easier to extract the key points that you’ll include in the summary.
7. Careful with Your Recommendations
Your communication skills may be critical in data analytics reports. Know that some of the results probably won’t be satisfactory, which means that someone’s strategy failed. Make sure you’re objective in your recommendations and that you’re not looking for someone to blame. Don’t criticize, but give suggestions on how things can be improved. Being solution-oriented is much more important and helpful for the business.
8. Double-Check Everything
The whole point of using data analytics tools and data, in general, is to achieve as much accuracy as possible. Avoid manual mistakes by proofreading your report when you finish, and if possible, give it to another person so they can confirm everything’s in place.
9. Use Interactive Dashboards
Using the right tools is just as important as the contents of your data analysis. The way you present it can make or break a good report, regardless of how valuable the data is. That said, choose a great reporting tool that can automatically update your data and display it in a visually appealing manner. Make sure it offers streamlined interactive dashboards that you can also customize depending on the purpose of the report.
To wrap up the guide, we decided to share nine excellent examples of what awesome data analysis reports can look like. You’ll learn what metrics you should include and how to organize them in logical sections to make your report beautiful and effective.
- Marketing Data Analysis Report Example
SEO Data Analysis Report Example
Sales data analysis report example.
- Customer Support Data Analysis Report Example
Help Desk Data Analysis Report Example
Ecommerce data analysis report example, project management data analysis report example, social media data analysis report example, financial kpi data analysis report example, marketing data report example.
If you need an intuitive dashboard that allows you to track your website performance effortlessly and monitor all the relevant metrics such as website sessions, pageviews, or CTA engagement, you’ll love this free HubSpot Marketing Website Overview dashboard template .

Tracking the performance of your SEO efforts is important. You can easily monitor relevant SEO KPIs like clicks by page, engaged sessions, or views by session medium by downloading this Google Organic SEO Dashboard .

How successful is your sales team? It’s easy to analyze their performance and predict future growth if you choose this HubSpot CRM Sales Analytics Overview dashboard template and track metrics such as average time to close the deal, new deals amount, or average revenue per new client.

Customer Support Analysis Data Report Example
Customer support is one of the essential factors that impact your business growth. You can use this streamlined, customizable Customer Success dashboard template . In a single dashboard, you can monitor metrics such as customer satisfaction score, new MRR, or time to first response time.

Other than being free and intuitive, this HelpScout for Customer Support dashboard template is also customizable and enables you to track the most vital metrics that indicate your customer support agents’ performance: handle time, happiness score, interactions per resolution, and more.

Is your online store improving or failing? You can easily collect relevant data about your store and monitor the most important metrics like total sales, orders placed, and new customers by downloading this WooCommerce Shop Overview dashboard template .

Does your IT department need feedback on their project management performance? Download this Jira dashboard template to track vital metrics such as issues created or resolved, issues by status, etc. Jira enables you to gain valuable insights into your teams’ productivity.

Need to know if your social media strategy is successful? You can find that out by using this easy-to-understand Social Media Awareness & Engagement dashboard template . Here you can monitor and analyze metrics like sessions by social source, track the number of likes and followers, and measure the traffic from each source.

Tracking your finances is critical for keeping your business profitable. If you want to monitor metrics such as the number of open invoices, open deals amount by stage by pipeline, or closed-won deals, use this free QuickBooks + HubSpot CRM Financial Performance dashboard template .

Rely on Accurate Data with Databox
“I don’t have time to build custom reports from scratch.”
“It takes too long and becomes daunting very soon.”
“I’m not sure how to organize the data to make it effective and prove the value of my work.”
Does this sound like you?
Well, it’s something we all said at some point – creating data analytics reports can be time-consuming and tiring. And you’re still not sure if the report is compelling and understandable enough when you’re done.
That’s why we decided to create Databox dashboards – a world-class solution for saving your money and time. We build streamlined and easy-to-follow dashboards that include all the metrics that you may need and allow you to create custom ones if necessary. That way, you can use templates and adjust them to any new project or client without having to build a report from scratch.
You can skip the setup and get your first dashboard for free in just 24 hours, with our fantastic customer support team on the line to assist you with the metrics you should track and the structure you should use.
Enjoy crafting brilliant data analysis reports that will improve your business – it’s never been faster and more effortless. Sign up today and get your free dashboard in no time.
Get practical strategies that drive consistent growth
12 Tips for Developing a Successful Data Analytics Strategy

What Is Data Reporting and How to Create Data Reports for Your Business
What is kpi reporting kpi report examples, tips, and best practices.

Build your first dashboard in 5 minutes or less
Latest from our blog
- Playmaker Spotlight: Tory Ferrall, Director of Revenue Operations March 27, 2024
- New in Databox: Safeguard Your Data With Advanced Security Settings March 18, 2024
- Metrics & KPIs
- vs. Tableau
- vs. Looker Studio
- vs. Klipfolio
- vs. Power BI
- vs. Whatagraph
- vs. AgencyAnalytics
- Product & Engineering
- Inside Databox
- Terms of Service
- Privacy Policy
- Talent Resources
- We're Hiring!
- Help Center
- API Documentation
A Step-by-Step Guide to the Data Analysis Process
Like any scientific discipline, data analysis follows a rigorous step-by-step process. Each stage requires different skills and know-how. To get meaningful insights, though, it’s important to understand the process as a whole. An underlying framework is invaluable for producing results that stand up to scrutiny.
In this post, we’ll explore the main steps in the data analysis process. This will cover how to define your goal, collect data, and carry out an analysis. Where applicable, we’ll also use examples and highlight a few tools to make the journey easier. When you’re done, you’ll have a much better understanding of the basics. This will help you tweak the process to fit your own needs.
Here are the steps we’ll take you through:
- Defining the question
- Collecting the data
- Cleaning the data
- Analyzing the data
- Sharing your results
- Embracing failure
On popular request, we’ve also developed a video based on this article. Scroll further along this article to watch that.
Ready? Let’s get started with step one.
1. Step one: Defining the question
The first step in any data analysis process is to define your objective. In data analytics jargon, this is sometimes called the ‘problem statement’.
Defining your objective means coming up with a hypothesis and figuring how to test it. Start by asking: What business problem am I trying to solve? While this might sound straightforward, it can be trickier than it seems. For instance, your organization’s senior management might pose an issue, such as: “Why are we losing customers?” It’s possible, though, that this doesn’t get to the core of the problem. A data analyst’s job is to understand the business and its goals in enough depth that they can frame the problem the right way.
Let’s say you work for a fictional company called TopNotch Learning. TopNotch creates custom training software for its clients. While it is excellent at securing new clients, it has much lower repeat business. As such, your question might not be, “Why are we losing customers?” but, “Which factors are negatively impacting the customer experience?” or better yet: “How can we boost customer retention while minimizing costs?”
Now you’ve defined a problem, you need to determine which sources of data will best help you solve it. This is where your business acumen comes in again. For instance, perhaps you’ve noticed that the sales process for new clients is very slick, but that the production team is inefficient. Knowing this, you could hypothesize that the sales process wins lots of new clients, but the subsequent customer experience is lacking. Could this be why customers don’t come back? Which sources of data will help you answer this question?
Tools to help define your objective
Defining your objective is mostly about soft skills, business knowledge, and lateral thinking. But you’ll also need to keep track of business metrics and key performance indicators (KPIs). Monthly reports can allow you to track problem points in the business. Some KPI dashboards come with a fee, like Databox and DashThis . However, you’ll also find open-source software like Grafana , Freeboard , and Dashbuilder . These are great for producing simple dashboards, both at the beginning and the end of the data analysis process.
2. Step two: Collecting the data
Once you’ve established your objective, you’ll need to create a strategy for collecting and aggregating the appropriate data. A key part of this is determining which data you need. This might be quantitative (numeric) data, e.g. sales figures, or qualitative (descriptive) data, such as customer reviews. All data fit into one of three categories: first-party, second-party, and third-party data. Let’s explore each one.
What is first-party data?
First-party data are data that you, or your company, have directly collected from customers. It might come in the form of transactional tracking data or information from your company’s customer relationship management (CRM) system. Whatever its source, first-party data is usually structured and organized in a clear, defined way. Other sources of first-party data might include customer satisfaction surveys, focus groups, interviews, or direct observation.
What is second-party data?
To enrich your analysis, you might want to secure a secondary data source. Second-party data is the first-party data of other organizations. This might be available directly from the company or through a private marketplace. The main benefit of second-party data is that they are usually structured, and although they will be less relevant than first-party data, they also tend to be quite reliable. Examples of second-party data include website, app or social media activity, like online purchase histories, or shipping data.
What is third-party data?
Third-party data is data that has been collected and aggregated from numerous sources by a third-party organization. Often (though not always) third-party data contains a vast amount of unstructured data points (big data). Many organizations collect big data to create industry reports or to conduct market research. The research and advisory firm Gartner is a good real-world example of an organization that collects big data and sells it on to other companies. Open data repositories and government portals are also sources of third-party data .
Tools to help you collect data
Once you’ve devised a data strategy (i.e. you’ve identified which data you need, and how best to go about collecting them) there are many tools you can use to help you. One thing you’ll need, regardless of industry or area of expertise, is a data management platform (DMP). A DMP is a piece of software that allows you to identify and aggregate data from numerous sources, before manipulating them, segmenting them, and so on. There are many DMPs available. Some well-known enterprise DMPs include Salesforce DMP , SAS , and the data integration platform, Xplenty . If you want to play around, you can also try some open-source platforms like Pimcore or D:Swarm .
Want to learn more about what data analytics is and the process a data analyst follows? We cover this topic (and more) in our free introductory short course for beginners. Check out tutorial one: An introduction to data analytics .
3. Step three: Cleaning the data
Once you’ve collected your data, the next step is to get it ready for analysis. This means cleaning, or ‘scrubbing’ it, and is crucial in making sure that you’re working with high-quality data . Key data cleaning tasks include:
- Removing major errors, duplicates, and outliers —all of which are inevitable problems when aggregating data from numerous sources.
- Removing unwanted data points —extracting irrelevant observations that have no bearing on your intended analysis.
- Bringing structure to your data —general ‘housekeeping’, i.e. fixing typos or layout issues, which will help you map and manipulate your data more easily.
- Filling in major gaps —as you’re tidying up, you might notice that important data are missing. Once you’ve identified gaps, you can go about filling them.
A good data analyst will spend around 70-90% of their time cleaning their data. This might sound excessive. But focusing on the wrong data points (or analyzing erroneous data) will severely impact your results. It might even send you back to square one…so don’t rush it! You’ll find a step-by-step guide to data cleaning here . You may be interested in this introductory tutorial to data cleaning, hosted by Dr. Humera Noor Minhas.
Carrying out an exploratory analysis
Another thing many data analysts do (alongside cleaning data) is to carry out an exploratory analysis. This helps identify initial trends and characteristics, and can even refine your hypothesis. Let’s use our fictional learning company as an example again. Carrying out an exploratory analysis, perhaps you notice a correlation between how much TopNotch Learning’s clients pay and how quickly they move on to new suppliers. This might suggest that a low-quality customer experience (the assumption in your initial hypothesis) is actually less of an issue than cost. You might, therefore, take this into account.
Tools to help you clean your data
Cleaning datasets manually—especially large ones—can be daunting. Luckily, there are many tools available to streamline the process. Open-source tools, such as OpenRefine , are excellent for basic data cleaning, as well as high-level exploration. However, free tools offer limited functionality for very large datasets. Python libraries (e.g. Pandas) and some R packages are better suited for heavy data scrubbing. You will, of course, need to be familiar with the languages. Alternatively, enterprise tools are also available. For example, Data Ladder , which is one of the highest-rated data-matching tools in the industry. There are many more. Why not see which free data cleaning tools you can find to play around with?
4. Step four: Analyzing the data
Finally, you’ve cleaned your data. Now comes the fun bit—analyzing it! The type of data analysis you carry out largely depends on what your goal is. But there are many techniques available. Univariate or bivariate analysis, time-series analysis, and regression analysis are just a few you might have heard of. More important than the different types, though, is how you apply them. This depends on what insights you’re hoping to gain. Broadly speaking, all types of data analysis fit into one of the following four categories.
Descriptive analysis
Descriptive analysis identifies what has already happened . It is a common first step that companies carry out before proceeding with deeper explorations. As an example, let’s refer back to our fictional learning provider once more. TopNotch Learning might use descriptive analytics to analyze course completion rates for their customers. Or they might identify how many users access their products during a particular period. Perhaps they’ll use it to measure sales figures over the last five years. While the company might not draw firm conclusions from any of these insights, summarizing and describing the data will help them to determine how to proceed.
Learn more: What is descriptive analytics?
Diagnostic analysis
Diagnostic analytics focuses on understanding why something has happened . It is literally the diagnosis of a problem, just as a doctor uses a patient’s symptoms to diagnose a disease. Remember TopNotch Learning’s business problem? ‘Which factors are negatively impacting the customer experience?’ A diagnostic analysis would help answer this. For instance, it could help the company draw correlations between the issue (struggling to gain repeat business) and factors that might be causing it (e.g. project costs, speed of delivery, customer sector, etc.) Let’s imagine that, using diagnostic analytics, TopNotch realizes its clients in the retail sector are departing at a faster rate than other clients. This might suggest that they’re losing customers because they lack expertise in this sector. And that’s a useful insight!
Predictive analysis
Predictive analysis allows you to identify future trends based on historical data . In business, predictive analysis is commonly used to forecast future growth, for example. But it doesn’t stop there. Predictive analysis has grown increasingly sophisticated in recent years. The speedy evolution of machine learning allows organizations to make surprisingly accurate forecasts. Take the insurance industry. Insurance providers commonly use past data to predict which customer groups are more likely to get into accidents. As a result, they’ll hike up customer insurance premiums for those groups. Likewise, the retail industry often uses transaction data to predict where future trends lie, or to determine seasonal buying habits to inform their strategies. These are just a few simple examples, but the untapped potential of predictive analysis is pretty compelling.
Prescriptive analysis
Prescriptive analysis allows you to make recommendations for the future. This is the final step in the analytics part of the process. It’s also the most complex. This is because it incorporates aspects of all the other analyses we’ve described. A great example of prescriptive analytics is the algorithms that guide Google’s self-driving cars. Every second, these algorithms make countless decisions based on past and present data, ensuring a smooth, safe ride. Prescriptive analytics also helps companies decide on new products or areas of business to invest in.
Learn more: What are the different types of data analysis?
5. Step five: Sharing your results
You’ve finished carrying out your analyses. You have your insights. The final step of the data analytics process is to share these insights with the wider world (or at least with your organization’s stakeholders!) This is more complex than simply sharing the raw results of your work—it involves interpreting the outcomes, and presenting them in a manner that’s digestible for all types of audiences. Since you’ll often present information to decision-makers, it’s very important that the insights you present are 100% clear and unambiguous. For this reason, data analysts commonly use reports, dashboards, and interactive visualizations to support their findings.
How you interpret and present results will often influence the direction of a business. Depending on what you share, your organization might decide to restructure, to launch a high-risk product, or even to close an entire division. That’s why it’s very important to provide all the evidence that you’ve gathered, and not to cherry-pick data. Ensuring that you cover everything in a clear, concise way will prove that your conclusions are scientifically sound and based on the facts. On the flip side, it’s important to highlight any gaps in the data or to flag any insights that might be open to interpretation. Honest communication is the most important part of the process. It will help the business, while also helping you to excel at your job!
Tools for interpreting and sharing your findings
There are tons of data visualization tools available, suited to different experience levels. Popular tools requiring little or no coding skills include Google Charts , Tableau , Datawrapper , and Infogram . If you’re familiar with Python and R, there are also many data visualization libraries and packages available. For instance, check out the Python libraries Plotly , Seaborn , and Matplotlib . Whichever data visualization tools you use, make sure you polish up your presentation skills, too. Remember: Visualization is great, but communication is key!
You can learn more about storytelling with data in this free, hands-on tutorial . We show you how to craft a compelling narrative for a real dataset, resulting in a presentation to share with key stakeholders. This is an excellent insight into what it’s really like to work as a data analyst!
6. Step six: Embrace your failures
The last ‘step’ in the data analytics process is to embrace your failures. The path we’ve described above is more of an iterative process than a one-way street. Data analytics is inherently messy, and the process you follow will be different for every project. For instance, while cleaning data, you might spot patterns that spark a whole new set of questions. This could send you back to step one (to redefine your objective). Equally, an exploratory analysis might highlight a set of data points you’d never considered using before. Or maybe you find that the results of your core analyses are misleading or erroneous. This might be caused by mistakes in the data, or human error earlier in the process.
While these pitfalls can feel like failures, don’t be disheartened if they happen. Data analysis is inherently chaotic, and mistakes occur. What’s important is to hone your ability to spot and rectify errors. If data analytics was straightforward, it might be easier, but it certainly wouldn’t be as interesting. Use the steps we’ve outlined as a framework, stay open-minded, and be creative. If you lose your way, you can refer back to the process to keep yourself on track.
In this post, we’ve covered the main steps of the data analytics process. These core steps can be amended, re-ordered and re-used as you deem fit, but they underpin every data analyst’s work:
- Define the question —What business problem are you trying to solve? Frame it as a question to help you focus on finding a clear answer.
- Collect data —Create a strategy for collecting data. Which data sources are most likely to help you solve your business problem?
- Clean the data —Explore, scrub, tidy, de-dupe, and structure your data as needed. Do whatever you have to! But don’t rush…take your time!
- Analyze the data —Carry out various analyses to obtain insights. Focus on the four types of data analysis: descriptive, diagnostic, predictive, and prescriptive.
- Share your results —How best can you share your insights and recommendations? A combination of visualization tools and communication is key.
- Embrace your mistakes —Mistakes happen. Learn from them. This is what transforms a good data analyst into a great one.
What next? From here, we strongly encourage you to explore the topic on your own. Get creative with the steps in the data analysis process, and see what tools you can find. As long as you stick to the core principles we’ve described, you can create a tailored technique that works for you.
To learn more, check out our free, 5-day data analytics short course . You might also be interested in the following:
- These are the top 9 data analytics tools
- 10 great places to find free datasets for your next project
- How to build a data analytics portfolio
Data analysis write-ups
What should a data-analysis write-up look like.
Writing up the results of a data analysis is not a skill that anyone is born with. It requires practice and, at least in the beginning, a bit of guidance.
Organization
When writing your report, organization will set you free. A good outline is: 1) overview of the problem, 2) your data and modeling approach, 3) the results of your data analysis (plots, numbers, etc), and 4) your substantive conclusions.
1) Overview Describe the problem. What substantive question are you trying to address? This needn’t be long, but it should be clear.
2) Data and model What data did you use to address the question, and how did you do it? When describing your approach, be specific. For example:
- Don’t say, “I ran a regression” when you instead can say, “I fit a linear regression model to predict price that included a house’s size and neighborhood as predictors.”
- Justify important features of your modeling approach. For example: “Neighborhood was included as a categorical predictor in the model because Figure 2 indicated clear differences in price across the neighborhoods.”
Sometimes your Data and Model section will contain plots or tables, and sometimes it won’t. If you feel that a plot helps the reader understand the problem or data set itself—as opposed to your results—then go ahead and include it. A great example here is Tables 1 and 2 in the main paper on the PREDIMED study . These tables help the reader understand some important properties of the data and approach, but not the results of the study itself.
3) Results In your results section, include any figures and tables necessary to make your case. Label them (Figure 1, 2, etc), give them informative captions, and refer to them in the text by their numbered labels where you discuss them. Typical things to include here may include: pictures of the data; pictures and tables that show the fitted model; tables of model coefficients and summaries.
4) Conclusion What did you learn from the analysis? What is the answer, if any, to the question you set out to address?
General advice
Make the sections as short or long as they need to be. For example, a conclusions section is often pretty short, while a results section is usually a bit longer.
It’s OK to use the first person to avoid awkward or bizarre sentence constructions, but try to do so sparingly.
Do not include computer code unless explicitly called for. Note: model outputs do not count as computer code. Outputs should be used as evidence in your results section (ideally formatted in a nice way). By code, I mean the sequence of commands you used to process the data and produce the outputs.
When in doubt, use shorter words and sentences.
A very common way for reports to go wrong is when the writer simply narrates the thought process he or she followed: :First I did this, but it didn’t work. Then I did something else, and I found A, B, and C. I wasn’t really sure what to make of B, but C was interesting, so I followed up with D and E. Then having done this…” Do not do this. The desire for specificity is admirable, but the overall effect is one of amateurism. Follow the recommended outline above.
Here’s a good example of a write-up for an analysis of a few relatively simple problems. Because the problems are so straightforward, there’s not much of a need for an outline of the kind described above. Nonetheless, the spirit of these guidelines is clearly in evidence. Notice the clear exposition, the labeled figures and tables that are referred to in the text, and the careful integration of visual and numerical evidence into the overall argument. This is one worth emulating.
The Community
Modern analyst blog, community blog.
- Member Profiles
Networking Opportunities
Community spotlight, business analysis glossary, articles listing, business analyst humor, self assessment.
- Training Courses
- Organizations
- Resume Writing Tips
- Interview Questions
Let Us Help Your Business
Advertise with us, rss feeds & syndication, privacy policy.

Writing a Good Data Analysis Report: 7 Steps
As a data analyst, you feel most comfortable when you’re alone with all the numbers and data. You’re able to analyze them with confidence and reach the results you were asked to find. But, this is not the end of the road for you. You still need to write a data analysis report explaining your findings to the laymen - your clients or coworkers.
That means you need to think about your target audience, that is the people who’ll be reading your report.
They don’t have nearly as much knowledge about data analysis as you do. So, your report needs to be straightforward and informative. The article below will help you learn how to do it. Let’s take a look at some practical tips you can apply to your data analysis report writing and the benefits of doing so.

source: Pexels
Data Analysis Report Writing: 7 Steps
The process of writing a data analysis report is far from simple, but you can master it quickly, with the right guidance and examples of similar reports .
This is why we've prepared a step-by-step guide that will cover everything you need to know about this process, as simply as possible. Let’s get to it.
Consider Your Audience
You are writing your report for a certain target audience, and you need to keep them in mind while writing. Depending on their level of expertise, you’ll need to adjust your report and ensure it speaks to them. So, before you go any further, ask yourself:
Who will be reading this report? How well do they understand the subject?
Let’s say you’re explaining the methodology you used to reach your conclusions and find the data in question. If the reader isn’t familiar with these tools and software, you’ll have to simplify it for them and provide additional explanations.
So, you won't be writing the same type of report for a coworker who's been on your team for years or a client who's seeing data analysis for the first time. Based on this determining factor, you'll think about:
the language and vocabulary you’re using
abbreviations and level of technicality
the depth you’ll go into to explain something
the type of visuals you’ll add
Your readers’ expertise dictates the tone of your report and you need to consider it before writing even a single word.
Draft Out the Sections
The next thing you need to do is create a draft of your data analysis report. This is just a skeleton of what your report will be once you finish. But, you need a starting point.
So, think about the sections you'll include and what each section is going to cover. Typically, your report should be divided into the following sections:
Introduction
Body (Data, Methods, Analysis, Results)
For each section, write down several short bullet points regarding the content to cover. Below, we'll discuss each section more elaborately.
Develop The Body
The body of your report is the most important section. You need to organize it into subsections and present all the information your readers will be interested in.
We suggest the following subsections.
Explain what data you used to conduct your analysis. Be specific and explain how you gathered the data, what your sample was, what tools and resources you’ve used, and how you’ve organized your data. This will give the reader a deeper understanding of your data sample and make your report more solid.
Also, explain why you choose the specific data for your sample. For instance, you may say “ The sample only includes data of the customers acquired during 2021, in the peak of the pandemic.”
Next, you need to explain what methods you’ve used to analyze the data. This simply means you need to explain why and how you choose specific methods. You also need to explain why these methods are the best fit for the goals you’ve set and the results you’re trying to reach.
Back up your methodology section with background information on each method or tool used. Explain how these resources are typically used in data analysis.
After you've explained the data and methods you've used, this next section brings those two together. The analysis section shows how you've analyzed the specific data using the specific methods.
This means you’ll show your calculations, charts, and analyses, step by step. Add descriptions and explain each of the steps. Try making it as simple as possible so that even the most inexperienced of your readers understand every word.
This final section of the body can be considered the most important section of your report. Most of your clients will skim the rest of the report to reach this section.
Because it’ll answer the questions you’ve all raised. It shares the results that were reached and gives the reader new findings, facts, and evidence.
So, explain and describe the results using numbers. Then, add a written description of what each of the numbers stands for and what it means for the entire analysis. Summarize your results and finalize the report on a strong note.
Write the Introduction
Yes, it may seem strange to write the introduction section at the end, but it’s the smartest way to do it. This section briefly explains what the report will cover. That’s why you should write it after you’ve finished writing the Body.
In your introduction, explain:
the question you’ve raised and answered with the analysis
context of the analysis and background information
short outline of the report
Simply put, you’re telling your audience what to expect.
Add a Short Conclusion
Finally, the last section of your paper is a brief conclusion. It only repeats what you described in the Body, but only points out the most important details.
It should be less than a page long and use straightforward language to deliver the most important findings. It should also include a paragraph about the implications and importance of those findings for the client, customer, business, or company that hired you.
Include Data Visualization Elements
You have all the data and numbers in your mind and find it easy to understand what the data is saying. But, to a layman or someone less experienced than yourself, it can be quite a puzzle. All the information that your data analysis has found can create a mess in the head of your reader.
So, you should simplify it by using data visualization elements.
Firstly, let’s define what are the most common and useful data visualization elements you can use in your report:
There are subcategories to each of the elements and you should explore them all to decide what will do the best job for your specific case. For instance, you'll find different types of charts including, pie charts, bar charts, area charts, or spider charts.
For each data visualization element, add a brief description to tell the readers what information it contains. You can also add a title to each element and create a table of contents for visual elements only.
Proofread & Edit Before Submission
All the hard work you’ve invested in writing a good data analysis report might go to waste if you don’t edit and proofread. Proofreading and editing will help you eliminate potential mistakes, but also take another objective look at your report.
First, do the editing part. It includes:
reading the whole report objectively, like you’re seeing it for the first time
leaving an open mind for changes
adding or removing information
rearranging sections
finding better words to say something
You should repeat the editing phase a couple of times until you're completely happy with the result. Once you're certain the content is all tidied up, you can move on to the proofreading stage. It includes:
finding and removing grammar and spelling mistakes
rethinking vocabulary choices
improving clarity
improving readability
You can use an online proofreading tool to make things faster. If you really want professional help, Grab My Essay is a great choice. Their professional writers can edit and rewrite your entire report, to make sure it’s impeccable before submission.
Whatever you choose to do, proofread yourself or get some help with it, make sure your report is well-organized and completely error-free.
Benefits of Writing Well-Structured Data Analysis Reports
Yes, writing a good data analysis report is a lot of hard work. But, if you understand the benefits of writing it, you’ll be more motivated and willing to invest the time and effort. After knowing how it can help you in different segments of your professional journey, you’ll be more willing to learn how to do it.
Below are the main benefits a data analysis report brings to the table.
Improved Collaboration
When you’re writing a data analysis report, you need to be aware more than one end user is going to use it. Whether it’s your employer, customer, or coworker - you need to make sure they’re all on the same page. And when you write a data analysis report that is easy to understand and learn from, you’re creating a bridge between all these people.
Simply, all of them are given accurate data they can rely on and you’re thus removing the potential misunderstandings that can happen in communication. This improves the overall collaboration level and makes everyone more open and helpful.
Increased Efficiency
People who are reading your data analysis report need the information it contains for some reason. They might use it to do their part of the job, to make decisions, or report further to someone else. Either way, the better your report, the more efficient it'll be. And, if you rely on those people as well, you'll benefit from this increased productivity as well.
Data tells a story about a business, project, or venture. It's able to show how well you've performed, what turned out to be a great move, and what needs to be reimagined. This means that a data analysis report provides valuable insight and measurable KPIs (key performance indicators) that you’re able to use to grow and develop.
Clear Communication
Information is key regardless of the industry you're in or the type of business you're doing. Data analysis finds that information and proves its accuracy and importance. But, if those findings and the information itself aren't communicated clearly, it's like you haven't even found them.
This is why a data analysis report is crucial. It will present the information less technically and bring it closer to the readers.
Final Thoughts
As you can see, it takes some skill and a bit more practice to write a good data analysis report. But, all the effort you invest in writing it will be worth it once the results kick in. You’ll improve the communication between you and your clients, employers, or coworkers. People will be able to understand, rely on, and use the analysis you’ve conducted.
So, don’t be afraid and start writing your first data analysis report. Just follow the 7 steps we’ve listed and use a tool such as ProWebScraper to help you with website data analysis. You’ll be surprised when you see the result of your hard work.

Jessica Fender is a business analyst and a blogger. She writes about business and data analysis, networking in this sector, and acquiring new skills. Her goal is to provide fresh and accurate information that readers can apply instantly.
Related Articles

Article/Paper Categories
Upcoming live webinars, ace the interview.
Roles and Titles
- Business Analyst
- Business Process Analyst
- IT Business Analyst
- Requirements Engineer
- Business Systems Analyst
- Systems Analyst
- Data Analyst
Career Resources
- Interview Tips
- Salary Information
- Directory of Links
Community Resources
- Project Members
Advertising Opportunities | Contact Us | Privacy Policy
- Online Degree Explore Bachelor’s & Master’s degrees
- MasterTrack™ Earn credit towards a Master’s degree
- University Certificates Advance your career with graduate-level learning
- Top Courses
- Join for Free
What Is Data Analysis? (With Examples)
Data analysis is the practice of working with data to glean useful information, which can then be used to make informed decisions.
![[Featured image] A female data analyst takes notes on her laptop at a standing desk in a modern office space](https://d3njjcbhbojbot.cloudfront.net/api/utilities/v1/imageproxy/https://images.ctfassets.net/wp1lcwdav1p1/2CUbULaq9mEfSSIq6lsCUu/b8ec58abf5106bf9bf75b17da09c39c0/What_is_data_analysis.png?w=1500&h=680&q=60&fit=fill&f=faces&fm=jpg&fl=progressive&auto=format%2Ccompress&dpr=1&w=1000 "how to write an analysis of data")
"It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts," Sherlock Holme's proclaims in Sir Arthur Conan Doyle's A Scandal in Bohemia.
This idea lies at the root of data analysis. When we can extract meaning from data, it empowers us to make better decisions. And we’re living in a time when we have more data than ever at our fingertips.
Companies are wisening up to the benefits of leveraging data. Data analysis can help a bank to personalize customer interactions, a health care system to predict future health needs, or an entertainment company to create the next big streaming hit.
The World Economic Forum Future of Jobs Report 2020 listed data analysts and scientists as the top emerging job, followed immediately by AI and machine learning specialists, and big data specialists [ 1 ]. In this article, you'll learn more about the data analysis process, different types of data analysis, and recommended courses to help you get started in this exciting field.
Read more: How to Become a Data Analyst (with or Without a Degree)
Data analysis process
As the data available to companies continues to grow both in amount and complexity, so too does the need for an effective and efficient process by which to harness the value of that data. The data analysis process typically moves through several iterative phases. Let’s take a closer look at each.
Identify the business question you’d like to answer. What problem is the company trying to solve? What do you need to measure, and how will you measure it?
Collect the raw data sets you’ll need to help you answer the identified question. Data collection might come from internal sources, like a company’s client relationship management (CRM) software, or from secondary sources, like government records or social media application programming interfaces (APIs).
Clean the data to prepare it for analysis. This often involves purging duplicate and anomalous data, reconciling inconsistencies, standardizing data structure and format, and dealing with white spaces and other syntax errors.
Analyze the data. By manipulating the data using various data analysis techniques and tools, you can begin to find trends, correlations, outliers, and variations that tell a story. During this stage, you might use data mining to discover patterns within databases or data visualization software to help transform data into an easy-to-understand graphical format.
Interpret the results of your analysis to see how well the data answered your original question. What recommendations can you make based on the data? What are the limitations to your conclusions?
Watch this video to hear what data analysis how Kevin, Director of Data Analytics at Google, defines data analysis.
Read more: What Does a Data Analyst Do? A Career Guide
Types of data analysis (with examples)
Data can be used to answer questions and support decisions in many different ways. To identify the best way to analyze your date, it can help to familiarize yourself with the four types of data analysis commonly used in the field.
In this section, we’ll take a look at each of these data analysis methods, along with an example of how each might be applied in the real world.
Descriptive analysis
Descriptive analysis tells us what happened. This type of analysis helps describe or summarize quantitative data by presenting statistics. For example, descriptive statistical analysis could show the distribution of sales across a group of employees and the average sales figure per employee.
Descriptive analysis answers the question, “what happened?”
Diagnostic analysis
If the descriptive analysis determines the “what,” diagnostic analysis determines the “why.” Let’s say a descriptive analysis shows an unusual influx of patients in a hospital. Drilling into the data further might reveal that many of these patients shared symptoms of a particular virus. This diagnostic analysis can help you determine that an infectious agent—the “why”—led to the influx of patients.
Diagnostic analysis answers the question, “why did it happen?”
Predictive analysis
So far, we’ve looked at types of analysis that examine and draw conclusions about the past. Predictive analytics uses data to form projections about the future. Using predictive analysis, you might notice that a given product has had its best sales during the months of September and October each year, leading you to predict a similar high point during the upcoming year.
Predictive analysis answers the question, “what might happen in the future?”
Prescriptive analysis
Prescriptive analysis takes all the insights gathered from the first three types of analysis and uses them to form recommendations for how a company should act. Using our previous example, this type of analysis might suggest a market plan to build on the success of the high sales months and harness new growth opportunities in the slower months.
Prescriptive analysis answers the question, “what should we do about it?”
This last type is where the concept of data-driven decision-making comes into play.
Read more : Advanced Analytics: Definition, Benefits, and Use Cases
What is data-driven decision-making (DDDM)?
Data-driven decision-making, sometimes abbreviated to DDDM), can be defined as the process of making strategic business decisions based on facts, data, and metrics instead of intuition, emotion, or observation.
This might sound obvious, but in practice, not all organizations are as data-driven as they could be. According to global management consulting firm McKinsey Global Institute, data-driven companies are better at acquiring new customers, maintaining customer loyalty, and achieving above-average profitability [ 2 ].
Get started with Coursera
If you’re interested in a career in the high-growth field of data analytics, consider these top-rated courses on Coursera:
Begin building job-ready skills with the Google Data Analytics Professional Certificate . Prepare for an entry-level job as you learn from Google employees—no experience or degree required.
Practice working with data with Macquarie University's Excel Skills for Business Specialization . Learn how to use Microsoft Excel to analyze data and make data-informed business decisions.
Deepen your skill set with Google's Advanced Data Analytics Professional Certificate . In this advanced program, you'll continue exploring the concepts introduced in the beginner-level courses, plus learn Python, statistics, and Machine Learning concepts.
Frequently asked questions (FAQ)
Where is data analytics used .
Just about any business or organization can use data analytics to help inform their decisions and boost their performance. Some of the most successful companies across a range of industries — from Amazon and Netflix to Starbucks and General Electric — integrate data into their business plans to improve their overall business performance.
What are the top skills for a data analyst?
Data analysis makes use of a range of analysis tools and technologies. Some of the top skills for data analysts include SQL, data visualization, statistical programming languages (like R and Python), machine learning, and spreadsheets.
Read : 7 In-Demand Data Analyst Skills to Get Hired in 2022
What is a data analyst job salary?
Data from Glassdoor indicates that the average base salary for a data analyst in the United States is $75,349 as of March 2024 [ 3 ]. How much you make will depend on factors like your qualifications, experience, and location.
Do data analysts need to be good at math?
Data analytics tends to be less math-intensive than data science. While you probably won’t need to master any advanced mathematics, a foundation in basic math and statistical analysis can help set you up for success.
Learn more: Data Analyst vs. Data Scientist: What’s the Difference?
Article sources
World Economic Forum. " The Future of Jobs Report 2020 , https://www.weforum.org/reports/the-future-of-jobs-report-2020." Accessed November 20, 2023.
McKinsey & Company. " Five facts: How customer analytics boosts corporate performance , https://www.mckinsey.com/business-functions/marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance." Accessed November 20, 2023.
Glassdoor. " Data Analyst Salaries , https://www.glassdoor.com/Salaries/data-analyst-salary-SRCH_KO0,12.htm" Accessed November 20, 2023.
Keep reading
Coursera staff.
Editorial Team
Coursera’s editorial team is comprised of highly experienced professional editors, writers, and fact...
This content has been made available for informational purposes only. Learners are advised to conduct additional research to ensure that courses and other credentials pursued meet their personal, professional, and financial goals.
Learn / Guides / Data analysis for marketers
Back to guides
How to build a marketing data analysis report (template and examples)
Creating a data analysis report is an underrated yet critical skill for marketers. A marketing report can impact team, stakeholder, and company decisions, so highlighting (and omitting) the right information is crucial.
But how do you consistently churn out clear and compelling reports? This guide will help you tie your reports up in a neat little bow, ensuring alignment with and buy-in from your audience—and beneficial decisions for your end-users.
Last updated
Reading time.

Data analysis reporting is a process that combines quantitative and qualitative data to evaluate performance, share findings, and inform future decisions. One common example is reporting on the results of a marketing campaign, but there are plenty more reasons marketers might create a data analysis report.
More examples—plus the reporting steps, tools, and template—await below, so keep reading.
Get started fast with our free monthly data analysis report template , and follow these six key steps to creating a persuasive report:
Nail down the elements : provide a title, timeframe, and summary. Present data visually and close with action points.
Determine your purpose : figure out why you're making this report so you can focus on the right information
Identify your audience and their needs : define your readers and tailor your report to their requirements
Put your key insights first : maximize Hotjar, a multi-product data analytics platform, to track metrics and gather meaningful insights
Visualize your data : incorporate charts, heatmaps, and other visuals to convey facts and insights effectively
Ask your audience for feedback : collect your audience's feedback to continuously improve your reporting approach
How to write a data analysis report in 6 easy steps
Knowing how to write a data analysis report is vital—especially in a data-informed field like marketing. Organizing and visualizing your data helps you
Evaluate strategies and performance
Inform future decisions and actions
Share findings and recommendations to serve users better
However, even marketers dealing with data regularly may find the task time-consuming. But we can promise you one thing: it won’t feel that way once you have a repeatable process and fewer data analysis and visualization tools to work with.
1. Nail down the elements
This chapter of our data analysis guide focuses on creating an executive report. But regardless of the type of report (we'll touch on a few more of them later), most share the same building blocks:
Title: use a straightforward title to convey your report's intent. Call it as it is, whether it's your overall marketing performance or a multi-channel marketing campaign.
Timeframe: reporting intervals include daily, weekly, monthly, quarterly, and annually. Monthly data analysis reports work best for marketing teams, clients, and executives.
TL;DR: summarize your key objectives and findings, such as insights, issues, and recommendations, in an executive summary. This sets your audience's expectations and helps busy team members focus on what matters to them.
Body: your bar charts, graphs, tables, and heatmaps go here. Add visual evidence from your analysis that supports your conclusion to win buy-in from decision-makers.
Conclusion: backed by the data in the body, state your plan for making progress with your goals. For instance, say you need additional dollars to spend on social media advertising since it's shown a consistent return on investment (ROI).
Discover actionable data, enhance business decisions
Craft compelling marketing reports fast. Collect, analyze, and report on crucial insights using Hotjar’s multi-product platform to get stakeholder buy-in and team alignment.
2. Determine your purpose
What data should you incorporate in your report? The answer lies in the purpose of your data analysis report.
Consider this: what do you hope to achieve when you share the results of your analysis? Is it to show stakeholders how customers use your products so you can improve them? Or is it to enlighten your team about what customers like so you can tailor campaigns to each segment?
Pulling the relevant data becomes a breeze once you’ve locked in your report’s primary purpose.
Collect meaningful data in real time with Hotjar
Marketers conduct quantitative data analysis to answer questions like, “How many?” or “How often?” In other words: this type of analysis involves numerical data, such as traffic and conversions.
But numbers alone don't provide the whole picture—you need to uncover the why behind them. Why did traffic from France increase yesterday? Why do certain customers rage-click on a call-to-action (CTA) button on your Demo page?
It's qualitative data that reveals the reasons customers behave a certain way. This non-numerical data includes behavioral observations, interview clips, and survey responses.
In Hotjar, an analytics platform for user behavior and digital experience insights, you can gather qualitative data via Surveys , Feedback, and Interviews , plus visualize quantitative data via Heatmaps and capture user behavior in real-time with Recordings, all from a single platform.
Here, it's easier than ever to collect and analyze quantitative and qualitative data, and build a user-centric marketing report based on your analysis.
Complement quantitative data with qualitative insights
3. Identify your audience
Always determine two audience types for your report: primary and secondary.
Company executives, clients (for marketing agencies), team members, and cross-functional collaborators, such as product managers, can fit into either category, depending on your report. Once you've categorized your primary and secondary audiences, it's easier to customize the report to their needs. Here are a few tips on how to do it:
Speak their language: in any business setting, this means striking a balance between not too formal and not too casual—think business in the front, party in the back
Discuss results, not methodologies: immediately dive into the insights gleaned from your quantitative and qualitative data analysis
Present key takeaways in the summary: as we said earlier, highlight your main points at the top of your report so the reader can instantly note what they think is interesting
Place eye-catching visuals in the body: your audience may skim through and search only for additional details in the body, so ensure your data visualization is easy to interpret
📋 Need a hand? Try using a template
If you’re unsure how to design your report or prefer not to build from scratch each time you run it, use a data analysis report template. Ensure it’s a well-crafted one aimed at showing—instead of telling—your audience what works and what doesn’t.
Aside from making you look good (😎), an excellent template saves you time, and gives your readers something to rely on during each reporting period.
So, what would an extremely occupied marketer do? Streamline the creation process, of course! Plug, play, and present your insights with our free monthly data analysis report template to get started 📈.

Click the link above to make a copy of our handy template
4. Prioritize key insights
Here comes the exciting part: assembling the data to draw a clear picture for your audience. Before you discovered this guide, you might have gathered data manually from various sources, such as Google Analytics, your preferred A/B testing platform, and even Hotjar.
Luckily for you, there's a faster way to track and spot patterns occurring in your custom metrics. Hotjar Trends enables you to find the behavioral data you need, such as visitors who viewed any of the two landing page variations you were A/B testing, or users who rage clicked (a sign of frustration) before exiting your checkout page.
Compare your A/B test participants or new and returning users to see if one segment encountered any issues. Or view your rage clicks over time to understand what makes users frustrated. Then, click the ‘play’ icon to dive straight into your session recordings and discover the reason behind their actions.
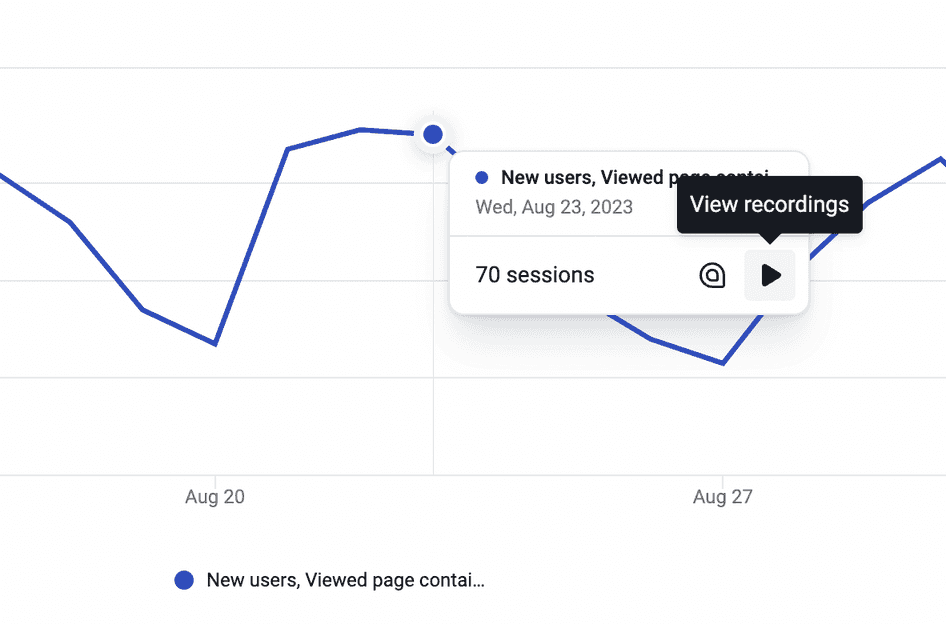
Go from quantitative to qualitative data in a single click with Hotjar Trends
Finally, screencap the charts in Trends and link to some relevant recordings in your trend report .
A sample trend report showing rage clicks over time, created via Hotjar Trends
What else can you do within Hotjar? Use Highlights and Collections to group snippets of recordings and heatmaps to support your conclusion. Add these meaningful insights to your monthly report or share them with teammates on an ordinary day, without having to switch between multiple analytics tools.
Trends, Highlights, Recordings…will my audience remember all these names?
They may even start looking for them in every report from now on. Our tools and features are self-explanatory, so everyone, from the marketing and sales teams to clients and C-suite execs, can quickly understand them.
Personally I love using Highlights and Collections together. I see each highlight as a self-contained explanation for the case I’m making to the product team. I’ve got the video. I’ve got the tags if I need them. I’ll add comments and a thread for a response.
There’s no risk of distraction and minimal lift to get my stakeholders directly to the central issue.
And then the Collections view basically creates a visual report of all the evidence I have for a given case. Here's how much this hurts (one Highlight); click on the rest of these if you can stomach it (a Collection of Highlights).
5. Incorporate visual data
Whether you're comparing past and present conversion rates or sharing multiple data sets, it's crucial to get your point across quickly. After all, you're not the only team or department vying for your audience's attention. This is where data visualization plays a considerable role: maps and charts allow you to effectively convey your message by making your data interactive, digestible, and enjoyable.
To visualize data, use your spreadsheet of choice (for example, Excel or Google Sheets) or a dedicated platform like Tableau . You can also screenshot your data in the Hotjar Dashboard to save time and effort. Showcase relevant heatmaps, recordings, survey responses, interview snapshots, and direct feedback to drive your point home and get everyone on the same page.
6. Collect feedback from your audience
Just as Surveys and Feedback let you connect with actual customers, they also prove valuable in asking your audience’s thoughts once you’ve sent out your reports. By building a custom survey—for free—in Hotjar, you can include and analyze open-ended questions like, “How did this data analysis report help you?” and “What would you want to see in the next report?”
This enables stakeholders to give you proper feedback, especially if they didn't get the chance to speak after your presentation.
4 examples of data analysis reports
Now, we’re tackling four popular types of data analysis reports. Practice makes permanent, so let’s go over the ones you’ll likely produce regularly (you'll ace them in no time).
Executive report or digital marketing report
This comprehensive report combines vital insights into your marketing efforts across various channels. It tracks metrics like advertising cost, conversion rate, customer acquisition cost, and online revenue.
Remember: you'll send this document out to company executives who want to see how marketing directly contributes to the bottom line. Be sure to connect your efforts to revenue. And what better way to demonstrate your impact than showing heatmaps or recordings of people responding positively to your campaigns?
Search engine optimization (SEO) report
While an executive report may contain an SEO performance overview, this specialized report breaks down organic traffic in detail. Show your keyword rankings, conversion rates, and top traffic channels to explain your strategy to executives and stakeholders.

Note that you can track these essential metrics in Hotjar's Dashboard. Screenshot your customized dashboard or share it live with your audience as you discuss key insights. Pull up a recording or two or highlight customer feedback to strengthen your case.
For example, if session recordings reveal an unclear CTA has caused conversions for several landing pages to decline, you might recommend changing the CTA by running an A/B test and going with the winning variation.
Social media marketing report
This data analysis report example unpacks multiple channels. Which ones are helping you spread brand awareness and enhance customer loyalty? As such, you should track social key performance indicators (KPIs) like new followers, total reach, share of voice (SOV), engagement, and website referrals.
You can access relevant data and insights in your social media pages’ in-app analytics or analytics tools like Buffer and Hootsuite .
Marketing funnel report
Conversion funnels allow you to home in on the few steps users take from first contact to final conversion. Here’s a basic conversion path if you’re marketing an ecommerce brand:
Homepage > category page > product page > cart > checkout > thank you page
Initially, you’ll look at how many people visit your main pages and who they are. Take your data analysis further with Hotjar Funnels , where you can measure conversion and drop-off rates. Add filters like traffic channels and user attributes to compare performance. To deepen your insights, jump into relevant recordings and see what causes users to leave before they convert.
The best part? You can gradually collect data, conduct funnel analysis , and integrate your findings into your report with in Hotjar and with out manually handling data: no hassle, no fuss.

Create data analysis reports that drive action
Ensure your team, stakeholders, and executives make data-informed decisions regarding your marketing campaigns and strategies with compelling data analysis reports.
Needle-moving, user-centric insights deserve the spotlight. Start with our free template and populate it with numerical and non-numerical data from Hotjar and other sources. Go ahead and tell a visual story that inspires action today.
FAQs about data analysis reports
What is a data analysis report.
A data analysis report is a document containing key insights derived from quantitative and qualitative data analysis. Marketers, for instance, use it to share findings and recommendations with teammates, stakeholders, clients, and company executives. This is to ensure everyone is on the same page before deciding on any improvements to marketing strategies and campaigns.
What is an example of a data analysis report?
One example of a data analysis report is the executive report on a company’s digital marketing efforts. It presents evidence backed by data on how different channels create opportunities for a business to serve its customers better and, in return, achieve sustainable growth.
How do you write a data analysis report?
Here’s how to develop your marketing report in seven simple steps:
Nail down the elements
Determine your purpose
Identify your audience and their needs
Enhance your reports using templates
Put your key insights first
Visualize your data
Ask your audience for feedback
Data analysis tools
Previous chapter
Guide index
Your Modern Business Guide To Data Analysis Methods And Techniques

Table of Contents
1) What Is Data Analysis?
2) Why Is Data Analysis Important?
3) What Is The Data Analysis Process?
4) Types Of Data Analysis Methods
5) Top Data Analysis Techniques To Apply
6) Quality Criteria For Data Analysis
7) Data Analysis Limitations & Barriers
8) Data Analysis Skills
9) Data Analysis In The Big Data Environment
In our data-rich age, understanding how to analyze and extract true meaning from our business’s digital insights is one of the primary drivers of success.
Despite the colossal volume of data we create every day, a mere 0.5% is actually analyzed and used for data discovery , improvement, and intelligence. While that may not seem like much, considering the amount of digital information we have at our fingertips, half a percent still accounts for a vast amount of data.
With so much data and so little time, knowing how to collect, curate, organize, and make sense of all of this potentially business-boosting information can be a minefield – but online data analysis is the solution.
In science, data analysis uses a more complex approach with advanced techniques to explore and experiment with data. On the other hand, in a business context, data is used to make data-driven decisions that will enable the company to improve its overall performance. In this post, we will cover the analysis of data from an organizational point of view while still going through the scientific and statistical foundations that are fundamental to understanding the basics of data analysis.
To put all of that into perspective, we will answer a host of important analytical questions, explore analytical methods and techniques, while demonstrating how to perform analysis in the real world with a 17-step blueprint for success.
What Is Data Analysis?
Data analysis is the process of collecting, modeling, and analyzing data using various statistical and logical methods and techniques. Businesses rely on analytics processes and tools to extract insights that support strategic and operational decision-making.
All these various methods are largely based on two core areas: quantitative and qualitative research.
To explain the key differences between qualitative and quantitative research, here’s a video for your viewing pleasure:
Gaining a better understanding of different techniques and methods in quantitative research as well as qualitative insights will give your analyzing efforts a more clearly defined direction, so it’s worth taking the time to allow this particular knowledge to sink in. Additionally, you will be able to create a comprehensive analytical report that will skyrocket your analysis.
Apart from qualitative and quantitative categories, there are also other types of data that you should be aware of before dividing into complex data analysis processes. These categories include:
- Big data: Refers to massive data sets that need to be analyzed using advanced software to reveal patterns and trends. It is considered to be one of the best analytical assets as it provides larger volumes of data at a faster rate.
- Metadata: Putting it simply, metadata is data that provides insights about other data. It summarizes key information about specific data that makes it easier to find and reuse for later purposes.
- Real time data: As its name suggests, real time data is presented as soon as it is acquired. From an organizational perspective, this is the most valuable data as it can help you make important decisions based on the latest developments. Our guide on real time analytics will tell you more about the topic.
- Machine data: This is more complex data that is generated solely by a machine such as phones, computers, or even websites and embedded systems, without previous human interaction.
Why Is Data Analysis Important?
Before we go into detail about the categories of analysis along with its methods and techniques, you must understand the potential that analyzing data can bring to your organization.
- Informed decision-making : From a management perspective, you can benefit from analyzing your data as it helps you make decisions based on facts and not simple intuition. For instance, you can understand where to invest your capital, detect growth opportunities, predict your income, or tackle uncommon situations before they become problems. Through this, you can extract relevant insights from all areas in your organization, and with the help of dashboard software , present the data in a professional and interactive way to different stakeholders.
- Reduce costs : Another great benefit is to reduce costs. With the help of advanced technologies such as predictive analytics, businesses can spot improvement opportunities, trends, and patterns in their data and plan their strategies accordingly. In time, this will help you save money and resources on implementing the wrong strategies. And not just that, by predicting different scenarios such as sales and demand you can also anticipate production and supply.
- Target customers better : Customers are arguably the most crucial element in any business. By using analytics to get a 360° vision of all aspects related to your customers, you can understand which channels they use to communicate with you, their demographics, interests, habits, purchasing behaviors, and more. In the long run, it will drive success to your marketing strategies, allow you to identify new potential customers, and avoid wasting resources on targeting the wrong people or sending the wrong message. You can also track customer satisfaction by analyzing your client’s reviews or your customer service department’s performance.
What Is The Data Analysis Process?

When we talk about analyzing data there is an order to follow in order to extract the needed conclusions. The analysis process consists of 5 key stages. We will cover each of them more in detail later in the post, but to start providing the needed context to understand what is coming next, here is a rundown of the 5 essential steps of data analysis.
- Identify: Before you get your hands dirty with data, you first need to identify why you need it in the first place. The identification is the stage in which you establish the questions you will need to answer. For example, what is the customer's perception of our brand? Or what type of packaging is more engaging to our potential customers? Once the questions are outlined you are ready for the next step.
- Collect: As its name suggests, this is the stage where you start collecting the needed data. Here, you define which sources of data you will use and how you will use them. The collection of data can come in different forms such as internal or external sources, surveys, interviews, questionnaires, and focus groups, among others. An important note here is that the way you collect the data will be different in a quantitative and qualitative scenario.
- Clean: Once you have the necessary data it is time to clean it and leave it ready for analysis. Not all the data you collect will be useful, when collecting big amounts of data in different formats it is very likely that you will find yourself with duplicate or badly formatted data. To avoid this, before you start working with your data you need to make sure to erase any white spaces, duplicate records, or formatting errors. This way you avoid hurting your analysis with bad-quality data.
- Analyze : With the help of various techniques such as statistical analysis, regressions, neural networks, text analysis, and more, you can start analyzing and manipulating your data to extract relevant conclusions. At this stage, you find trends, correlations, variations, and patterns that can help you answer the questions you first thought of in the identify stage. Various technologies in the market assist researchers and average users with the management of their data. Some of them include business intelligence and visualization software, predictive analytics, and data mining, among others.
- Interpret: Last but not least you have one of the most important steps: it is time to interpret your results. This stage is where the researcher comes up with courses of action based on the findings. For example, here you would understand if your clients prefer packaging that is red or green, plastic or paper, etc. Additionally, at this stage, you can also find some limitations and work on them.
Now that you have a basic understanding of the key data analysis steps, let’s look at the top 17 essential methods.
17 Essential Types Of Data Analysis Methods
Before diving into the 17 essential types of methods, it is important that we go over really fast through the main analysis categories. Starting with the category of descriptive up to prescriptive analysis, the complexity and effort of data evaluation increases, but also the added value for the company.
a) Descriptive analysis - What happened.
The descriptive analysis method is the starting point for any analytic reflection, and it aims to answer the question of what happened? It does this by ordering, manipulating, and interpreting raw data from various sources to turn it into valuable insights for your organization.
Performing descriptive analysis is essential, as it enables us to present our insights in a meaningful way. Although it is relevant to mention that this analysis on its own will not allow you to predict future outcomes or tell you the answer to questions like why something happened, it will leave your data organized and ready to conduct further investigations.
b) Exploratory analysis - How to explore data relationships.
As its name suggests, the main aim of the exploratory analysis is to explore. Prior to it, there is still no notion of the relationship between the data and the variables. Once the data is investigated, exploratory analysis helps you to find connections and generate hypotheses and solutions for specific problems. A typical area of application for it is data mining.
c) Diagnostic analysis - Why it happened.
Diagnostic data analytics empowers analysts and executives by helping them gain a firm contextual understanding of why something happened. If you know why something happened as well as how it happened, you will be able to pinpoint the exact ways of tackling the issue or challenge.
Designed to provide direct and actionable answers to specific questions, this is one of the world’s most important methods in research, among its other key organizational functions such as retail analytics , e.g.
c) Predictive analysis - What will happen.
The predictive method allows you to look into the future to answer the question: what will happen? In order to do this, it uses the results of the previously mentioned descriptive, exploratory, and diagnostic analysis, in addition to machine learning (ML) and artificial intelligence (AI). Through this, you can uncover future trends, potential problems or inefficiencies, connections, and casualties in your data.
With predictive analysis, you can unfold and develop initiatives that will not only enhance your various operational processes but also help you gain an all-important edge over the competition. If you understand why a trend, pattern, or event happened through data, you will be able to develop an informed projection of how things may unfold in particular areas of the business.
e) Prescriptive analysis - How will it happen.
Another of the most effective types of analysis methods in research. Prescriptive data techniques cross over from predictive analysis in the way that it revolves around using patterns or trends to develop responsive, practical business strategies.
By drilling down into prescriptive analysis, you will play an active role in the data consumption process by taking well-arranged sets of visual data and using it as a powerful fix to emerging issues in a number of key areas, including marketing, sales, customer experience, HR, fulfillment, finance, logistics analytics , and others.

As mentioned at the beginning of the post, data analysis methods can be divided into two big categories: quantitative and qualitative. Each of these categories holds a powerful analytical value that changes depending on the scenario and type of data you are working with. Below, we will discuss 17 methods that are divided into qualitative and quantitative approaches.
Without further ado, here are the 17 essential types of data analysis methods with some use cases in the business world:
A. Quantitative Methods
To put it simply, quantitative analysis refers to all methods that use numerical data or data that can be turned into numbers (e.g. category variables like gender, age, etc.) to extract valuable insights. It is used to extract valuable conclusions about relationships, differences, and test hypotheses. Below we discuss some of the key quantitative methods.
1. Cluster analysis
The action of grouping a set of data elements in a way that said elements are more similar (in a particular sense) to each other than to those in other groups – hence the term ‘cluster.’ Since there is no target variable when clustering, the method is often used to find hidden patterns in the data. The approach is also used to provide additional context to a trend or dataset.
Let's look at it from an organizational perspective. In a perfect world, marketers would be able to analyze each customer separately and give them the best-personalized service, but let's face it, with a large customer base, it is timely impossible to do that. That's where clustering comes in. By grouping customers into clusters based on demographics, purchasing behaviors, monetary value, or any other factor that might be relevant for your company, you will be able to immediately optimize your efforts and give your customers the best experience based on their needs.
2. Cohort analysis
This type of data analysis approach uses historical data to examine and compare a determined segment of users' behavior, which can then be grouped with others with similar characteristics. By using this methodology, it's possible to gain a wealth of insight into consumer needs or a firm understanding of a broader target group.
Cohort analysis can be really useful for performing analysis in marketing as it will allow you to understand the impact of your campaigns on specific groups of customers. To exemplify, imagine you send an email campaign encouraging customers to sign up for your site. For this, you create two versions of the campaign with different designs, CTAs, and ad content. Later on, you can use cohort analysis to track the performance of the campaign for a longer period of time and understand which type of content is driving your customers to sign up, repurchase, or engage in other ways.
A useful tool to start performing cohort analysis method is Google Analytics. You can learn more about the benefits and limitations of using cohorts in GA in this useful guide . In the bottom image, you see an example of how you visualize a cohort in this tool. The segments (devices traffic) are divided into date cohorts (usage of devices) and then analyzed week by week to extract insights into performance.

3. Regression analysis
Regression uses historical data to understand how a dependent variable's value is affected when one (linear regression) or more independent variables (multiple regression) change or stay the same. By understanding each variable's relationship and how it developed in the past, you can anticipate possible outcomes and make better decisions in the future.
Let's bring it down with an example. Imagine you did a regression analysis of your sales in 2019 and discovered that variables like product quality, store design, customer service, marketing campaigns, and sales channels affected the overall result. Now you want to use regression to analyze which of these variables changed or if any new ones appeared during 2020. For example, you couldn’t sell as much in your physical store due to COVID lockdowns. Therefore, your sales could’ve either dropped in general or increased in your online channels. Through this, you can understand which independent variables affected the overall performance of your dependent variable, annual sales.
If you want to go deeper into this type of analysis, check out this article and learn more about how you can benefit from regression.
4. Neural networks
The neural network forms the basis for the intelligent algorithms of machine learning. It is a form of analytics that attempts, with minimal intervention, to understand how the human brain would generate insights and predict values. Neural networks learn from each and every data transaction, meaning that they evolve and advance over time.
A typical area of application for neural networks is predictive analytics. There are BI reporting tools that have this feature implemented within them, such as the Predictive Analytics Tool from datapine. This tool enables users to quickly and easily generate all kinds of predictions. All you have to do is select the data to be processed based on your KPIs, and the software automatically calculates forecasts based on historical and current data. Thanks to its user-friendly interface, anyone in your organization can manage it; there’s no need to be an advanced scientist.
Here is an example of how you can use the predictive analysis tool from datapine:

**click to enlarge**
5. Factor analysis
The factor analysis also called “dimension reduction” is a type of data analysis used to describe variability among observed, correlated variables in terms of a potentially lower number of unobserved variables called factors. The aim here is to uncover independent latent variables, an ideal method for streamlining specific segments.
A good way to understand this data analysis method is a customer evaluation of a product. The initial assessment is based on different variables like color, shape, wearability, current trends, materials, comfort, the place where they bought the product, and frequency of usage. Like this, the list can be endless, depending on what you want to track. In this case, factor analysis comes into the picture by summarizing all of these variables into homogenous groups, for example, by grouping the variables color, materials, quality, and trends into a brother latent variable of design.
If you want to start analyzing data using factor analysis we recommend you take a look at this practical guide from UCLA.
6. Data mining
A method of data analysis that is the umbrella term for engineering metrics and insights for additional value, direction, and context. By using exploratory statistical evaluation, data mining aims to identify dependencies, relations, patterns, and trends to generate advanced knowledge. When considering how to analyze data, adopting a data mining mindset is essential to success - as such, it’s an area that is worth exploring in greater detail.
An excellent use case of data mining is datapine intelligent data alerts . With the help of artificial intelligence and machine learning, they provide automated signals based on particular commands or occurrences within a dataset. For example, if you’re monitoring supply chain KPIs , you could set an intelligent alarm to trigger when invalid or low-quality data appears. By doing so, you will be able to drill down deep into the issue and fix it swiftly and effectively.
In the following picture, you can see how the intelligent alarms from datapine work. By setting up ranges on daily orders, sessions, and revenues, the alarms will notify you if the goal was not completed or if it exceeded expectations.

7. Time series analysis
As its name suggests, time series analysis is used to analyze a set of data points collected over a specified period of time. Although analysts use this method to monitor the data points in a specific interval of time rather than just monitoring them intermittently, the time series analysis is not uniquely used for the purpose of collecting data over time. Instead, it allows researchers to understand if variables changed during the duration of the study, how the different variables are dependent, and how did it reach the end result.
In a business context, this method is used to understand the causes of different trends and patterns to extract valuable insights. Another way of using this method is with the help of time series forecasting. Powered by predictive technologies, businesses can analyze various data sets over a period of time and forecast different future events.
A great use case to put time series analysis into perspective is seasonality effects on sales. By using time series forecasting to analyze sales data of a specific product over time, you can understand if sales rise over a specific period of time (e.g. swimwear during summertime, or candy during Halloween). These insights allow you to predict demand and prepare production accordingly.
8. Decision Trees
The decision tree analysis aims to act as a support tool to make smart and strategic decisions. By visually displaying potential outcomes, consequences, and costs in a tree-like model, researchers and company users can easily evaluate all factors involved and choose the best course of action. Decision trees are helpful to analyze quantitative data and they allow for an improved decision-making process by helping you spot improvement opportunities, reduce costs, and enhance operational efficiency and production.
But how does a decision tree actually works? This method works like a flowchart that starts with the main decision that you need to make and branches out based on the different outcomes and consequences of each decision. Each outcome will outline its own consequences, costs, and gains and, at the end of the analysis, you can compare each of them and make the smartest decision.
Businesses can use them to understand which project is more cost-effective and will bring more earnings in the long run. For example, imagine you need to decide if you want to update your software app or build a new app entirely. Here you would compare the total costs, the time needed to be invested, potential revenue, and any other factor that might affect your decision. In the end, you would be able to see which of these two options is more realistic and attainable for your company or research.
9. Conjoint analysis
Last but not least, we have the conjoint analysis. This approach is usually used in surveys to understand how individuals value different attributes of a product or service and it is one of the most effective methods to extract consumer preferences. When it comes to purchasing, some clients might be more price-focused, others more features-focused, and others might have a sustainable focus. Whatever your customer's preferences are, you can find them with conjoint analysis. Through this, companies can define pricing strategies, packaging options, subscription packages, and more.
A great example of conjoint analysis is in marketing and sales. For instance, a cupcake brand might use conjoint analysis and find that its clients prefer gluten-free options and cupcakes with healthier toppings over super sugary ones. Thus, the cupcake brand can turn these insights into advertisements and promotions to increase sales of this particular type of product. And not just that, conjoint analysis can also help businesses segment their customers based on their interests. This allows them to send different messaging that will bring value to each of the segments.
10. Correspondence Analysis
Also known as reciprocal averaging, correspondence analysis is a method used to analyze the relationship between categorical variables presented within a contingency table. A contingency table is a table that displays two (simple correspondence analysis) or more (multiple correspondence analysis) categorical variables across rows and columns that show the distribution of the data, which is usually answers to a survey or questionnaire on a specific topic.
This method starts by calculating an “expected value” which is done by multiplying row and column averages and dividing it by the overall original value of the specific table cell. The “expected value” is then subtracted from the original value resulting in a “residual number” which is what allows you to extract conclusions about relationships and distribution. The results of this analysis are later displayed using a map that represents the relationship between the different values. The closest two values are in the map, the bigger the relationship. Let’s put it into perspective with an example.
Imagine you are carrying out a market research analysis about outdoor clothing brands and how they are perceived by the public. For this analysis, you ask a group of people to match each brand with a certain attribute which can be durability, innovation, quality materials, etc. When calculating the residual numbers, you can see that brand A has a positive residual for innovation but a negative one for durability. This means that brand A is not positioned as a durable brand in the market, something that competitors could take advantage of.
11. Multidimensional Scaling (MDS)
MDS is a method used to observe the similarities or disparities between objects which can be colors, brands, people, geographical coordinates, and more. The objects are plotted using an “MDS map” that positions similar objects together and disparate ones far apart. The (dis) similarities between objects are represented using one or more dimensions that can be observed using a numerical scale. For example, if you want to know how people feel about the COVID-19 vaccine, you can use 1 for “don’t believe in the vaccine at all” and 10 for “firmly believe in the vaccine” and a scale of 2 to 9 for in between responses. When analyzing an MDS map the only thing that matters is the distance between the objects, the orientation of the dimensions is arbitrary and has no meaning at all.
Multidimensional scaling is a valuable technique for market research, especially when it comes to evaluating product or brand positioning. For instance, if a cupcake brand wants to know how they are positioned compared to competitors, it can define 2-3 dimensions such as taste, ingredients, shopping experience, or more, and do a multidimensional scaling analysis to find improvement opportunities as well as areas in which competitors are currently leading.
Another business example is in procurement when deciding on different suppliers. Decision makers can generate an MDS map to see how the different prices, delivery times, technical services, and more of the different suppliers differ and pick the one that suits their needs the best.
A final example proposed by a research paper on "An Improved Study of Multilevel Semantic Network Visualization for Analyzing Sentiment Word of Movie Review Data". Researchers picked a two-dimensional MDS map to display the distances and relationships between different sentiments in movie reviews. They used 36 sentiment words and distributed them based on their emotional distance as we can see in the image below where the words "outraged" and "sweet" are on opposite sides of the map, marking the distance between the two emotions very clearly.

Aside from being a valuable technique to analyze dissimilarities, MDS also serves as a dimension-reduction technique for large dimensional data.
B. Qualitative Methods
Qualitative data analysis methods are defined as the observation of non-numerical data that is gathered and produced using methods of observation such as interviews, focus groups, questionnaires, and more. As opposed to quantitative methods, qualitative data is more subjective and highly valuable in analyzing customer retention and product development.
12. Text analysis
Text analysis, also known in the industry as text mining, works by taking large sets of textual data and arranging them in a way that makes it easier to manage. By working through this cleansing process in stringent detail, you will be able to extract the data that is truly relevant to your organization and use it to develop actionable insights that will propel you forward.
Modern software accelerate the application of text analytics. Thanks to the combination of machine learning and intelligent algorithms, you can perform advanced analytical processes such as sentiment analysis. This technique allows you to understand the intentions and emotions of a text, for example, if it's positive, negative, or neutral, and then give it a score depending on certain factors and categories that are relevant to your brand. Sentiment analysis is often used to monitor brand and product reputation and to understand how successful your customer experience is. To learn more about the topic check out this insightful article .
By analyzing data from various word-based sources, including product reviews, articles, social media communications, and survey responses, you will gain invaluable insights into your audience, as well as their needs, preferences, and pain points. This will allow you to create campaigns, services, and communications that meet your prospects’ needs on a personal level, growing your audience while boosting customer retention. There are various other “sub-methods” that are an extension of text analysis. Each of them serves a more specific purpose and we will look at them in detail next.
13. Content Analysis
This is a straightforward and very popular method that examines the presence and frequency of certain words, concepts, and subjects in different content formats such as text, image, audio, or video. For example, the number of times the name of a celebrity is mentioned on social media or online tabloids. It does this by coding text data that is later categorized and tabulated in a way that can provide valuable insights, making it the perfect mix of quantitative and qualitative analysis.
There are two types of content analysis. The first one is the conceptual analysis which focuses on explicit data, for instance, the number of times a concept or word is mentioned in a piece of content. The second one is relational analysis, which focuses on the relationship between different concepts or words and how they are connected within a specific context.
Content analysis is often used by marketers to measure brand reputation and customer behavior. For example, by analyzing customer reviews. It can also be used to analyze customer interviews and find directions for new product development. It is also important to note, that in order to extract the maximum potential out of this analysis method, it is necessary to have a clearly defined research question.
14. Thematic Analysis
Very similar to content analysis, thematic analysis also helps in identifying and interpreting patterns in qualitative data with the main difference being that the first one can also be applied to quantitative analysis. The thematic method analyzes large pieces of text data such as focus group transcripts or interviews and groups them into themes or categories that come up frequently within the text. It is a great method when trying to figure out peoples view’s and opinions about a certain topic. For example, if you are a brand that cares about sustainability, you can do a survey of your customers to analyze their views and opinions about sustainability and how they apply it to their lives. You can also analyze customer service calls transcripts to find common issues and improve your service.
Thematic analysis is a very subjective technique that relies on the researcher’s judgment. Therefore, to avoid biases, it has 6 steps that include familiarization, coding, generating themes, reviewing themes, defining and naming themes, and writing up. It is also important to note that, because it is a flexible approach, the data can be interpreted in multiple ways and it can be hard to select what data is more important to emphasize.
15. Narrative Analysis
A bit more complex in nature than the two previous ones, narrative analysis is used to explore the meaning behind the stories that people tell and most importantly, how they tell them. By looking into the words that people use to describe a situation you can extract valuable conclusions about their perspective on a specific topic. Common sources for narrative data include autobiographies, family stories, opinion pieces, and testimonials, among others.
From a business perspective, narrative analysis can be useful to analyze customer behaviors and feelings towards a specific product, service, feature, or others. It provides unique and deep insights that can be extremely valuable. However, it has some drawbacks.
The biggest weakness of this method is that the sample sizes are usually very small due to the complexity and time-consuming nature of the collection of narrative data. Plus, the way a subject tells a story will be significantly influenced by his or her specific experiences, making it very hard to replicate in a subsequent study.
16. Discourse Analysis
Discourse analysis is used to understand the meaning behind any type of written, verbal, or symbolic discourse based on its political, social, or cultural context. It mixes the analysis of languages and situations together. This means that the way the content is constructed and the meaning behind it is significantly influenced by the culture and society it takes place in. For example, if you are analyzing political speeches you need to consider different context elements such as the politician's background, the current political context of the country, the audience to which the speech is directed, and so on.
From a business point of view, discourse analysis is a great market research tool. It allows marketers to understand how the norms and ideas of the specific market work and how their customers relate to those ideas. It can be very useful to build a brand mission or develop a unique tone of voice.
17. Grounded Theory Analysis
Traditionally, researchers decide on a method and hypothesis and start to collect the data to prove that hypothesis. The grounded theory is the only method that doesn’t require an initial research question or hypothesis as its value lies in the generation of new theories. With the grounded theory method, you can go into the analysis process with an open mind and explore the data to generate new theories through tests and revisions. In fact, it is not necessary to collect the data and then start to analyze it. Researchers usually start to find valuable insights as they are gathering the data.
All of these elements make grounded theory a very valuable method as theories are fully backed by data instead of initial assumptions. It is a great technique to analyze poorly researched topics or find the causes behind specific company outcomes. For example, product managers and marketers might use the grounded theory to find the causes of high levels of customer churn and look into customer surveys and reviews to develop new theories about the causes.
How To Analyze Data? Top 17 Data Analysis Techniques To Apply

Now that we’ve answered the questions “what is data analysis’”, why is it important, and covered the different data analysis types, it’s time to dig deeper into how to perform your analysis by working through these 17 essential techniques.
1. Collaborate your needs
Before you begin analyzing or drilling down into any techniques, it’s crucial to sit down collaboratively with all key stakeholders within your organization, decide on your primary campaign or strategic goals, and gain a fundamental understanding of the types of insights that will best benefit your progress or provide you with the level of vision you need to evolve your organization.
2. Establish your questions
Once you’ve outlined your core objectives, you should consider which questions will need answering to help you achieve your mission. This is one of the most important techniques as it will shape the very foundations of your success.
To help you ask the right things and ensure your data works for you, you have to ask the right data analysis questions .
3. Data democratization
After giving your data analytics methodology some real direction, and knowing which questions need answering to extract optimum value from the information available to your organization, you should continue with democratization.
Data democratization is an action that aims to connect data from various sources efficiently and quickly so that anyone in your organization can access it at any given moment. You can extract data in text, images, videos, numbers, or any other format. And then perform cross-database analysis to achieve more advanced insights to share with the rest of the company interactively.
Once you have decided on your most valuable sources, you need to take all of this into a structured format to start collecting your insights. For this purpose, datapine offers an easy all-in-one data connectors feature to integrate all your internal and external sources and manage them at your will. Additionally, datapine’s end-to-end solution automatically updates your data, allowing you to save time and focus on performing the right analysis to grow your company.

4. Think of governance
When collecting data in a business or research context you always need to think about security and privacy. With data breaches becoming a topic of concern for businesses, the need to protect your client's or subject’s sensitive information becomes critical.
To ensure that all this is taken care of, you need to think of a data governance strategy. According to Gartner , this concept refers to “ the specification of decision rights and an accountability framework to ensure the appropriate behavior in the valuation, creation, consumption, and control of data and analytics .” In simpler words, data governance is a collection of processes, roles, and policies, that ensure the efficient use of data while still achieving the main company goals. It ensures that clear roles are in place for who can access the information and how they can access it. In time, this not only ensures that sensitive information is protected but also allows for an efficient analysis as a whole.
5. Clean your data
After harvesting from so many sources you will be left with a vast amount of information that can be overwhelming to deal with. At the same time, you can be faced with incorrect data that can be misleading to your analysis. The smartest thing you can do to avoid dealing with this in the future is to clean the data. This is fundamental before visualizing it, as it will ensure that the insights you extract from it are correct.
There are many things that you need to look for in the cleaning process. The most important one is to eliminate any duplicate observations; this usually appears when using multiple internal and external sources of information. You can also add any missing codes, fix empty fields, and eliminate incorrectly formatted data.
Another usual form of cleaning is done with text data. As we mentioned earlier, most companies today analyze customer reviews, social media comments, questionnaires, and several other text inputs. In order for algorithms to detect patterns, text data needs to be revised to avoid invalid characters or any syntax or spelling errors.
Most importantly, the aim of cleaning is to prevent you from arriving at false conclusions that can damage your company in the long run. By using clean data, you will also help BI solutions to interact better with your information and create better reports for your organization.
6. Set your KPIs
Once you’ve set your sources, cleaned your data, and established clear-cut questions you want your insights to answer, you need to set a host of key performance indicators (KPIs) that will help you track, measure, and shape your progress in a number of key areas.
KPIs are critical to both qualitative and quantitative analysis research. This is one of the primary methods of data analysis you certainly shouldn’t overlook.
To help you set the best possible KPIs for your initiatives and activities, here is an example of a relevant logistics KPI : transportation-related costs. If you want to see more go explore our collection of key performance indicator examples .

7. Omit useless data
Having bestowed your data analysis tools and techniques with true purpose and defined your mission, you should explore the raw data you’ve collected from all sources and use your KPIs as a reference for chopping out any information you deem to be useless.
Trimming the informational fat is one of the most crucial methods of analysis as it will allow you to focus your analytical efforts and squeeze every drop of value from the remaining ‘lean’ information.
Any stats, facts, figures, or metrics that don’t align with your business goals or fit with your KPI management strategies should be eliminated from the equation.
8. Build a data management roadmap
While, at this point, this particular step is optional (you will have already gained a wealth of insight and formed a fairly sound strategy by now), creating a data governance roadmap will help your data analysis methods and techniques become successful on a more sustainable basis. These roadmaps, if developed properly, are also built so they can be tweaked and scaled over time.
Invest ample time in developing a roadmap that will help you store, manage, and handle your data internally, and you will make your analysis techniques all the more fluid and functional – one of the most powerful types of data analysis methods available today.
9. Integrate technology
There are many ways to analyze data, but one of the most vital aspects of analytical success in a business context is integrating the right decision support software and technology.
Robust analysis platforms will not only allow you to pull critical data from your most valuable sources while working with dynamic KPIs that will offer you actionable insights; it will also present them in a digestible, visual, interactive format from one central, live dashboard . A data methodology you can count on.
By integrating the right technology within your data analysis methodology, you’ll avoid fragmenting your insights, saving you time and effort while allowing you to enjoy the maximum value from your business’s most valuable insights.
For a look at the power of software for the purpose of analysis and to enhance your methods of analyzing, glance over our selection of dashboard examples .
10. Answer your questions
By considering each of the above efforts, working with the right technology, and fostering a cohesive internal culture where everyone buys into the different ways to analyze data as well as the power of digital intelligence, you will swiftly start to answer your most burning business questions. Arguably, the best way to make your data concepts accessible across the organization is through data visualization.
11. Visualize your data
Online data visualization is a powerful tool as it lets you tell a story with your metrics, allowing users across the organization to extract meaningful insights that aid business evolution – and it covers all the different ways to analyze data.
The purpose of analyzing is to make your entire organization more informed and intelligent, and with the right platform or dashboard, this is simpler than you think, as demonstrated by our marketing dashboard .

This visual, dynamic, and interactive online dashboard is a data analysis example designed to give Chief Marketing Officers (CMO) an overview of relevant metrics to help them understand if they achieved their monthly goals.
In detail, this example generated with a modern dashboard creator displays interactive charts for monthly revenues, costs, net income, and net income per customer; all of them are compared with the previous month so that you can understand how the data fluctuated. In addition, it shows a detailed summary of the number of users, customers, SQLs, and MQLs per month to visualize the whole picture and extract relevant insights or trends for your marketing reports .
The CMO dashboard is perfect for c-level management as it can help them monitor the strategic outcome of their marketing efforts and make data-driven decisions that can benefit the company exponentially.
12. Be careful with the interpretation
We already dedicated an entire post to data interpretation as it is a fundamental part of the process of data analysis. It gives meaning to the analytical information and aims to drive a concise conclusion from the analysis results. Since most of the time companies are dealing with data from many different sources, the interpretation stage needs to be done carefully and properly in order to avoid misinterpretations.
To help you through the process, here we list three common practices that you need to avoid at all costs when looking at your data:
- Correlation vs. causation: The human brain is formatted to find patterns. This behavior leads to one of the most common mistakes when performing interpretation: confusing correlation with causation. Although these two aspects can exist simultaneously, it is not correct to assume that because two things happened together, one provoked the other. A piece of advice to avoid falling into this mistake is never to trust just intuition, trust the data. If there is no objective evidence of causation, then always stick to correlation.
- Confirmation bias: This phenomenon describes the tendency to select and interpret only the data necessary to prove one hypothesis, often ignoring the elements that might disprove it. Even if it's not done on purpose, confirmation bias can represent a real problem, as excluding relevant information can lead to false conclusions and, therefore, bad business decisions. To avoid it, always try to disprove your hypothesis instead of proving it, share your analysis with other team members, and avoid drawing any conclusions before the entire analytical project is finalized.
- Statistical significance: To put it in short words, statistical significance helps analysts understand if a result is actually accurate or if it happened because of a sampling error or pure chance. The level of statistical significance needed might depend on the sample size and the industry being analyzed. In any case, ignoring the significance of a result when it might influence decision-making can be a huge mistake.
13. Build a narrative
Now, we’re going to look at how you can bring all of these elements together in a way that will benefit your business - starting with a little something called data storytelling.
The human brain responds incredibly well to strong stories or narratives. Once you’ve cleansed, shaped, and visualized your most invaluable data using various BI dashboard tools , you should strive to tell a story - one with a clear-cut beginning, middle, and end.
By doing so, you will make your analytical efforts more accessible, digestible, and universal, empowering more people within your organization to use your discoveries to their actionable advantage.
14. Consider autonomous technology
Autonomous technologies, such as artificial intelligence (AI) and machine learning (ML), play a significant role in the advancement of understanding how to analyze data more effectively.
Gartner predicts that by the end of this year, 80% of emerging technologies will be developed with AI foundations. This is a testament to the ever-growing power and value of autonomous technologies.
At the moment, these technologies are revolutionizing the analysis industry. Some examples that we mentioned earlier are neural networks, intelligent alarms, and sentiment analysis.
15. Share the load
If you work with the right tools and dashboards, you will be able to present your metrics in a digestible, value-driven format, allowing almost everyone in the organization to connect with and use relevant data to their advantage.
Modern dashboards consolidate data from various sources, providing access to a wealth of insights in one centralized location, no matter if you need to monitor recruitment metrics or generate reports that need to be sent across numerous departments. Moreover, these cutting-edge tools offer access to dashboards from a multitude of devices, meaning that everyone within the business can connect with practical insights remotely - and share the load.
Once everyone is able to work with a data-driven mindset, you will catalyze the success of your business in ways you never thought possible. And when it comes to knowing how to analyze data, this kind of collaborative approach is essential.
16. Data analysis tools
In order to perform high-quality analysis of data, it is fundamental to use tools and software that will ensure the best results. Here we leave you a small summary of four fundamental categories of data analysis tools for your organization.
- Business Intelligence: BI tools allow you to process significant amounts of data from several sources in any format. Through this, you can not only analyze and monitor your data to extract relevant insights but also create interactive reports and dashboards to visualize your KPIs and use them for your company's good. datapine is an amazing online BI software that is focused on delivering powerful online analysis features that are accessible to beginner and advanced users. Like this, it offers a full-service solution that includes cutting-edge analysis of data, KPIs visualization, live dashboards, reporting, and artificial intelligence technologies to predict trends and minimize risk.
- Statistical analysis: These tools are usually designed for scientists, statisticians, market researchers, and mathematicians, as they allow them to perform complex statistical analyses with methods like regression analysis, predictive analysis, and statistical modeling. A good tool to perform this type of analysis is R-Studio as it offers a powerful data modeling and hypothesis testing feature that can cover both academic and general data analysis. This tool is one of the favorite ones in the industry, due to its capability for data cleaning, data reduction, and performing advanced analysis with several statistical methods. Another relevant tool to mention is SPSS from IBM. The software offers advanced statistical analysis for users of all skill levels. Thanks to a vast library of machine learning algorithms, text analysis, and a hypothesis testing approach it can help your company find relevant insights to drive better decisions. SPSS also works as a cloud service that enables you to run it anywhere.
- SQL Consoles: SQL is a programming language often used to handle structured data in relational databases. Tools like these are popular among data scientists as they are extremely effective in unlocking these databases' value. Undoubtedly, one of the most used SQL software in the market is MySQL Workbench . This tool offers several features such as a visual tool for database modeling and monitoring, complete SQL optimization, administration tools, and visual performance dashboards to keep track of KPIs.
- Data Visualization: These tools are used to represent your data through charts, graphs, and maps that allow you to find patterns and trends in the data. datapine's already mentioned BI platform also offers a wealth of powerful online data visualization tools with several benefits. Some of them include: delivering compelling data-driven presentations to share with your entire company, the ability to see your data online with any device wherever you are, an interactive dashboard design feature that enables you to showcase your results in an interactive and understandable way, and to perform online self-service reports that can be used simultaneously with several other people to enhance team productivity.
17. Refine your process constantly
Last is a step that might seem obvious to some people, but it can be easily ignored if you think you are done. Once you have extracted the needed results, you should always take a retrospective look at your project and think about what you can improve. As you saw throughout this long list of techniques, data analysis is a complex process that requires constant refinement. For this reason, you should always go one step further and keep improving.
Quality Criteria For Data Analysis
So far we’ve covered a list of methods and techniques that should help you perform efficient data analysis. But how do you measure the quality and validity of your results? This is done with the help of some science quality criteria. Here we will go into a more theoretical area that is critical to understanding the fundamentals of statistical analysis in science. However, you should also be aware of these steps in a business context, as they will allow you to assess the quality of your results in the correct way. Let’s dig in.
- Internal validity: The results of a survey are internally valid if they measure what they are supposed to measure and thus provide credible results. In other words , internal validity measures the trustworthiness of the results and how they can be affected by factors such as the research design, operational definitions, how the variables are measured, and more. For instance, imagine you are doing an interview to ask people if they brush their teeth two times a day. While most of them will answer yes, you can still notice that their answers correspond to what is socially acceptable, which is to brush your teeth at least twice a day. In this case, you can’t be 100% sure if respondents actually brush their teeth twice a day or if they just say that they do, therefore, the internal validity of this interview is very low.
- External validity: Essentially, external validity refers to the extent to which the results of your research can be applied to a broader context. It basically aims to prove that the findings of a study can be applied in the real world. If the research can be applied to other settings, individuals, and times, then the external validity is high.
- Reliability : If your research is reliable, it means that it can be reproduced. If your measurement were repeated under the same conditions, it would produce similar results. This means that your measuring instrument consistently produces reliable results. For example, imagine a doctor building a symptoms questionnaire to detect a specific disease in a patient. Then, various other doctors use this questionnaire but end up diagnosing the same patient with a different condition. This means the questionnaire is not reliable in detecting the initial disease. Another important note here is that in order for your research to be reliable, it also needs to be objective. If the results of a study are the same, independent of who assesses them or interprets them, the study can be considered reliable. Let’s see the objectivity criteria in more detail now.
- Objectivity: In data science, objectivity means that the researcher needs to stay fully objective when it comes to its analysis. The results of a study need to be affected by objective criteria and not by the beliefs, personality, or values of the researcher. Objectivity needs to be ensured when you are gathering the data, for example, when interviewing individuals, the questions need to be asked in a way that doesn't influence the results. Paired with this, objectivity also needs to be thought of when interpreting the data. If different researchers reach the same conclusions, then the study is objective. For this last point, you can set predefined criteria to interpret the results to ensure all researchers follow the same steps.
The discussed quality criteria cover mostly potential influences in a quantitative context. Analysis in qualitative research has by default additional subjective influences that must be controlled in a different way. Therefore, there are other quality criteria for this kind of research such as credibility, transferability, dependability, and confirmability. You can see each of them more in detail on this resource .
Data Analysis Limitations & Barriers
Analyzing data is not an easy task. As you’ve seen throughout this post, there are many steps and techniques that you need to apply in order to extract useful information from your research. While a well-performed analysis can bring various benefits to your organization it doesn't come without limitations. In this section, we will discuss some of the main barriers you might encounter when conducting an analysis. Let’s see them more in detail.
- Lack of clear goals: No matter how good your data or analysis might be if you don’t have clear goals or a hypothesis the process might be worthless. While we mentioned some methods that don’t require a predefined hypothesis, it is always better to enter the analytical process with some clear guidelines of what you are expecting to get out of it, especially in a business context in which data is utilized to support important strategic decisions.
- Objectivity: Arguably one of the biggest barriers when it comes to data analysis in research is to stay objective. When trying to prove a hypothesis, researchers might find themselves, intentionally or unintentionally, directing the results toward an outcome that they want. To avoid this, always question your assumptions and avoid confusing facts with opinions. You can also show your findings to a research partner or external person to confirm that your results are objective.
- Data representation: A fundamental part of the analytical procedure is the way you represent your data. You can use various graphs and charts to represent your findings, but not all of them will work for all purposes. Choosing the wrong visual can not only damage your analysis but can mislead your audience, therefore, it is important to understand when to use each type of data depending on your analytical goals. Our complete guide on the types of graphs and charts lists 20 different visuals with examples of when to use them.
- Flawed correlation : Misleading statistics can significantly damage your research. We’ve already pointed out a few interpretation issues previously in the post, but it is an important barrier that we can't avoid addressing here as well. Flawed correlations occur when two variables appear related to each other but they are not. Confusing correlations with causation can lead to a wrong interpretation of results which can lead to building wrong strategies and loss of resources, therefore, it is very important to identify the different interpretation mistakes and avoid them.
- Sample size: A very common barrier to a reliable and efficient analysis process is the sample size. In order for the results to be trustworthy, the sample size should be representative of what you are analyzing. For example, imagine you have a company of 1000 employees and you ask the question “do you like working here?” to 50 employees of which 49 say yes, which means 95%. Now, imagine you ask the same question to the 1000 employees and 950 say yes, which also means 95%. Saying that 95% of employees like working in the company when the sample size was only 50 is not a representative or trustworthy conclusion. The significance of the results is way more accurate when surveying a bigger sample size.
- Privacy concerns: In some cases, data collection can be subjected to privacy regulations. Businesses gather all kinds of information from their customers from purchasing behaviors to addresses and phone numbers. If this falls into the wrong hands due to a breach, it can affect the security and confidentiality of your clients. To avoid this issue, you need to collect only the data that is needed for your research and, if you are using sensitive facts, make it anonymous so customers are protected. The misuse of customer data can severely damage a business's reputation, so it is important to keep an eye on privacy.
- Lack of communication between teams : When it comes to performing data analysis on a business level, it is very likely that each department and team will have different goals and strategies. However, they are all working for the same common goal of helping the business run smoothly and keep growing. When teams are not connected and communicating with each other, it can directly affect the way general strategies are built. To avoid these issues, tools such as data dashboards enable teams to stay connected through data in a visually appealing way.
- Innumeracy : Businesses are working with data more and more every day. While there are many BI tools available to perform effective analysis, data literacy is still a constant barrier. Not all employees know how to apply analysis techniques or extract insights from them. To prevent this from happening, you can implement different training opportunities that will prepare every relevant user to deal with data.
Key Data Analysis Skills
As you've learned throughout this lengthy guide, analyzing data is a complex task that requires a lot of knowledge and skills. That said, thanks to the rise of self-service tools the process is way more accessible and agile than it once was. Regardless, there are still some key skills that are valuable to have when working with data, we list the most important ones below.
- Critical and statistical thinking: To successfully analyze data you need to be creative and think out of the box. Yes, that might sound like a weird statement considering that data is often tight to facts. However, a great level of critical thinking is required to uncover connections, come up with a valuable hypothesis, and extract conclusions that go a step further from the surface. This, of course, needs to be complemented by statistical thinking and an understanding of numbers.
- Data cleaning: Anyone who has ever worked with data before will tell you that the cleaning and preparation process accounts for 80% of a data analyst's work, therefore, the skill is fundamental. But not just that, not cleaning the data adequately can also significantly damage the analysis which can lead to poor decision-making in a business scenario. While there are multiple tools that automate the cleaning process and eliminate the possibility of human error, it is still a valuable skill to dominate.
- Data visualization: Visuals make the information easier to understand and analyze, not only for professional users but especially for non-technical ones. Having the necessary skills to not only choose the right chart type but know when to apply it correctly is key. This also means being able to design visually compelling charts that make the data exploration process more efficient.
- SQL: The Structured Query Language or SQL is a programming language used to communicate with databases. It is fundamental knowledge as it enables you to update, manipulate, and organize data from relational databases which are the most common databases used by companies. It is fairly easy to learn and one of the most valuable skills when it comes to data analysis.
- Communication skills: This is a skill that is especially valuable in a business environment. Being able to clearly communicate analytical outcomes to colleagues is incredibly important, especially when the information you are trying to convey is complex for non-technical people. This applies to in-person communication as well as written format, for example, when generating a dashboard or report. While this might be considered a “soft” skill compared to the other ones we mentioned, it should not be ignored as you most likely will need to share analytical findings with others no matter the context.
Data Analysis In The Big Data Environment
Big data is invaluable to today’s businesses, and by using different methods for data analysis, it’s possible to view your data in a way that can help you turn insight into positive action.
To inspire your efforts and put the importance of big data into context, here are some insights that you should know:
- By 2026 the industry of big data is expected to be worth approximately $273.4 billion.
- 94% of enterprises say that analyzing data is important for their growth and digital transformation.
- Companies that exploit the full potential of their data can increase their operating margins by 60% .
- We already told you the benefits of Artificial Intelligence through this article. This industry's financial impact is expected to grow up to $40 billion by 2025.
Data analysis concepts may come in many forms, but fundamentally, any solid methodology will help to make your business more streamlined, cohesive, insightful, and successful than ever before.
Key Takeaways From Data Analysis
As we reach the end of our data analysis journey, we leave a small summary of the main methods and techniques to perform excellent analysis and grow your business.
17 Essential Types of Data Analysis Methods:
- Cluster analysis
- Cohort analysis
- Regression analysis
- Factor analysis
- Neural Networks
- Data Mining
- Text analysis
- Time series analysis
- Decision trees
- Conjoint analysis
- Correspondence Analysis
- Multidimensional Scaling
- Content analysis
- Thematic analysis
- Narrative analysis
- Grounded theory analysis
- Discourse analysis
Top 17 Data Analysis Techniques:
- Collaborate your needs
- Establish your questions
- Data democratization
- Think of data governance
- Clean your data
- Set your KPIs
- Omit useless data
- Build a data management roadmap
- Integrate technology
- Answer your questions
- Visualize your data
- Interpretation of data
- Consider autonomous technology
- Build a narrative
- Share the load
- Data Analysis tools
- Refine your process constantly
We’ve pondered the data analysis definition and drilled down into the practical applications of data-centric analytics, and one thing is clear: by taking measures to arrange your data and making your metrics work for you, it’s possible to transform raw information into action - the kind of that will push your business to the next level.
Yes, good data analytics techniques result in enhanced business intelligence (BI). To help you understand this notion in more detail, read our exploration of business intelligence reporting .
And, if you’re ready to perform your own analysis, drill down into your facts and figures while interacting with your data on astonishing visuals, you can try our software for a free, 14-day trial .
Business growth
Business tips
What is data analysis? Examples and how to get started

Even with years of professional experience working with data, the term "data analysis" still sets off a panic button in my soul. And yes, when it comes to serious data analysis for your business, you'll eventually want data scientists on your side. But if you're just getting started, no panic attacks are required.
Table of contents:
Quick review: What is data analysis?
Why is data analysis important, types of data analysis (with examples), data analysis process: how to get started, frequently asked questions.
Zapier is the leader in workflow automation—integrating with 6,000+ apps from partners like Google, Salesforce, and Microsoft. Use interfaces, data tables, and logic to build secure, automated systems for your business-critical workflows across your organization's technology stack. Learn more .
Data analysis is the process of examining, filtering, adapting, and modeling data to help solve problems. Data analysis helps determine what is and isn't working, so you can make the changes needed to achieve your business goals.
Keep in mind that data analysis includes analyzing both quantitative data (e.g., profits and sales) and qualitative data (e.g., surveys and case studies) to paint the whole picture. Here are two simple examples (of a nuanced topic) to show you what I mean.
An example of quantitative data analysis is an online jewelry store owner using inventory data to forecast and improve reordering accuracy. The owner looks at their sales from the past six months and sees that, on average, they sold 210 gold pieces and 105 silver pieces per month, but they only had 100 gold pieces and 100 silver pieces in stock. By collecting and analyzing inventory data on these SKUs, they're forecasting to improve reordering accuracy. The next time they order inventory, they order twice as many gold pieces as silver to meet customer demand.
An example of qualitative data analysis is a fitness studio owner collecting customer feedback to improve class offerings. The studio owner sends out an open-ended survey asking customers what types of exercises they enjoy the most. The owner then performs qualitative content analysis to identify the most frequently suggested exercises and incorporates these into future workout classes.
Here's why it's worth implementing data analysis for your business:
Understand your target audience: You might think you know how to best target your audience, but are your assumptions backed by data? Data analysis can help answer questions like, "What demographics define my target audience?" or "What is my audience motivated by?"
Inform decisions: You don't need to toss and turn over a decision when the data points clearly to the answer. For instance, a restaurant could analyze which dishes on the menu are selling the most, helping them decide which ones to keep and which ones to change.
Adjust budgets: Similarly, data analysis can highlight areas in your business that are performing well and are worth investing more in, as well as areas that aren't generating enough revenue and should be cut. For example, a B2B software company might discover their product for enterprises is thriving while their small business solution lags behind. This discovery could prompt them to allocate more budget toward the enterprise product, resulting in better resource utilization.
Identify and solve problems: Let's say a cell phone manufacturer notices data showing a lot of customers returning a certain model. When they investigate, they find that model also happens to have the highest number of crashes. Once they identify and solve the technical issue, they can reduce the number of returns.
There are five main types of data analysis—with increasingly scary-sounding names. Each one serves a different purpose, so take a look to see which makes the most sense for your situation. It's ok if you can't pronounce the one you choose.

Text analysis: What is happening?
Text analysis, AKA data mining , involves pulling insights from large amounts of unstructured, text-based data sources : emails, social media, support tickets, reviews, and so on. You would use text analysis when the volume of data is too large to sift through manually.
Here are a few methods used to perform text analysis, to give you a sense of how it's different from a human reading through the text:
Word frequency identifies the most frequently used words. For example, a restaurant monitors social media mentions and measures the frequency of positive and negative keywords like "delicious" or "expensive" to determine how customers feel about their experience.
Language detection indicates the language of text. For example, a global software company may use language detection on support tickets to connect customers with the appropriate agent.
Keyword extraction automatically identifies the most used terms. For example, instead of sifting through thousands of reviews, a popular brand uses a keyword extractor to summarize the words or phrases that are most relevant.
Because text analysis is based on words, not numbers, it's a bit more subjective. Words can have multiple meanings, of course, and Gen Z makes things even tougher with constant coinage. Natural language processing (NLP) software will help you get the most accurate text analysis, but it's rarely as objective as numerical analysis.
Statistical analysis: What happened?
Statistical analysis pulls past data to identify meaningful trends. Two primary categories of statistical analysis exist: descriptive and inferential.
Descriptive analysis
Descriptive analysis looks at numerical data and calculations to determine what happened in a business. Companies use descriptive analysis to determine customer satisfaction , track campaigns, generate reports, and evaluate performance.
Here are a few methods used to perform descriptive analysis:
Measures of frequency identify how frequently an event occurs. For example, a popular coffee chain sends out a survey asking customers what their favorite holiday drink is and uses measures of frequency to determine how often a particular drink is selected.
Measures of central tendency use mean, median, and mode to identify results. For example, a dating app company might use measures of central tendency to determine the average age of its users.
Measures of dispersion measure how data is distributed across a range. For example, HR may use measures of dispersion to determine what salary to offer in a given field.
Inferential analysis
Inferential analysis uses a sample of data to draw conclusions about a much larger population. This type of analysis is used when the population you're interested in analyzing is very large.
Here are a few methods used when performing inferential analysis:
Hypothesis testing identifies which variables impact a particular topic. For example, a business uses hypothesis testing to determine if increased sales were the result of a specific marketing campaign.
Confidence intervals indicates how accurate an estimate is. For example, a company using market research to survey customers about a new product may want to determine how confident they are that the individuals surveyed make up their target market.
Regression analysis shows the effect of independent variables on a dependent variable. For example, a rental car company may use regression analysis to determine the relationship between wait times and number of bad reviews.
Diagnostic analysis: Why did it happen?
Diagnostic analysis, also referred to as root cause analysis, uncovers the causes of certain events or results.
Here are a few methods used to perform diagnostic analysis:
Time-series analysis analyzes data collected over a period of time. A retail store may use time-series analysis to determine that sales increase between October and December every year.
Data drilling uses business intelligence (BI) to show a more detailed view of data. For example, a business owner could use data drilling to see a detailed view of sales by state to determine if certain regions are driving increased sales.
Correlation analysis determines the strength of the relationship between variables. For example, a local ice cream shop may determine that as the temperature in the area rises, so do ice cream sales.
Predictive analysis: What is likely to happen?
Predictive analysis aims to anticipate future developments and events. By analyzing past data, companies can predict future scenarios and make strategic decisions.
Here are a few methods used to perform predictive analysis:
Machine learning uses AI and algorithms to predict outcomes. For example, search engines employ machine learning to recommend products to online shoppers that they are likely to buy based on their browsing history.
Decision trees map out possible courses of action and outcomes. For example, a business may use a decision tree when deciding whether to downsize or expand.
Prescriptive analysis: What action should we take?
The highest level of analysis, prescriptive analysis, aims to find the best action plan. Typically, AI tools model different outcomes to predict the best approach. While these tools serve to provide insight, they don't replace human consideration, so always use your human brain before going with the conclusion of your prescriptive analysis. Otherwise, your GPS might drive you into a lake.
Here are a few methods used to perform prescriptive analysis:
Lead scoring is used in sales departments to assign values to leads based on their perceived interest. For example, a sales team uses lead scoring to rank leads on a scale of 1-100 depending on the actions they take (e.g., opening an email or downloading an eBook). They then prioritize the leads that are most likely to convert.
Algorithms are used in technology to perform specific tasks. For example, banks use prescriptive algorithms to monitor customers' spending and recommend that they deactivate their credit card if fraud is suspected.
The actual analysis is just one step in a much bigger process of using data to move your business forward. Here's a quick look at all the steps you need to take to make sure you're making informed decisions.

Data decision
As with almost any project, the first step is to determine what problem you're trying to solve through data analysis.
Make sure you get specific here. For example, a food delivery service may want to understand why customers are canceling their subscriptions. But to enable the most effective data analysis, they should pose a more targeted question, such as "How can we reduce customer churn without raising costs?"
These questions will help you determine your KPIs and what type(s) of data analysis you'll conduct , so spend time honing the question—otherwise your analysis won't provide the actionable insights you want.
Data collection
Next, collect the required data from both internal and external sources.
Internal data comes from within your business (think CRM software, internal reports, and archives), and helps you understand your business and processes.
External data originates from outside of the company (surveys, questionnaires, public data) and helps you understand your industry and your customers.
You'll rely heavily on software for this part of the process. Your analytics or business dashboard tool, along with reports from any other internal tools like CRMs , will give you the internal data. For external data, you'll use survey apps and other data collection tools to get the information you need.
Data cleaning
Data can be seriously misleading if it's not clean. So before you analyze, make sure you review the data you collected. Depending on the type of data you have, cleanup will look different, but it might include:
Removing unnecessary information
Addressing structural errors like misspellings
Deleting duplicates
Trimming whitespace
Human checking for accuracy
You can use your spreadsheet's cleanup suggestions to quickly and effectively clean data, but a human review is always important.
Data analysis
Now that you've compiled and cleaned the data, use one or more of the above types of data analysis to find relationships, patterns, and trends.
Data analysis tools can speed up the data analysis process and remove the risk of inevitable human error. Here are some examples.
Spreadsheets sort, filter, analyze, and visualize data.
Business intelligence platforms model data and create dashboards.
Structured query language (SQL) tools manage and extract data in relational databases.
Data interpretation
After you analyze the data, you'll need to go back to the original question you posed and draw conclusions from your findings. Here are some common pitfalls to avoid:
Correlation vs. causation: Just because two variables are associated doesn't mean they're necessarily related or dependent on one another.
Confirmation bias: This occurs when you interpret data in a way that confirms your own preconceived notions. To avoid this, have multiple people interpret the data.
Small sample size: If your sample size is too small or doesn't represent the demographics of your customers, you may get misleading results. If you run into this, consider widening your sample size to give you a more accurate representation.
Data visualization
Last but not least, visualizing the data in the form of graphs, maps, reports, charts, and dashboards can help you explain your findings to decision-makers and stakeholders. While it's not absolutely necessary, it will help tell the story of your data in a way that everyone in the business can understand and make decisions based on.
Automate your data collection
Data doesn't live in one place. To make sure data is where it needs to be—and isn't duplicative or conflicting—make sure all your apps talk to each other. Zapier automates the process of moving data from one place to another, so you can focus on the work that matters to move your business forward.
Need a quick summary or still have a few nagging data analysis questions? I'm here for you.
What are the five types of data analysis?
The five types of data analysis are text analysis, statistical analysis, diagnostic analysis, predictive analysis, and prescriptive analysis. Each type offers a unique lens for understanding data: text analysis provides insights into text-based content, statistical analysis focuses on numerical trends, diagnostic analysis looks into problem causes, predictive analysis deals with what may happen in the future, and prescriptive analysis gives actionable recommendations.
What is the data analysis process?
The data analysis process involves data decision, collection, cleaning, analysis, interpretation, and visualization. Every stage comes together to transform raw data into meaningful insights. Decision determines what data to collect, collection gathers the relevant information, cleaning ensures accuracy, analysis uncovers patterns, interpretation assigns meaning, and visualization presents the insights.
What is the main purpose of data analysis?
In business, the main purpose of data analysis is to uncover patterns, trends, and anomalies, and then use that information to make decisions, solve problems, and reach your business goals.
Related reading:
How to get started with data collection and analytics at your business
How to conduct your own market research survey
Automatically find and match related data across apps
How to build an analysis assistant with ChatGPT
What can the ChatGPT data analysis chatbot do?
This article was originally published in October 2022 and has since been updated with contributions from Cecilia Gillen. The most recent update was in September 2023.
Get productivity tips delivered straight to your inbox
We’ll email you 1-3 times per week—and never share your information.

Shea Stevens
Shea is a content writer currently living in Charlotte, North Carolina. After graduating with a degree in Marketing from East Carolina University, she joined the digital marketing industry focusing on content and social media. In her free time, you can find Shea visiting her local farmers market, attending a country music concert, or planning her next adventure.
- Data & analytics
- Small business

Data extraction is the process of taking actionable information from larger, less structured sources to be further refined or analyzed. Here's how to do it.
Related articles

How to create a sales plan (and 3 templates that do it for you)
How to create a sales plan (and 3 templates...

How to build a B2B prospecting list for cold email campaigns
How to build a B2B prospecting list for cold...

The only Gantt chart template you'll ever need for Excel (and how to automate it)
The only Gantt chart template you'll ever...

6 ways to break down organizational silos
Improve your productivity automatically. Use Zapier to get your apps working together.


Analyze Report: How to Write the Best Analytical Report (+ 6 Examples!)
By Varun Saharawat | March 1, 2024
Organizations analyze reports to improve performance by identifying areas of strength and weakness, understanding customer needs and preferences, optimizing business processes, and making data-driven decisions!

Analyze Report: Picture a heap of bricks scattered on the ground. Individually, they lack purpose until meticulously assembled into a cohesive structure—a house, perhaps?
In the realm of business intelligence , data serves as the fundamental building material, with a well-crafted data analysis report serving as the ultimate desired outcome.
However, if you’ve ever attempted to harness collected data and transform it into an insightful report, you understand the inherent challenges. Bridging the gap between raw, unprocessed data and a coherent narrative capable of informing actionable strategies is no simple feat.
Table of Contents
What is an Analyze Report?
An analytical report serves as a crucial tool for stakeholders to make informed decisions and determine the most effective course of action. For instance, a Chief Marketing Officer (CMO) might refer to a business executive analytical report to identify specific issues caused by the pandemic before adapting an existing marketing strategy.
Marketers often utilize business intelligence tools to generate these informative reports. They vary in layout, ranging from text-heavy documents (such as those created in Google Docs with screenshots or Excel spreadsheets) to visually engaging presentations.
A quick search on Google reveals that many marketers opt for text-heavy documents with a formal writing style, often featuring a table of contents on the first page. In some instances, such as the analytical report example provided below, these reports may consist of spreadsheets filled with numbers and screenshots, providing a comprehensive overview of the data.
Also Read: The Best Business Intelligence Software in 2024
How to Write an Analyze Report?
Writing an Analyze Report requires careful planning, data analysis , and clear communication of findings. Here’s a step-by-step guide to help you write an effective analytical report:
Step 1: Define the Purpose:
- Clearly define the objective and purpose of the report. Determine what problem or question the report aims to address.
- Consider the audience for the report and what information they need to make informed decisions.
Step 2: Gather Data:
- Identify relevant sources of data that can provide insights into the topic.
- Collect data from primary sources (e.g., surveys, interviews) and secondary sources (e.g., research studies, industry reports).
- Ensure that the data collected is accurate, reliable, and up-to-date.
Step 3: Analyze the Data:
- Use analytical tools and techniques to analyze the data effectively. This may include statistical analysis, qualitative coding, or data visualization.
- Look for patterns, trends, correlations, and outliers in the data that may provide insights into the topic.
- Consider the context in which the data was collected and any limitations that may affect the analysis.
Step 4: Organize the Information:
- Structure the report in a logical and coherent manner. Divide the report into sections, such as an introduction, methodology, findings, analysis, and conclusion.
- Ensure that each section flows logically into the next and that there is a clear progression of ideas throughout the report.
Step 5: Write the Introduction:
- Start with an introduction that provides background information on the topic and outlines the scope of the report.
- Clearly state the purpose and objectives of the analysis.
- Provide context for the analysis and explain why it is relevant and important.
Step 6: Present the Methodology:
- Describe the methods and techniques used to gather and analyze the data.
- Explain any assumptions made and the rationale behind your approach.
- Provide sufficient detail so that the reader can understand how the analysis was conducted.
Step 7: Present the Findings:
- Present the findings of your analysis in a clear and concise manner.
- Use charts, graphs, tables, and other visual aids to illustrate key points and make the data easier to understand.
- Provide context for the findings and explain their significance.
Step 8: Analyze the Data:
- Interpret the findings and analyze their implications.
- Discuss any patterns, trends, or insights uncovered by the analysis and explain their significance.
- Consider alternative explanations or interpretations of the data.
Step 9: Draw Conclusions:
- Draw conclusions based on the analysis and findings.
- Summarize the main points and insights of the report.
- Reiterate the key takeaways and their implications for decision-making.
Step 10: Make Recommendations:
- Finally, make recommendations based on your conclusions.
- Suggest actionable steps that can be taken to address any issues identified or capitalize on any opportunities uncovered by the analysis.
- Provide specific, practical recommendations that are feasible and aligned with the objectives of the report.
Step 11: Proofread and Revise:
- Review the report for accuracy, clarity, and coherence.
- Ensure that the writing is clear, concise, and free of errors.
- Make any necessary revisions before finalizing the report.
Step 12: Write the Executive Summary:
- Write a brief executive summary that provides an overview of the report’s key findings, conclusions, and recommendations.
- This summary should be concise and easy to understand for busy stakeholders who may not have time to read the entire report.
- Include only the most important information and avoid unnecessary details.
By following these steps, you can write an analytical report that effectively communicates your findings and insights to your audience.
Also Read: Analytics For BI: What is Business Intelligence and Analytics?
Analyze Report Examples
Analyze Report play a crucial role in providing valuable insights to businesses, enabling informed decision-making and strategic planning. Here are some examples of analytical reports along with detailed descriptions:
1) Executive Report Template:
An executive report serves as a comprehensive overview of a company’s performance, specifically tailored for C-suite executives. This report typically includes key metrics and KPIs that provide insights into the organization’s financial health and operational efficiency. For example, the Highlights tab may showcase total revenue for a specific period, along with the breakdown of transactions and associated costs.
Additionally, the report may feature visualizations such as cost vs. revenue comparison charts, allowing executives to quickly identify trends and make data-driven decisions. With easy-to-understand graphs and charts, executives can expedite decision-making processes and adapt business strategies for effective cost containment and revenue growth.
2) Digital Marketing Report Template:
In today’s digital age, businesses rely heavily on digital marketing channels to reach their target audience and drive engagement. A digital marketing report provides insights into the performance of various marketing channels and campaigns, helping businesses optimize their marketing strategies for maximum impact.
This report typically includes key metrics such as website traffic, conversion rates, and ROI for each marketing channel. By analyzing these KPIs, businesses can identify their best-performing channels and allocate resources accordingly. For example, the report may reveal that certain channels, such as social media or email marketing, yield higher response rates than others. Armed with this information, businesses can refine their digital marketing efforts to enhance the user experience, attract more customers, and ultimately drive growth.
3) Sales Performance Report:
A sales performance report provides a detailed analysis of sales activities, including revenue generated, sales volume, customer acquisition, and sales team performance. This report typically includes visualizations such as sales trend charts, pipeline analysis, and territory-wise sales comparisons. By analyzing these metrics, sales managers can identify top-performing products or services, track sales targets, and identify areas for improvement.
4) Customer Satisfaction Report:
A customer satisfaction report evaluates customer feedback and sentiment to measure overall satisfaction levels with products or services. This report may include metrics such as Net Promoter Score (NPS), customer survey results, and customer support ticket data. By analyzing these metrics, businesses can identify areas where they excel and areas where they need to improve to enhance the overall customer experience.
5) Financial Performance Report:
A financial performance report provides an in-depth analysis of an organization’s financial health, including revenue, expenses, profitability, and cash flow. This report may include financial ratios, trend analysis, and variance reports to assess performance against budgeted targets or industry benchmarks. By analyzing these metrics, financial managers can identify areas of strength and weakness and make strategic decisions to improve financial performance .
6) Inventory Management Report:
An inventory management report tracks inventory levels, turnover rates, stockouts, and inventory costs to optimize inventory management processes. This report may include metrics such as inventory turnover ratio, carrying costs, and stock-to-sales ratios. By analyzing these metrics, inventory managers can ensure optimal inventory levels, minimize stockouts, and reduce carrying costs to improve overall operational efficiency.
7) Employee Performance Report:
An employee performance report evaluates individual and team performance based on key performance indicators (KPIs) such as sales targets, customer satisfaction scores, productivity metrics, and attendance records. This report may include visualizations such as performance scorecards, heatmaps, and trend analysis charts to identify top performers, areas for improvement, and training needs.
Also Check: Analytics & Insights: The Difference Between Data, Analytics, and Insights
Why are Analyze Report Important?
Analyze Report are important for several reasons:
- Informed Decision Making: Analytical reports provide valuable insights and data-driven analysis that enable businesses to make informed decisions. By presenting relevant information in a structured format, these reports help stakeholders understand trends, identify patterns, and evaluate potential courses of action.
- Problem Solving: Analytical reports help organizations identify and address challenges or issues within their operations. Whether it’s identifying inefficiencies in processes, addressing customer complaints, or mitigating risks, these reports provide a framework for problem-solving and decision-making.
- Business Opportunities: Analytical reports can uncover new business opportunities by analyzing market trends, customer behavior, and competitor activities. By identifying emerging trends or unmet customer needs, businesses can capitalize on opportunities for growth and innovation.
- Performance Evaluation: Analytical reports are instrumental in evaluating the performance of various aspects of a business, such as sales, marketing campaigns, and financial metrics. By tracking key performance indicators (KPIs) and metrics, organizations can assess their progress towards goals and objectives.
- Accountability and Transparency: Analytical reports promote accountability and transparency within an organization by providing objective data and analysis. By sharing insights and findings with stakeholders, businesses can foster trust and confidence in their decision-making processes.
Overall, analytical reports serve as valuable tools for businesses to gain insights, solve problems, identify opportunities, evaluate performance, and enhance decision-making processes.
Types of Analyze Report
- Financial Analyze Report: These reports analyze the financial performance of an organization, including revenue, expenses, profitability, and cash flow. They help stakeholders understand the financial health of the business and make informed decisions about investments, budgeting, and strategic planning.
- Market Research Reports: Market research reports analyze market trends, consumer behavior, competitive landscape, and other factors affecting a particular industry or market segment. They provide valuable insights for businesses looking to launch new products, enter new markets, or refine their marketing strategies .
- Performance Analysis Reports: These reports evaluate the performance of various aspects of an organization, such as sales performance, operational efficiency, employee productivity, and customer satisfaction. They help identify areas of improvement and inform decision-making to enhance overall performance.
- Risk Assessment Reports: Risk assessment reports analyze potential risks and vulnerabilities within an organization, such as financial risks, operational risks, cybersecurity risks, and regulatory compliance risks. They help stakeholders understand and mitigate risks to protect the organization’s assets and reputation.
- SWOT Analysis Reports: SWOT (Strengths, Weaknesses, Opportunities, Threats) analysis reports assess the internal strengths and weaknesses of an organization, as well as external opportunities and threats in the business environment. They provide a comprehensive overview of the organization’s strategic position and guide decision-making.
- Customer Analysis Reports: Customer analysis reports examine customer demographics, purchasing behavior, satisfaction levels, and preferences. They help businesses understand their target audience better, tailor products and services to meet customer needs, and improve customer retention and loyalty.
- Operational Efficiency Reports: These reports evaluate the efficiency and effectiveness of operational processes within an organization, such as production, logistics, and supply chain management. They identify bottlenecks, inefficiencies, and areas for improvement to optimize operations and reduce costs.
- Compliance and Regulatory Reports: Compliance and regulatory reports assess an organization’s adherence to industry regulations, legal requirements, and internal policies. They ensure that the organization operates ethically and legally, mitigating the risk of fines, penalties, and reputational damage.
For Latest Tech Related Information, Join Our Official Free Telegram Group : PW Skills Telegram Group
Analyze Report FAQs
What is an analytical report.
An analytical report is a document that presents data, analysis, and insights on a specific topic or problem. It provides a detailed examination of information to support decision-making and problem-solving within an organization.
Why are analytical reports important?
Analytical reports are important because they help organizations make informed decisions, solve problems, and identify opportunities for improvement. By analyzing data and providing insights, these reports enable stakeholders to understand trends, patterns, and relationships within their business operations.
What types of data are typically included in analytical reports?
Analytical reports may include various types of data, such as financial data, sales data, customer feedback, market research, and operational metrics. The specific data included depends on the purpose of the report and the information needed to address the topic or problem being analyzed.
How are analytical reports different from other types of reports?
Analytical reports differ from other types of reports, such as descriptive reports or summary reports, in that they go beyond presenting raw data or summarizing information. Instead, analytical reports analyze data in-depth, draw conclusions, and provide recommendations based on the analysis.
What are the key components of an analytical report?
Key components of an analytical report typically include an introduction, methodology, findings, analysis, conclusions, and recommendations. The introduction provides background information on the topic, the methodology outlines the approach used to analyze the data, the findings present the results of the analysis, the analysis interprets the findings, and the conclusions and recommendations offer insights and actionable steps.
Data Mining Architecture: Components, Types & Techniques

Comprehensive Data Analytics Syllabus: Courses and Curriculum

Google Data Analytics Professional Certificate Review, Cost, Eligibility 2023

- Skip to main content
- Skip to secondary menu
- Skip to primary sidebar
- Skip to footer
Data and Technology Insights
How to Write a Data Analysis Report

Datafloq AI Score: 80
Datafloq enables anyone to contribute articles, but we value high-quality content. This means that we do not accept SEO link building content, spammy articles, clickbait, articles written by bots and especially not misinformation. Therefore, we have developed an AI, built using multiple built open-source and proprietary tools to instantly define whether an article is written by a human or a bot and determine the level of bias, objectivity, whether it is fact-based or not, sentiment and overall quality.
Articles published on Datafloq need to have a minimum AI score of 60% and we provide this graph to give more detailed information on how we rate this article. Please note that this is a work in progress and if you have any suggestions, feel free to contact us .

Lets face it, data analysis reports, whether youre writing them for universities or for big data , are intimidating. Theyre also not a great deal of fun to write. I asked some people where theyd rank writing one and it came in just above going to the dentist. Thats not a good place to find yourself (and here Im talking both about the list and the chair).
You know what the crazy thing is? Theyre actually not that hard to write! Like so many things in life you just need to know where to start. For that reason, I thought Id write you up a quick article so that the next time you at least know how to get it over with as quickly as possible. And then, maybe youll start to enjoy it more and it will become only as unpleasant as being woken by your neighbor drilling holes in the wall. We can only hope, right?
There is no one right way
The first thing youve got to realize is that there is not yet one way to present your data. Admittedly, thats unfortunate. It would probably be helpful for everybody if there was some standard way to do these things. Thats not the case, however. Nor will it happen soon, as different companies , sectors and data presenters want to do entirely different things.
What that means is that there is no official wrong way. These are of course the unofficial one, which is where you hand over your 10,000-word report, people stare at it for a while, point to the first sentence and ask what does that mean?
Follow by example
The best thing to do is to find data analyses reports that you yourself find clear and easy to understand and to not just read them, but keep them on file . Then, when youre writing up a report, pull out one that is close to what youre trying to do and follow their example as closely as possible. This works surprisingly well, particularly if youre not that confident what youre doing is the right way to do things.
Whats more, if you do this a number of times without doing anything else, youll still start noticing underlying patterns and ideas that you can use .
Dont be afraid to ask
There are tons of very smart people online at such places as Quora and Linkedin Groups who are willing to answer even the most complicated questions , provided youve demonstrated youve at least tried to understand the concepts.
So no asking how do I write a data report? as then people will call you lazy. If on the other hand, you want to know if you should use a regression or a Linear Model for a specific analysis, then theyll gladly answer that for you.
Pay attention to the right criticism
Note that quite often youre going to get criticized. Thats just the name of the game. There are always people out there with opinions and the desire to share them. Make sure you pay attention to the right ones.
If the person delivering the criticism has no understanding of data or how to present it (and lets face it, there are a lot of those) then you can generally simply say thank you for them being so kind as to give their opinions and move on. Of course, if the person that is doing the criticizing is paying for the report, thats a different story. Unfortunately, then youre going to have to accommodate their criticism.
Know your content
When youre going to write a data report, make sure that you know the content . With that, I mean that youve actually been the one to do the analysis. It should always be the person who has done the analyses that write the content. Only in that way can you be sure that the data presentation isnt distorted.
Interested in what the future will bring? Download our 2023 Technology Trends eBook for free.
Start out by describing the data. Who was the population you analyzed? How did you collect the data? What were the conditions, if any, for you excluding samples from your data set? Did excluding them make a substantial difference to your results?
At the same time, you dont want to go into too much detail here. Include whats relevant (how results changed as a result of different treatments) and ruthlessly cut down on whats not (what program you used).
Know what matters
A data report, just like any other report, has a message. It is trying to convey an idea. Of course, this is often more difficult when youre writing a data-driven report as data rarely cares about what you want to say and can therefore not fit your story exactly.
Nonetheless, you should focus on telling your stories (while not deleting the data-driven caveats). The natural structure of abstract, introduction, method, results, conclusion, thats generally used for these kinds of texts will help in that regard as it will steer your story.
The abstract is vital
A lot of students will write the abstract right at the end, when everything else is done and when theyre thinking about their friends down at the pub. Dont be like those students. The abstract is probably the most important part of your entire paper. Its certainly the part that is going to get read most.
The abstract is not a wow, pazaaz! piece. Youre not trying to impress your audience with it. Instead, youre trying to summarize the main findings of your data and the conclusions you draw from there. A well-written abstract will make the rest of the paper much easier to digest.
Remember to cater your abstract to your audience. If theyre looking to find out about a specific result, then include that! This way, what they want is right there at the beginning. Yes, that does make it less likely that theyll read the whole report, but then if you only have to explain the abstract, that makes life so much easier.
Numbers and words
Remember that not everybody understands data and what it means. For that reason, when you write out a result, dont just write it out in numbers, also write out the results in words. In fact, if you really want to do it correctly, you want to write it out twice the first time to translate the results into words pretty much one on one, the second time to explain what that actually means.
In this way, both the numerate and the number-illiterate will find it easy to understand what youre trying to say.
The most important thing to remember is that you can ask for help. If youre struggling with an analysis or how to write it out, go online and ask people! Youll be surprised how quickly people will get back to you if your question is specific enough.
Then, you can move forward confident in the knowledge that your report is as understandable as it can be. And thats a great feeling. And who knows, maybe once you stop being so intimidated by presenting the numbers, you can finally get that position as chief data officer !
About Pat Fredshaw
Pat Fredshaw is a passionate freelance writer and content editor at Essaysupply.com . She writes about digital marketing marketing, SEO, and blogging.
- 5 Reasons Why Modern Data Integration Gives You a Competitive Advantage
- 5 Most Common Database Structures for Small Businesses
- 6 Ways to Reduce IT Costs Through Observability
- How is Big Data Analytics Used in Business? These 5 Use Cases Share Valuable Insights
- How Realistic Are Self-Driving Cars?
Dear visitor, Thank you for visiting Datafloq. If you find our content interesting, please subscribe to our weekly newsletter:
Did you know that you can publish job posts for free on Datafloq? You can start immediately and find the best candidates for free! Click here to get started.
Thanks for visiting Datafloq If you enjoyed our content on emerging technologies, why not subscribe to our weekly newsletter to receive the latest news straight into your mailbox?
- Privacy Overview
- Necessary Cookies
- Marketing cookies
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.
This website uses Google Analytics to collect anonymous information such as the number of visitors to the site, and the most popular pages.
Keeping this cookie enabled helps us to improve our website.
Please enable Strictly Necessary Cookies first so that we can save your preferences!
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Data Analysis in Research: Types & Methods

Content Index
Why analyze data in research?
Types of data in research, finding patterns in the qualitative data, methods used for data analysis in qualitative research, preparing data for analysis, methods used for data analysis in quantitative research, considerations in research data analysis, what is data analysis in research.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense.
Three essential things occur during the data analysis process — the first is data organization . Summarization and categorization together contribute to becoming the second known method used for data reduction. It helps find patterns and themes in the data for easy identification and linking. The third and last way is data analysis – researchers do it in both top-down and bottom-up fashion.
LEARN ABOUT: Research Process Steps
On the other hand, Marshall and Rossman describe data analysis as a messy, ambiguous, and time-consuming but creative and fascinating process through which a mass of collected data is brought to order, structure and meaning.
We can say that “the data analysis and data interpretation is a process representing the application of deductive and inductive logic to the research and data analysis.”
Researchers rely heavily on data as they have a story to tell or research problems to solve. It starts with a question, and data is nothing but an answer to that question. But, what if there is no question to ask? Well! It is possible to explore data even without a problem – we call it ‘Data Mining’, which often reveals some interesting patterns within the data that are worth exploring.
Irrelevant to the type of data researchers explore, their mission and audiences’ vision guide them to find the patterns to shape the story they want to tell. One of the essential things expected from researchers while analyzing data is to stay open and remain unbiased toward unexpected patterns, expressions, and results. Remember, sometimes, data analysis tells the most unforeseen yet exciting stories that were not expected when initiating data analysis. Therefore, rely on the data you have at hand and enjoy the journey of exploratory research.
Create a Free Account
Every kind of data has a rare quality of describing things after assigning a specific value to it. For analysis, you need to organize these values, processed and presented in a given context, to make it useful. Data can be in different forms; here are the primary data types.
- Qualitative data: When the data presented has words and descriptions, then we call it qualitative data . Although you can observe this data, it is subjective and harder to analyze data in research, especially for comparison. Example: Quality data represents everything describing taste, experience, texture, or an opinion that is considered quality data. This type of data is usually collected through focus groups, personal qualitative interviews , qualitative observation or using open-ended questions in surveys.
- Quantitative data: Any data expressed in numbers of numerical figures are called quantitative data . This type of data can be distinguished into categories, grouped, measured, calculated, or ranked. Example: questions such as age, rank, cost, length, weight, scores, etc. everything comes under this type of data. You can present such data in graphical format, charts, or apply statistical analysis methods to this data. The (Outcomes Measurement Systems) OMS questionnaires in surveys are a significant source of collecting numeric data.
- Categorical data: It is data presented in groups. However, an item included in the categorical data cannot belong to more than one group. Example: A person responding to a survey by telling his living style, marital status, smoking habit, or drinking habit comes under the categorical data. A chi-square test is a standard method used to analyze this data.
Learn More : Examples of Qualitative Data in Education
Data analysis in qualitative research
Data analysis and qualitative data research work a little differently from the numerical data as the quality data is made up of words, descriptions, images, objects, and sometimes symbols. Getting insight from such complicated information is a complicated process. Hence it is typically used for exploratory research and data analysis .
Although there are several ways to find patterns in the textual information, a word-based method is the most relied and widely used global technique for research and data analysis. Notably, the data analysis process in qualitative research is manual. Here the researchers usually read the available data and find repetitive or commonly used words.
For example, while studying data collected from African countries to understand the most pressing issues people face, researchers might find “food” and “hunger” are the most commonly used words and will highlight them for further analysis.
LEARN ABOUT: Level of Analysis
The keyword context is another widely used word-based technique. In this method, the researcher tries to understand the concept by analyzing the context in which the participants use a particular keyword.
For example , researchers conducting research and data analysis for studying the concept of ‘diabetes’ amongst respondents might analyze the context of when and how the respondent has used or referred to the word ‘diabetes.’
The scrutiny-based technique is also one of the highly recommended text analysis methods used to identify a quality data pattern. Compare and contrast is the widely used method under this technique to differentiate how a specific text is similar or different from each other.
For example: To find out the “importance of resident doctor in a company,” the collected data is divided into people who think it is necessary to hire a resident doctor and those who think it is unnecessary. Compare and contrast is the best method that can be used to analyze the polls having single-answer questions types .
Metaphors can be used to reduce the data pile and find patterns in it so that it becomes easier to connect data with theory.
Variable Partitioning is another technique used to split variables so that researchers can find more coherent descriptions and explanations from the enormous data.
LEARN ABOUT: Qualitative Research Questions and Questionnaires
There are several techniques to analyze the data in qualitative research, but here are some commonly used methods,
- Content Analysis: It is widely accepted and the most frequently employed technique for data analysis in research methodology. It can be used to analyze the documented information from text, images, and sometimes from the physical items. It depends on the research questions to predict when and where to use this method.
- Narrative Analysis: This method is used to analyze content gathered from various sources such as personal interviews, field observation, and surveys . The majority of times, stories, or opinions shared by people are focused on finding answers to the research questions.
- Discourse Analysis: Similar to narrative analysis, discourse analysis is used to analyze the interactions with people. Nevertheless, this particular method considers the social context under which or within which the communication between the researcher and respondent takes place. In addition to that, discourse analysis also focuses on the lifestyle and day-to-day environment while deriving any conclusion.
- Grounded Theory: When you want to explain why a particular phenomenon happened, then using grounded theory for analyzing quality data is the best resort. Grounded theory is applied to study data about the host of similar cases occurring in different settings. When researchers are using this method, they might alter explanations or produce new ones until they arrive at some conclusion.
LEARN ABOUT: 12 Best Tools for Researchers
Data analysis in quantitative research
The first stage in research and data analysis is to make it for the analysis so that the nominal data can be converted into something meaningful. Data preparation consists of the below phases.
Phase I: Data Validation
Data validation is done to understand if the collected data sample is per the pre-set standards, or it is a biased data sample again divided into four different stages
- Fraud: To ensure an actual human being records each response to the survey or the questionnaire
- Screening: To make sure each participant or respondent is selected or chosen in compliance with the research criteria
- Procedure: To ensure ethical standards were maintained while collecting the data sample
- Completeness: To ensure that the respondent has answered all the questions in an online survey. Else, the interviewer had asked all the questions devised in the questionnaire.
Phase II: Data Editing
More often, an extensive research data sample comes loaded with errors. Respondents sometimes fill in some fields incorrectly or sometimes skip them accidentally. Data editing is a process wherein the researchers have to confirm that the provided data is free of such errors. They need to conduct necessary checks and outlier checks to edit the raw edit and make it ready for analysis.
Phase III: Data Coding
Out of all three, this is the most critical phase of data preparation associated with grouping and assigning values to the survey responses . If a survey is completed with a 1000 sample size, the researcher will create an age bracket to distinguish the respondents based on their age. Thus, it becomes easier to analyze small data buckets rather than deal with the massive data pile.
LEARN ABOUT: Steps in Qualitative Research
After the data is prepared for analysis, researchers are open to using different research and data analysis methods to derive meaningful insights. For sure, statistical analysis plans are the most favored to analyze numerical data. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities. The method is again classified into two groups. First, ‘Descriptive Statistics’ used to describe data. Second, ‘Inferential statistics’ that helps in comparing the data .
Descriptive statistics
This method is used to describe the basic features of versatile types of data in research. It presents the data in such a meaningful way that pattern in the data starts making sense. Nevertheless, the descriptive analysis does not go beyond making conclusions. The conclusions are again based on the hypothesis researchers have formulated so far. Here are a few major types of descriptive analysis methods.
Measures of Frequency
- Count, Percent, Frequency
- It is used to denote home often a particular event occurs.
- Researchers use it when they want to showcase how often a response is given.
Measures of Central Tendency
- Mean, Median, Mode
- The method is widely used to demonstrate distribution by various points.
- Researchers use this method when they want to showcase the most commonly or averagely indicated response.
Measures of Dispersion or Variation
- Range, Variance, Standard deviation
- Here the field equals high/low points.
- Variance standard deviation = difference between the observed score and mean
- It is used to identify the spread of scores by stating intervals.
- Researchers use this method to showcase data spread out. It helps them identify the depth until which the data is spread out that it directly affects the mean.
Measures of Position
- Percentile ranks, Quartile ranks
- It relies on standardized scores helping researchers to identify the relationship between different scores.
- It is often used when researchers want to compare scores with the average count.
For quantitative research use of descriptive analysis often give absolute numbers, but the in-depth analysis is never sufficient to demonstrate the rationale behind those numbers. Nevertheless, it is necessary to think of the best method for research and data analysis suiting your survey questionnaire and what story researchers want to tell. For example, the mean is the best way to demonstrate the students’ average scores in schools. It is better to rely on the descriptive statistics when the researchers intend to keep the research or outcome limited to the provided sample without generalizing it. For example, when you want to compare average voting done in two different cities, differential statistics are enough.
Descriptive analysis is also called a ‘univariate analysis’ since it is commonly used to analyze a single variable.
Inferential statistics
Inferential statistics are used to make predictions about a larger population after research and data analysis of the representing population’s collected sample. For example, you can ask some odd 100 audiences at a movie theater if they like the movie they are watching. Researchers then use inferential statistics on the collected sample to reason that about 80-90% of people like the movie.
Here are two significant areas of inferential statistics.
- Estimating parameters: It takes statistics from the sample research data and demonstrates something about the population parameter.
- Hypothesis test: I t’s about sampling research data to answer the survey research questions. For example, researchers might be interested to understand if the new shade of lipstick recently launched is good or not, or if the multivitamin capsules help children to perform better at games.
These are sophisticated analysis methods used to showcase the relationship between different variables instead of describing a single variable. It is often used when researchers want something beyond absolute numbers to understand the relationship between variables.
Here are some of the commonly used methods for data analysis in research.
- Correlation: When researchers are not conducting experimental research or quasi-experimental research wherein the researchers are interested to understand the relationship between two or more variables, they opt for correlational research methods.
- Cross-tabulation: Also called contingency tables, cross-tabulation is used to analyze the relationship between multiple variables. Suppose provided data has age and gender categories presented in rows and columns. A two-dimensional cross-tabulation helps for seamless data analysis and research by showing the number of males and females in each age category.
- Regression analysis: For understanding the strong relationship between two variables, researchers do not look beyond the primary and commonly used regression analysis method, which is also a type of predictive analysis used. In this method, you have an essential factor called the dependent variable. You also have multiple independent variables in regression analysis. You undertake efforts to find out the impact of independent variables on the dependent variable. The values of both independent and dependent variables are assumed as being ascertained in an error-free random manner.
- Frequency tables: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Analysis of variance: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Researchers must have the necessary research skills to analyze and manipulation the data , Getting trained to demonstrate a high standard of research practice. Ideally, researchers must possess more than a basic understanding of the rationale of selecting one statistical method over the other to obtain better data insights.
- Usually, research and data analytics projects differ by scientific discipline; therefore, getting statistical advice at the beginning of analysis helps design a survey questionnaire, select data collection methods, and choose samples.
LEARN ABOUT: Best Data Collection Tools
- The primary aim of data research and analysis is to derive ultimate insights that are unbiased. Any mistake in or keeping a biased mind to collect data, selecting an analysis method, or choosing audience sample il to draw a biased inference.
- Irrelevant to the sophistication used in research data and analysis is enough to rectify the poorly defined objective outcome measurements. It does not matter if the design is at fault or intentions are not clear, but lack of clarity might mislead readers, so avoid the practice.
- The motive behind data analysis in research is to present accurate and reliable data. As far as possible, avoid statistical errors, and find a way to deal with everyday challenges like outliers, missing data, data altering, data mining , or developing graphical representation.
LEARN MORE: Descriptive Research vs Correlational Research The sheer amount of data generated daily is frightening. Especially when data analysis has taken center stage. in 2018. In last year, the total data supply amounted to 2.8 trillion gigabytes. Hence, it is clear that the enterprises willing to survive in the hypercompetitive world must possess an excellent capability to analyze complex research data, derive actionable insights, and adapt to the new market needs.
LEARN ABOUT: Average Order Value
QuestionPro is an online survey platform that empowers organizations in data analysis and research and provides them a medium to collect data by creating appealing surveys.
MORE LIKE THIS

In-App Feedback Tools: How to Collect, Uses & 14 Best Tools
Mar 29, 2024

11 Best Customer Journey Analytics Software in 2024

17 Best VOC Software for Customer Experience in 2024
Mar 28, 2024

CEM Software: What it is, 7 Best CEM Software in 2024
Other categories.
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
- AI & NLP
- Churn & Loyalty
- Customer Experience
- Customer Journeys
- Customer Metrics
- Feedback Analysis
- Product Experience
- Product Updates
- Sentiment Analysis
- Surveys & Feedback Collection
- Try Thematic
Welcome to the community

Qualitative Data Analysis: Step-by-Step Guide (Manual vs. Automatic)
When we conduct qualitative methods of research, need to explain changes in metrics or understand people's opinions, we always turn to qualitative data. Qualitative data is typically generated through:
- Interview transcripts
- Surveys with open-ended questions
- Contact center transcripts
- Texts and documents
- Audio and video recordings
- Observational notes
Compared to quantitative data, which captures structured information, qualitative data is unstructured and has more depth. It can answer our questions, can help formulate hypotheses and build understanding.
It's important to understand the differences between quantitative data & qualitative data . But unfortunately, analyzing qualitative data is difficult. While tools like Excel, Tableau and PowerBI crunch and visualize quantitative data with ease, there are a limited number of mainstream tools for analyzing qualitative data . The majority of qualitative data analysis still happens manually.
That said, there are two new trends that are changing this. First, there are advances in natural language processing (NLP) which is focused on understanding human language. Second, there is an explosion of user-friendly software designed for both researchers and businesses. Both help automate the qualitative data analysis process.
In this post we want to teach you how to conduct a successful qualitative data analysis. There are two primary qualitative data analysis methods; manual & automatic. We will teach you how to conduct the analysis manually, and also, automatically using software solutions powered by NLP. We’ll guide you through the steps to conduct a manual analysis, and look at what is involved and the role technology can play in automating this process.
More businesses are switching to fully-automated analysis of qualitative customer data because it is cheaper, faster, and just as accurate. Primarily, businesses purchase subscriptions to feedback analytics platforms so that they can understand customer pain points and sentiment.

We’ll take you through 5 steps to conduct a successful qualitative data analysis. Within each step we will highlight the key difference between the manual, and automated approach of qualitative researchers. Here's an overview of the steps:
The 5 steps to doing qualitative data analysis
- Gathering and collecting your qualitative data
- Organizing and connecting into your qualitative data
- Coding your qualitative data
- Analyzing the qualitative data for insights
- Reporting on the insights derived from your analysis
What is Qualitative Data Analysis?
Qualitative data analysis is a process of gathering, structuring and interpreting qualitative data to understand what it represents.
Qualitative data is non-numerical and unstructured. Qualitative data generally refers to text, such as open-ended responses to survey questions or user interviews, but also includes audio, photos and video.
Businesses often perform qualitative data analysis on customer feedback. And within this context, qualitative data generally refers to verbatim text data collected from sources such as reviews, complaints, chat messages, support centre interactions, customer interviews, case notes or social media comments.
How is qualitative data analysis different from quantitative data analysis?
Understanding the differences between quantitative & qualitative data is important. When it comes to analyzing data, Qualitative Data Analysis serves a very different role to Quantitative Data Analysis. But what sets them apart?
Qualitative Data Analysis dives into the stories hidden in non-numerical data such as interviews, open-ended survey answers, or notes from observations. It uncovers the ‘whys’ and ‘hows’ giving a deep understanding of people’s experiences and emotions.
Quantitative Data Analysis on the other hand deals with numerical data, using statistics to measure differences, identify preferred options, and pinpoint root causes of issues. It steps back to address questions like "how many" or "what percentage" to offer broad insights we can apply to larger groups.
In short, Qualitative Data Analysis is like a microscope, helping us understand specific detail. Quantitative Data Analysis is like the telescope, giving us a broader perspective. Both are important, working together to decode data for different objectives.
Qualitative Data Analysis methods
Once all the data has been captured, there are a variety of analysis techniques available and the choice is determined by your specific research objectives and the kind of data you’ve gathered. Common qualitative data analysis methods include:
Content Analysis
This is a popular approach to qualitative data analysis. Other qualitative analysis techniques may fit within the broad scope of content analysis. Thematic analysis is a part of the content analysis. Content analysis is used to identify the patterns that emerge from text, by grouping content into words, concepts, and themes. Content analysis is useful to quantify the relationship between all of the grouped content. The Columbia School of Public Health has a detailed breakdown of content analysis .
Narrative Analysis
Narrative analysis focuses on the stories people tell and the language they use to make sense of them. It is particularly useful in qualitative research methods where customer stories are used to get a deep understanding of customers’ perspectives on a specific issue. A narrative analysis might enable us to summarize the outcomes of a focused case study.
Discourse Analysis
Discourse analysis is used to get a thorough understanding of the political, cultural and power dynamics that exist in specific situations. The focus of discourse analysis here is on the way people express themselves in different social contexts. Discourse analysis is commonly used by brand strategists who hope to understand why a group of people feel the way they do about a brand or product.
Thematic Analysis
Thematic analysis is used to deduce the meaning behind the words people use. This is accomplished by discovering repeating themes in text. These meaningful themes reveal key insights into data and can be quantified, particularly when paired with sentiment analysis . Often, the outcome of thematic analysis is a code frame that captures themes in terms of codes, also called categories. So the process of thematic analysis is also referred to as “coding”. A common use-case for thematic analysis in companies is analysis of customer feedback.
Grounded Theory
Grounded theory is a useful approach when little is known about a subject. Grounded theory starts by formulating a theory around a single data case. This means that the theory is “grounded”. Grounded theory analysis is based on actual data, and not entirely speculative. Then additional cases can be examined to see if they are relevant and can add to the original grounded theory.

Challenges of Qualitative Data Analysis
While Qualitative Data Analysis offers rich insights, it comes with its challenges. Each unique QDA method has its unique hurdles. Let’s take a look at the challenges researchers and analysts might face, depending on the chosen method.
- Time and Effort (Narrative Analysis): Narrative analysis, which focuses on personal stories, demands patience. Sifting through lengthy narratives to find meaningful insights can be time-consuming, requires dedicated effort.
- Being Objective (Grounded Theory): Grounded theory, building theories from data, faces the challenges of personal biases. Staying objective while interpreting data is crucial, ensuring conclusions are rooted in the data itself.
- Complexity (Thematic Analysis): Thematic analysis involves identifying themes within data, a process that can be intricate. Categorizing and understanding themes can be complex, especially when each piece of data varies in context and structure. Thematic Analysis software can simplify this process.
- Generalizing Findings (Narrative Analysis): Narrative analysis, dealing with individual stories, makes drawing broad challenging. Extending findings from a single narrative to a broader context requires careful consideration.
- Managing Data (Thematic Analysis): Thematic analysis involves organizing and managing vast amounts of unstructured data, like interview transcripts. Managing this can be a hefty task, requiring effective data management strategies.
- Skill Level (Grounded Theory): Grounded theory demands specific skills to build theories from the ground up. Finding or training analysts with these skills poses a challenge, requiring investment in building expertise.
Benefits of qualitative data analysis
Qualitative Data Analysis (QDA) is like a versatile toolkit, offering a tailored approach to understanding your data. The benefits it offers are as diverse as the methods. Let’s explore why choosing the right method matters.
- Tailored Methods for Specific Needs: QDA isn't one-size-fits-all. Depending on your research objectives and the type of data at hand, different methods offer unique benefits. If you want emotive customer stories, narrative analysis paints a strong picture. When you want to explain a score, thematic analysis reveals insightful patterns
- Flexibility with Thematic Analysis: thematic analysis is like a chameleon in the toolkit of QDA. It adapts well to different types of data and research objectives, making it a top choice for any qualitative analysis.
- Deeper Understanding, Better Products: QDA helps you dive into people's thoughts and feelings. This deep understanding helps you build products and services that truly matches what people want, ensuring satisfied customers
- Finding the Unexpected: Qualitative data often reveals surprises that we miss in quantitative data. QDA offers us new ideas and perspectives, for insights we might otherwise miss.
- Building Effective Strategies: Insights from QDA are like strategic guides. They help businesses in crafting plans that match people’s desires.
- Creating Genuine Connections: Understanding people’s experiences lets businesses connect on a real level. This genuine connection helps build trust and loyalty, priceless for any business.
How to do Qualitative Data Analysis: 5 steps
Now we are going to show how you can do your own qualitative data analysis. We will guide you through this process step by step. As mentioned earlier, you will learn how to do qualitative data analysis manually , and also automatically using modern qualitative data and thematic analysis software.
To get best value from the analysis process and research process, it’s important to be super clear about the nature and scope of the question that’s being researched. This will help you select the research collection channels that are most likely to help you answer your question.
Depending on if you are a business looking to understand customer sentiment, or an academic surveying a school, your approach to qualitative data analysis will be unique.
Once you’re clear, there’s a sequence to follow. And, though there are differences in the manual and automatic approaches, the process steps are mostly the same.
The use case for our step-by-step guide is a company looking to collect data (customer feedback data), and analyze the customer feedback - in order to improve customer experience. By analyzing the customer feedback the company derives insights about their business and their customers. You can follow these same steps regardless of the nature of your research. Let’s get started.
Step 1: Gather your qualitative data and conduct research (Conduct qualitative research)
The first step of qualitative research is to do data collection. Put simply, data collection is gathering all of your data for analysis. A common situation is when qualitative data is spread across various sources.
Classic methods of gathering qualitative data
Most companies use traditional methods for gathering qualitative data: conducting interviews with research participants, running surveys, and running focus groups. This data is typically stored in documents, CRMs, databases and knowledge bases. It’s important to examine which data is available and needs to be included in your research project, based on its scope.
Using your existing qualitative feedback
As it becomes easier for customers to engage across a range of different channels, companies are gathering increasingly large amounts of both solicited and unsolicited qualitative feedback.
Most organizations have now invested in Voice of Customer programs , support ticketing systems, chatbot and support conversations, emails and even customer Slack chats.
These new channels provide companies with new ways of getting feedback, and also allow the collection of unstructured feedback data at scale.
The great thing about this data is that it contains a wealth of valubale insights and that it’s already there! When you have a new question about user behavior or your customers, you don’t need to create a new research study or set up a focus group. You can find most answers in the data you already have.
Typically, this data is stored in third-party solutions or a central database, but there are ways to export it or connect to a feedback analysis solution through integrations or an API.
Utilize untapped qualitative data channels
There are many online qualitative data sources you may not have considered. For example, you can find useful qualitative data in social media channels like Twitter or Facebook. Online forums, review sites, and online communities such as Discourse or Reddit also contain valuable data about your customers, or research questions.
If you are considering performing a qualitative benchmark analysis against competitors - the internet is your best friend. Gathering feedback in competitor reviews on sites like Trustpilot, G2, Capterra, Better Business Bureau or on app stores is a great way to perform a competitor benchmark analysis.
Customer feedback analysis software often has integrations into social media and review sites, or you could use a solution like DataMiner to scrape the reviews.

Step 2: Connect & organize all your qualitative data
Now you all have this qualitative data but there’s a problem, the data is unstructured. Before feedback can be analyzed and assigned any value, it needs to be organized in a single place. Why is this important? Consistency!
If all data is easily accessible in one place and analyzed in a consistent manner, you will have an easier time summarizing and making decisions based on this data.
The manual approach to organizing your data
The classic method of structuring qualitative data is to plot all the raw data you’ve gathered into a spreadsheet.
Typically, research and support teams would share large Excel sheets and different business units would make sense of the qualitative feedback data on their own. Each team collects and organizes the data in a way that best suits them, which means the feedback tends to be kept in separate silos.
An alternative and a more robust solution is to store feedback in a central database, like Snowflake or Amazon Redshift .
Keep in mind that when you organize your data in this way, you are often preparing it to be imported into another software. If you go the route of a database, you would need to use an API to push the feedback into a third-party software.
Computer-assisted qualitative data analysis software (CAQDAS)
Traditionally within the manual analysis approach (but not always), qualitative data is imported into CAQDAS software for coding.
In the early 2000s, CAQDAS software was popularised by developers such as ATLAS.ti, NVivo and MAXQDA and eagerly adopted by researchers to assist with the organizing and coding of data.
The benefits of using computer-assisted qualitative data analysis software:
- Assists in the organizing of your data
- Opens you up to exploring different interpretations of your data analysis
- Allows you to share your dataset easier and allows group collaboration (allows for secondary analysis)
However you still need to code the data, uncover the themes and do the analysis yourself. Therefore it is still a manual approach.

Organizing your qualitative data in a feedback repository
Another solution to organizing your qualitative data is to upload it into a feedback repository where it can be unified with your other data , and easily searchable and taggable. There are a number of software solutions that act as a central repository for your qualitative research data. Here are a couple solutions that you could investigate:
- Dovetail: Dovetail is a research repository with a focus on video and audio transcriptions. You can tag your transcriptions within the platform for theme analysis. You can also upload your other qualitative data such as research reports, survey responses, support conversations, and customer interviews. Dovetail acts as a single, searchable repository. And makes it easier to collaborate with other people around your qualitative research.
- EnjoyHQ: EnjoyHQ is another research repository with similar functionality to Dovetail. It boasts a more sophisticated search engine, but it has a higher starting subscription cost.
Organizing your qualitative data in a feedback analytics platform
If you have a lot of qualitative customer or employee feedback, from the likes of customer surveys or employee surveys, you will benefit from a feedback analytics platform. A feedback analytics platform is a software that automates the process of both sentiment analysis and thematic analysis . Companies use the integrations offered by these platforms to directly tap into their qualitative data sources (review sites, social media, survey responses, etc.). The data collected is then organized and analyzed consistently within the platform.
If you have data prepared in a spreadsheet, it can also be imported into feedback analytics platforms.
Once all this rich data has been organized within the feedback analytics platform, it is ready to be coded and themed, within the same platform. Thematic is a feedback analytics platform that offers one of the largest libraries of integrations with qualitative data sources.

Step 3: Coding your qualitative data
Your feedback data is now organized in one place. Either within your spreadsheet, CAQDAS, feedback repository or within your feedback analytics platform. The next step is to code your feedback data so we can extract meaningful insights in the next step.
Coding is the process of labelling and organizing your data in such a way that you can then identify themes in the data, and the relationships between these themes.
To simplify the coding process, you will take small samples of your customer feedback data, come up with a set of codes, or categories capturing themes, and label each piece of feedback, systematically, for patterns and meaning. Then you will take a larger sample of data, revising and refining the codes for greater accuracy and consistency as you go.
If you choose to use a feedback analytics platform, much of this process will be automated and accomplished for you.
The terms to describe different categories of meaning (‘theme’, ‘code’, ‘tag’, ‘category’ etc) can be confusing as they are often used interchangeably. For clarity, this article will use the term ‘code’.
To code means to identify key words or phrases and assign them to a category of meaning. “I really hate the customer service of this computer software company” would be coded as “poor customer service”.
How to manually code your qualitative data
- Decide whether you will use deductive or inductive coding. Deductive coding is when you create a list of predefined codes, and then assign them to the qualitative data. Inductive coding is the opposite of this, you create codes based on the data itself. Codes arise directly from the data and you label them as you go. You need to weigh up the pros and cons of each coding method and select the most appropriate.
- Read through the feedback data to get a broad sense of what it reveals. Now it’s time to start assigning your first set of codes to statements and sections of text.
- Keep repeating step 2, adding new codes and revising the code description as often as necessary. Once it has all been coded, go through everything again, to be sure there are no inconsistencies and that nothing has been overlooked.
- Create a code frame to group your codes. The coding frame is the organizational structure of all your codes. And there are two commonly used types of coding frames, flat, or hierarchical. A hierarchical code frame will make it easier for you to derive insights from your analysis.
- Based on the number of times a particular code occurs, you can now see the common themes in your feedback data. This is insightful! If ‘bad customer service’ is a common code, it’s time to take action.
We have a detailed guide dedicated to manually coding your qualitative data .

Using software to speed up manual coding of qualitative data
An Excel spreadsheet is still a popular method for coding. But various software solutions can help speed up this process. Here are some examples.
- CAQDAS / NVivo - CAQDAS software has built-in functionality that allows you to code text within their software. You may find the interface the software offers easier for managing codes than a spreadsheet.
- Dovetail/EnjoyHQ - You can tag transcripts and other textual data within these solutions. As they are also repositories you may find it simpler to keep the coding in one platform.
- IBM SPSS - SPSS is a statistical analysis software that may make coding easier than in a spreadsheet.
- Ascribe - Ascribe’s ‘Coder’ is a coding management system. Its user interface will make it easier for you to manage your codes.
Automating the qualitative coding process using thematic analysis software
In solutions which speed up the manual coding process, you still have to come up with valid codes and often apply codes manually to pieces of feedback. But there are also solutions that automate both the discovery and the application of codes.
Advances in machine learning have now made it possible to read, code and structure qualitative data automatically. This type of automated coding is offered by thematic analysis software .
Automation makes it far simpler and faster to code the feedback and group it into themes. By incorporating natural language processing (NLP) into the software, the AI looks across sentences and phrases to identify common themes meaningful statements. Some automated solutions detect repeating patterns and assign codes to them, others make you train the AI by providing examples. You could say that the AI learns the meaning of the feedback on its own.
Thematic automates the coding of qualitative feedback regardless of source. There’s no need to set up themes or categories in advance. Simply upload your data and wait a few minutes. You can also manually edit the codes to further refine their accuracy. Experiments conducted indicate that Thematic’s automated coding is just as accurate as manual coding .
Paired with sentiment analysis and advanced text analytics - these automated solutions become powerful for deriving quality business or research insights.
You could also build your own , if you have the resources!
The key benefits of using an automated coding solution
Automated analysis can often be set up fast and there’s the potential to uncover things that would never have been revealed if you had given the software a prescribed list of themes to look for.
Because the model applies a consistent rule to the data, it captures phrases or statements that a human eye might have missed.
Complete and consistent analysis of customer feedback enables more meaningful findings. Leading us into step 4.
Step 4: Analyze your data: Find meaningful insights
Now we are going to analyze our data to find insights. This is where we start to answer our research questions. Keep in mind that step 4 and step 5 (tell the story) have some overlap . This is because creating visualizations is both part of analysis process and reporting.
The task of uncovering insights is to scour through the codes that emerge from the data and draw meaningful correlations from them. It is also about making sure each insight is distinct and has enough data to support it.
Part of the analysis is to establish how much each code relates to different demographics and customer profiles, and identify whether there’s any relationship between these data points.
Manually create sub-codes to improve the quality of insights
If your code frame only has one level, you may find that your codes are too broad to be able to extract meaningful insights. This is where it is valuable to create sub-codes to your primary codes. This process is sometimes referred to as meta coding.
Note: If you take an inductive coding approach, you can create sub-codes as you are reading through your feedback data and coding it.
While time-consuming, this exercise will improve the quality of your analysis. Here is an example of what sub-codes could look like.

You need to carefully read your qualitative data to create quality sub-codes. But as you can see, the depth of analysis is greatly improved. By calculating the frequency of these sub-codes you can get insight into which customer service problems you can immediately address.
Correlate the frequency of codes to customer segments
Many businesses use customer segmentation . And you may have your own respondent segments that you can apply to your qualitative analysis. Segmentation is the practise of dividing customers or research respondents into subgroups.
Segments can be based on:
- Demographic
- And any other data type that you care to segment by
It is particularly useful to see the occurrence of codes within your segments. If one of your customer segments is considered unimportant to your business, but they are the cause of nearly all customer service complaints, it may be in your best interest to focus attention elsewhere. This is a useful insight!
Manually visualizing coded qualitative data
There are formulas you can use to visualize key insights in your data. The formulas we will suggest are imperative if you are measuring a score alongside your feedback.
If you are collecting a metric alongside your qualitative data this is a key visualization. Impact answers the question: “What’s the impact of a code on my overall score?”. Using Net Promoter Score (NPS) as an example, first you need to:
- Calculate overall NPS
- Calculate NPS in the subset of responses that do not contain that theme
- Subtract B from A
Then you can use this simple formula to calculate code impact on NPS .

You can then visualize this data using a bar chart.
You can download our CX toolkit - it includes a template to recreate this.
Trends over time
This analysis can help you answer questions like: “Which codes are linked to decreases or increases in my score over time?”
We need to compare two sequences of numbers: NPS over time and code frequency over time . Using Excel, calculate the correlation between the two sequences, which can be either positive (the more codes the higher the NPS, see picture below), or negative (the more codes the lower the NPS).
Now you need to plot code frequency against the absolute value of code correlation with NPS. Here is the formula:

The visualization could look like this:

These are two examples, but there are more. For a third manual formula, and to learn why word clouds are not an insightful form of analysis, read our visualizations article .
Using a text analytics solution to automate analysis
Automated text analytics solutions enable codes and sub-codes to be pulled out of the data automatically. This makes it far faster and easier to identify what’s driving negative or positive results. And to pick up emerging trends and find all manner of rich insights in the data.
Another benefit of AI-driven text analytics software is its built-in capability for sentiment analysis, which provides the emotive context behind your feedback and other qualitative textual data therein.
Thematic provides text analytics that goes further by allowing users to apply their expertise on business context to edit or augment the AI-generated outputs.
Since the move away from manual research is generally about reducing the human element, adding human input to the technology might sound counter-intuitive. However, this is mostly to make sure important business nuances in the feedback aren’t missed during coding. The result is a higher accuracy of analysis. This is sometimes referred to as augmented intelligence .

Step 5: Report on your data: Tell the story
The last step of analyzing your qualitative data is to report on it, to tell the story. At this point, the codes are fully developed and the focus is on communicating the narrative to the audience.
A coherent outline of the qualitative research, the findings and the insights is vital for stakeholders to discuss and debate before they can devise a meaningful course of action.
Creating graphs and reporting in Powerpoint
Typically, qualitative researchers take the tried and tested approach of distilling their report into a series of charts, tables and other visuals which are woven into a narrative for presentation in Powerpoint.
Using visualization software for reporting
With data transformation and APIs, the analyzed data can be shared with data visualisation software, such as Power BI or Tableau , Google Studio or Looker. Power BI and Tableau are among the most preferred options.
Visualizing your insights inside a feedback analytics platform
Feedback analytics platforms, like Thematic, incorporate visualisation tools that intuitively turn key data and insights into graphs. This removes the time consuming work of constructing charts to visually identify patterns and creates more time to focus on building a compelling narrative that highlights the insights, in bite-size chunks, for executive teams to review.
Using a feedback analytics platform with visualization tools means you don’t have to use a separate product for visualizations. You can export graphs into Powerpoints straight from the platforms.

Conclusion - Manual or Automated?
There are those who remain deeply invested in the manual approach - because it’s familiar, because they’re reluctant to spend money and time learning new software, or because they’ve been burned by the overpromises of AI.
For projects that involve small datasets, manual analysis makes sense. For example, if the objective is simply to quantify a simple question like “Do customers prefer X concepts to Y?”. If the findings are being extracted from a small set of focus groups and interviews, sometimes it’s easier to just read them
However, as new generations come into the workplace, it’s technology-driven solutions that feel more comfortable and practical. And the merits are undeniable. Especially if the objective is to go deeper and understand the ‘why’ behind customers’ preference for X or Y. And even more especially if time and money are considerations.
The ability to collect a free flow of qualitative feedback data at the same time as the metric means AI can cost-effectively scan, crunch, score and analyze a ton of feedback from one system in one go. And time-intensive processes like focus groups, or coding, that used to take weeks, can now be completed in a matter of hours or days.
But aside from the ever-present business case to speed things up and keep costs down, there are also powerful research imperatives for automated analysis of qualitative data: namely, accuracy and consistency.
Finding insights hidden in feedback requires consistency, especially in coding. Not to mention catching all the ‘unknown unknowns’ that can skew research findings and steering clear of cognitive bias.
Some say without manual data analysis researchers won’t get an accurate “feel” for the insights. However, the larger data sets are, the harder it is to sort through the feedback and organize feedback that has been pulled from different places. And, the more difficult it is to stay on course, the greater the risk of drawing incorrect, or incomplete, conclusions grows.
Though the process steps for qualitative data analysis have remained pretty much unchanged since psychologist Paul Felix Lazarsfeld paved the path a hundred years ago, the impact digital technology has had on types of qualitative feedback data and the approach to the analysis are profound.
If you want to try an automated feedback analysis solution on your own qualitative data, you can get started with Thematic .

Community & Marketing
Tyler manages our community of CX, insights & analytics professionals. Tyler's goal is to help unite insights professionals around common challenges.
We make it easy to discover the customer and product issues that matter.
Unlock the value of feedback at scale, in one platform. Try it for free now!
- Questions to ask your Feedback Analytics vendor
- How to end customer churn for good
- Scalable analysis of NPS verbatims
- 5 Text analytics approaches
- How to calculate the ROI of CX
Our experts will show you how Thematic works, how to discover pain points and track the ROI of decisions. To access your free trial, book a personal demo today.
Recent posts
Watercare, New Zealand's largest water and wastewater utility, are responsible for bringing clean water to people and managing the waste water systems that safeguard the Auckland environment and citizen health. On a typical day, Aucklanders don’t say much to Watercare. Water as a sector gets taken for granted, with
Become a qualitative theming pro! Creating a perfect code frame is hard, but thematic analysis software makes the process much easier.
Qualtrics is one of the most well-known and powerful Customer Feedback Management platforms. But even so, it has limitations. We recently hosted a live panel where data analysts from two well-known brands shared their experiences with Qualtrics, and how they extended this platform’s capabilities. Below, we’ll share the
11 Tips For Writing a Dissertation Data Analysis
Since the evolution of the fourth industrial revolution – the Digital World; lots of data have surrounded us. There are terabytes of data around us or in data centers that need to be processed and used. The data needs to be appropriately analyzed to process it, and Dissertation data analysis forms its basis. If data analysis is valid and free from errors, the research outcomes will be reliable and lead to a successful dissertation.
Considering the complexity of many data analysis projects, it becomes challenging to get precise results if analysts are not familiar with data analysis tools and tests properly. The analysis is a time-taking process that starts with collecting valid and relevant data and ends with the demonstration of error-free results.
So, in today’s topic, we will cover the need to analyze data, dissertation data analysis, and mainly the tips for writing an outstanding data analysis dissertation. If you are a doctoral student and plan to perform dissertation data analysis on your data, make sure that you give this article a thorough read for the best tips!
What is Data Analysis in Dissertation?
Dissertation Data Analysis is the process of understanding, gathering, compiling, and processing a large amount of data. Then identifying common patterns in responses and critically examining facts and figures to find the rationale behind those outcomes.
Even f you have the data collected and compiled in the form of facts and figures, it is not enough for proving your research outcomes. There is still a need to apply dissertation data analysis on your data; to use it in the dissertation. It provides scientific support to the thesis and conclusion of the research.
Data Analysis Tools
There are plenty of indicative tests used to analyze data and infer relevant results for the discussion part. Following are some tests used to perform analysis of data leading to a scientific conclusion:
11 Most Useful Tips for Dissertation Data Analysis
Doctoral students need to perform dissertation data analysis and then dissertation to receive their degree. Many Ph.D. students find it hard to do dissertation data analysis because they are not trained in it.
1. Dissertation Data Analysis Services
The first tip applies to those students who can afford to look for help with their dissertation data analysis work. It’s a viable option, and it can help with time management and with building the other elements of the dissertation with much detail.
Dissertation Analysis services are professional services that help doctoral students with all the basics of their dissertation work, from planning, research and clarification, methodology, dissertation data analysis and review, literature review, and final powerpoint presentation.
One great reference for dissertation data analysis professional services is Statistics Solutions , they’ve been around for over 22 years helping students succeed in their dissertation work. You can find the link to their website here .
For a proper dissertation data analysis, the student should have a clear understanding and statistical knowledge. Through this knowledge and experience, a student can perform dissertation analysis on their own.
Following are some helpful tips for writing a splendid dissertation data analysis:
2. Relevance of Collected Data
If the data is irrelevant and not appropriate, you might get distracted from the point of focus. To show the reader that you can critically solve the problem, make sure that you write a theoretical proposition regarding the selection and analysis of data.
3. Data Analysis
For analysis, it is crucial to use such methods that fit best with the types of data collected and the research objectives. Elaborate on these methods and the ones that justify your data collection methods thoroughly. Make sure to make the reader believe that you did not choose your method randomly. Instead, you arrived at it after critical analysis and prolonged research.
On the other hand, quantitative analysis refers to the analysis and interpretation of facts and figures – to build reasoning behind the advent of primary findings. An assessment of the main results and the literature review plays a pivotal role in qualitative and quantitative analysis.
The overall objective of data analysis is to detect patterns and inclinations in data and then present the outcomes implicitly. It helps in providing a solid foundation for critical conclusions and assisting the researcher to complete the dissertation proposal.
4. Qualitative Data Analysis
Qualitative data refers to data that does not involve numbers. You are required to carry out an analysis of the data collected through experiments, focus groups, and interviews. This can be a time-taking process because it requires iterative examination and sometimes demanding the application of hermeneutics. Note that using qualitative technique doesn’t only mean generating good outcomes but to unveil more profound knowledge that can be transferrable.
Presenting qualitative data analysis in a dissertation can also be a challenging task. It contains longer and more detailed responses. Placing such comprehensive data coherently in one chapter of the dissertation can be difficult due to two reasons. Firstly, we cannot figure out clearly which data to include and which one to exclude. Secondly, unlike quantitative data, it becomes problematic to present data in figures and tables. Making information condensed into a visual representation is not possible. As a writer, it is of essence to address both of these challenges.
Qualitative Data Analysis Methods
Following are the methods used to perform quantitative data analysis.
- Deductive Method
This method involves analyzing qualitative data based on an argument that a researcher already defines. It’s a comparatively easy approach to analyze data. It is suitable for the researcher with a fair idea about the responses they are likely to receive from the questionnaires.
- Inductive Method
In this method, the researcher analyzes the data not based on any predefined rules. It is a time-taking process used by students who have very little knowledge of the research phenomenon.
5. Quantitative Data Analysis
Quantitative data contains facts and figures obtained from scientific research and requires extensive statistical analysis. After collection and analysis, you will be able to conclude. Generic outcomes can be accepted beyond the sample by assuming that it is representative – one of the preliminary checkpoints to carry out in your analysis to a larger group. This method is also referred to as the “scientific method”, gaining its roots from natural sciences.
The Presentation of quantitative data depends on the domain to which it is being presented. It is beneficial to consider your audience while writing your findings. Quantitative data for hard sciences might require numeric inputs and statistics. As for natural sciences , such comprehensive analysis is not required.
Quantitative Analysis Methods
Following are some of the methods used to perform quantitative data analysis.
- Trend analysis: This corresponds to a statistical analysis approach to look at the trend of quantitative data collected over a considerable period.
- Cross-tabulation: This method uses a tabula way to draw readings among data sets in research.
- Conjoint analysis : Quantitative data analysis method that can collect and analyze advanced measures. These measures provide a thorough vision about purchasing decisions and the most importantly, marked parameters.
- TURF analysis: This approach assesses the total market reach of a service or product or a mix of both.
- Gap analysis: It utilizes the side-by-side matrix to portray quantitative data, which captures the difference between the actual and expected performance.
- Text analysis: In this method, innovative tools enumerate open-ended data into easily understandable data.
6. Data Presentation Tools
Since large volumes of data need to be represented, it becomes a difficult task to present such an amount of data in coherent ways. To resolve this issue, consider all the available choices you have, such as tables, charts, diagrams, and graphs.
Tables help in presenting both qualitative and quantitative data concisely. While presenting data, always keep your reader in mind. Anything clear to you may not be apparent to your reader. So, constantly rethink whether your data presentation method is understandable to someone less conversant with your research and findings. If the answer is “No”, you may need to rethink your Presentation.
7. Include Appendix or Addendum
After presenting a large amount of data, your dissertation analysis part might get messy and look disorganized. Also, you would not be cutting down or excluding the data you spent days and months collecting. To avoid this, you should include an appendix part.
The data you find hard to arrange within the text, include that in the appendix part of a dissertation . And place questionnaires, copies of focus groups and interviews, and data sheets in the appendix. On the other hand, one must put the statistical analysis and sayings quoted by interviewees within the dissertation.
8. Thoroughness of Data
It is a common misconception that the data presented is self-explanatory. Most of the students provide the data and quotes and think that it is enough and explaining everything. It is not sufficient. Rather than just quoting everything, you should analyze and identify which data you will use to approve or disapprove your standpoints.
Thoroughly demonstrate the ideas and critically analyze each perspective taking care of the points where errors can occur. Always make sure to discuss the anomalies and strengths of your data to add credibility to your research.
9. Discussing Data
Discussion of data involves elaborating the dimensions to classify patterns, themes, and trends in presented data. In addition, to balancing, also take theoretical interpretations into account. Discuss the reliability of your data by assessing their effect and significance. Do not hide the anomalies. While using interviews to discuss the data, make sure you use relevant quotes to develop a strong rationale.
It also involves answering what you are trying to do with the data and how you have structured your findings. Once you have presented the results, the reader will be looking for interpretation. Hence, it is essential to deliver the understanding as soon as you have submitted your data.
10. Findings and Results
Findings refer to the facts derived after the analysis of collected data. These outcomes should be stated; clearly, their statements should tightly support your objective and provide logical reasoning and scientific backing to your point. This part comprises of majority part of the dissertation.
In the finding part, you should tell the reader what they are looking for. There should be no suspense for the reader as it would divert their attention. State your findings clearly and concisely so that they can get the idea of what is more to come in your dissertation.
11. Connection with Literature Review
At the ending of your data analysis in the dissertation, make sure to compare your data with other published research. In this way, you can identify the points of differences and agreements. Check the consistency of your findings if they meet your expectations—lookup for bottleneck position. Analyze and discuss the reasons behind it. Identify the key themes, gaps, and the relation of your findings with the literature review. In short, you should link your data with your research question, and the questions should form a basis for literature.
The Role of Data Analytics at The Senior Management Level

From small and medium-sized businesses to Fortune 500 conglomerates, the success of a modern business is now increasingly tied to how the company implements its data infrastructure and data-based decision-making. According
The Decision-Making Model Explained (In Plain Terms)

Any form of the systematic decision-making process is better enhanced with data. But making sense of big data or even small data analysis when venturing into a decision-making process might
13 Reasons Why Data Is Important in Decision Making

Wrapping Up
Writing data analysis in the dissertation involves dedication, and its implementations demand sound knowledge and proper planning. Choosing your topic, gathering relevant data, analyzing it, presenting your data and findings correctly, discussing the results, connecting with the literature and conclusions are milestones in it. Among these checkpoints, the Data analysis stage is most important and requires a lot of keenness.
In this article, we thoroughly looked at the tips that prove valuable for writing a data analysis in a dissertation. Make sure to give this article a thorough read before you write data analysis in the dissertation leading to the successful future of your research.
Oxbridge Essays. Top 10 Tips for Writing a Dissertation Data Analysis.
Emidio Amadebai
As an IT Engineer, who is passionate about learning and sharing. I have worked and learned quite a bit from Data Engineers, Data Analysts, Business Analysts, and Key Decision Makers almost for the past 5 years. Interested in learning more about Data Science and How to leverage it for better decision-making in my business and hopefully help you do the same in yours.
Recent Posts
Bootstrapping vs. Boosting
Over the past decade, the field of machine learning has witnessed remarkable advancements in predictive techniques and ensemble learning methods. Ensemble techniques are very popular in machine...
Boosting Algorithms vs. Random Forests Explained
Imagine yourself in the position of a marketing analyst for an e-commerce site who has to make a model that will predict if a customer purchases in the next month or not. In such a scenario, you...
How to Write Analysis of Qualitative Data
Analysing and presenting data properly is one of the most important parts of any research project. Remember that if your dissertation includes weak analysis, your overall grade will be negatively affected.
That said, it’s important to analyse qualitative data carefully and accurately. But how do you write an analysis for qualitative data? Well, qualitative data comes from a range of sources (words, observations, images and even symbols), so there is no ‘one-size-fits-all’ approach.
In this article, we will take you through everything you need to know about qualitative data analysis. So, let’s get started!
Methods of Qualitative data
Whichever method of data gathering used, the preparation and analysis follow the same stages:

Good Practice for Qualitative Data Analysis
- In the initial stages of reading the information and identifying basic observations, you can try writing out lists so you can then add in the sub-themes as the analysis progresses. This helps to understand the data and key outcomes better.
- Keep your research questions to hand so you can refer back to them constantly and keep that all-important focus.
- Make sure your data is trustworthy and meets the following criteria:
- Credibility: the validity of conclusions achieved through extended engagement, checking with peers, and reviewing with interviewees as well as multiple data sources
- Transferability: how well the results can be applied in similar situations / settings
- Dependability: whether similar outcomes would occur if the study were repeated
- Confirmability: how objective the researcher (and survey instruments) was in gathering the data.
Once the data has been successfully interpreted and you are confident that the results achieved are trustworthy, you are good to go on writing up your findings!
Writing up your qualitative data
Introduction.
Your introduction should start with an overview of your respondent profile. Narratives can be one good way, but a table is often an effective way to provide your readers with key information such as gender, age, socio-economic status, or other areas relevant to your work. Your introduction should also include an overview of key themes.
To make sure your work is clear and of the highest quality, the body text for qualitative data, irrespective of the analysis process followed, should be broken up into sub-sections for each theme. We suggest having a main heading of a key theme, with sub-headings for each of the sub themes identified in the analysis.
The content of each paragraph or topic theme should identify the codes used for the analysis, followed by the conclusions you have drawn. Note: it is a good idea to include quotations from the raw data to illustrate the points you have made.
But be careful not to use overly long quotes and only use the parts which reinforce your findings. It is also, subject to confidentiality, sensible to identify the source of the quotation (e.g., “respondent 1, female, age 25) as this provides the reader with some context for the views expressed. Hint: Code different respondents with a number so that it is clear when using quotations that they come from a range of sources.
Plus, instead of indicating a number of respondents, it is better to give in fractions rather than percentages e.g., 7/10 respondents indicated, rather than 70%. We also recommend, where possible, to avoid the use of the word “significant” as this can suggest statistical significance which would be inappropriate in qualitative data.
As part of the presentation of the results it is also good practice to refer back to research questions and previous research. Whether the results back up or contradict previous research, including previous works shows that you have undertaken a wider level of reading and understanding of the topic being researched and gives a greater depth to your own work.
Using graphs or figures of key words and themes and how frequently they occurred during the data collection makes your work stand out as this provides illustrative evidence of your analysis process and findings.
Summary of results
Rather than a conclusion, when presenting qualitative results, remember that you at this stage you are giving an overall summation of the key findings, ideally with a conceptual framework. This could be an illustration, diagram, or existing framework, for example a strengths, weaknesses, opportunities, and threats (SWOT) analysis, or a conceptual framework that is original and emerged from your results. This shows that you have understood your data, and that your interpretation has led to some firm outcomes.
Key Phrases for use in writing up qualitative research.
“ A strong theme that emerged was…. with the term “x” being used by (%) of respondents.
“5/20 felt that the issue under discussion was…”
“ A high number of respondents (give fraction) felt that…”
“Underlying this main theme, a number of sub-themes emerged, suggesting some variation”.
“Indications from the core themes are that… but through examination of the sub-themes it was found at…”
“From these quotes, it can be inferred that…” which is in line with work by …”
You may also like

- Mathematics Textbook
- Apps and Hardware
- Exam Strategy
- Test Taking Tips
- Making the best use of your Mathematics Class
- Functions Relations and Graphs
- Coordinate Geometry
- Simplifying Algebraic Expressions
- Factorization
- Transposition Of Formula
- Solving Linear Equations
- Quadratic Equations
- Trigonometry and Bearings
- Inequalities and inequations
- Circle Theorems
- Measurement
- Consumer Arithmetic
- Sequences, Bases, Ratios Indices and Sets
- Fractions and Computations
- Transformations
- Dividing Polynomials
- Algebraic Fractions
- Inequalities
- Exponents and Logarithms
- Domain and Range
- Sequences and Series
- Mathematics SBA Guide
- SBA Ideas and Topics
- Sample SBA Straight vs Curve
- Mathematics SBA Sample - Using a Survey
- Mathematics SBA Sample 3- using an investigation/experiment
- Choosing the right graph
- Writing your data analysis
- CSEC Mathematics worksheets
- Multiple Choice Practice
- Paper 2 and 3 Practice by topic
- July 2021 Paper 2
- January 2021 paper 2
- January 2021 Paper 3
- January 2020 Paper 2
- January 2020 Paper 3
- May 2019 solutions
- January 2019 paper 3
- January 2019 paper 2
- May 2018 Paper 03
- January 2018 Paper 2
- May 2018 Paper 2
- January 2017
- January 2016
- January 2015
- January 2014
- January 2013
- January 2012
- January 2011
- January 2010
- January 2009
- January 2008
- 2022 paper 2 and 3
- 2023 January and May
- Consumer Arithmetic - Interest
- Consumer Arithmetic - Percentages
- buying on credit, best buys
- Determinants and singular Matrices
- Matrices and their inverses
- Matrices and Simultaneous Equations
- Vectors - Magnitude and direction
- Vectors - Proving parallel and Collinear
- completing the square
- Simplifying Algebraic Exppressions
- Factorization of Algebraic Expressions
- Simultaneous Equations
- Linear Equations
- Distance and Velocity time graphs
- inequalities and inequations
- Linear Programming
- Privacy Policy
Writing your data analysis for your CSEC SBA

- Career Advice
- Computer Vision
- Data Engineering
- Data Science
- Language Models
- Machine Learning
- Programming
- Cheat Sheets
- Recommendations
- Tech Briefs
The 7 Best AI Tools for Data Science Workflow
Learn about AI productivity tools that will make you a super data scientist.

It is now evident that those who adopt AI quickly will lead the way, while those who resist change will be replaced by those who are already using AI. Artificial intelligence is no longer just a passing fad; it is becoming an essential tool in various industries, including data science. Developers and researchers are increasingly using AI-powered tools to simplify their workflows, and one such tool that has gained immense popularity recently is ChatGPT.
In this blog, I will discuss the 7 best AI tools that have made my life as a data scientist easier. These tools are indispensable in my daily tasks, such as writing tutorials, researching, coding, analyzing data, and performing machine learning tasks. By sharing these tools, I hope to help fellow data scientists and researchers streamline their workflows and stay ahead of the curve in the ever-evolving field of AI.
1. PandasAI: Conversational Data Analysis
Every data professional is familiar with pandas, a Python package used for data manipulation and analysis. But what if I told you that instead of writing code, you can analyze and generate data visualizations by simply typing a prompt or a question? That's what PandasAI does - it's like an AI Agent for your Python workflow that automates data analysis using various AI models. You can even use locally run models.
In the code below, we have created an agent using the pandas dataframe and OpenAI model. This agent can perform various tasks on your dataframe using natural language. We asked it a simple question and then requested an explanation of how it arrived at the results.
The results are amazing. Experimenting with my real-life data would have taken at least half an hour.
2. GitHub Copilot: Your AI Code Assistant
GitHub Copilot is now necessary if you are a full time developer or dealing with the code everyday. Why? It enhances your ability to write clean and effective code faster. You can even chat with your file and debug faster or generate context aware code.

GitHub Copilot includes AI chatbot, inline chatbox, code generation, autocomplete, CLI autocomplete, and other GitHub-based features that can help with code search and understanding.
GitHub Copilot is a paid tool, so if you don't want to pay $10/ month then you should check out Top 5 AI Coding Assistants You Must Try .
3. ChatGPT: Chat Application Powered by GPT-4
ChatGPT has been dominating the AI space for 2 years now. People use it for writing emails, generating content, code generation, and all kinds of nominal work-related tasks.

If you pay for a subscription, you get access to the state-of-the-art model GPT-4, which is excellent at solving complex problems.
I use it daily for code generation, for code explanation, for asking general questions, and for content generation. The work generated by AI is not always perfect. You may need to make some edits to present it to a wider audience.
ChatGPT is an essential tool for data scientists. Using it is not cheating. Instead, it saves you time in researching and finding solutions compared to everyone else.
If you value privacy, consider running open source AI models on your laptop. Check out 5 Ways To Use LLMs On Your Laptop .
4. Colab AI: AI Powered Cloud Notebook
If you have trained a deep neural network for a complex machine learning task, then you must have first trained it on Google Colab due to the availability of freely accessible GPUs and TPUs. With the surge in Generative AI, Google Colab has recently introduced some features that will help you generate code, debug faster, and autocomplete.

Colab AI is like an integrated AI coding assistant in your workspace. You can generate code by simply prompting and asking follow-up questions. It also comes with inline code prompting, although it has limited use with the free version.
I would highly recommend getting the paid version as it provides better GPUs and an overall better coding experience.
Discover the Top 11 AI Coding Assistants for 2024 and try out all alternatives to Colab AI to find the best fit for you.
5. Perplexity AI: Smart Search Engine
I have been using Perplexity AI as my new search engine and research assistant. It helps me learn about new technologies and concepts by providing concise and up-to-date summaries with links to relevant blogs and videos. I can even ask follow-up questions and get a modified answer.

Perplexity AI offers various features to assist its users. It can answer a wide range of questions, from basic facts to complex queries, using the latest sources. Its Copilot feature allows users to explore their topics in-depth, enabling them to expand their knowledge and discover new areas of interest. Furthermore, users can organize their search results into "Collections" based on projects or topics, making it easier to find what they need in the future.
Check out 8 AI-powered search engines that can enhance your internet searching and research capabilities as an alternative to Google.
6. Grammarly: AI Writing Assistance
I want to let you know that Grammarly is an exceptional tool for individuals with Dyslexia. It helps me write content quickly and accurately. I have been using Grammarly for almost 9 years now, and I love the features that correct my spelling, grammar, and overall structure of my writing. Recently, they introduced Grammarly AI, which allows me to improve my writing with the help of generative AI models. This tool has made my life easier as I can now write better emails, direct messages, content, tutorials, and reports. It is a vital tool for me, much like Canva.

7. Hugging Face: Building the Future of AI
Hugging Face is not just a tool, but an entire ecosystem that has become an essential part of my daily work life. I use it to access datasets, models, machine learning demos, and APIs for AI models. Additionally, I rely on various Hugging Face Python packages for training, fine-tuning, evaluating, and deploying machine learning models.

Hugging Face is an open-source platform that's free for the community and allows people to host datasets, models, and AI demos. It even lets you deploy your models inferences and run them on GPUs. In the next few years, it's likely to become the primary platform for data discussions, research and development, and operations.
Discover the top 10 data science tools to use in 2024 and become a super data scientist, solving data problems better than anyone.
I have been using Travis , an AI-powered tutor, to conduct research on advanced topics such as MLOps, LLMOps, and data engineering. It provides simple explanations about these topics and you can ask follow-up questions just like with any chatbot. It's perfect for those who only want search results from top publications on Medium.
In this blog, we have explored 7 powerful AI tools that can significantly enhance the productivity and efficiency of data scientists and researchers - from conversational data analysis with PandasAI to code generation and debugging assistance with GitHub Copilot and Colab AI, offering game-changing capabilities to simplify complex code related tasks and save valuable time. ChatGPT's versatility allows for content generation, code explanation, and problem-solving, while Perplexity AI provides a smart search engine and research assistant. Grammarly AI offers invaluable writing assistance, and Hugging Face serves as a comprehensive ecosystem for accessing datasets, models, and APIs to develop and deploy machine learning solutions.
Abid Ali Awan ( @1abidaliawan ) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in technology management and a bachelor's degree in telecommunication engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.
- RAPIDS cuDF to Speed up Your Next Data Science Workflow
- 7 GPTs to Help Improve Your Data Science Workflow
- Streamline Your Machine Learning Workflow with Scikit-learn Pipelines
- Easily Integrate LLMs into Your Scikit-learn Workflow with Scikit-LLM
- The Seven Best ELT Tools for Data Warehouses
- A List of 7 Best Data Modeling Tools for 2023

Get the FREE ebook 'The Great Big Natural Language Processing Primer' and 'The Complete Collection of Data Science Cheat Sheets' along with the leading newsletter on Data Science, Machine Learning, AI & Analytics straight to your inbox.
By subscribing you accept KDnuggets Privacy Policy
Latest Posts
- A Collection Of Free Data Science Courses From Harvard, Stanford, MIT, Cornell, and Berkeley
- Top Free Data Science Online Courses for 2024
- A Free Data Science Learning Roadmap: For All Levels with IBM
- Become a Business Intelligence Analyst in Less Than 6 Months
- The Art of Effective Prompt Engineering with Free Courses and Certifications
- Pydantic Tutorial: Data Validation in Python Made Simple
- Collection of Guides on Mastering SQL, Python, Data Cleaning, Data Wrangling, and Exploratory Data Analysis
- 7 Steps to Mastering Large Language Model Fine-tuning
- 5 Free Books to Master Statistics for Data Science
- 7 Free Google Courses to Become a Machine Learning Engineer

- Share full article
Advertisement
Supported by
What the Data Says About Pandemic School Closures, Four Years Later
The more time students spent in remote instruction, the further they fell behind. And, experts say, extended closures did little to stop the spread of Covid.

By Sarah Mervosh , Claire Cain Miller and Francesca Paris
Four years ago this month, schools nationwide began to shut down, igniting one of the most polarizing and partisan debates of the pandemic.
Some schools, often in Republican-led states and rural areas, reopened by fall 2020. Others, typically in large cities and states led by Democrats, would not fully reopen for another year.
A variety of data — about children’s academic outcomes and about the spread of Covid-19 — has accumulated in the time since. Today, there is broad acknowledgment among many public health and education experts that extended school closures did not significantly stop the spread of Covid, while the academic harms for children have been large and long-lasting.
While poverty and other factors also played a role, remote learning was a key driver of academic declines during the pandemic, research shows — a finding that held true across income levels.
Source: Fahle, Kane, Patterson, Reardon, Staiger and Stuart, “ School District and Community Factors Associated With Learning Loss During the COVID-19 Pandemic .” Score changes are measured from 2019 to 2022. In-person means a district offered traditional in-person learning, even if not all students were in-person.
“There’s fairly good consensus that, in general, as a society, we probably kept kids out of school longer than we should have,” said Dr. Sean O’Leary, a pediatric infectious disease specialist who helped write guidance for the American Academy of Pediatrics, which recommended in June 2020 that schools reopen with safety measures in place.
There were no easy decisions at the time. Officials had to weigh the risks of an emerging virus against the academic and mental health consequences of closing schools. And even schools that reopened quickly, by the fall of 2020, have seen lasting effects.
But as experts plan for the next public health emergency, whatever it may be, a growing body of research shows that pandemic school closures came at a steep cost to students.
The longer schools were closed, the more students fell behind.
At the state level, more time spent in remote or hybrid instruction in the 2020-21 school year was associated with larger drops in test scores, according to a New York Times analysis of school closure data and results from the National Assessment of Educational Progress , an authoritative exam administered to a national sample of fourth- and eighth-grade students.
At the school district level, that finding also holds, according to an analysis of test scores from third through eighth grade in thousands of U.S. districts, led by researchers at Stanford and Harvard. In districts where students spent most of the 2020-21 school year learning remotely, they fell more than half a grade behind in math on average, while in districts that spent most of the year in person they lost just over a third of a grade.
( A separate study of nearly 10,000 schools found similar results.)
Such losses can be hard to overcome, without significant interventions. The most recent test scores, from spring 2023, show that students, overall, are not caught up from their pandemic losses , with larger gaps remaining among students that lost the most ground to begin with. Students in districts that were remote or hybrid the longest — at least 90 percent of the 2020-21 school year — still had almost double the ground to make up compared with students in districts that allowed students back for most of the year.
Some time in person was better than no time.
As districts shifted toward in-person learning as the year went on, students that were offered a hybrid schedule (a few hours or days a week in person, with the rest online) did better, on average, than those in places where school was fully remote, but worse than those in places that had school fully in person.
Students in hybrid or remote learning, 2020-21
80% of students
Some schools return online, as Covid-19 cases surge. Vaccinations start for high-priority groups.
Teachers are eligible for the Covid vaccine in more than half of states.
Most districts end the year in-person or hybrid.
Source: Burbio audit of more than 1,200 school districts representing 47 percent of U.S. K-12 enrollment. Note: Learning mode was defined based on the most in-person option available to students.
Income and family background also made a big difference.
A second factor associated with academic declines during the pandemic was a community’s poverty level. Comparing districts with similar remote learning policies, poorer districts had steeper losses.
But in-person learning still mattered: Looking at districts with similar poverty levels, remote learning was associated with greater declines.
A community’s poverty rate and the length of school closures had a “roughly equal” effect on student outcomes, said Sean F. Reardon, a professor of poverty and inequality in education at Stanford, who led a district-level analysis with Thomas J. Kane, an economist at Harvard.
Score changes are measured from 2019 to 2022. Poorest and richest are the top and bottom 20% of districts by percent of students on free/reduced lunch. Mostly in-person and mostly remote are districts that offered traditional in-person learning for more than 90 percent or less than 10 percent of the 2020-21 year.
But the combination — poverty and remote learning — was particularly harmful. For each week spent remote, students in poor districts experienced steeper losses in math than peers in richer districts.
That is notable, because poor districts were also more likely to stay remote for longer .
Some of the country’s largest poor districts are in Democratic-leaning cities that took a more cautious approach to the virus. Poor areas, and Black and Hispanic communities , also suffered higher Covid death rates, making many families and teachers in those districts hesitant to return.
“We wanted to survive,” said Sarah Carpenter, the executive director of Memphis Lift, a parent advocacy group in Memphis, where schools were closed until spring 2021 .
“But I also think, man, looking back, I wish our kids could have gone back to school much quicker,” she added, citing the academic effects.
Other things were also associated with worse student outcomes, including increased anxiety and depression among adults in children’s lives, and the overall restriction of social activity in a community, according to the Stanford and Harvard research .
Even short closures had long-term consequences for children.
While being in school was on average better for academic outcomes, it wasn’t a guarantee. Some districts that opened early, like those in Cherokee County, Ga., a suburb of Atlanta, and Hanover County, Va., lost significant learning and remain behind.
At the same time, many schools are seeing more anxiety and behavioral outbursts among students. And chronic absenteeism from school has surged across demographic groups .
These are signs, experts say, that even short-term closures, and the pandemic more broadly, had lasting effects on the culture of education.
“There was almost, in the Covid era, a sense of, ‘We give up, we’re just trying to keep body and soul together,’ and I think that was corrosive to the higher expectations of schools,” said Margaret Spellings, an education secretary under President George W. Bush who is now chief executive of the Bipartisan Policy Center.
Closing schools did not appear to significantly slow Covid’s spread.
Perhaps the biggest question that hung over school reopenings: Was it safe?
That was largely unknown in the spring of 2020, when schools first shut down. But several experts said that had changed by the fall of 2020, when there were initial signs that children were less likely to become seriously ill, and growing evidence from Europe and parts of the United States that opening schools, with safety measures, did not lead to significantly more transmission.
“Infectious disease leaders have generally agreed that school closures were not an important strategy in stemming the spread of Covid,” said Dr. Jeanne Noble, who directed the Covid response at the U.C.S.F. Parnassus emergency department.
Politically, though, there remains some disagreement about when, exactly, it was safe to reopen school.
Republican governors who pushed to open schools sooner have claimed credit for their approach, while Democrats and teachers’ unions have emphasized their commitment to safety and their investment in helping students recover.
“I do believe it was the right decision,” said Jerry T. Jordan, president of the Philadelphia Federation of Teachers, which resisted returning to school in person over concerns about the availability of vaccines and poor ventilation in school buildings. Philadelphia schools waited to partially reopen until the spring of 2021 , a decision Mr. Jordan believes saved lives.
“It doesn’t matter what is going on in the building and how much people are learning if people are getting the virus and running the potential of dying,” he said.
Pandemic school closures offer lessons for the future.
Though the next health crisis may have different particulars, with different risk calculations, the consequences of closing schools are now well established, experts say.
In the future, infectious disease experts said, they hoped decisions would be guided more by epidemiological data as it emerged, taking into account the trade-offs.
“Could we have used data to better guide our decision making? Yes,” said Dr. Uzma N. Hasan, division chief of pediatric infectious diseases at RWJBarnabas Health in Livingston, N.J. “Fear should not guide our decision making.”
Source: Fahle, Kane, Patterson, Reardon, Staiger and Stuart, “ School District and Community Factors Associated With Learning Loss During the Covid-19 Pandemic. ”
The study used estimates of learning loss from the Stanford Education Data Archive . For closure lengths, the study averaged district-level estimates of time spent in remote and hybrid learning compiled by the Covid-19 School Data Hub (C.S.D.H.) and American Enterprise Institute (A.E.I.) . The A.E.I. data defines remote status by whether there was an in-person or hybrid option, even if some students chose to remain virtual. In the C.S.D.H. data set, districts are defined as remote if “all or most” students were virtual.
An earlier version of this article misstated a job description of Dr. Jeanne Noble. She directed the Covid response at the U.C.S.F. Parnassus emergency department. She did not direct the Covid response for the University of California, San Francisco health system.
How we handle corrections
Sarah Mervosh covers education for The Times, focusing on K-12 schools. More about Sarah Mervosh
Claire Cain Miller writes about gender, families and the future of work for The Upshot. She joined The Times in 2008 and was part of a team that won a Pulitzer Prize in 2018 for public service for reporting on workplace sexual harassment issues. More about Claire Cain Miller
Francesca Paris is a Times reporter working with data and graphics for The Upshot. More about Francesca Paris
How do I write code in Google Earth Engine?

As a Travel Agent, I often come across clients who are interested in using Google Earth Engine to explore and analyze geospatial data. Writing code in Google Earth Engine may seem daunting at first, but with a little practice, it can be a powerful tool for unlocking the potential of satellite imagery and geospatial data. In this article, I will guide you through the process of writing code in Google Earth Engine and provide you with some useful tips and tricks along the way.
To get started, you will need to access the Code Editor, which is a web-based programming interface for Google Earth Engine. Simply type the following URL into your browser: https://code.earthengine.google.com. Once you have accessed the Code Editor, you will see a webpage programming interface with various functionalities.
Opening and running code in the Code Editor is easy. You can navigate to the Scripts tab located on the far left of the Code Editor. Here, you will find a collection of example scripts that you can use to access, display, and analyze Earth Engine data. These example scripts serve as a great starting point for beginners and can help you understand the capabilities of Google Earth Engine.
Commenting code in Google Earth Engine is important for making your code more readable and understandable. You can write comments by using a double slash (//). For example, if you want to add a comment to your code, simply type // followed by your comment. Comments are ignored by the computer when running the code, but they can help you and others understand your code better.
Google Earth Engine supports two coding languages: Python and JavaScript. Both languages have their advantages and can be used to harness the power of Google’s cloud for geospatial analysis. JavaScript is ideal for working with Google Earth Engine’s web-based interface and for easy prototyping and visualization of data. On the other hand, Python is more suitable for scientific computing, data analysis, and geospatial analysis tasks. You can choose the language that best suits your needs and preferences.
The Earth Engine Code Editor is designed to make developing complex geospatial workflows fast and easy. It features a JavaScript code editor that allows you to write and execute code directly in the browser. The Code Editor also provides various elements and features that enhance your coding experience. These include options for importing libraries, displaying maps and images, and executing code step by step.
Now that we have covered the basics of how to write code in Google Earth Engine, let’s dive into some frequently asked questions to help you further understand this powerful tool.
Frequently Asked Questions
1. can google earth engine be used for commercial purposes.
Yes, Google Earth Engine can be used for commercial purposes. It is a platform for scientific analysis and visualization of geospatial datasets for academic, non-profit, business, and government users.
2. What are the coding languages supported by Google Earth Engine?
Google Earth Engine supports two coding languages: Python and JavaScript. You can choose the language that best suits your needs and preferences.
3. Is Google Earth Engine free to use?
Yes, Google Earth Engine is free for non-commercial use. However, different pricing plans may apply for commercial usage. You can learn more about the pricing and licensing options on Google Earth Engine’s official website.
4. How do I run a Python script in Google Earth Engine?
To run a Python script in Google Earth Engine, you need to set up the necessary dependencies and libraries. You can download Python and install the Earth Engine Python library. Once the setup is complete, you can write and execute Python code in the Earth Engine Code Editor.
5. What are the advantages and disadvantages of using Google Earth Engine?
One advantage of using Google Earth Engine is the vast amount of remote sensing data available. With access to over 200 public datasets and millions of images, Google Earth Engine provides a rich resource for geospatial analysis. However, one disadvantage is that creating sophisticated applications using the Earth Engine framework can be challenging due to certain limitations. The parallel programming framework used by Earth Engine is based on maps and reduced operations, which may present challenges for complex projects.
6. Is Google Earth Engine a GIS software?
While Google Earth Engine is not a traditional geographic information system (GIS), it can be used for visualization, assessment, and manipulation of geospatial data. It provides powerful tools for analyzing satellite imagery and other geospatial datasets.
7. Can I use Google Earth Engine for real-time analysis?
Google Earth Engine is primarily designed for offline analysis of large-scale geospatial datasets. Real-time analysis may not be feasible in all cases due to the processing time required for complex computations. However, Google Earth Engine provides capabilities for batch processing and cloud-based analysis, which can be useful for timely and efficient geospatial analysis.
8. Where can I find more resources and tutorials for Google Earth Engine?
Google Earth Engine provides a comprehensive documentation and tutorial section on their website. You can access tutorials, code examples, and documentation to learn more about the capabilities of Google Earth Engine. Additionally, there are online communities and forums where you can connect with other users and experts to seek guidance and share knowledge.
In conclusion, writing code in Google Earth Engine may seem intimidating at first, but with practice and the right resources, you can master the art of geospatial analysis. Whether you are a beginner or an experienced programmer, Google Earth Engine offers a wide range of functionalities and datasets to explore. So why not dive in and unlock the potential of satellite imagery and geospatial data with Google Earth Engine?
About The Author
Luther costa, leave a comment cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- How to Do Thematic Analysis | Step-by-Step Guide & Examples
How to Do Thematic Analysis | Step-by-Step Guide & Examples
Published on September 6, 2019 by Jack Caulfield . Revised on June 22, 2023.
Thematic analysis is a method of analyzing qualitative data . It is usually applied to a set of texts, such as an interview or transcripts . The researcher closely examines the data to identify common themes – topics, ideas and patterns of meaning that come up repeatedly.
There are various approaches to conducting thematic analysis, but the most common form follows a six-step process: familiarization, coding, generating themes, reviewing themes, defining and naming themes, and writing up. Following this process can also help you avoid confirmation bias when formulating your analysis.
This process was originally developed for psychology research by Virginia Braun and Victoria Clarke . However, thematic analysis is a flexible method that can be adapted to many different kinds of research.
Table of contents
When to use thematic analysis, different approaches to thematic analysis, step 1: familiarization, step 2: coding, step 3: generating themes, step 4: reviewing themes, step 5: defining and naming themes, step 6: writing up, other interesting articles.
Thematic analysis is a good approach to research where you’re trying to find out something about people’s views, opinions, knowledge, experiences or values from a set of qualitative data – for example, interview transcripts , social media profiles, or survey responses .
Some types of research questions you might use thematic analysis to answer:
- How do patients perceive doctors in a hospital setting?
- What are young women’s experiences on dating sites?
- What are non-experts’ ideas and opinions about climate change?
- How is gender constructed in high school history teaching?
To answer any of these questions, you would collect data from a group of relevant participants and then analyze it. Thematic analysis allows you a lot of flexibility in interpreting the data, and allows you to approach large data sets more easily by sorting them into broad themes.
However, it also involves the risk of missing nuances in the data. Thematic analysis is often quite subjective and relies on the researcher’s judgement, so you have to reflect carefully on your own choices and interpretations.
Pay close attention to the data to ensure that you’re not picking up on things that are not there – or obscuring things that are.
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

Once you’ve decided to use thematic analysis, there are different approaches to consider.
There’s the distinction between inductive and deductive approaches:
- An inductive approach involves allowing the data to determine your themes.
- A deductive approach involves coming to the data with some preconceived themes you expect to find reflected there, based on theory or existing knowledge.
Ask yourself: Does my theoretical framework give me a strong idea of what kind of themes I expect to find in the data (deductive), or am I planning to develop my own framework based on what I find (inductive)?
There’s also the distinction between a semantic and a latent approach:
- A semantic approach involves analyzing the explicit content of the data.
- A latent approach involves reading into the subtext and assumptions underlying the data.
Ask yourself: Am I interested in people’s stated opinions (semantic) or in what their statements reveal about their assumptions and social context (latent)?
After you’ve decided thematic analysis is the right method for analyzing your data, and you’ve thought about the approach you’re going to take, you can follow the six steps developed by Braun and Clarke .
The first step is to get to know our data. It’s important to get a thorough overview of all the data we collected before we start analyzing individual items.
This might involve transcribing audio , reading through the text and taking initial notes, and generally looking through the data to get familiar with it.
Next up, we need to code the data. Coding means highlighting sections of our text – usually phrases or sentences – and coming up with shorthand labels or “codes” to describe their content.
Let’s take a short example text. Say we’re researching perceptions of climate change among conservative voters aged 50 and up, and we have collected data through a series of interviews. An extract from one interview looks like this:
In this extract, we’ve highlighted various phrases in different colors corresponding to different codes. Each code describes the idea or feeling expressed in that part of the text.
At this stage, we want to be thorough: we go through the transcript of every interview and highlight everything that jumps out as relevant or potentially interesting. As well as highlighting all the phrases and sentences that match these codes, we can keep adding new codes as we go through the text.
After we’ve been through the text, we collate together all the data into groups identified by code. These codes allow us to gain a a condensed overview of the main points and common meanings that recur throughout the data.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
Next, we look over the codes we’ve created, identify patterns among them, and start coming up with themes.
Themes are generally broader than codes. Most of the time, you’ll combine several codes into a single theme. In our example, we might start combining codes into themes like this:
At this stage, we might decide that some of our codes are too vague or not relevant enough (for example, because they don’t appear very often in the data), so they can be discarded.
Other codes might become themes in their own right. In our example, we decided that the code “uncertainty” made sense as a theme, with some other codes incorporated into it.
Again, what we decide will vary according to what we’re trying to find out. We want to create potential themes that tell us something helpful about the data for our purposes.
Now we have to make sure that our themes are useful and accurate representations of the data. Here, we return to the data set and compare our themes against it. Are we missing anything? Are these themes really present in the data? What can we change to make our themes work better?
If we encounter problems with our themes, we might split them up, combine them, discard them or create new ones: whatever makes them more useful and accurate.
For example, we might decide upon looking through the data that “changing terminology” fits better under the “uncertainty” theme than under “distrust of experts,” since the data labelled with this code involves confusion, not necessarily distrust.
Now that you have a final list of themes, it’s time to name and define each of them.
Defining themes involves formulating exactly what we mean by each theme and figuring out how it helps us understand the data.
Naming themes involves coming up with a succinct and easily understandable name for each theme.
For example, we might look at “distrust of experts” and determine exactly who we mean by “experts” in this theme. We might decide that a better name for the theme is “distrust of authority” or “conspiracy thinking”.
Finally, we’ll write up our analysis of the data. Like all academic texts, writing up a thematic analysis requires an introduction to establish our research question, aims and approach.
We should also include a methodology section, describing how we collected the data (e.g. through semi-structured interviews or open-ended survey questions ) and explaining how we conducted the thematic analysis itself.
The results or findings section usually addresses each theme in turn. We describe how often the themes come up and what they mean, including examples from the data as evidence. Finally, our conclusion explains the main takeaways and shows how the analysis has answered our research question.
In our example, we might argue that conspiracy thinking about climate change is widespread among older conservative voters, point out the uncertainty with which many voters view the issue, and discuss the role of misinformation in respondents’ perceptions.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Measures of central tendency
- Chi square tests
- Confidence interval
- Quartiles & Quantiles
- Cluster sampling
- Stratified sampling
- Discourse analysis
- Cohort study
- Peer review
- Ethnography
Research bias
- Implicit bias
- Cognitive bias
- Conformity bias
- Hawthorne effect
- Availability heuristic
- Attrition bias
- Social desirability bias
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Caulfield, J. (2023, June 22). How to Do Thematic Analysis | Step-by-Step Guide & Examples. Scribbr. Retrieved March 31, 2024, from https://www.scribbr.com/methodology/thematic-analysis/
Is this article helpful?

Jack Caulfield
Other students also liked, what is qualitative research | methods & examples, inductive vs. deductive research approach | steps & examples, critical discourse analysis | definition, guide & examples, what is your plagiarism score.
- Introduction
- Conclusions
- Article Information
The size of each box is proportional to the weight of the study in relation to the pooled estimate.
eFigure 1. PRISMA flow diagram
eFigure 2. Prevalence of MRI abnormalities in FEP: funnel plot of studies
eFigure 3. Prevalence of MRI abnormalities in FEP: forest plots of MRI abnormalities by anatomical subtype
eFigure 4. Prevalence of MRI abnormalities in FEP: forest plots of clinically relevant MRI abnormalities by anatomical subtype
eFigure 5. Risk ratio of MRI abnormalities in FEP: forest plots of all MRI abnormalities in psychosis
eFigure 6. Forest plot of clinically relevant MRI abnormalities: leave one out sensitivity analysis
eTable 1. Summary of included studies
eTable 2. Summary of recruitment, screening, and matching criteria of healthy controls
eTable 3. Newcastle Ottawa Scale results
eTable 4. Neuroanatomical Groupings
eReferences
Data sharing statement
- Concerns Regarding Strength of Conclusions in Systematic Review and Meta-Analysis of Neuroradiological Abnormalities in First-Episode Psychosis JAMA Psychiatry Comment & Response January 1, 2024 Anil N. Makam, MD, MAS
- Concerns Regarding Strength of Conclusions in Systematic Review and Meta-Analysis of Neuroradiological Abnormalities in First-Episode Psychosis JAMA Psychiatry Comment & Response January 1, 2024 Benjamin Dralle, MD; Robert J. Morgan, MD, PhD
- Concerns Regarding Strength of Conclusions in Systematic Review and Meta-Analysis of Neuroradiological Abnormalities in First-Episode Psychosis JAMA Psychiatry Comment & Response January 1, 2024 Malcolm Forbes, MBBS; Stephen Stuckey, MD; Steve Kisely, MD, PhD
See More About
Select your interests.
Customize your JAMA Network experience by selecting one or more topics from the list below.
- Academic Medicine
- Acid Base, Electrolytes, Fluids
- Allergy and Clinical Immunology
- American Indian or Alaska Natives
- Anesthesiology
- Anticoagulation
- Art and Images in Psychiatry
- Artificial Intelligence
- Assisted Reproduction
- Bleeding and Transfusion
- Caring for the Critically Ill Patient
- Challenges in Clinical Electrocardiography
- Climate and Health
- Climate Change
- Clinical Challenge
- Clinical Decision Support
- Clinical Implications of Basic Neuroscience
- Clinical Pharmacy and Pharmacology
- Complementary and Alternative Medicine
- Consensus Statements
- Coronavirus (COVID-19)
- Critical Care Medicine
- Cultural Competency
- Dental Medicine
- Dermatology
- Diabetes and Endocrinology
- Diagnostic Test Interpretation
- Drug Development
- Electronic Health Records
- Emergency Medicine
- End of Life, Hospice, Palliative Care
- Environmental Health
- Equity, Diversity, and Inclusion
- Facial Plastic Surgery
- Gastroenterology and Hepatology
- Genetics and Genomics
- Genomics and Precision Health
- Global Health
- Guide to Statistics and Methods
- Hair Disorders
- Health Care Delivery Models
- Health Care Economics, Insurance, Payment
- Health Care Quality
- Health Care Reform
- Health Care Safety
- Health Care Workforce
- Health Disparities
- Health Inequities
- Health Policy
- Health Systems Science
- History of Medicine
- Hypertension
- Images in Neurology
- Implementation Science
- Infectious Diseases
- Innovations in Health Care Delivery
- JAMA Infographic
- Law and Medicine
- Leading Change
- Less is More
- LGBTQIA Medicine
- Lifestyle Behaviors
- Medical Coding
- Medical Devices and Equipment
- Medical Education
- Medical Education and Training
- Medical Journals and Publishing
- Mobile Health and Telemedicine
- Narrative Medicine
- Neuroscience and Psychiatry
- Notable Notes
- Nutrition, Obesity, Exercise
- Obstetrics and Gynecology
- Occupational Health
- Ophthalmology
- Orthopedics
- Otolaryngology
- Pain Medicine
- Palliative Care
- Pathology and Laboratory Medicine
- Patient Care
- Patient Information
- Performance Improvement
- Performance Measures
- Perioperative Care and Consultation
- Pharmacoeconomics
- Pharmacoepidemiology
- Pharmacogenetics
- Pharmacy and Clinical Pharmacology
- Physical Medicine and Rehabilitation
- Physical Therapy
- Physician Leadership
- Population Health
- Primary Care
- Professional Well-being
- Professionalism
- Psychiatry and Behavioral Health
- Public Health
- Pulmonary Medicine
- Regulatory Agencies
- Reproductive Health
- Research, Methods, Statistics
- Resuscitation
- Rheumatology
- Risk Management
- Scientific Discovery and the Future of Medicine
- Shared Decision Making and Communication
- Sleep Medicine
- Sports Medicine
- Stem Cell Transplantation
- Substance Use and Addiction Medicine
- Surgical Innovation
- Surgical Pearls
- Teachable Moment
- Technology and Finance
- The Art of JAMA
- The Arts and Medicine
- The Rational Clinical Examination
- Tobacco and e-Cigarettes
- Translational Medicine
- Trauma and Injury
- Treatment Adherence
- Ultrasonography
- Users' Guide to the Medical Literature
- Vaccination
- Venous Thromboembolism
- Veterans Health
- Women's Health
- Workflow and Process
- Wound Care, Infection, Healing
Others Also Liked
- Download PDF
- X Facebook More LinkedIn
Blackman G , Neri G , Al-Doori O, et al. Prevalence of Neuroradiological Abnormalities in First-Episode Psychosis : A Systematic Review and Meta-analysis . JAMA Psychiatry. 2023;80(10):1047–1054. doi:10.1001/jamapsychiatry.2023.2225
Manage citations:
© 2024
- Permissions
Prevalence of Neuroradiological Abnormalities in First-Episode Psychosis : A Systematic Review and Meta-analysis
- 1 Department of Psychiatry, University of Oxford, Warneford Hospital, Oxford, United Kingdom
- 2 Department of Psychosis Studies, Institute of Psychiatry, Psychology and Neuroscience, King’s College London, London, United Kingdom
- 3 South London and Maudsley NHS Foundation Trust, London, United Kingdom
- 4 Department of Neuroradiology, King’s College Hospital NHS Foundation Trust, London, United Kingdom
- 5 Department of Radiology, Guy’s and St Thomas’ NHS Foundation Trust, London, United Kingdom
- 6 Institute of Cognitive Neuroscience, University College London, London, United Kingdom
- 7 Department of Psychiatry and Psychotherapy, Ludwig-Maximilian-University, Munich, Germany
- 8 Max-Planck Institute of Psychiatry, Munich, Germany
- 9 Research Department of Clinical, Educational and Health Psychology, University College London, London, United Kingdom
- Comment & Response Concerns Regarding Strength of Conclusions in Systematic Review and Meta-Analysis of Neuroradiological Abnormalities in First-Episode Psychosis Anil N. Makam, MD, MAS JAMA Psychiatry
- Comment & Response Concerns Regarding Strength of Conclusions in Systematic Review and Meta-Analysis of Neuroradiological Abnormalities in First-Episode Psychosis Benjamin Dralle, MD; Robert J. Morgan, MD, PhD JAMA Psychiatry
- Comment & Response Concerns Regarding Strength of Conclusions in Systematic Review and Meta-Analysis of Neuroradiological Abnormalities in First-Episode Psychosis Malcolm Forbes, MBBS; Stephen Stuckey, MD; Steve Kisely, MD, PhD JAMA Psychiatry
Question How common are neuroradiological abnormalities in first-episode psychosis?
Findings In this systematic review and meta-analysis, we found approximately 6% of patients with first-episode psychosis had an abnormality that required a change in clinical management. The number of patients needed to scan to detect 1 clinically relevant abnormality was estimated to be 18.
Meaning These findings support the routine use of magnetic resonance imaging as part of the initial assessment in patients presenting with first-episode psychosis.
Importance Individuals presenting with first-episode psychosis (FEP) may have a secondary (“organic”) etiology to their symptoms that can be identified using neuroimaging. Because failure to detect such cases at an early stage can have serious clinical consequences, it has been suggested that brain magnetic resonance imaging (MRI) should be mandatory for all patients presenting with FEP. However, this remains a controversial issue, partly because the prevalence of clinically relevant MRI abnormalities in this group is unclear.
Objective To derive a meta-analytic estimate of the prevalence of clinically relevant neuroradiological abnormalities in FEP.
Data Sources Electronic databases Ovid, MEDLINE, PubMed, Embase, PsychINFO, and Global Health were searched up to July 2021. References and citations of included articles and review articles were also searched.
Study Selection Magnetic resonance imaging studies of patients with FEP were included if they reported the frequency of intracranial radiological abnormalities.
Data Extraction and Synthesis Independent extraction was undertaken by 3 researchers and a random-effects meta-analysis of pooled proportions was calculated. Moderators were tested using subgroup and meta-regression analyses. Heterogeneity was evaluated using the I 2 index. The robustness of results was evaluated using sensitivity analyses. Publication bias was assessed using funnel plots and Egger tests.
Main Outcomes and Measures Proportion of patients with a clinically relevant radiological abnormality (defined as a change in clinical management or diagnosis); number of patients needed to scan to detect 1 such abnormality (number needed to assess [NNA]).
Results Twelve independent studies (13 samples) comprising 1613 patients with FEP were included. Of these patients, 26.4% (95% CI, 16.3%-37.9%; NNA of 4) had an intracranial radiological abnormality, and 5.9% (95% CI, 3.2%-9.0%) had a clinically relevant abnormality, yielding an NNA of 18. There were high degrees of heterogeneity among the studies for these outcomes, 95% to 73%, respectively. The most common type of clinically relevant finding was white matter abnormalities, with a prevalence of 0.9% (95% CI, 0%-2.8%), followed by cysts, with a prevalence of 0.5% (95% CI, 0%-1.4%).
Conclusions and Relevance This systematic review and meta-analysis found that 5.9% of patients presenting with a first episode of psychosis had a clinically relevant finding on MRI. Because the consequences of not detecting these abnormalities can be serious, these findings support the use of MRI as part of the initial clinical assessment of all patients with FEP.
The early diagnosis of secondary psychosis, where a psychotic disorder is caused by another medical condition, is an indispensable but complex diagnostic task in psychiatry. Because several causes of secondary psychosis result in structural brain abnormalities, 1 brain imaging is considered essential by many psychiatrists during the assessment phase. 2 Magnetic resonance imaging (MRI) is a safe and well-tolerated 3 technique that has high sensitivity for detecting intracranial abnormalities. Since its introduction more than 40 years ago, structural MRI has become increasingly available, and the costs of scanning have progressively reduced. 4 However, there is no consensus as to whether MRI scanning should be a mandatory part of the clinical assessment of patients presenting with a first episode of psychosis (FEP). Some guidelines recommend scanning all patients with FEP, 5 while others recommend that MRI be restricted to cases in which a secondary cause is suspected. 6
Most radiological abnormalities in patients with FEP are incidental and do not require any clinical action. However, a minority of abnormalities lead to a change to a patient’s clinical care. A barrier to resolving the debate about the routine use of MRI in the assessment of FEP has been uncertainty about the prevalence of clinically relevant abnormalities, with estimates ranging from 0% 7 to more than 10%. 8 Beyond guidelines for individual clinical management, there is also the issue of population health. In otherwise healthy individuals, white matter hyperintensities reliably predict later cognitive decline, greater cerebrovascular risk, and increased mortality in epidemiological studies, 9 , 10 suggesting that the presence of neuroradiological abnormalities may be an indicator of neurological health.
We sought to clarify the prevalence of intracranial abnormalities in FEP by undertaking the first meta-analysis of such studies to our knowledge. We also sought to establish the prevalence of clinically relevant abnormalities that led to a change in diagnosis or management. In addition, we examined the influence of study, patient, and imaging characteristics on outcome.
A systematic review and meta-analysis was conducted in accordance with Meta-analysis of Observational Studies in Epidemiology ( MOOSE ) 11 and Preferred Reporting Items for Systematic Reviews and Meta-analyses ( PRISMA ) guidelines, 12 and the study was prospectively registered on PROSPERO ( CRD42020140917 ). See the eMethods in Supplement 1 for details of the search strategy, eligibility criteria, and data extraction and encoding. In brief, we searched the databases Ovid, MEDLINE, PubMed, Embase, PsychINFO, and Global Health up to July 2021. References and citations of included articles and review articles were also searched.
Included studies were assessed for the risk of bias using a 10-item tool developed for prevalence studies 13 (eTable 3 in Supplement 1 ). The sum was calculated to derive a summary score. Studies were categorized based on the overall score as high (0-3), moderate (4-6), or low (7-10) risk of bias using well-established cutoffs. Studies at high risk of bias were excluded from the meta-analysis.
A radiological abnormality was defined as any intracranial finding, regardless of the evidence to suggest a causal relationship with psychosis. Radiological abnormalities were further categorized by clinical relevance. A clinically relevant finding was defined as an abnormality that was reported by the study authors as having led to a change in management (eg, referral to a medical specialty) or diagnosis. Abnormalities were also grouped into the following neuroanatomical categories: white matter, vascular (excluding white matter), ventricular, cyst, pituitary, tumor, cerebral atrophy, and other (ie, not falling into any of the aforementioned categories) by a psychiatrist (G.B.) and a neuroradiologist (A.M.), with the latter blind to diagnosis (eMethods in Supplement 1 ).
For each study, the proportion of patients with FEP and a radiological abnormality was calculated, along with the 95% CI based on the Score (Wilson) method. 14 A Freeman-Tukey double arcsine transformation 15 was used to stabilize the variance because the proportion of abnormal scans was expected to be low. 16 Transformed proportions were meta-analyzed using a random-effects inverse variance method 17 as methodological heterogeneity was anticipated. To assess the clinical usefulness of MRI, the estimated number of patients needed to be scanned to detect 1 abnormality (number needed to assess [NNA]) was calculated, based on the reciprocal of the prevalence estimate, 18 which is comparable with the numbers-needed-to-treat 19 statistic: NNA = 1 / (proportion with abnormality).
We also estimated the prevalence of the neuroanatomical subtypes of abnormalities (eTable 4 in Supplement 1 ). In addition, for studies that included a healthy control group, we calculated the risk ratio (relative risk) to explore the specific association between neuroradiological abnormalities and psychosis.
The significance level was set to P ≤ .05, and all analyses were performed using R version 4.2.1 20 with meta-analyses performed using meta. 21 , 22 Further details on the statistical analysis are reported in the eMethods in Supplement 1 , and all code and data are included in an online archive (link available on request).
Heterogeneity was assessed using the Cochran Q statistic, as well as the I 2 index, which is independent of the number of studies. Risk of publication bias was assessed thorough visual inspection of funnel plots and an Egger test. 23 Modifiers of clinically relevant abnormalities were assessed through subgroup analysis and meta regression provided there were sufficient data points. For categorical variables, we explored the effect of the sample (research vs clinical) and field strength (3 T vs <3 T) using subgroup analysis based on the Cochran Q statistic. For continuous variables, we explored the effect of sample age, psychosis duration, and year of publication using meta-regression provided at least 6 studies could be included. 24
Sensitivity analyses were performed to determine the effect of studies (1) with a mean patient age older than 35 years, (2) where assessment was performed by a nonradiologist, and (3) based on a research sample. Influential study analysis using the leave-1-out paradigm 25 was performed using the dmetar package. 26 This was performed to identify any study with an excessive influence on the pooled effect size and/or that contributed substantially to between-study heterogeneity.
The search strategy yielded 1682 publications from the database search and other sources. After duplicates were removed and abstracts screened, 240 publications were reviewed in full. eFigure 1 in Supplement 1 shows the PRISMA flowchart. In 1 study, patients with FEP had been pooled with patients with multiepisode psychosis 8 ; however, it was possible to estimate the proportion of abnormalities in the FEP subgroup group based on published details and consultation with the study authors (eMethods in Supplement 1 ). In another study, only white matter abnormalities were reported, 27 so this study was not entered into the main meta-analysis.
Twelve studies were eligible, 3 , 7 , 8 , 27 - 35 with no overlapping samples (eTable 1 in Supplement 1 contains study characteristics). Studies were published between 1991 and 2021 and reported a pooled sample of 1613 patients with FEP. Nine studies reported clinically relevant abnormalities, 3 , 7 , 8 , 27 - 30 , 32 , 34 with a pooled sample of 1318 patients. Eight studies included a healthy control group, 3 , 8 , 27 , 29 , 30 , 33 - 36 with a pooled sample of 3265 patients (FEP = 1399; control = 1866). (eTable 2 in Supplement 1 describes the recruitment, screening, and matching of healthy controls for each study.) Studies were conducted in Europe (n = 7), North America (n = 4), Australasia (n = 1), and South America (n = 1). Ten studies excluded patients in whom a potential secondary cause of psychosis was suspected before neuroimaging, such as a positive finding on a neurological examination (not reported in 2 studies).
In a minority of studies, the total number of abnormalities in the sample were reported, rather than the number of patients with an abnormality. A post hoc sensitivity analysis was therefore performed to restrict to studies that reported the total number of patients with an abnormality. All studies reporting clinically relevant abnormalities reported this at the patient level.
The FEP sample size ranged from 20 35 to 349 patients. 8 Mean age ranged from 20 to 60 years, and the proportion of female patients ranged from 27% to 70%. Five studies reported data from routine clinical practice, and 6 studies reported data from clinical research studies. One study reported data from both routine clinical practice and clinical research. 3 For the purposes of subsequent analysis, this study was split into research and clinical subsamples (therefore, 13 samples are considered henceforth). Antipsychotic status at the time of neuroimaging was reported in 6 samples (n = 714). Among these, the proportion of patients receiving antipsychotic medication was 65%. Duration of psychosis was reported in 6 samples (n = 665) and ranged between 4 and 52 weeks with the exception of 1 study, which had a mean duration of 90 weeks. 35
Scanner field strength was reported in 10 samples, with 1.5 T (n = 6) being the most common. MRI scans were interpreted by a neuroradiologist in 9 samples. In the other 3 samples, MRI scans were reported by a general radiologist (n = 1) or a psychiatrist (n = 1), or the clinician was unspecified (n = 1). In 6 samples, raters were blind to clinical status (unreported in 8 samples).
The quality assessment score ranged from 4 to 8 of 10 (eTable 2 in Supplement 1 ). Overall, 10 samples were at medium risk and 3 were at low risk of bias. No studies were at high risk of bias.
The proportion of patients with any abnormality was calculable for 12 samples (11 studies) because 1 study only reported the presence or absence of white matter abnormalities. 27 The pooled prevalence was 26.4% (95% CI, 16.3%-37.9%), with a corresponding NNA of 4 (95% CI, 3-7) ( Figure 1 ). The I 2 statistic was 95%, indicating a high degree of heterogeneity. The proportion of patients with a clinically relevant abnormality was calculable for 10 samples (9 studies). In the other samples, clinically relevant abnormalities were grouped with non–clinically relevant abnormalities. 29 , 31 , 33 The pooled prevalence was 5.9% (95% CI, 3.2%-9.0%), with a corresponding NNA of 18 (95% CI, 12-31). The I 2 statistic was 73%, indicating moderate heterogeneity.
As part of the secondary analysis, we calculated the prevalence of specific neuroanatomical abnormalities among patients with FEP ( Figure 2 ). Overall, white matter abnormalities were the most common (typically white matter hyperintensities), with a prevalence of 7.9% (95% CI, 3.0% to 14.4%), followed by ventricular abnormalities (typically ventricular enlargement), with a prevalence of 5.0% (95% CI, −1.5% to 10.0%) (eFigure 3 in Supplement 1 ). Among clinically relevant abnormalities, white matter abnormalities were the most common, with a prevalence of 0.9% (95% CI, 0% to 2.8%), followed by cysts, with a prevalence of 0.5% (95% CI, 0% to 1.4%) ( Figure 2 and eFigure 4 in Supplement 1 ).
We also calculated the pooled risk ratio of neuroanatomical abnormalities in patients with FEP vs healthy controls. Patients with FEP had a relative risk of 2.8 (95% CI, 1.3-5.9; k = 9 studies) for any radiological abnormality compared with heathy controls (eFigure 5A in Supplement 1 ). Among abnormalities that were clinically relevant, patients with FEP had a relative risk of 1.5 (95% CI, 0.8-2.8) compared with heathy controls (eFigure 5B in Supplement 1 ); however, a leave-1-out sensitivity analysis (below) indicated that this may be an underestimate.
Meta-regression found no association between the prevalence of clinically relevant abnormalities and publication year (k = 10, P = .07) or sample age (k = 9, P = .95). There were insufficient samples (k = 3) to explore the effect of psychosis duration. Subgroup analysis found no association for the effect of sample type (k = 10, P = .99) or field strength (k = 12, P = .16).
We repeated the analysis excluding samples (1) with a mean patient age older than 35 years, (2) where assessment was performed by a nonradiologist, and (3) that recruited patients for research. Removing studies under any 1 of these conditions did not result in pooled estimates becoming nonsignificant. Leave-1-out sensitivity analysis did not identify any influential samples for the meta-analysis of prevalence (eFigure 6 in Supplement 1 ). Leave-1-out sensitivity analysis indicated that the study by Khandanpour et al 30 was influential in the meta-analysis of relative risk for any abnormality, and removal adjusted the pooled relative risk to 1.8 (95% CI, 1.1-3.2). For the meta-analysis of relative risk for clinically relevant abnormalities, the study by Sommer et al 8 was identified as influential, and removal adjusted the pooled relative risk to 2.1 (95% CI, 1.1-4.0).
Inspection of funnel plots suggested no clear evidence of publication bias (eFigure 2 in Supplement 1 ), which was confirmed by nonsignificant Egger test results for studies reporting any abnormalities ( P = .36) and those reporting clinically relevant abnormalities ( P = .70).
The estimated prevalence of a radiological MRI abnormality in patients with FEP was 26%, while that of a clinically relevant abnormality was 6%. Patients with FEP had a significantly higher prevalence of radiological abnormalities overall, as well as clinically relevant abnormalities compared with healthy controls, after removal of an outlier. White matter abnormalities, predominantly small hyperintensities, were the most common finding overall and the most common clinically relevant finding. The NNA to detect 1 clinically relevant abnormality was 18.
Although the prevalence of neuroradiological abnormalities in FEP has previously been explored in systematic reviews, 4 , 37 , 38 to our knowledge, this is the first study to derive a meta-analytic estimate based on MRI data. Previous studies have reported conflicting results. The largest MRI study of patients with psychosis (n = 656) reported a higher prevalence of clinically relevant abnormalities (10.3%) in their first episode subsample compared with our meta-analytic estimate but essentially found no difference from healthy controls, who had a similarly high prevalence of clinically relevant abnormalities (11.8%). 8 This study is notable for being the only one in our meta-analysis that reported the prevalence of clinically relevant abnormalities to be lower in patients with psychosis than in controls and was identified as an outlier in the leave-1-out sensitivity analysis. Studies exploring radiological abnormalities in patients with psychosis using computed tomography (CT) have yielded substantially lower estimates than MRI. 4 , 39 This likely reflects the relative insensitivity of CT to detect intracranial abnormalities in patients with psychosis.
In otherwise healthy individuals, the prevalence of incidental clinically relevant brain abnormalities found on MRI is estimated to be 1.4% 40 to 2.7%. 18 In our study, we were able to derive the first meta-analytic estimate of the relative risk of clinically relevant brain abnormalities in FEP compared with asymptomatic healthy individuals. Our findings suggest a 2-fold increased risk, once adjusted for outliers. Research MRI studies have identified widespread differences in gray and white matter density in FEP compared with controls. However, these studies typically use voxel-based morphometry and involve alterations that are too small to be detected by the naked eye. Although most radiological abnormalities in FEP do not necessitate a change in management, it is worth noting that these apparently benign findings may be associated with relatively poor outcomes across the life span 41 and a marker of neurovascular health. 42 This suggests that they could reflect the macroscopic sequelae of suboptimal brain development and as such may represent determinants of a poor outcome, even if they do not lead to a diagnosis of secondary psychosis.
The most common neuroradiological abnormality was white matter abnormalities, predominantly small hyperintensities. They were also the most common clinically relevant abnormality reported. This finding is consistent with independent neuroimaging evidence that psychosis is associated with widely distributed anatomical and functional dysconnectivity. 43 - 45 White matter lesions are closely associated with neuroinflammatory processes in psychosis, 46 as well as immune-mediated neurological disorders such as multiple sclerosis, 47 supporting an etiological role of the immune system in psychosis.
Interestingly, we found the prevalence of brain tumors in FEP was very low (with the estimated NNA to detect 1 tumor of around 1000) despite this being one of the main concerns of psychiatrists. However, because all the studies in this meta-analysis excluded patients with clinical evidence suggestive of a secondary medical (“organic”) cause, our results are likely to underestimate the true prevalence of tumors in patients with FEP more broadly, as such cases are more likely to present with neurologic features, such as apraxia, visual field deficits, and anomia. 48
The heterogeneity between studies in the proportion of patients with any type of abnormality was large. In contrast, heterogeneity for clinically relevant abnormalities was moderate. Between-study differences in design, eligibility criteria, neuroimaging methods, and radiological assessment may have contributed to this statistical heterogeneity. We explored its basis using subgroup analysis and meta-regression. The former found no difference between studies based on sample type, rater, or field strength, and the latter found that the effects of patient age and publication year were not significant. We were not able to explore the effect of psychosis duration because of insufficient data.
We assessed the robustness of the findings using sensitivity analyses. One study 49 was identified as an outlier in the meta-analysis of risk for clinical abnormalities, and its removal resulted in the risk ratio becoming significant. Furthermore, the results remained robust to several sensitivity analyses. Our group-level estimates assumed that each patient had a maximum of 1 type of abnormality, and findings did not change substantially at a group level when we excluded studies in which this assumption could not be confirmed.
Should MRI be routinely performed in patients with FEP? One approach to resolving this debate is to consider the net clinical benefit. We were able to ascertain that 1 in 18 patients had a change in management after an MRI, and therefore it could be argued they received some clinical benefit. In contrast, clinical risks associated with MRI scanning are minimal, and most patients find the procedure acceptable. 3 Another approach is to consider the economic implications. The financial costs of a brain MRI vary considerably, and therefore the economic case for routine screening is also likely to vary. In Europe, the average cost is around $264 (€250), including evaluation by a radiologist. Based on the estimated NNA, the cost to detect 1 clinically relevant abnormality is approximately $4752 (€4500). In comparison, the financial cost is substantially higher in the United States. However, the potential costs associated with failing to identify a clinically relevant abnormality (that may include a potentially reversible cause) are also likely to be higher. While further analysis is indicated to explore the net economic benefits, provisional evaluation based on clinical grounds would favor offering MRI to all patients with FEP.
This meta-analysis provides the most precise estimate of the prevalence of neuroradiological abnormalities in FEP in the literature to date. Subgroup and meta-regression permitted the exploration of moderating factors and causes of heterogeneity, such as study characteristics and imaging parameters. Furthermore, by comparing neuroradiological abnormalities in FEP with healthy controls, we were able to determine the specificity of these abnormalities. Importantly, in most studies, FEP samples were matched with healthy controls. Other strengths included a rigorous approach to study identification and data extraction. Furthermore, because the meta-analysis focused on patients with FEP, the findings are unlikely to have been confounded by the influence of chronic illness or its treatment.
This study also had limitations. First, the studies we examined may not have included patients who were particularly unwell and/or lacked capacity. Second, around half of the studies involved patients who had undergone MRI as part of research rather than routine clinical care, and all the studies had excluded patients in whom there was clinical evidence of a potential secondary cause (based on examination and/or psychiatric assessment). These factors are likely to have resulted in an underestimate of the prevalence of clinically relevant radiological abnormalities in FEP, suggesting the true figure may be higher. Third, we assumed each patient had only 1 type of radiological abnormality. However, in a few studies, this could not be confirmed, which may have inflated the overall estimate (of note, this limitation did not apply to our estimate of clinically relevant abnormalities). Fourth, because we used aggregate data, we were unable to explore the influence of potentially relevant patient-level characteristics. Fifth, information on duration of illness and antipsychotic exposure was unavailable in several studies. Finally, included studies mostly consisted of relatively small samples, which reduces statistical precision.
Follow-up data would help determine the proportion of clinically relevant radiological abnormalities that are treatable. Similarly, it would be useful to clarify whether the presence of radiological abnormalities are associated with adverse long-term clinical outcomes. If this was the case, this may suggest a role for MRI in providing prognostic information in addition to its diagnostic role. Secondary causes of psychosis are associated with particular clinical variables, such as visual hallucinations 50 - 52 and delusions of misidentification. 53 Systematic assessment of these risk factors could complement the use of MRI to help clinicians identify patients with a secondary etiology. Further research is also indicated to explore the optimal MRI parameters for detecting radiological abnormalities.
This systematic review and meta-analysis found that around 6% of patients presenting with psychosis have a clinically relevant radiological abnormality on MRI, with a corresponding NNA of 18. These findings provide a rationale for the use of MRI in the clinical assessment of all patients presenting with psychosis. As the availability of MRI increases and its costs decrease, it is becoming increasingly difficult to justify not making MRI a mandatory part of the clinical assessment of FEP.
Accepted for Publication: May 8, 2023.
Published Online: July 12, 2023. doi:10.1001/jamapsychiatry.2023.2225
Open Access: This is an open access article distributed under the terms of the CC-BY License . © 2023 Blackman G et al. JAMA Psychiatry .
Corresponding Author: Graham Blackman, MBChB, Department of Psychiatry, University of Oxford, Warneford Hospital, Oxford OX3 7JX, United Kingdom ( [email protected] ).
Author Contributions: Dr Blackman had full access to all of the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis. Drs Kempton and McGuire contributed equally as co–senior authors.
Concept and design: Blackman, Neri, Al-Doori, Pollak, Hird, Koutsouleris, McGuire.
Acquisition, analysis, or interpretation of data: Blackman, Neri, Al-Doori, Teixeira-Dias, Mazumder, Pollak, Bell, Kempton, McGuire.
Drafting of the manuscript: Blackman, Al-Doori, Teixeira-Dias, Kempton, McGuire.
Critical revision of the manuscript for important intellectual content: Blackman, Neri, Al-Doori, Mazumder, Pollak, Hird, Koutsouleris, Bell, McGuire.
Statistical analysis: Blackman, Neri, Al-Doori, Teixeira-Dias, Bell.
Administrative, technical, or material support: Blackman, Neri, Al-Doori, Teixeira-Dias, Bell, McGuire.
Supervision: Blackman, Al-Doori, Pollak, Hird, Koutsouleris, Kempton, McGuire.
Conflict of Interest Disclosures: None reported.
Data Sharing Statement: See Supplement 2 .
Additional Contributions: We thank Iris Sommer, MD, PhD, Department of Neuroscience, University Medical Center Groningen, and Inge Winter-van Rossum, PhD, Department of Psychiatry, University of Oxford, for their assistance. They received no compensation for their contribution.
- Register for email alerts with links to free full-text articles
- Access PDFs of free articles
- Manage your interests
- Save searches and receive search alerts
How to Write a Policy Analysis Paper in 6 Easy Steps (+Examples)

Working on a policy analysis paper is both challenging and fulfilling. In this article, we'll guide you through the process, whether you're new to the field or experienced. Understanding how policies are made, evaluated, and recommended is crucial for making a difference in public discussions and decisions. We'll cover everything from defining your goals to researching thoroughly, analyzing data, and presenting persuasive arguments. By following these steps, you'll be able to communicate your ideas effectively, shape procedure debates, and contribute to positive changes in society. Should you need more hands-on aid with the assignment, hire a college essay writer for the maximum result.
What Is a Policy Analysis Paper
A policy analysis essay definition is a comprehensive examination and evaluation of a particular policy or set of policies within a given context. It involves analyzing the rationale behind the system, its objectives, implementation strategies, and its intended and unintended consequences. This type of paper aims to provide insights into the effectiveness, efficiency, equity, and feasibility of the approach, often considering various perspectives, stakeholders, and alternatives. Through rigorous research, data analysis, and critical reasoning, procedure analysis papers aim to inform decision-makers, scholars, and the public about the strengths and weaknesses of existing policies and propose recommendations for improvement or alternative courses of action.
Haven’t Written a Policy Analysis Paper Before?
Let expert writers guide you through the process!
Policy Analysis Paper Purpose
The purpose of a policy analysis paper is to critically assess a specific procedure or set of policies in order to provide valuable insights into its effectiveness, implications, and potential areas for improvement. By examining the underlying rationale, objectives, and outcomes of the implementation, this type of paper aims to inform decision-makers, stakeholders, and the public about its strengths, weaknesses, and impacts on society.
Students are writing a policy analysis paper in college for several reasons. Firstly, it allows them to develop critical thinking and analytical skills by evaluating real-world policies and their implications. Additionally, it helps students understand the complexities of policy-making processes and how policies impact various stakeholders. Writing analysis papers also enhances research and writing skills, as students must gather and synthesize information from diverse sources to support their arguments effectively. Furthermore, engaging with procedure analysis fosters civic engagement and social responsibility, encouraging students to contribute to public discourse and advocate for evidence-based solutions. Are you dealing with multiple assignments all at the same time? If you’re about to address the audience, say, ‘ write a speech for me ,’ so our experts can relieve your workload.
Topic Ideas for Policy Analysis Paper
Here’s a collection of 50 thought-provoking policy analysis paper topics for your inspiration. In addition, we’d like to offer you informative essay topics for the purpose of learning and self-education.
- The viability of a universal healthcare system: An analysis.
- Plastic bag bans: Environmental implications examined.
- Tax credits for renewable energy adoption: Assessing effectiveness.
- Social security and raising the retirement age: Exploring implications.
- Implementing a four-day workweek: Feasibility assessment.
- Community policing strategies: Effectiveness in crime reduction.
- Increasing the minimum wage: Consequences evaluated.
- School voucher programs: Impact on educational equity.
- Congestion pricing for urban areas: Benefits and drawbacks analyzed.
- Government subsidies for electric vehicles: Effectiveness assessed.
- Zoning laws and affordable housing availability: An investigation.
- National carbon tax: Feasibility and impact explored.
- Mandatory voting laws: Consequences for political participation.
- Drug rehabilitation programs: Effectiveness in reducing recidivism.
- Legalizing marijuana: Public health implications examined.
- Immigration policies and cultural diversity: Assessing impact.
- Privatizing water utilities: Consequences analyzed.
- Anti-bullying policies in schools: Effectiveness evaluated.
- Free college tuition programs: Benefits and drawbacks assessed.
- Wealth tax implementation: Feasibility analysis.
- Ride-sharing services and traditional taxi industries: Impact assessment.
- Gender quotas in corporate leadership: Effectiveness examined.
- National gun registry: Implications and feasibility explored.
- Expanding nuclear energy production: Consequences evaluated.
- Mandatory parental leave policies: Effectiveness assessment.
- Charter school expansion: Impact on public education explored.
- Basic income implementation: Viability and consequences assessed.
- Affordable housing initiatives: Success factors examined.
- Internet privacy regulations: Impact on data security analyzed.
- Corporate tax breaks: Economic implications assessed.
- Universal preschool programs: Long-term benefits explored.
- Climate change adaptation policies: Effectiveness in resilience building.
- Universal voting by mail: Implications for voter turnout examined.
- Reducing military spending: Consequences and feasibility analyzed.
- Workplace diversity training: Effectiveness in promoting inclusivity.
- Renewable energy subsidies: Impact on energy independence assessed.
- Telecommuting incentives: Feasibility and impact on traffic analyzed.
- Carbon capture and storage initiatives: Viability and effectiveness.
- Local food sourcing policies: Benefits for communities examined.
- Police body camera mandates: Impact on accountability assessed.
- Community land trust programs: Success factors and limitations.
- Mental health parity laws: Effectiveness in improving access.
- Corporate social responsibility regulations: Impact on sustainability.
- Universal pre-kindergarten education: Social and economic benefits.
- Land value tax implementation: Impact on property markets assessed.
- Affordable childcare initiatives: Impact on workforce participation.
- Smart city technology investments: Benefits for urban development.
- Flexible work hour policies: Impact on productivity and well-being.
- Prescription drug pricing regulations: Consequences for affordability.
- Public-private partnerships for infrastructure development: Effectiveness and risks assessed.
If you need more ideas, you may want to consult our guide on argumentative essay topics , which will definitely help kickstart your creativity.
How to Structure a Policy Analysis Paper
A policy analysis paper format demands organizing your content coherently and logically to effectively communicate your analysis and findings. Here's a typical structure you can follow:
.webp "how to write an analysis of data")
Introduction
- Provide an overview of the issue or problem you're analyzing.
- Clearly state the purpose of your analysis.
- Introduce the policy or policies under review.
- Provide background information to contextualize the issue.
- State your thesis or research question.
Policy Context and Background
- Provide more in-depth background information on the issue.
- Describe the historical development of the policies.
- Discuss the context in which the procedure was implemented.
- Identify key stakeholders and their interests in the strategy.
Policy Analysis Framework
- Explain the framework or methodology you're using to analyze the policy.
- Define key concepts and terms relevant to your analysis.
- Discuss any theoretical frameworks or models guiding your analysis.
- Outline the criteria or criteria you will use to evaluate the procedure's effectiveness.
Policy Goals and Objectives
- Identify and discuss the stated goals and objectives of the policy.
- Evaluate the clarity and coherence of these goals.
- Discuss any potential conflicts or contradictions among the goals.
Policy Implementation
- Describe how the policy has been implemented in practice.
- Discuss any challenges or barriers to implementation.
- Evaluate the effectiveness of implementation strategies.
Policy Outcomes and Impacts
- Assess the outcomes and impacts of the policy.
- Evaluate the extent to which the procedure has achieved its intended goals.
- Discuss any unintended consequences or side effects of the approach.
Policy Alternatives
- Identify and discuss alternative policy options or approaches.
- Evaluate the strengths and weaknesses of each alternative.
- Discuss the potential trade-offs associated with each alternative.
Recommendations
- Based on your analysis, provide recommendations for policymakers.
- Discuss specific actions or changes that could improve the process.
- Justify your recommendations with evidence from your analysis.
- Summarize the main findings of your analysis.
- Restate your thesis or research question.
- Reflect on the broader implications of your analysis.
- Discuss any limitations or areas for further research.
- Provide a list of sources cited in your paper.
- Follow the appropriate citation style (e.g., APA, MLA, Chicago).
Need help with the assignment at this stage? Use our political science essay assistance to save time and secure optimal academic results.
How to Write a Policy Analysis Paper
In this section, we'll cover the basics of writing a policy analysis paper. This type of paper involves breaking down complicated policy issues, figuring out how well they're working, and suggesting ways to make them better. We'll walk you through the steps, like defining the goals of the implementation, looking at how it's being put into action, and checking what effects it's having. By the end, you'll have the skills to write a clear, well-reasoned paper that can help shape policies for the better.
.webp "how to write an analysis of data")
Understanding the Policy Issue
Start by thoroughly understanding the policy issue or problem you're analyzing. Research its background, context, and significance. Identify key stakeholders, relevant laws or regulations, and any existing policies addressing the issue.
Defining the Scope and Purpose
Clearly define the scope and purpose of your analysis. Determine what specific aspect of the approach you'll focus on and why it's important. Clarify the goals of your analysis and what you hope to achieve with your paper. Use an expert essay writing service to streamline your effort in producing a first-class paper.
Gathering Data and Evidence
Collect relevant data and evidence to support your analysis. This may include statistical information, case studies, expert opinions, and academic research. Use credible sources and ensure your data is accurate and up-to-date.
Analyzing the Policy
A policy analysis paper evaluates the legislative program’s effectiveness, strengths, weaknesses, and implications. Use a structured approach, such as a SWOT analysis (Strengths, Weaknesses, Opportunities, Threats) or cost-benefit analysis, to assess the procedure from multiple perspectives. Consider its intended goals, implementation strategies, outcomes, and unintended consequences. If you need help with SWOT analysis, using our analytical essay writing service is highly recommended.
Developing Recommendations
Based on your analysis, develop clear and actionable recommendations for policymakers or stakeholders. Identify specific changes or improvements that could enhance the system’s effectiveness or address its shortcomings. Support your recommendations with evidence and reasoning.
Writing and Communicating Your Analysis
Organize your analysis into a coherent and persuasive paper. Structure your paper with an introduction, background information, analysis, recommendations, and conclusion. Use clear and concise language, avoiding jargon or technical terms unless necessary. Provide citations for your sources and evidence. Finally, ensure your paper is well-written, logically organized, and effectively communicates your insights and recommendations.
Policy Analysis Paper Example
A policy analysis paper example serves as a valuable learning tool for students by providing a concrete model to follow and reference when undertaking their own analysis assignments. By studying an example paper, students can gain insights into the structure, content, and methodology of analysis, helping them understand how to effectively frame their analysis, support their arguments with evidence, and formulate actionable recommendations.
Example 1: “Implementing Universal Basic Income”
This policy analysis paper examines the feasibility and potential impacts of implementing a Universal Basic Income (UBI) program in the United States. It explores various options for UBI design, including cost and financing considerations, labor market effects, poverty reduction potential, and administrative feasibility. By reviewing existing evidence and debates surrounding UBI, the paper aims to provide a comprehensive understanding of the opportunities and challenges associated with adopting such a program, ultimately highlighting the need for careful analysis, experimentation, and stakeholder engagement in shaping effective UBI policies.
Example 2: “Addressing Climate Change through Carbon Pricing”
This policy analysis paper examines the role of carbon pricing policies in addressing climate change, evaluating their efficacy, implementation challenges, and potential impacts. Carbon pricing mechanisms, including carbon taxes and cap-and-trade systems, aim to internalize the external costs of carbon emissions and incentivize emission reductions. The paper discusses the economic efficiency of carbon pricing in promoting innovation and investment in clean technologies while also addressing equity considerations regarding its distributional impacts on low-income households and vulnerable communities.
Writing a policy analysis paper is super important for students because it helps them learn how to tackle tough societal problems and make smart decisions. You get to sharpen your thinking skills, learn how to research thoroughly and become better at expressing yourself clearly. Plus, writing these papers helps students practice effectively communicating their ideas, which is a skill they'll need in their future careers, whether they work in government, nonprofits, or elsewhere. By digging into real-world issues, students also get a better grip on how politics, economics, and society all fit together. If you’re not committed to handling this task yourself, instruct our experts, saying, ‘ write my essay ,’ and receive the most competent help within hours.
How Short Is Your Deadline?
Use our writing service to submit an A-grade policy analysis paper on time.
What Is a Policy Analysis Paper Outline?
How to write a policy analysis paper, what is a policy analysis paper, related articles.
.webp "how to write an analysis of data")

An official website of the United States government
Here’s how you know
Official websites use .gov A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS A lock ( Lock A locked padlock ) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
JavaScript appears to be disabled on this computer. Please click here to see any active alerts .
Why is Page 34 In the "data interpretation, statistical analysis and report writing, item (3) of effective plans" empty?
Thank you for bringing this to our attention. It appears there was an issue converting the document to a PDF. The missing text will be reflected in a modification to the RFA which will be posted to grants.gov and the EPA's RFA website as soon as possible.
- Great Lakes Funding Home
- About Great Lakes Funding
- Great Lakes Restoration Initiative (GLRI)
- Previous Grant Awards
- Request for Applications
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 26 March 2024
Predicting and improving complex beer flavor through machine learning
- Michiel Schreurs ORCID: orcid.org/0000-0002-9449-5619 1 , 2 , 3 na1 ,
- Supinya Piampongsant 1 , 2 , 3 na1 ,
- Miguel Roncoroni ORCID: orcid.org/0000-0001-7461-1427 1 , 2 , 3 na1 ,
- Lloyd Cool ORCID: orcid.org/0000-0001-9936-3124 1 , 2 , 3 , 4 ,
- Beatriz Herrera-Malaver ORCID: orcid.org/0000-0002-5096-9974 1 , 2 , 3 ,
- Christophe Vanderaa ORCID: orcid.org/0000-0001-7443-5427 4 ,
- Florian A. Theßeling 1 , 2 , 3 ,
- Łukasz Kreft ORCID: orcid.org/0000-0001-7620-4657 5 ,
- Alexander Botzki ORCID: orcid.org/0000-0001-6691-4233 5 ,
- Philippe Malcorps 6 ,
- Luk Daenen 6 ,
- Tom Wenseleers ORCID: orcid.org/0000-0002-1434-861X 4 &
- Kevin J. Verstrepen ORCID: orcid.org/0000-0002-3077-6219 1 , 2 , 3
Nature Communications volume 15 , Article number: 2368 ( 2024 ) Cite this article
39k Accesses
749 Altmetric
Metrics details
- Chemical engineering
- Gas chromatography
- Machine learning
- Metabolomics
- Taste receptors
The perception and appreciation of food flavor depends on many interacting chemical compounds and external factors, and therefore proves challenging to understand and predict. Here, we combine extensive chemical and sensory analyses of 250 different beers to train machine learning models that allow predicting flavor and consumer appreciation. For each beer, we measure over 200 chemical properties, perform quantitative descriptive sensory analysis with a trained tasting panel and map data from over 180,000 consumer reviews to train 10 different machine learning models. The best-performing algorithm, Gradient Boosting, yields models that significantly outperform predictions based on conventional statistics and accurately predict complex food features and consumer appreciation from chemical profiles. Model dissection allows identifying specific and unexpected compounds as drivers of beer flavor and appreciation. Adding these compounds results in variants of commercial alcoholic and non-alcoholic beers with improved consumer appreciation. Together, our study reveals how big data and machine learning uncover complex links between food chemistry, flavor and consumer perception, and lays the foundation to develop novel, tailored foods with superior flavors.
Similar content being viewed by others

BitterSweet: Building machine learning models for predicting the bitter and sweet taste of small molecules
Rudraksh Tuwani, Somin Wadhwa & Ganesh Bagler

Sensory lexicon and aroma volatiles analysis of brewing malt
Xiaoxia Su, Miao Yu, … Tianyi Du

Predicting odor from molecular structure: a multi-label classification approach
Kushagra Saini & Venkatnarayan Ramanathan
Introduction
Predicting and understanding food perception and appreciation is one of the major challenges in food science. Accurate modeling of food flavor and appreciation could yield important opportunities for both producers and consumers, including quality control, product fingerprinting, counterfeit detection, spoilage detection, and the development of new products and product combinations (food pairing) 1 , 2 , 3 , 4 , 5 , 6 . Accurate models for flavor and consumer appreciation would contribute greatly to our scientific understanding of how humans perceive and appreciate flavor. Moreover, accurate predictive models would also facilitate and standardize existing food assessment methods and could supplement or replace assessments by trained and consumer tasting panels, which are variable, expensive and time-consuming 7 , 8 , 9 . Lastly, apart from providing objective, quantitative, accurate and contextual information that can help producers, models can also guide consumers in understanding their personal preferences 10 .
Despite the myriad of applications, predicting food flavor and appreciation from its chemical properties remains a largely elusive goal in sensory science, especially for complex food and beverages 11 , 12 . A key obstacle is the immense number of flavor-active chemicals underlying food flavor. Flavor compounds can vary widely in chemical structure and concentration, making them technically challenging and labor-intensive to quantify, even in the face of innovations in metabolomics, such as non-targeted metabolic fingerprinting 13 , 14 . Moreover, sensory analysis is perhaps even more complicated. Flavor perception is highly complex, resulting from hundreds of different molecules interacting at the physiochemical and sensorial level. Sensory perception is often non-linear, characterized by complex and concentration-dependent synergistic and antagonistic effects 15 , 16 , 17 , 18 , 19 , 20 , 21 that are further convoluted by the genetics, environment, culture and psychology of consumers 22 , 23 , 24 . Perceived flavor is therefore difficult to measure, with problems of sensitivity, accuracy, and reproducibility that can only be resolved by gathering sufficiently large datasets 25 . Trained tasting panels are considered the prime source of quality sensory data, but require meticulous training, are low throughput and high cost. Public databases containing consumer reviews of food products could provide a valuable alternative, especially for studying appreciation scores, which do not require formal training 25 . Public databases offer the advantage of amassing large amounts of data, increasing the statistical power to identify potential drivers of appreciation. However, public datasets suffer from biases, including a bias in the volunteers that contribute to the database, as well as confounding factors such as price, cult status and psychological conformity towards previous ratings of the product.
Classical multivariate statistics and machine learning methods have been used to predict flavor of specific compounds by, for example, linking structural properties of a compound to its potential biological activities or linking concentrations of specific compounds to sensory profiles 1 , 26 . Importantly, most previous studies focused on predicting organoleptic properties of single compounds (often based on their chemical structure) 27 , 28 , 29 , 30 , 31 , 32 , 33 , thus ignoring the fact that these compounds are present in a complex matrix in food or beverages and excluding complex interactions between compounds. Moreover, the classical statistics commonly used in sensory science 34 , 35 , 36 , 37 , 38 , 39 require a large sample size and sufficient variance amongst predictors to create accurate models. They are not fit for studying an extensive set of hundreds of interacting flavor compounds, since they are sensitive to outliers, have a high tendency to overfit and are less suited for non-linear and discontinuous relationships 40 .
In this study, we combine extensive chemical analyses and sensory data of a set of different commercial beers with machine learning approaches to develop models that predict taste, smell, mouthfeel and appreciation from compound concentrations. Beer is particularly suited to model the relationship between chemistry, flavor and appreciation. First, beer is a complex product, consisting of thousands of flavor compounds that partake in complex sensory interactions 41 , 42 , 43 . This chemical diversity arises from the raw materials (malt, yeast, hops, water and spices) and biochemical conversions during the brewing process (kilning, mashing, boiling, fermentation, maturation and aging) 44 , 45 . Second, the advent of the internet saw beer consumers embrace online review platforms, such as RateBeer (ZX Ventures, Anheuser-Busch InBev SA/NV) and BeerAdvocate (Next Glass, inc.). In this way, the beer community provides massive data sets of beer flavor and appreciation scores, creating extraordinarily large sensory databases to complement the analyses of our professional sensory panel. Specifically, we characterize over 200 chemical properties of 250 commercial beers, spread across 22 beer styles, and link these to the descriptive sensory profiling data of a 16-person in-house trained tasting panel and data acquired from over 180,000 public consumer reviews. These unique and extensive datasets enable us to train a suite of machine learning models to predict flavor and appreciation from a beer’s chemical profile. Dissection of the best-performing models allows us to pinpoint specific compounds as potential drivers of beer flavor and appreciation. Follow-up experiments confirm the importance of these compounds and ultimately allow us to significantly improve the flavor and appreciation of selected commercial beers. Together, our study represents a significant step towards understanding complex flavors and reinforces the value of machine learning to develop and refine complex foods. In this way, it represents a stepping stone for further computer-aided food engineering applications 46 .
To generate a comprehensive dataset on beer flavor, we selected 250 commercial Belgian beers across 22 different beer styles (Supplementary Fig. S1 ). Beers with ≤ 4.2% alcohol by volume (ABV) were classified as non-alcoholic and low-alcoholic. Blonds and Tripels constitute a significant portion of the dataset (12.4% and 11.2%, respectively) reflecting their presence on the Belgian beer market and the heterogeneity of beers within these styles. By contrast, lager beers are less diverse and dominated by a handful of brands. Rare styles such as Brut or Faro make up only a small fraction of the dataset (2% and 1%, respectively) because fewer of these beers are produced and because they are dominated by distinct characteristics in terms of flavor and chemical composition.
Extensive analysis identifies relationships between chemical compounds in beer
For each beer, we measured 226 different chemical properties, including common brewing parameters such as alcohol content, iso-alpha acids, pH, sugar concentration 47 , and over 200 flavor compounds (Methods, Supplementary Table S1 ). A large portion (37.2%) are terpenoids arising from hopping, responsible for herbal and fruity flavors 16 , 48 . A second major category are yeast metabolites, such as esters and alcohols, that result in fruity and solvent notes 48 , 49 , 50 . Other measured compounds are primarily derived from malt, or other microbes such as non- Saccharomyces yeasts and bacteria (‘wild flora’). Compounds that arise from spices or staling are labeled under ‘Others’. Five attributes (caloric value, total acids and total ester, hop aroma and sulfur compounds) are calculated from multiple individually measured compounds.
As a first step in identifying relationships between chemical properties, we determined correlations between the concentrations of the compounds (Fig. 1 , upper panel, Supplementary Data 1 and 2 , and Supplementary Fig. S2 . For the sake of clarity, only a subset of the measured compounds is shown in Fig. 1 ). Compounds of the same origin typically show a positive correlation, while absence of correlation hints at parameters varying independently. For example, the hop aroma compounds citronellol, and alpha-terpineol show moderate correlations with each other (Spearman’s rho=0.39 and 0.57), but not with the bittering hop component iso-alpha acids (Spearman’s rho=0.16 and −0.07). This illustrates how brewers can independently modify hop aroma and bitterness by selecting hop varieties and dosage time. If hops are added early in the boiling phase, chemical conversions increase bitterness while aromas evaporate, conversely, late addition of hops preserves aroma but limits bitterness 51 . Similarly, hop-derived iso-alpha acids show a strong anti-correlation with lactic acid and acetic acid, likely reflecting growth inhibition of lactic acid and acetic acid bacteria, or the consequent use of fewer hops in sour beer styles, such as West Flanders ales and Fruit beers, that rely on these bacteria for their distinct flavors 52 . Finally, yeast-derived esters (ethyl acetate, ethyl decanoate, ethyl hexanoate, ethyl octanoate) and alcohols (ethanol, isoamyl alcohol, isobutanol, and glycerol), correlate with Spearman coefficients above 0.5, suggesting that these secondary metabolites are correlated with the yeast genetic background and/or fermentation parameters and may be difficult to influence individually, although the choice of yeast strain may offer some control 53 .

Spearman rank correlations are shown. Descriptors are grouped according to their origin (malt (blue), hops (green), yeast (red), wild flora (yellow), Others (black)), and sensory aspect (aroma, taste, palate, and overall appreciation). Please note that for the chemical compounds, for the sake of clarity, only a subset of the total number of measured compounds is shown, with an emphasis on the key compounds for each source. For more details, see the main text and Methods section. Chemical data can be found in Supplementary Data 1 , correlations between all chemical compounds are depicted in Supplementary Fig. S2 and correlation values can be found in Supplementary Data 2 . See Supplementary Data 4 for sensory panel assessments and Supplementary Data 5 for correlation values between all sensory descriptors.
Interestingly, different beer styles show distinct patterns for some flavor compounds (Supplementary Fig. S3 ). These observations agree with expectations for key beer styles, and serve as a control for our measurements. For instance, Stouts generally show high values for color (darker), while hoppy beers contain elevated levels of iso-alpha acids, compounds associated with bitter hop taste. Acetic and lactic acid are not prevalent in most beers, with notable exceptions such as Kriek, Lambic, Faro, West Flanders ales and Flanders Old Brown, which use acid-producing bacteria ( Lactobacillus and Pediococcus ) or unconventional yeast ( Brettanomyces ) 54 , 55 . Glycerol, ethanol and esters show similar distributions across all beer styles, reflecting their common origin as products of yeast metabolism during fermentation 45 , 53 . Finally, low/no-alcohol beers contain low concentrations of glycerol and esters. This is in line with the production process for most of the low/no-alcohol beers in our dataset, which are produced through limiting fermentation or by stripping away alcohol via evaporation or dialysis, with both methods having the unintended side-effect of reducing the amount of flavor compounds in the final beer 56 , 57 .
Besides expected associations, our data also reveals less trivial associations between beer styles and specific parameters. For example, geraniol and citronellol, two monoterpenoids responsible for citrus, floral and rose flavors and characteristic of Citra hops, are found in relatively high amounts in Christmas, Saison, and Brett/co-fermented beers, where they may originate from terpenoid-rich spices such as coriander seeds instead of hops 58 .
Tasting panel assessments reveal sensorial relationships in beer
To assess the sensory profile of each beer, a trained tasting panel evaluated each of the 250 beers for 50 sensory attributes, including different hop, malt and yeast flavors, off-flavors and spices. Panelists used a tasting sheet (Supplementary Data 3 ) to score the different attributes. Panel consistency was evaluated by repeating 12 samples across different sessions and performing ANOVA. In 95% of cases no significant difference was found across sessions ( p > 0.05), indicating good panel consistency (Supplementary Table S2 ).
Aroma and taste perception reported by the trained panel are often linked (Fig. 1 , bottom left panel and Supplementary Data 4 and 5 ), with high correlations between hops aroma and taste (Spearman’s rho=0.83). Bitter taste was found to correlate with hop aroma and taste in general (Spearman’s rho=0.80 and 0.69), and particularly with “grassy” noble hops (Spearman’s rho=0.75). Barnyard flavor, most often associated with sour beers, is identified together with stale hops (Spearman’s rho=0.97) that are used in these beers. Lactic and acetic acid, which often co-occur, are correlated (Spearman’s rho=0.66). Interestingly, sweetness and bitterness are anti-correlated (Spearman’s rho = −0.48), confirming the hypothesis that they mask each other 59 , 60 . Beer body is highly correlated with alcohol (Spearman’s rho = 0.79), and overall appreciation is found to correlate with multiple aspects that describe beer mouthfeel (alcohol, carbonation; Spearman’s rho= 0.32, 0.39), as well as with hop and ester aroma intensity (Spearman’s rho=0.39 and 0.35).
Similar to the chemical analyses, sensorial analyses confirmed typical features of specific beer styles (Supplementary Fig. S4 ). For example, sour beers (Faro, Flanders Old Brown, Fruit beer, Kriek, Lambic, West Flanders ale) were rated acidic, with flavors of both acetic and lactic acid. Hoppy beers were found to be bitter and showed hop-associated aromas like citrus and tropical fruit. Malt taste is most detected among scotch, stout/porters, and strong ales, while low/no-alcohol beers, which often have a reputation for being ‘worty’ (reminiscent of unfermented, sweet malt extract) appear in the middle. Unsurprisingly, hop aromas are most strongly detected among hoppy beers. Like its chemical counterpart (Supplementary Fig. S3 ), acidity shows a right-skewed distribution, with the most acidic beers being Krieks, Lambics, and West Flanders ales.
Tasting panel assessments of specific flavors correlate with chemical composition
We find that the concentrations of several chemical compounds strongly correlate with specific aroma or taste, as evaluated by the tasting panel (Fig. 2 , Supplementary Fig. S5 , Supplementary Data 6 ). In some cases, these correlations confirm expectations and serve as a useful control for data quality. For example, iso-alpha acids, the bittering compounds in hops, strongly correlate with bitterness (Spearman’s rho=0.68), while ethanol and glycerol correlate with tasters’ perceptions of alcohol and body, the mouthfeel sensation of fullness (Spearman’s rho=0.82/0.62 and 0.72/0.57 respectively) and darker color from roasted malts is a good indication of malt perception (Spearman’s rho=0.54).

Heatmap colors indicate Spearman’s Rho. Axes are organized according to sensory categories (aroma, taste, mouthfeel, overall), chemical categories and chemical sources in beer (malt (blue), hops (green), yeast (red), wild flora (yellow), Others (black)). See Supplementary Data 6 for all correlation values.
Interestingly, for some relationships between chemical compounds and perceived flavor, correlations are weaker than expected. For example, the rose-smelling phenethyl acetate only weakly correlates with floral aroma. This hints at more complex relationships and interactions between compounds and suggests a need for a more complex model than simple correlations. Lastly, we uncovered unexpected correlations. For instance, the esters ethyl decanoate and ethyl octanoate appear to correlate slightly with hop perception and bitterness, possibly due to their fruity flavor. Iron is anti-correlated with hop aromas and bitterness, most likely because it is also anti-correlated with iso-alpha acids. This could be a sign of metal chelation of hop acids 61 , given that our analyses measure unbound hop acids and total iron content, or could result from the higher iron content in dark and Fruit beers, which typically have less hoppy and bitter flavors 62 .
Public consumer reviews complement expert panel data
To complement and expand the sensory data of our trained tasting panel, we collected 180,000 reviews of our 250 beers from the online consumer review platform RateBeer. This provided numerical scores for beer appearance, aroma, taste, palate, overall quality as well as the average overall score.
Public datasets are known to suffer from biases, such as price, cult status and psychological conformity towards previous ratings of a product. For example, prices correlate with appreciation scores for these online consumer reviews (rho=0.49, Supplementary Fig. S6 ), but not for our trained tasting panel (rho=0.19). This suggests that prices affect consumer appreciation, which has been reported in wine 63 , while blind tastings are unaffected. Moreover, we observe that some beer styles, like lagers and non-alcoholic beers, generally receive lower scores, reflecting that online reviewers are mostly beer aficionados with a preference for specialty beers over lager beers. In general, we find a modest correlation between our trained panel’s overall appreciation score and the online consumer appreciation scores (Fig. 3 , rho=0.29). Apart from the aforementioned biases in the online datasets, serving temperature, sample freshness and surroundings, which are all tightly controlled during the tasting panel sessions, can vary tremendously across online consumers and can further contribute to (among others, appreciation) differences between the two categories of tasters. Importantly, in contrast to the overall appreciation scores, for many sensory aspects the results from the professional panel correlated well with results obtained from RateBeer reviews. Correlations were highest for features that are relatively easy to recognize even for untrained tasters, like bitterness, sweetness, alcohol and malt aroma (Fig. 3 and below).

RateBeer text mining results can be found in Supplementary Data 7 . Rho values shown are Spearman correlation values, with asterisks indicating significant correlations ( p < 0.05, two-sided). All p values were smaller than 0.001, except for Esters aroma (0.0553), Esters taste (0.3275), Esters aroma—banana (0.0019), Coriander (0.0508) and Diacetyl (0.0134).
Besides collecting consumer appreciation from these online reviews, we developed automated text analysis tools to gather additional data from review texts (Supplementary Data 7 ). Processing review texts on the RateBeer database yielded comparable results to the scores given by the trained panel for many common sensory aspects, including acidity, bitterness, sweetness, alcohol, malt, and hop tastes (Fig. 3 ). This is in line with what would be expected, since these attributes require less training for accurate assessment and are less influenced by environmental factors such as temperature, serving glass and odors in the environment. Consumer reviews also correlate well with our trained panel for 4-vinyl guaiacol, a compound associated with a very characteristic aroma. By contrast, correlations for more specific aromas like ester, coriander or diacetyl are underrepresented in the online reviews, underscoring the importance of using a trained tasting panel and standardized tasting sheets with explicit factors to be scored for evaluating specific aspects of a beer. Taken together, our results suggest that public reviews are trustworthy for some, but not all, flavor features and can complement or substitute taste panel data for these sensory aspects.
Models can predict beer sensory profiles from chemical data
The rich datasets of chemical analyses, tasting panel assessments and public reviews gathered in the first part of this study provided us with a unique opportunity to develop predictive models that link chemical data to sensorial features. Given the complexity of beer flavor, basic statistical tools such as correlations or linear regression may not always be the most suitable for making accurate predictions. Instead, we applied different machine learning models that can model both simple linear and complex interactive relationships. Specifically, we constructed a set of regression models to predict (a) trained panel scores for beer flavor and quality and (b) public reviews’ appreciation scores from beer chemical profiles. We trained and tested 10 different models (Methods), 3 linear regression-based models (simple linear regression with first-order interactions (LR), lasso regression with first-order interactions (Lasso), partial least squares regressor (PLSR)), 5 decision tree models (AdaBoost regressor (ABR), extra trees (ET), gradient boosting regressor (GBR), random forest (RF) and XGBoost regressor (XGBR)), 1 support vector regression (SVR), and 1 artificial neural network (ANN) model.
To compare the performance of our machine learning models, the dataset was randomly split into a training and test set, stratified by beer style. After a model was trained on data in the training set, its performance was evaluated on its ability to predict the test dataset obtained from multi-output models (based on the coefficient of determination, see Methods). Additionally, individual-attribute models were ranked per descriptor and the average rank was calculated, as proposed by Korneva et al. 64 . Importantly, both ways of evaluating the models’ performance agreed in general. Performance of the different models varied (Table 1 ). It should be noted that all models perform better at predicting RateBeer results than results from our trained tasting panel. One reason could be that sensory data is inherently variable, and this variability is averaged out with the large number of public reviews from RateBeer. Additionally, all tree-based models perform better at predicting taste than aroma. Linear models (LR) performed particularly poorly, with negative R 2 values, due to severe overfitting (training set R 2 = 1). Overfitting is a common issue in linear models with many parameters and limited samples, especially with interaction terms further amplifying the number of parameters. L1 regularization (Lasso) successfully overcomes this overfitting, out-competing multiple tree-based models on the RateBeer dataset. Similarly, the dimensionality reduction of PLSR avoids overfitting and improves performance, to some extent. Still, tree-based models (ABR, ET, GBR, RF and XGBR) show the best performance, out-competing the linear models (LR, Lasso, PLSR) commonly used in sensory science 65 .
GBR models showed the best overall performance in predicting sensory responses from chemical information, with R 2 values up to 0.75 depending on the predicted sensory feature (Supplementary Table S4 ). The GBR models predict consumer appreciation (RateBeer) better than our trained panel’s appreciation (R 2 value of 0.67 compared to R 2 value of 0.09) (Supplementary Table S3 and Supplementary Table S4 ). ANN models showed intermediate performance, likely because neural networks typically perform best with larger datasets 66 . The SVR shows intermediate performance, mostly due to the weak predictions of specific attributes that lower the overall performance (Supplementary Table S4 ).
Model dissection identifies specific, unexpected compounds as drivers of consumer appreciation
Next, we leveraged our models to infer important contributors to sensory perception and consumer appreciation. Consumer preference is a crucial sensory aspects, because a product that shows low consumer appreciation scores often does not succeed commercially 25 . Additionally, the requirement for a large number of representative evaluators makes consumer trials one of the more costly and time-consuming aspects of product development. Hence, a model for predicting chemical drivers of overall appreciation would be a welcome addition to the available toolbox for food development and optimization.
Since GBR models on our RateBeer dataset showed the best overall performance, we focused on these models. Specifically, we used two approaches to identify important contributors. First, rankings of the most important predictors for each sensorial trait in the GBR models were obtained based on impurity-based feature importance (mean decrease in impurity). High-ranked parameters were hypothesized to be either the true causal chemical properties underlying the trait, to correlate with the actual causal properties, or to take part in sensory interactions affecting the trait 67 (Fig. 4A ). In a second approach, we used SHAP 68 to determine which parameters contributed most to the model for making predictions of consumer appreciation (Fig. 4B ). SHAP calculates parameter contributions to model predictions on a per-sample basis, which can be aggregated into an importance score.

A The impurity-based feature importance (mean deviance in impurity, MDI) calculated from the Gradient Boosting Regression (GBR) model predicting RateBeer appreciation scores. The top 15 highest ranked chemical properties are shown. B SHAP summary plot for the top 15 parameters contributing to our GBR model. Each point on the graph represents a sample from our dataset. The color represents the concentration of that parameter, with bluer colors representing low values and redder colors representing higher values. Greater absolute values on the horizontal axis indicate a higher impact of the parameter on the prediction of the model. C Spearman correlations between the 15 most important chemical properties and consumer overall appreciation. Numbers indicate the Spearman Rho correlation coefficient, and the rank of this correlation compared to all other correlations. The top 15 important compounds were determined using SHAP (panel B).
Both approaches identified ethyl acetate as the most predictive parameter for beer appreciation (Fig. 4 ). Ethyl acetate is the most abundant ester in beer with a typical ‘fruity’, ‘solvent’ and ‘alcoholic’ flavor, but is often considered less important than other esters like isoamyl acetate. The second most important parameter identified by SHAP is ethanol, the most abundant beer compound after water. Apart from directly contributing to beer flavor and mouthfeel, ethanol drastically influences the physical properties of beer, dictating how easily volatile compounds escape the beer matrix to contribute to beer aroma 69 . Importantly, it should also be noted that the importance of ethanol for appreciation is likely inflated by the very low appreciation scores of non-alcoholic beers (Supplementary Fig. S4 ). Despite not often being considered a driver of beer appreciation, protein level also ranks highly in both approaches, possibly due to its effect on mouthfeel and body 70 . Lactic acid, which contributes to the tart taste of sour beers, is the fourth most important parameter identified by SHAP, possibly due to the generally high appreciation of sour beers in our dataset.
Interestingly, some of the most important predictive parameters for our model are not well-established as beer flavors or are even commonly regarded as being negative for beer quality. For example, our models identify methanethiol and ethyl phenyl acetate, an ester commonly linked to beer staling 71 , as a key factor contributing to beer appreciation. Although there is no doubt that high concentrations of these compounds are considered unpleasant, the positive effects of modest concentrations are not yet known 72 , 73 .
To compare our approach to conventional statistics, we evaluated how well the 15 most important SHAP-derived parameters correlate with consumer appreciation (Fig. 4C ). Interestingly, only 6 of the properties derived by SHAP rank amongst the top 15 most correlated parameters. For some chemical compounds, the correlations are so low that they would have likely been considered unimportant. For example, lactic acid, the fourth most important parameter, shows a bimodal distribution for appreciation, with sour beers forming a separate cluster, that is missed entirely by the Spearman correlation. Additionally, the correlation plots reveal outliers, emphasizing the need for robust analysis tools. Together, this highlights the need for alternative models, like the Gradient Boosting model, that better grasp the complexity of (beer) flavor.
Finally, to observe the relationships between these chemical properties and their predicted targets, partial dependence plots were constructed for the six most important predictors of consumer appreciation 74 , 75 , 76 (Supplementary Fig. S7 ). One-way partial dependence plots show how a change in concentration affects the predicted appreciation. These plots reveal an important limitation of our models: appreciation predictions remain constant at ever-increasing concentrations. This implies that once a threshold concentration is reached, further increasing the concentration does not affect appreciation. This is false, as it is well-documented that certain compounds become unpleasant at high concentrations, including ethyl acetate (‘nail polish’) 77 and methanethiol (‘sulfury’ and ‘rotten cabbage’) 78 . The inability of our models to grasp that flavor compounds have optimal levels, above which they become negative, is a consequence of working with commercial beer brands where (off-)flavors are rarely too high to negatively impact the product. The two-way partial dependence plots show how changing the concentration of two compounds influences predicted appreciation, visualizing their interactions (Supplementary Fig. S7 ). In our case, the top 5 parameters are dominated by additive or synergistic interactions, with high concentrations for both compounds resulting in the highest predicted appreciation.
To assess the robustness of our best-performing models and model predictions, we performed 100 iterations of the GBR, RF and ET models. In general, all iterations of the models yielded similar performance (Supplementary Fig. S8 ). Moreover, the main predictors (including the top predictors ethanol and ethyl acetate) remained virtually the same, especially for GBR and RF. For the iterations of the ET model, we did observe more variation in the top predictors, which is likely a consequence of the model’s inherent random architecture in combination with co-correlations between certain predictors. However, even in this case, several of the top predictors (ethanol and ethyl acetate) remain unchanged, although their rank in importance changes (Supplementary Fig. S8 ).
Next, we investigated if a combination of RateBeer and trained panel data into one consolidated dataset would lead to stronger models, under the hypothesis that such a model would suffer less from bias in the datasets. A GBR model was trained to predict appreciation on the combined dataset. This model underperformed compared to the RateBeer model, both in the native case and when including a dataset identifier (R 2 = 0.67, 0.26 and 0.42 respectively). For the latter, the dataset identifier is the most important feature (Supplementary Fig. S9 ), while most of the feature importance remains unchanged, with ethyl acetate and ethanol ranking highest, like in the original model trained only on RateBeer data. It seems that the large variation in the panel dataset introduces noise, weakening the models’ performances and reliability. In addition, it seems reasonable to assume that both datasets are fundamentally different, with the panel dataset obtained by blind tastings by a trained professional panel.
Lastly, we evaluated whether beer style identifiers would further enhance the model’s performance. A GBR model was trained with parameters that explicitly encoded the styles of the samples. This did not improve model performance (R2 = 0.66 with style information vs R2 = 0.67). The most important chemical features are consistent with the model trained without style information (eg. ethanol and ethyl acetate), and with the exception of the most preferred (strong ale) and least preferred (low/no-alcohol) styles, none of the styles were among the most important features (Supplementary Fig. S9 , Supplementary Table S5 and S6 ). This is likely due to a combination of style-specific chemical signatures, such as iso-alpha acids and lactic acid, that implicitly convey style information to the original models, as well as the low number of samples belonging to some styles, making it difficult for the model to learn style-specific patterns. Moreover, beer styles are not rigorously defined, with some styles overlapping in features and some beers being misattributed to a specific style, all of which leads to more noise in models that use style parameters.
Model validation
To test if our predictive models give insight into beer appreciation, we set up experiments aimed at improving existing commercial beers. We specifically selected overall appreciation as the trait to be examined because of its complexity and commercial relevance. Beer flavor comprises a complex bouquet rather than single aromas and tastes 53 . Hence, adding a single compound to the extent that a difference is noticeable may lead to an unbalanced, artificial flavor. Therefore, we evaluated the effect of combinations of compounds. Because Blond beers represent the most extensive style in our dataset, we selected a beer from this style as the starting material for these experiments (Beer 64 in Supplementary Data 1 ).
In the first set of experiments, we adjusted the concentrations of compounds that made up the most important predictors of overall appreciation (ethyl acetate, ethanol, lactic acid, ethyl phenyl acetate) together with correlated compounds (ethyl hexanoate, isoamyl acetate, glycerol), bringing them up to 95 th percentile ethanol-normalized concentrations (Methods) within the Blond group (‘Spiked’ concentration in Fig. 5A ). Compared to controls, the spiked beers were found to have significantly improved overall appreciation among trained panelists, with panelist noting increased intensity of ester flavors, sweetness, alcohol, and body fullness (Fig. 5B ). To disentangle the contribution of ethanol to these results, a second experiment was performed without the addition of ethanol. This resulted in a similar outcome, including increased perception of alcohol and overall appreciation.

Adding the top chemical compounds, identified as best predictors of appreciation by our model, into poorly appreciated beers results in increased appreciation from our trained panel. Results of sensory tests between base beers and those spiked with compounds identified as the best predictors by the model. A Blond and Non/Low-alcohol (0.0% ABV) base beers were brought up to 95th-percentile ethanol-normalized concentrations within each style. B For each sensory attribute, tasters indicated the more intense sample and selected the sample they preferred. The numbers above the bars correspond to the p values that indicate significant changes in perceived flavor (two-sided binomial test: alpha 0.05, n = 20 or 13).
In a last experiment, we tested whether using the model’s predictions can boost the appreciation of a non-alcoholic beer (beer 223 in Supplementary Data 1 ). Again, the addition of a mixture of predicted compounds (omitting ethanol, in this case) resulted in a significant increase in appreciation, body, ester flavor and sweetness.
Predicting flavor and consumer appreciation from chemical composition is one of the ultimate goals of sensory science. A reliable, systematic and unbiased way to link chemical profiles to flavor and food appreciation would be a significant asset to the food and beverage industry. Such tools would substantially aid in quality control and recipe development, offer an efficient and cost-effective alternative to pilot studies and consumer trials and would ultimately allow food manufacturers to produce superior, tailor-made products that better meet the demands of specific consumer groups more efficiently.
A limited set of studies have previously tried, to varying degrees of success, to predict beer flavor and beer popularity based on (a limited set of) chemical compounds and flavors 79 , 80 . Current sensitive, high-throughput technologies allow measuring an unprecedented number of chemical compounds and properties in a large set of samples, yielding a dataset that can train models that help close the gaps between chemistry and flavor, even for a complex natural product like beer. To our knowledge, no previous research gathered data at this scale (250 samples, 226 chemical parameters, 50 sensory attributes and 5 consumer scores) to disentangle and validate the chemical aspects driving beer preference using various machine-learning techniques. We find that modern machine learning models outperform conventional statistical tools, such as correlations and linear models, and can successfully predict flavor appreciation from chemical composition. This could be attributed to the natural incorporation of interactions and non-linear or discontinuous effects in machine learning models, which are not easily grasped by the linear model architecture. While linear models and partial least squares regression represent the most widespread statistical approaches in sensory science, in part because they allow interpretation 65 , 81 , 82 , modern machine learning methods allow for building better predictive models while preserving the possibility to dissect and exploit the underlying patterns. Of the 10 different models we trained, tree-based models, such as our best performing GBR, showed the best overall performance in predicting sensory responses from chemical information, outcompeting artificial neural networks. This agrees with previous reports for models trained on tabular data 83 . Our results are in line with the findings of Colantonio et al. who also identified the gradient boosting architecture as performing best at predicting appreciation and flavor (of tomatoes and blueberries, in their specific study) 26 . Importantly, besides our larger experimental scale, we were able to directly confirm our models’ predictions in vivo.
Our study confirms that flavor compound concentration does not always correlate with perception, suggesting complex interactions that are often missed by more conventional statistics and simple models. Specifically, we find that tree-based algorithms may perform best in developing models that link complex food chemistry with aroma. Furthermore, we show that massive datasets of untrained consumer reviews provide a valuable source of data, that can complement or even replace trained tasting panels, especially for appreciation and basic flavors, such as sweetness and bitterness. This holds despite biases that are known to occur in such datasets, such as price or conformity bias. Moreover, GBR models predict taste better than aroma. This is likely because taste (e.g. bitterness) often directly relates to the corresponding chemical measurements (e.g., iso-alpha acids), whereas such a link is less clear for aromas, which often result from the interplay between multiple volatile compounds. We also find that our models are best at predicting acidity and alcohol, likely because there is a direct relation between the measured chemical compounds (acids and ethanol) and the corresponding perceived sensorial attribute (acidity and alcohol), and because even untrained consumers are generally able to recognize these flavors and aromas.
The predictions of our final models, trained on review data, hold even for blind tastings with small groups of trained tasters, as demonstrated by our ability to validate specific compounds as drivers of beer flavor and appreciation. Since adding a single compound to the extent of a noticeable difference may result in an unbalanced flavor profile, we specifically tested our identified key drivers as a combination of compounds. While this approach does not allow us to validate if a particular single compound would affect flavor and/or appreciation, our experiments do show that this combination of compounds increases consumer appreciation.
It is important to stress that, while it represents an important step forward, our approach still has several major limitations. A key weakness of the GBR model architecture is that amongst co-correlating variables, the largest main effect is consistently preferred for model building. As a result, co-correlating variables often have artificially low importance scores, both for impurity and SHAP-based methods, like we observed in the comparison to the more randomized Extra Trees models. This implies that chemicals identified as key drivers of a specific sensory feature by GBR might not be the true causative compounds, but rather co-correlate with the actual causative chemical. For example, the high importance of ethyl acetate could be (partially) attributed to the total ester content, ethanol or ethyl hexanoate (rho=0.77, rho=0.72 and rho=0.68), while ethyl phenylacetate could hide the importance of prenyl isobutyrate and ethyl benzoate (rho=0.77 and rho=0.76). Expanding our GBR model to include beer style as a parameter did not yield additional power or insight. This is likely due to style-specific chemical signatures, such as iso-alpha acids and lactic acid, that implicitly convey style information to the original model, as well as the smaller sample size per style, limiting the power to uncover style-specific patterns. This can be partly attributed to the curse of dimensionality, where the high number of parameters results in the models mainly incorporating single parameter effects, rather than complex interactions such as style-dependent effects 67 . A larger number of samples may overcome some of these limitations and offer more insight into style-specific effects. On the other hand, beer style is not a rigid scientific classification, and beers within one style often differ a lot, which further complicates the analysis of style as a model factor.
Our study is limited to beers from Belgian breweries. Although these beers cover a large portion of the beer styles available globally, some beer styles and consumer patterns may be missing, while other features might be overrepresented. For example, many Belgian ales exhibit yeast-driven flavor profiles, which is reflected in the chemical drivers of appreciation discovered by this study. In future work, expanding the scope to include diverse markets and beer styles could lead to the identification of even more drivers of appreciation and better models for special niche products that were not present in our beer set.
In addition to inherent limitations of GBR models, there are also some limitations associated with studying food aroma. Even if our chemical analyses measured most of the known aroma compounds, the total number of flavor compounds in complex foods like beer is still larger than the subset we were able to measure in this study. For example, hop-derived thiols, that influence flavor at very low concentrations, are notoriously difficult to measure in a high-throughput experiment. Moreover, consumer perception remains subjective and prone to biases that are difficult to avoid. It is also important to stress that the models are still immature and that more extensive datasets will be crucial for developing more complete models in the future. Besides more samples and parameters, our dataset does not include any demographic information about the tasters. Including such data could lead to better models that grasp external factors like age and culture. Another limitation is that our set of beers consists of high-quality end-products and lacks beers that are unfit for sale, which limits the current model in accurately predicting products that are appreciated very badly. Finally, while models could be readily applied in quality control, their use in sensory science and product development is restrained by their inability to discern causal relationships. Given that the models cannot distinguish compounds that genuinely drive consumer perception from those that merely correlate, validation experiments are essential to identify true causative compounds.
Despite the inherent limitations, dissection of our models enabled us to pinpoint specific molecules as potential drivers of beer aroma and consumer appreciation, including compounds that were unexpected and would not have been identified using standard approaches. Important drivers of beer appreciation uncovered by our models include protein levels, ethyl acetate, ethyl phenyl acetate and lactic acid. Currently, many brewers already use lactic acid to acidify their brewing water and ensure optimal pH for enzymatic activity during the mashing process. Our results suggest that adding lactic acid can also improve beer appreciation, although its individual effect remains to be tested. Interestingly, ethanol appears to be unnecessary to improve beer appreciation, both for blond beer and alcohol-free beer. Given the growing consumer interest in alcohol-free beer, with a predicted annual market growth of >7% 84 , it is relevant for brewers to know what compounds can further increase consumer appreciation of these beers. Hence, our model may readily provide avenues to further improve the flavor and consumer appreciation of both alcoholic and non-alcoholic beers, which is generally considered one of the key challenges for future beer production.
Whereas we see a direct implementation of our results for the development of superior alcohol-free beverages and other food products, our study can also serve as a stepping stone for the development of novel alcohol-containing beverages. We want to echo the growing body of scientific evidence for the negative effects of alcohol consumption, both on the individual level by the mutagenic, teratogenic and carcinogenic effects of ethanol 85 , 86 , as well as the burden on society caused by alcohol abuse and addiction. We encourage the use of our results for the production of healthier, tastier products, including novel and improved beverages with lower alcohol contents. Furthermore, we strongly discourage the use of these technologies to improve the appreciation or addictive properties of harmful substances.
The present work demonstrates that despite some important remaining hurdles, combining the latest developments in chemical analyses, sensory analysis and modern machine learning methods offers exciting avenues for food chemistry and engineering. Soon, these tools may provide solutions in quality control and recipe development, as well as new approaches to sensory science and flavor research.
Beer selection
250 commercial Belgian beers were selected to cover the broad diversity of beer styles and corresponding diversity in chemical composition and aroma. See Supplementary Fig. S1 .
Chemical dataset
Sample preparation.
Beers within their expiration date were purchased from commercial retailers. Samples were prepared in biological duplicates at room temperature, unless explicitly stated otherwise. Bottle pressure was measured with a manual pressure device (Steinfurth Mess-Systeme GmbH) and used to calculate CO 2 concentration. The beer was poured through two filter papers (Macherey-Nagel, 500713032 MN 713 ¼) to remove carbon dioxide and prevent spontaneous foaming. Samples were then prepared for measurements by targeted Headspace-Gas Chromatography-Flame Ionization Detector/Flame Photometric Detector (HS-GC-FID/FPD), Headspace-Solid Phase Microextraction-Gas Chromatography-Mass Spectrometry (HS-SPME-GC-MS), colorimetric analysis, enzymatic analysis, Near-Infrared (NIR) analysis, as described in the sections below. The mean values of biological duplicates are reported for each compound.
HS-GC-FID/FPD
HS-GC-FID/FPD (Shimadzu GC 2010 Plus) was used to measure higher alcohols, acetaldehyde, esters, 4-vinyl guaicol, and sulfur compounds. Each measurement comprised 5 ml of sample pipetted into a 20 ml glass vial containing 1.75 g NaCl (VWR, 27810.295). 100 µl of 2-heptanol (Sigma-Aldrich, H3003) (internal standard) solution in ethanol (Fisher Chemical, E/0650DF/C17) was added for a final concentration of 2.44 mg/L. Samples were flushed with nitrogen for 10 s, sealed with a silicone septum, stored at −80 °C and analyzed in batches of 20.
The GC was equipped with a DB-WAXetr column (length, 30 m; internal diameter, 0.32 mm; layer thickness, 0.50 µm; Agilent Technologies, Santa Clara, CA, USA) to the FID and an HP-5 column (length, 30 m; internal diameter, 0.25 mm; layer thickness, 0.25 µm; Agilent Technologies, Santa Clara, CA, USA) to the FPD. N 2 was used as the carrier gas. Samples were incubated for 20 min at 70 °C in the headspace autosampler (Flow rate, 35 cm/s; Injection volume, 1000 µL; Injection mode, split; Combi PAL autosampler, CTC analytics, Switzerland). The injector, FID and FPD temperatures were kept at 250 °C. The GC oven temperature was first held at 50 °C for 5 min and then allowed to rise to 80 °C at a rate of 5 °C/min, followed by a second ramp of 4 °C/min until 200 °C kept for 3 min and a final ramp of (4 °C/min) until 230 °C for 1 min. Results were analyzed with the GCSolution software version 2.4 (Shimadzu, Kyoto, Japan). The GC was calibrated with a 5% EtOH solution (VWR International) containing the volatiles under study (Supplementary Table S7 ).
HS-SPME-GC-MS
HS-SPME-GC-MS (Shimadzu GCMS-QP-2010 Ultra) was used to measure additional volatile compounds, mainly comprising terpenoids and esters. Samples were analyzed by HS-SPME using a triphase DVB/Carboxen/PDMS 50/30 μm SPME fiber (Supelco Co., Bellefonte, PA, USA) followed by gas chromatography (Thermo Fisher Scientific Trace 1300 series, USA) coupled to a mass spectrometer (Thermo Fisher Scientific ISQ series MS) equipped with a TriPlus RSH autosampler. 5 ml of degassed beer sample was placed in 20 ml vials containing 1.75 g NaCl (VWR, 27810.295). 5 µl internal standard mix was added, containing 2-heptanol (1 g/L) (Sigma-Aldrich, H3003), 4-fluorobenzaldehyde (1 g/L) (Sigma-Aldrich, 128376), 2,3-hexanedione (1 g/L) (Sigma-Aldrich, 144169) and guaiacol (1 g/L) (Sigma-Aldrich, W253200) in ethanol (Fisher Chemical, E/0650DF/C17). Each sample was incubated at 60 °C in the autosampler oven with constant agitation. After 5 min equilibration, the SPME fiber was exposed to the sample headspace for 30 min. The compounds trapped on the fiber were thermally desorbed in the injection port of the chromatograph by heating the fiber for 15 min at 270 °C.
The GC-MS was equipped with a low polarity RXi-5Sil MS column (length, 20 m; internal diameter, 0.18 mm; layer thickness, 0.18 µm; Restek, Bellefonte, PA, USA). Injection was performed in splitless mode at 320 °C, a split flow of 9 ml/min, a purge flow of 5 ml/min and an open valve time of 3 min. To obtain a pulsed injection, a programmed gas flow was used whereby the helium gas flow was set at 2.7 mL/min for 0.1 min, followed by a decrease in flow of 20 ml/min to the normal 0.9 mL/min. The temperature was first held at 30 °C for 3 min and then allowed to rise to 80 °C at a rate of 7 °C/min, followed by a second ramp of 2 °C/min till 125 °C and a final ramp of 8 °C/min with a final temperature of 270 °C.
Mass acquisition range was 33 to 550 amu at a scan rate of 5 scans/s. Electron impact ionization energy was 70 eV. The interface and ion source were kept at 275 °C and 250 °C, respectively. A mix of linear n-alkanes (from C7 to C40, Supelco Co.) was injected into the GC-MS under identical conditions to serve as external retention index markers. Identification and quantification of the compounds were performed using an in-house developed R script as described in Goelen et al. and Reher et al. 87 , 88 (for package information, see Supplementary Table S8 ). Briefly, chromatograms were analyzed using AMDIS (v2.71) 89 to separate overlapping peaks and obtain pure compound spectra. The NIST MS Search software (v2.0 g) in combination with the NIST2017, FFNSC3 and Adams4 libraries were used to manually identify the empirical spectra, taking into account the expected retention time. After background subtraction and correcting for retention time shifts between samples run on different days based on alkane ladders, compound elution profiles were extracted and integrated using a file with 284 target compounds of interest, which were either recovered in our identified AMDIS list of spectra or were known to occur in beer. Compound elution profiles were estimated for every peak in every chromatogram over a time-restricted window using weighted non-negative least square analysis after which peak areas were integrated 87 , 88 . Batch effect correction was performed by normalizing against the most stable internal standard compound, 4-fluorobenzaldehyde. Out of all 284 target compounds that were analyzed, 167 were visually judged to have reliable elution profiles and were used for final analysis.
Discrete photometric and enzymatic analysis
Discrete photometric and enzymatic analysis (Thermo Scientific TM Gallery TM Plus Beermaster Discrete Analyzer) was used to measure acetic acid, ammonia, beta-glucan, iso-alpha acids, color, sugars, glycerol, iron, pH, protein, and sulfite. 2 ml of sample volume was used for the analyses. Information regarding the reagents and standard solutions used for analyses and calibrations is included in Supplementary Table S7 and Supplementary Table S9 .
NIR analyses
NIR analysis (Anton Paar Alcolyzer Beer ME System) was used to measure ethanol. Measurements comprised 50 ml of sample, and a 10% EtOH solution was used for calibration.
Correlation calculations
Pairwise Spearman Rank correlations were calculated between all chemical properties.
Sensory dataset
Trained panel.
Our trained tasting panel consisted of volunteers who gave prior verbal informed consent. All compounds used for the validation experiment were of food-grade quality. The tasting sessions were approved by the Social and Societal Ethics Committee of the KU Leuven (G-2022-5677-R2(MAR)). All online reviewers agreed to the Terms and Conditions of the RateBeer website.
Sensory analysis was performed according to the American Society of Brewing Chemists (ASBC) Sensory Analysis Methods 90 . 30 volunteers were screened through a series of triangle tests. The sixteen most sensitive and consistent tasters were retained as taste panel members. The resulting panel was diverse in age [22–42, mean: 29], sex [56% male] and nationality [7 different countries]. The panel developed a consensus vocabulary to describe beer aroma, taste and mouthfeel. Panelists were trained to identify and score 50 different attributes, using a 7-point scale to rate attributes’ intensity. The scoring sheet is included as Supplementary Data 3 . Sensory assessments took place between 10–12 a.m. The beers were served in black-colored glasses. Per session, between 5 and 12 beers of the same style were tasted at 12 °C to 16 °C. Two reference beers were added to each set and indicated as ‘Reference 1 & 2’, allowing panel members to calibrate their ratings. Not all panelists were present at every tasting. Scores were scaled by standard deviation and mean-centered per taster. Values are represented as z-scores and clustered by Euclidean distance. Pairwise Spearman correlations were calculated between taste and aroma sensory attributes. Panel consistency was evaluated by repeating samples on different sessions and performing ANOVA to identify differences, using the ‘stats’ package (v4.2.2) in R (for package information, see Supplementary Table S8 ).
Online reviews from a public database
The ‘scrapy’ package in Python (v3.6) (for package information, see Supplementary Table S8 ). was used to collect 232,288 online reviews (mean=922, min=6, max=5343) from RateBeer, an online beer review database. Each review entry comprised 5 numerical scores (appearance, aroma, taste, palate and overall quality) and an optional review text. The total number of reviews per reviewer was collected separately. Numerical scores were scaled and centered per rater, and mean scores were calculated per beer.
For the review texts, the language was estimated using the packages ‘langdetect’ and ‘langid’ in Python. Reviews that were classified as English by both packages were kept. Reviewers with fewer than 100 entries overall were discarded. 181,025 reviews from >6000 reviewers from >40 countries remained. Text processing was done using the ‘nltk’ package in Python. Texts were corrected for slang and misspellings; proper nouns and rare words that are relevant to the beer context were specified and kept as-is (‘Chimay’,’Lambic’, etc.). A dictionary of semantically similar sensorial terms, for example ‘floral’ and ‘flower’, was created and collapsed together into one term. Words were stemmed and lemmatized to avoid identifying words such as ‘acid’ and ‘acidity’ as separate terms. Numbers and punctuation were removed.
Sentences from up to 50 randomly chosen reviews per beer were manually categorized according to the aspect of beer they describe (appearance, aroma, taste, palate, overall quality—not to be confused with the 5 numerical scores described above) or flagged as irrelevant if they contained no useful information. If a beer contained fewer than 50 reviews, all reviews were manually classified. This labeled data set was used to train a model that classified the rest of the sentences for all beers 91 . Sentences describing taste and aroma were extracted, and term frequency–inverse document frequency (TFIDF) was implemented to calculate enrichment scores for sensorial words per beer.
The sex of the tasting subject was not considered when building our sensory database. Instead, results from different panelists were averaged, both for our trained panel (56% male, 44% female) and the RateBeer reviews (70% male, 30% female for RateBeer as a whole).
Beer price collection and processing
Beer prices were collected from the following stores: Colruyt, Delhaize, Total Wine, BeerHawk, The Belgian Beer Shop, The Belgian Shop, and Beer of Belgium. Where applicable, prices were converted to Euros and normalized per liter. Spearman correlations were calculated between these prices and mean overall appreciation scores from RateBeer and the taste panel, respectively.
Pairwise Spearman Rank correlations were calculated between all sensory properties.
Machine learning models
Predictive modeling of sensory profiles from chemical data.
Regression models were constructed to predict (a) trained panel scores for beer flavors and quality from beer chemical profiles and (b) public reviews’ appreciation scores from beer chemical profiles. Z-scores were used to represent sensory attributes in both data sets. Chemical properties with log-normal distributions (Shapiro-Wilk test, p < 0.05 ) were log-transformed. Missing chemical measurements (0.1% of all data) were replaced with mean values per attribute. Observations from 250 beers were randomly separated into a training set (70%, 175 beers) and a test set (30%, 75 beers), stratified per beer style. Chemical measurements (p = 231) were normalized based on the training set average and standard deviation. In total, three linear regression-based models: linear regression with first-order interaction terms (LR), lasso regression with first-order interaction terms (Lasso) and partial least squares regression (PLSR); five decision tree models, Adaboost regressor (ABR), Extra Trees (ET), Gradient Boosting regressor (GBR), Random Forest (RF) and XGBoost regressor (XGBR); one support vector machine model (SVR) and one artificial neural network model (ANN) were trained. The models were implemented using the ‘scikit-learn’ package (v1.2.2) and ‘xgboost’ package (v1.7.3) in Python (v3.9.16). Models were trained, and hyperparameters optimized, using five-fold cross-validated grid search with the coefficient of determination (R 2 ) as the evaluation metric. The ANN (scikit-learn’s MLPRegressor) was optimized using Bayesian Tree-Structured Parzen Estimator optimization with the ‘Optuna’ Python package (v3.2.0). Individual models were trained per attribute, and a multi-output model was trained on all attributes simultaneously.
Model dissection
GBR was found to outperform other methods, resulting in models with the highest average R 2 values in both trained panel and public review data sets. Impurity-based rankings of the most important predictors for each predicted sensorial trait were obtained using the ‘scikit-learn’ package. To observe the relationships between these chemical properties and their predicted targets, partial dependence plots (PDP) were constructed for the six most important predictors of consumer appreciation 74 , 75 .
The ‘SHAP’ package in Python (v0.41.0) was implemented to provide an alternative ranking of predictor importance and to visualize the predictors’ effects as a function of their concentration 68 .
Validation of causal chemical properties
To validate the effects of the most important model features on predicted sensory attributes, beers were spiked with the chemical compounds identified by the models and descriptive sensory analyses were carried out according to the American Society of Brewing Chemists (ASBC) protocol 90 .
Compound spiking was done 30 min before tasting. Compounds were spiked into fresh beer bottles, that were immediately resealed and inverted three times. Fresh bottles of beer were opened for the same duration, resealed, and inverted thrice, to serve as controls. Pairs of spiked samples and controls were served simultaneously, chilled and in dark glasses as outlined in the Trained panel section above. Tasters were instructed to select the glass with the higher flavor intensity for each attribute (directional difference test 92 ) and to select the glass they prefer.
The final concentration after spiking was equal to the within-style average, after normalizing by ethanol concentration. This was done to ensure balanced flavor profiles in the final spiked beer. The same methods were applied to improve a non-alcoholic beer. Compounds were the following: ethyl acetate (Merck KGaA, W241415), ethyl hexanoate (Merck KGaA, W243906), isoamyl acetate (Merck KGaA, W205508), phenethyl acetate (Merck KGaA, W285706), ethanol (96%, Colruyt), glycerol (Merck KGaA, W252506), lactic acid (Merck KGaA, 261106).
Significant differences in preference or perceived intensity were determined by performing the two-sided binomial test on each attribute.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The data that support the findings of this work are available in the Supplementary Data files and have been deposited to Zenodo under accession code 10653704 93 . The RateBeer scores data are under restricted access, they are not publicly available as they are property of RateBeer (ZX Ventures, USA). Access can be obtained from the authors upon reasonable request and with permission of RateBeer (ZX Ventures, USA). Source data are provided with this paper.
Code availability
The code for training the machine learning models, analyzing the models, and generating the figures has been deposited to Zenodo under accession code 10653704 93 .
Tieman, D. et al. A chemical genetic roadmap to improved tomato flavor. Science 355 , 391–394 (2017).
Article ADS CAS PubMed Google Scholar
Plutowska, B. & Wardencki, W. Application of gas chromatography–olfactometry (GC–O) in analysis and quality assessment of alcoholic beverages – A review. Food Chem. 107 , 449–463 (2008).
Article CAS Google Scholar
Legin, A., Rudnitskaya, A., Seleznev, B. & Vlasov, Y. Electronic tongue for quality assessment of ethanol, vodka and eau-de-vie. Anal. Chim. Acta 534 , 129–135 (2005).
Loutfi, A., Coradeschi, S., Mani, G. K., Shankar, P. & Rayappan, J. B. B. Electronic noses for food quality: A review. J. Food Eng. 144 , 103–111 (2015).
Ahn, Y.-Y., Ahnert, S. E., Bagrow, J. P. & Barabási, A.-L. Flavor network and the principles of food pairing. Sci. Rep. 1 , 196 (2011).
Article CAS PubMed PubMed Central Google Scholar
Bartoshuk, L. M. & Klee, H. J. Better fruits and vegetables through sensory analysis. Curr. Biol. 23 , R374–R378 (2013).
Article CAS PubMed Google Scholar
Piggott, J. R. Design questions in sensory and consumer science. Food Qual. Prefer. 3293 , 217–220 (1995).
Article Google Scholar
Kermit, M. & Lengard, V. Assessing the performance of a sensory panel-panellist monitoring and tracking. J. Chemom. 19 , 154–161 (2005).
Cook, D. J., Hollowood, T. A., Linforth, R. S. T. & Taylor, A. J. Correlating instrumental measurements of texture and flavour release with human perception. Int. J. Food Sci. Technol. 40 , 631–641 (2005).
Chinchanachokchai, S., Thontirawong, P. & Chinchanachokchai, P. A tale of two recommender systems: The moderating role of consumer expertise on artificial intelligence based product recommendations. J. Retail. Consum. Serv. 61 , 1–12 (2021).
Ross, C. F. Sensory science at the human-machine interface. Trends Food Sci. Technol. 20 , 63–72 (2009).
Chambers, E. IV & Koppel, K. Associations of volatile compounds with sensory aroma and flavor: The complex nature of flavor. Molecules 18 , 4887–4905 (2013).
Pinu, F. R. Metabolomics—The new frontier in food safety and quality research. Food Res. Int. 72 , 80–81 (2015).
Danezis, G. P., Tsagkaris, A. S., Brusic, V. & Georgiou, C. A. Food authentication: state of the art and prospects. Curr. Opin. Food Sci. 10 , 22–31 (2016).
Shepherd, G. M. Smell images and the flavour system in the human brain. Nature 444 , 316–321 (2006).
Meilgaard, M. C. Prediction of flavor differences between beers from their chemical composition. J. Agric. Food Chem. 30 , 1009–1017 (1982).
Xu, L. et al. Widespread receptor-driven modulation in peripheral olfactory coding. Science 368 , eaaz5390 (2020).
Kupferschmidt, K. Following the flavor. Science 340 , 808–809 (2013).
Billesbølle, C. B. et al. Structural basis of odorant recognition by a human odorant receptor. Nature 615 , 742–749 (2023).
Article ADS PubMed PubMed Central Google Scholar
Smith, B. Perspective: Complexities of flavour. Nature 486 , S6–S6 (2012).
Pfister, P. et al. Odorant receptor inhibition is fundamental to odor encoding. Curr. Biol. 30 , 2574–2587 (2020).
Moskowitz, H. W., Kumaraiah, V., Sharma, K. N., Jacobs, H. L. & Sharma, S. D. Cross-cultural differences in simple taste preferences. Science 190 , 1217–1218 (1975).
Eriksson, N. et al. A genetic variant near olfactory receptor genes influences cilantro preference. Flavour 1 , 22 (2012).
Ferdenzi, C. et al. Variability of affective responses to odors: Culture, gender, and olfactory knowledge. Chem. Senses 38 , 175–186 (2013).
Article PubMed Google Scholar
Lawless, H. T. & Heymann, H. Sensory evaluation of food: Principles and practices. (Springer, New York, NY). https://doi.org/10.1007/978-1-4419-6488-5 (2010).
Colantonio, V. et al. Metabolomic selection for enhanced fruit flavor. Proc. Natl. Acad. Sci. 119 , e2115865119 (2022).
Fritz, F., Preissner, R. & Banerjee, P. VirtualTaste: a web server for the prediction of organoleptic properties of chemical compounds. Nucleic Acids Res 49 , W679–W684 (2021).
Tuwani, R., Wadhwa, S. & Bagler, G. BitterSweet: Building machine learning models for predicting the bitter and sweet taste of small molecules. Sci. Rep. 9 , 1–13 (2019).
Dagan-Wiener, A. et al. Bitter or not? BitterPredict, a tool for predicting taste from chemical structure. Sci. Rep. 7 , 1–13 (2017).
Pallante, L. et al. Toward a general and interpretable umami taste predictor using a multi-objective machine learning approach. Sci. Rep. 12 , 1–11 (2022).
Malavolta, M. et al. A survey on computational taste predictors. Eur. Food Res. Technol. 248 , 2215–2235 (2022).
Lee, B. K. et al. A principal odor map unifies diverse tasks in olfactory perception. Science 381 , 999–1006 (2023).
Mayhew, E. J. et al. Transport features predict if a molecule is odorous. Proc. Natl. Acad. Sci. 119 , e2116576119 (2022).
Niu, Y. et al. Sensory evaluation of the synergism among ester odorants in light aroma-type liquor by odor threshold, aroma intensity and flash GC electronic nose. Food Res. Int. 113 , 102–114 (2018).
Yu, P., Low, M. Y. & Zhou, W. Design of experiments and regression modelling in food flavour and sensory analysis: A review. Trends Food Sci. Technol. 71 , 202–215 (2018).
Oladokun, O. et al. The impact of hop bitter acid and polyphenol profiles on the perceived bitterness of beer. Food Chem. 205 , 212–220 (2016).
Linforth, R., Cabannes, M., Hewson, L., Yang, N. & Taylor, A. Effect of fat content on flavor delivery during consumption: An in vivo model. J. Agric. Food Chem. 58 , 6905–6911 (2010).
Guo, S., Na Jom, K. & Ge, Y. Influence of roasting condition on flavor profile of sunflower seeds: A flavoromics approach. Sci. Rep. 9 , 11295 (2019).
Ren, Q. et al. The changes of microbial community and flavor compound in the fermentation process of Chinese rice wine using Fagopyrum tataricum grain as feedstock. Sci. Rep. 9 , 3365 (2019).
Hastie, T., Friedman, J. & Tibshirani, R. The Elements of Statistical Learning. (Springer, New York, NY). https://doi.org/10.1007/978-0-387-21606-5 (2001).
Dietz, C., Cook, D., Huismann, M., Wilson, C. & Ford, R. The multisensory perception of hop essential oil: a review. J. Inst. Brew. 126 , 320–342 (2020).
CAS Google Scholar
Roncoroni, Miguel & Verstrepen, Kevin Joan. Belgian Beer: Tested and Tasted. (Lannoo, 2018).
Meilgaard, M. Flavor chemistry of beer: Part II: Flavor and threshold of 239 aroma volatiles. in (1975).
Bokulich, N. A. & Bamforth, C. W. The microbiology of malting and brewing. Microbiol. Mol. Biol. Rev. MMBR 77 , 157–172 (2013).
Dzialo, M. C., Park, R., Steensels, J., Lievens, B. & Verstrepen, K. J. Physiology, ecology and industrial applications of aroma formation in yeast. FEMS Microbiol. Rev. 41 , S95–S128 (2017).
Article PubMed PubMed Central Google Scholar
Datta, A. et al. Computer-aided food engineering. Nat. Food 3 , 894–904 (2022).
American Society of Brewing Chemists. Beer Methods. (American Society of Brewing Chemists, St. Paul, MN, U.S.A.).
Olaniran, A. O., Hiralal, L., Mokoena, M. P. & Pillay, B. Flavour-active volatile compounds in beer: production, regulation and control. J. Inst. Brew. 123 , 13–23 (2017).
Verstrepen, K. J. et al. Flavor-active esters: Adding fruitiness to beer. J. Biosci. Bioeng. 96 , 110–118 (2003).
Meilgaard, M. C. Flavour chemistry of beer. part I: flavour interaction between principal volatiles. Master Brew. Assoc. Am. Tech. Q 12 , 107–117 (1975).
Briggs, D. E., Boulton, C. A., Brookes, P. A. & Stevens, R. Brewing 227–254. (Woodhead Publishing). https://doi.org/10.1533/9781855739062.227 (2004).
Bossaert, S., Crauwels, S., De Rouck, G. & Lievens, B. The power of sour - A review: Old traditions, new opportunities. BrewingScience 72 , 78–88 (2019).
Google Scholar
Verstrepen, K. J. et al. Flavor active esters: Adding fruitiness to beer. J. Biosci. Bioeng. 96 , 110–118 (2003).
Snauwaert, I. et al. Microbial diversity and metabolite composition of Belgian red-brown acidic ales. Int. J. Food Microbiol. 221 , 1–11 (2016).
Spitaels, F. et al. The microbial diversity of traditional spontaneously fermented lambic beer. PLoS ONE 9 , e95384 (2014).
Blanco, C. A., Andrés-Iglesias, C. & Montero, O. Low-alcohol Beers: Flavor Compounds, Defects, and Improvement Strategies. Crit. Rev. Food Sci. Nutr. 56 , 1379–1388 (2016).
Jackowski, M. & Trusek, A. Non-Alcohol. beer Prod. – Overv. 20 , 32–38 (2018).
Takoi, K. et al. The contribution of geraniol metabolism to the citrus flavour of beer: Synergy of geraniol and β-citronellol under coexistence with excess linalool. J. Inst. Brew. 116 , 251–260 (2010).
Kroeze, J. H. & Bartoshuk, L. M. Bitterness suppression as revealed by split-tongue taste stimulation in humans. Physiol. Behav. 35 , 779–783 (1985).
Mennella, J. A. et al. A spoonful of sugar helps the medicine go down”: Bitter masking bysucrose among children and adults. Chem. Senses 40 , 17–25 (2015).
Wietstock, P., Kunz, T., Perreira, F. & Methner, F.-J. Metal chelation behavior of hop acids in buffered model systems. BrewingScience 69 , 56–63 (2016).
Sancho, D., Blanco, C. A., Caballero, I. & Pascual, A. Free iron in pale, dark and alcohol-free commercial lager beers. J. Sci. Food Agric. 91 , 1142–1147 (2011).
Rodrigues, H. & Parr, W. V. Contribution of cross-cultural studies to understanding wine appreciation: A review. Food Res. Int. 115 , 251–258 (2019).
Korneva, E. & Blockeel, H. Towards better evaluation of multi-target regression models. in ECML PKDD 2020 Workshops (eds. Koprinska, I. et al.) 353–362 (Springer International Publishing, Cham, 2020). https://doi.org/10.1007/978-3-030-65965-3_23 .
Gastón Ares. Mathematical and Statistical Methods in Food Science and Technology. (Wiley, 2013).
Grinsztajn, L., Oyallon, E. & Varoquaux, G. Why do tree-based models still outperform deep learning on tabular data? Preprint at http://arxiv.org/abs/2207.08815 (2022).
Gries, S. T. Statistics for Linguistics with R: A Practical Introduction. in Statistics for Linguistics with R (De Gruyter Mouton, 2021). https://doi.org/10.1515/9783110718256 .
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2 , 56–67 (2020).
Ickes, C. M. & Cadwallader, K. R. Effects of ethanol on flavor perception in alcoholic beverages. Chemosens. Percept. 10 , 119–134 (2017).
Kato, M. et al. Influence of high molecular weight polypeptides on the mouthfeel of commercial beer. J. Inst. Brew. 127 , 27–40 (2021).
Wauters, R. et al. Novel Saccharomyces cerevisiae variants slow down the accumulation of staling aldehydes and improve beer shelf-life. Food Chem. 398 , 1–11 (2023).
Li, H., Jia, S. & Zhang, W. Rapid determination of low-level sulfur compounds in beer by headspace gas chromatography with a pulsed flame photometric detector. J. Am. Soc. Brew. Chem. 66 , 188–191 (2008).
Dercksen, A., Laurens, J., Torline, P., Axcell, B. C. & Rohwer, E. Quantitative analysis of volatile sulfur compounds in beer using a membrane extraction interface. J. Am. Soc. Brew. Chem. 54 , 228–233 (1996).
Molnar, C. Interpretable Machine Learning: A Guide for Making Black-Box Models Interpretable. (2020).
Zhao, Q. & Hastie, T. Causal interpretations of black-box models. J. Bus. Econ. Stat. Publ. Am. Stat. Assoc. 39 , 272–281 (2019).
Article MathSciNet Google Scholar
Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning. (Springer, 2019).
Labrado, D. et al. Identification by NMR of key compounds present in beer distillates and residual phases after dealcoholization by vacuum distillation. J. Sci. Food Agric. 100 , 3971–3978 (2020).
Lusk, L. T., Kay, S. B., Porubcan, A. & Ryder, D. S. Key olfactory cues for beer oxidation. J. Am. Soc. Brew. Chem. 70 , 257–261 (2012).
Gonzalez Viejo, C., Torrico, D. D., Dunshea, F. R. & Fuentes, S. Development of artificial neural network models to assess beer acceptability based on sensory properties using a robotic pourer: A comparative model approach to achieve an artificial intelligence system. Beverages 5 , 33 (2019).
Gonzalez Viejo, C., Fuentes, S., Torrico, D. D., Godbole, A. & Dunshea, F. R. Chemical characterization of aromas in beer and their effect on consumers liking. Food Chem. 293 , 479–485 (2019).
Gilbert, J. L. et al. Identifying breeding priorities for blueberry flavor using biochemical, sensory, and genotype by environment analyses. PLOS ONE 10 , 1–21 (2015).
Goulet, C. et al. Role of an esterase in flavor volatile variation within the tomato clade. Proc. Natl. Acad. Sci. 109 , 19009–19014 (2012).
Article ADS CAS PubMed PubMed Central Google Scholar
Borisov, V. et al. Deep Neural Networks and Tabular Data: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 1–21 https://doi.org/10.1109/TNNLS.2022.3229161 (2022).
Statista. Statista Consumer Market Outlook: Beer - Worldwide.
Seitz, H. K. & Stickel, F. Molecular mechanisms of alcoholmediated carcinogenesis. Nat. Rev. Cancer 7 , 599–612 (2007).
Voordeckers, K. et al. Ethanol exposure increases mutation rate through error-prone polymerases. Nat. Commun. 11 , 3664 (2020).
Goelen, T. et al. Bacterial phylogeny predicts volatile organic compound composition and olfactory response of an aphid parasitoid. Oikos 129 , 1415–1428 (2020).
Article ADS Google Scholar
Reher, T. et al. Evaluation of hop (Humulus lupulus) as a repellent for the management of Drosophila suzukii. Crop Prot. 124 , 104839 (2019).
Stein, S. E. An integrated method for spectrum extraction and compound identification from gas chromatography/mass spectrometry data. J. Am. Soc. Mass Spectrom. 10 , 770–781 (1999).
American Society of Brewing Chemists. Sensory Analysis Methods. (American Society of Brewing Chemists, St. Paul, MN, U.S.A., 1992).
McAuley, J., Leskovec, J. & Jurafsky, D. Learning Attitudes and Attributes from Multi-Aspect Reviews. Preprint at https://doi.org/10.48550/arXiv.1210.3926 (2012).
Meilgaard, M. C., Carr, B. T. & Carr, B. T. Sensory Evaluation Techniques. (CRC Press, Boca Raton). https://doi.org/10.1201/b16452 (2014).
Schreurs, M. et al. Data from: Predicting and improving complex beer flavor through machine learning. Zenodo https://doi.org/10.5281/zenodo.10653704 (2024).
Download references
Acknowledgements
We thank all lab members for their discussions and thank all tasting panel members for their contributions. Special thanks go out to Dr. Karin Voordeckers for her tremendous help in proofreading and improving the manuscript. M.S. was supported by a Baillet-Latour fellowship, L.C. acknowledges financial support from KU Leuven (C16/17/006), F.A.T. was supported by a PhD fellowship from FWO (1S08821N). Research in the lab of K.J.V. is supported by KU Leuven, FWO, VIB, VLAIO and the Brewing Science Serves Health Fund. Research in the lab of T.W. is supported by FWO (G.0A51.15) and KU Leuven (C16/17/006).
Author information
These authors contributed equally: Michiel Schreurs, Supinya Piampongsant, Miguel Roncoroni.
Authors and Affiliations
VIB—KU Leuven Center for Microbiology, Gaston Geenslaan 1, B-3001, Leuven, Belgium
Michiel Schreurs, Supinya Piampongsant, Miguel Roncoroni, Lloyd Cool, Beatriz Herrera-Malaver, Florian A. Theßeling & Kevin J. Verstrepen
CMPG Laboratory of Genetics and Genomics, KU Leuven, Gaston Geenslaan 1, B-3001, Leuven, Belgium
Leuven Institute for Beer Research (LIBR), Gaston Geenslaan 1, B-3001, Leuven, Belgium
Laboratory of Socioecology and Social Evolution, KU Leuven, Naamsestraat 59, B-3000, Leuven, Belgium
Lloyd Cool, Christophe Vanderaa & Tom Wenseleers
VIB Bioinformatics Core, VIB, Rijvisschestraat 120, B-9052, Ghent, Belgium
Łukasz Kreft & Alexander Botzki
AB InBev SA/NV, Brouwerijplein 1, B-3000, Leuven, Belgium
Philippe Malcorps & Luk Daenen
You can also search for this author in PubMed Google Scholar
Contributions
S.P., M.S. and K.J.V. conceived the experiments. S.P., M.S. and K.J.V. designed the experiments. S.P., M.S., M.R., B.H. and F.A.T. performed the experiments. S.P., M.S., L.C., C.V., L.K., A.B., P.M., L.D., T.W. and K.J.V. contributed analysis ideas. S.P., M.S., L.C., C.V., T.W. and K.J.V. analyzed the data. All authors contributed to writing the manuscript.
Corresponding author
Correspondence to Kevin J. Verstrepen .
Ethics declarations
Competing interests.
K.J.V. is affiliated with bar.on. The other authors declare no competing interests.
Peer review
Peer review information.
Nature Communications thanks Florian Bauer, Andrew John Macintosh and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary information, peer review file, description of additional supplementary files, supplementary data 1, supplementary data 2, supplementary data 3, supplementary data 4, supplementary data 5, supplementary data 6, supplementary data 7, reporting summary, source data, source data, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Schreurs, M., Piampongsant, S., Roncoroni, M. et al. Predicting and improving complex beer flavor through machine learning. Nat Commun 15 , 2368 (2024). https://doi.org/10.1038/s41467-024-46346-0
Download citation
Received : 30 October 2023
Accepted : 21 February 2024
Published : 26 March 2024
DOI : https://doi.org/10.1038/s41467-024-46346-0
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Translational Research newsletter — top stories in biotechnology, drug discovery and pharma.

IMAGES
VIDEO
COMMENTS
1. Start with an Outline. If you start writing without having a clear idea of what your data analysis report is going to include, it may get messy. Important insights may slip through your fingers, and you may stray away too far from the main topic. To avoid this, start the report by writing an outline first.
1. Step one: Defining the question. The first step in any data analysis process is to define your objective. In data analytics jargon, this is sometimes called the 'problem statement'. Defining your objective means coming up with a hypothesis and figuring how to test it.
When writing your report, organization will set you free. A good outline is: 1) overview of the problem, 2) your data and modeling approach, 3) the results of your data analysis (plots, numbers, etc), and 4) your substantive conclusions. 1) Overview. Describe the problem.
Step 1: Write your hypotheses and plan your research design. To collect valid data for statistical analysis, you first need to specify your hypotheses and plan out your research design. Writing statistical hypotheses. The goal of research is often to investigate a relationship between variables within a population. You start with a prediction ...
Let's take a look at some practical tips you can apply to your data analysis report writing and the benefits of doing so. source: Pexels . Data Analysis Report Writing: 7 Steps. The process of writing a data analysis report is far from simple, but you can master it quickly, with the right guidance and examples of similar reports.
Written by Coursera Staff • Updated on Nov 20, 2023. Data analysis is the practice of working with data to glean useful information, which can then be used to make informed decisions. "It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts," Sherlock ...
The data analysis report has two very important features: •It is organized in a way that makes it easy for different audiences to skim/fish through it to find the topics and the level of detail that are of interest to them. •The writing is as invisible/unremarkable as possible, so that the content of the analysis is what the
Monthly data analysis reports work best for marketing teams, clients, and executives. TL;DR: summarize your key objectives and findings, such as insights, issues, and recommendations, in an executive summary. This sets your audience's expectations and helps busy team members focus on what matters to them. Body: your bar charts, graphs, tables ...
9. Integrate technology. There are many ways to analyze data, but one of the most vital aspects of analytical success in a business context is integrating the right decision support software and technology.. Robust analysis platforms will not only allow you to pull critical data from your most valuable sources while working with dynamic KPIs that will offer you actionable insights; it will ...
Data analysis is the process of examining, filtering, adapting, and modeling data to help solve problems. Data analysis helps determine what is and isn't working, so you can make the changes needed to achieve your business goals. Keep in mind that data analysis includes analyzing both quantitative data (e.g., profits and sales) and qualitative ...
Ensure that the data collected is accurate, reliable, and up-to-date. Step 3: Analyze the Data: Use analytical tools and techniques to analyze the data effectively. This may include statistical analysis, qualitative coding, or data visualization. Look for patterns, trends, correlations, and outliers in the data that may provide insights into ...
Writing an analysis requires a particular structure and key components to create a compelling argument. The following steps can help you format and write your analysis: Choose your argument. Define your thesis. Write the introduction. Write the body paragraphs. Add a conclusion. 1. Choose your argument.
Know your content. When youre going to write a data report, make sure that you know the content. With that, I mean that youve actually been the one to do the analysis. It should always be the person who has done the analyses that write the content. Only in that way can you be sure that the data presentation isnt distorted.
A good data analysis plan should summarize the variables as demonstrated in Figure 1 below. Figure 1. Presentation of variables in a data analysis plan. 5. Statistical software. There are tons of software packages for data analysis, some common examples are SPSS, Epi Info, SAS, STATA, Microsoft Excel.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense. Three essential things occur during the data ...
Step 1: Gather your qualitative data and conduct research (Conduct qualitative research) The first step of qualitative research is to do data collection. Put simply, data collection is gathering all of your data for analysis. A common situation is when qualitative data is spread across various sources.
Data Collection | Definition, Methods & Examples. Published on June 5, 2020 by Pritha Bhandari.Revised on June 21, 2023. Data collection is a systematic process of gathering observations or measurements. Whether you are performing research for business, governmental or academic purposes, data collection allows you to gain first-hand knowledge and original insights into your research problem.
How to Write a Results Section | Tips & Examples. Published on August 30, 2022 by Tegan George. Revised on July 18, 2023. A results section is where you report the main findings of the data collection and analysis you conducted for your thesis or dissertation. You should report all relevant results concisely and objectively, in a logical order.
And place questionnaires, copies of focus groups and interviews, and data sheets in the appendix. On the other hand, one must put the statistical analysis and sayings quoted by interviewees within the dissertation. 8. Thoroughness of Data. It is a common misconception that the data presented is self-explanatory.
Good Practice for Qualitative Data Analysis. In the initial stages of reading the information and identifying basic observations, you can try writing out lists so you can then add in the sub-themes as the analysis progresses. This helps to understand the data and key outcomes better. Keep your research questions to hand so you can refer back to ...
Writing your data analysis for your CSEC SBA. One of the major weakness, so far, to emerge out of the Mathematics SBA project is the inability of students to communicate what their data is saying. The ability to look for patterns in data, to communicate their ideas and to communicate using Mathematical language is wanting.
By sharing these tools, I hope to help fellow data scientists and researchers streamline their workflows and stay ahead of the curve in the ever-evolving field of AI. 1. PandasAI: Conversational Data Analysis . Every data professional is familiar with pandas, a Python package used for data manipulation and analysis.
The A.E.I. data defines remote status by whether there was an in-person or hybrid option, even if some students chose to remain virtual. In the C.S.D.H. data set, districts are defined as remote ...
Writing code in Google Earth Engine may seem daunting at first, but with a little practice, it can be a powerful tool for unlocking the potential of satellite imagery and geospatial data. In this article, I will guide you through the process of writing code in Google Earth Engine and provide you with some useful tips and tricks along the way.
Finally, we'll write up our analysis of the data. Like all academic texts, writing up a thematic analysis requires an introduction to establish our research question, aims and approach. We should also include a methodology section, describing how we collected the data (e.g. through semi-structured interviews or open-ended survey questions ...
One study reported data from both routine clinical practice and clinical research. 3 For the purposes of subsequent analysis, this study was split into research and clinical subsamples (therefore, 13 samples are considered henceforth). Antipsychotic status at the time of neuroimaging was reported in 6 samples (n = 714).
Writing analysis papers also enhances research and writing skills, as students must gather and synthesize information from diverse sources to support their arguments effectively. ... Collect relevant data and evidence to support your analysis. This may include statistical information, case studies, expert opinions, and academic research. Use ...
Why is Page 34 In the "data interpretation, statistical analysis and report writing, item (3) of effective plans" empty? Thank you for bringing this to our attention. It appears there was an issue converting the document to a PDF.
Besides collecting consumer appreciation from these online reviews, we developed automated text analysis tools to gather additional data from review texts (Supplementary Data 7).