

Annotating Texts
What is annotation.
Annotation can be:
- A systematic summary of the text that you create within the document
- A key tool for close reading that helps you uncover patterns, notice important words, and identify main points
- An active learning strategy that improves comprehension and retention of information
Why annotate?
- Isolate and organize important material
- Identify key concepts
- Monitor your learning as you read
- Make exam prep effective and streamlined
- Can be more efficient than creating a separate set of reading notes
How do you annotate?
Summarize key points in your own words .
- Use headers and words in bold to guide you
- Look for main ideas, arguments, and points of evidence
- Notice how the text organizes itself. Chronological order? Idea trees? Etc.
Circle key concepts and phrases
- What words would it be helpful to look-up at the end?
- What terms show up in lecture? When are different words used for similar concepts? Why?
Write brief comments and questions in the margins
- Be as specific or broad as you would like—use these questions to activate your thinking about the content
- See our handout on reading comprehension tips for some examples
Use abbreviations and symbols
- Try ? when you have a question or something you need to explore further
- Try ! When something is interesting, a connection, or otherwise worthy of note
- Try * For anything that you might use as an example or evidence when you use this information.
- Ask yourself what other system of symbols would make sense to you.
Highlight/underline
- Highlight or underline, but mindfully. Check out our resource on strategic highlighting for tips on when and how to highlight.
Use comment and highlight features built into pdfs, online/digital textbooks, or other apps and browser add-ons
- Are you using a pdf? Explore its highlight, edit, and comment functions to support your annotations
- Some browsers have add-ons or extensions that allow you to annotate web pages or web-based documents
- Does your digital or online textbook come with an annotation feature?
- Can your digital text be imported into a note-taking tool like OneNote, EverNote, or Google Keep? If so, you might be able to annotate texts in those apps
What are the most important takeaways?
- Annotation is about increasing your engagement with a text
- Increased engagement, where you think about and process the material then expand on your learning, is how you achieve mastery in a subject
- As you annotate a text, ask yourself: how would I explain this to a friend?
- Put things in your own words and draw connections to what you know and wonder
The table below demonstrates this process using a geography textbook excerpt (Press 2004):

A common concern about annotating texts: It takes time!
Yes, it can, but that time isn’t lost—it’s invested.
Spending the time to annotate on the front end does two important things:
- It saves you time later when you’re studying. Your annotated notes will help speed up exam prep, because you can review critical concepts quickly and efficiently.
- It increases the likelihood that you will retain the information after the course is completed. This is especially important when you are supplying the building blocks of your mind and future career.
One last tip: Try separating the reading and annotating processes! Quickly read through a section of the text first, then go back and annotate.
Works consulted:
Nist, S., & Holschuh, J. (2000). Active learning: strategies for college success. Boston: Allyn and Bacon. 202-218.
Simpson, M., & Nist, S. (1990). Textbook annotation: An effective and efficient study strategy for college students. Journal of Reading, 34: 122-129.
Press, F. (2004). Understanding earth (4th ed). New York: W.H. Freeman. 208-210.

Make a Gift

The Ultimate Guide to Text Annotation: Techniques, Tools, and Best Practices

Puneet Jindal
Introduction.
Welcome to the realm where language meets machine intelligence : text annotation - the catalyst propelling artificial intelligence to understand, interpret, and communicate in human language. Evolving from editorial footnotes to a cornerstone in data science, text annotation now drives Natural Language Processing (NLP) and Computer Vision , reshaping industries across the globe.
Imagine AI models decoding sentiments, recognizing entities, and grasping human nuances in a text. Text annotation is the magical key to making this possible. Join us on this journey through text annotation - exploring its techniques, challenges, and the transformative potential it holds for healthcare, finance, government, logistics, and beyond.
In this exploration, witness text annotation's evolution and its pivotal role in fueling AI's understanding of language. Explore how tools such as Labellerr help in text annotation and work. Let's unravel the artistry behind text annotation, shaping a future where AI comprehends, adapts, and innovates alongside human communication.
1. What is Text Annotation?
Text annotation is a crucial process that involves adding labels, comments, or metadata to textual data to facilitate machine learning algorithms' understanding and analysis.
This practice, known for its traditional role in editorial reviews by adding comments or footnotes to text drafts, has evolved significantly within the realm of data science, particularly in Natural Language Processing (NLP) and Computer Vision applications .
In the context of machine learning, text annotation takes on a more specific role. It involves systematically labeling pieces of text to create a reference dataset, enabling supervised machine learning algorithms to recognize patterns, learn from labeled data, and make accurate predictions or classifications when faced with new, unseen text.
To elaborate on what it means to annotate text: In data science and NLP, annotating text demands a comprehensive understanding of the problem domain and the dataset. It involves identifying and marking relevant features within the text. This can be akin to labeling images in image classification tasks, but in text, it includes categorizing sentences or segments into predefined classes or topics.
For instance, labeling sentiments in online reviews, distinguishing fake and real news articles, or marking parts of speech and named entities in text.

1.1 Text Annotation Tasks: A Multifaceted Approach to Data Labeling
(i) Text Classification : Assigning predefined categories or labels to text segments based on their content, such as sentiment analysis or topic classification.
(ii) Named Entity Recognition (NER) : Identifying and labeling specific entities within the text, like names of people, organizations, locations, dates, etc.
(iii) Parts of Speech Tagging : Labeling words in a sentence with their respective grammatical categories, like nouns, verbs, adjectives, etc.
(iv) Summarization : Condensing a lengthy text into a shorter, coherent version while retaining its key information.
1.2 Significant Benefits of Text Annotation
(i) Improved Machine Learning Models : Annotated data provides labeled examples for algorithms to learn from, enhancing their ability to make accurate predictions or classifications when faced with new, unlabeled text.
(ii) Enhanced Performance and Efficiency : Annotations expedite the learning process by offering clear indicators to algorithms, leading to improved performance and faster model convergence.
(iii) Nuance Recognition : Text annotations help algorithms understand contextual nuances, sarcasm, or subtle linguistic cues that might not be immediately apparent, enhancing their ability to interpret text accurately.
(iv) Applications in Various Industries : Text annotation is vital across industries, aiding in tasks like content moderation, sentiment analysis for customer feedback , information extraction for search engines , and much more.
Text annotation is a critical process in modern machine learning, empowering algorithms to comprehend, interpret, and extract valuable insights from textual data, thereby enabling various applications across different sectors.
2. Types of Text Annotation

Text annotation, in the realm of data labeling and Natural Language Processing (NLP), encompasses a diverse range of techniques used to label, categorize, and extract meaningful information from textual data. This multifaceted process involves several types of annotations, each serving a distinct purpose in enhancing machine understanding and analysis of text.

These annotation types include sentiment annotation, intent annotation, entity annotation, text classification, linguistic annotation, named entity recognition (NER), part-of-speech tagging, keyphrase tagging, entity linking, document classification, language identification, and toxicity classification.
1. Sentiment Annotation
Sentiment annotation is a technique crucial for understanding emotions conveyed in text. Assigning sentiments like positive, negative, or neutral to sentences aids in sentiment analysis .
This process involves deciphering emotions in customer reviews on e-commerce platforms (e.g., Amazon, Flipkart), enabling businesses to gauge customer satisfaction.
Precise sentiment annotation is vital for training machine learning models that categorize texts into various emotions, facilitating a deeper understanding of user sentiments towards products or services.
Let's consider various instances where sentiment annotation encounters complexities:

(i) Clear Emotions: In the initial examples, emotions are distinctly evident. The first instance exudes happiness and positivity, while the second reflects disappointment and negative feelings. However, in the third case, emotions become intricate. Phrases like "nostalgic" or "bittersweet" evoke mixed sentiments, making it challenging to classify into a single emotion.
(ii) Success versus Failure: Analyzing phrases such as "Yay! Argentina beat France in the World Cup Finale" presents a paradox. Initially appearing positive, this sentence also implies negative emotions for the opposing side, complicating straightforward sentiment classification.
(iii) Sarcasm and Ridicule: Capturing sarcasm involves comprehending nuanced human communication styles, relying on context, tone, and social cues—characteristics often intricate for machines to interpret.
(iv) Rhetorical Questions: Phrases like "Why do we have to quibble every time?" may seem neutral initially. However, the speaker's tone and delivery convey a sense of frustration and negativity, posing challenges in categorizing the sentiment accurately.
(v) Quoting or Re-tweeting: Sentiment annotation confronts difficulties when dealing with quoted or retweeted content. The sentiment expressed might not align with the opinions of the one sharing the quote, creating discrepancies in sentiment classification.
In essence, sentiment annotation encounters challenges due to the complexity of human emotions, contextual nuances, and the subtleties of language expression, making accurate classification a demanding task for automated systems.
Intent Annotation
Intent annotation is a crucial aspect in the development of chatbots and virtual assistants , forming the backbone of their functionality. It involves labeling or categorizing user messages or sentences to identify the underlying purpose or intention behind the communication.
This annotation process aims to understand and extract the user's intent, enabling these AI systems to provide contextually relevant and accurate responses. Intent annotation involves labeling sentences to discern the user's intention behind a message. By annotating intents like greetings, complaints, or inquiries, systems can generate appropriate responses.

Key points regarding intent text annotation include:
Purpose Identification: Intent annotation involves categorizing user messages into specific intents such as greetings, inquiries, complaints, feedback, orders, or any other actionable user intents. Each category represents a different user goal or purpose within the conversation.
Training Data Creation: Creating labeled datasets is crucial for training machine learning models to recognize and classify intents accurately. Annotated datasets consist of labeled sentences or phrases paired with their corresponding intended purposes, forming the foundation for model training.
Contextual Understanding: Intent annotation often requires a deep understanding of contextual nuances within language. It's not solely about identifying keywords but comprehending the broader meaning and context of user queries or statements.
Natural Language Understanding (NLU) : It falls under the realm of natural language processing (NLP) and requires sophisticated algorithms capable of interpreting and categorizing user intents accurately. Machine learning models, such as classifiers or neural networks, are commonly used for this purpose.
Iterative Process: Annotation of intents often involves an iterative process. Initially, a set of intent categories is defined based on common user interactions. As the system encounters new user intents, the annotation process may expand or refine these categories to ensure comprehensive coverage.
Quality Assurance and Validation: It's essential to validate and ensure the quality of labeled data. This may involve multiple annotators labeling the same data independently to assess inter-annotator agreement and enhance annotation consistency.
Adaptation and Evolution: Intent annotation isn't a one-time task. As user behaviors, language use, and interaction patterns evolve, the annotated intents also need periodic review and adaptation to maintain accuracy and relevance.
Enhancing User Experience: Accurate intent annotation is pivotal in enhancing user experience. It enables chatbots and virtual assistants to understand user needs promptly and respond with relevant and helpful information or actions, improving overall user satisfaction.
Industry-Specific Customization: Intent annotation can be industry-specific. For instance, in healthcare, intents may include appointment scheduling, medication queries, or symptom descriptions, while in finance, intents may revolve around account inquiries, transaction history, or support requests.
Continuous Improvement: Feedback loops and analytics derived from user interactions help refine intent annotation. Analyzing user feedback on system responses can drive improvements in intent categorization and response generation.
For instance, Siri or Alexa, trained on annotated data for specific intents, responds accurately to user queries, enhancing user experience. Below are given examples:
- Greeting Intent: Hello there, how are you?
- Complaint Intent: I am very disappointed with the service I received.
- Inquiry Intent: What are your business hours?
- Confirmation Intent: Yes, I'd like to confirm my appointment for tomorrow at 10 AM.
- Request Intent: Could you please provide me with the menu?
- Gratitude Intent: Thank you so much for your help!
- Feedback Intent: I wanted to give feedback about the recent product purchase.
- Apology Intent: I'm sorry for the inconvenience caused.
- Assistance Intent: Can you assist me with setting up my account?
- Goodbye Intent: Goodbye, have a great day!
These annotations serve as training data for AI models to learn and understand different user intentions, enabling chatbots or virtual assistants to respond accurately and effectively.
Entity Annotation:
Entity annotation focuses on labeling key phrases, named entities, or parts of speech in text. This technique emphasizes crucial details in lengthy texts and aids in training models for entity extraction. Named entity recognition (NER) is a subset of entity annotation, labeling entities like people's names, locations, dates, etc., enabling machines to comprehend text more comprehensively by distinguishing semantic meanings.
Text Classification
Text classification assigns categories or labels to text segments. This annotation technique is essential for organizing text data into specific classes or topics, such as document classification or sentiment analysis. Categorizing tweets into education, politics, etc., helps organize content and enables better understanding.

Let's look at each of these forms separately.
Document Classification: This involves assigning a single label to a document, aiding in the efficient sorting of vast textual data based on its primary theme or content.
Product Categorization: It's the process of organizing products or services into specific classes or categories. This helps enhance search results in eCommerce platforms, improving SEO strategies and boosting visibility in product ranking pages.
Email Classification: This task involves categorizing emails into either spam or non-spam (ham) categories, typically based on their content, aiding in email filtering and prioritization.
News Article Classification: Categorizing news articles based on their content or topics such as politics, entertainment, sports, technology, etc. This categorization assists in better organizing and presenting news content to readers.
Language Identification: This task involves determining the language used in a given text, is useful in multilingual contexts or language-specific applications.
Toxicity Classification: Identifying whether a social media comment or post contains toxic content, hate speech, or is non-toxic. This classification helps in content moderation and creating safer online environments.
Each form of text annotation serves a specific purpose, enabling better organization, classification, and understanding of textual data, and contributing to various applications across industries and domains.
Linguistic Annotation
Linguistic annotation focuses on language-related details in text or speech, including semantics, phonetics, and discourse. It encompasses intonation, stress, pauses, and discourse relations. It helps systems understand linguistic nuances, like coreference resolution linking pronouns to their antecedents, semantic labeling, and annotating stress or tone in speech.
Named Entity Recognition (NER)
NER identifies and labels named entities like people's names, locations, dates, etc., in text. It plays a pivotal role in NLP applications, allowing systems like Google Translate or Siri to understand and process textual data accurately.
Part-of-Speech Tagging
Part-of-speech tagging labels words in a sentence with their grammatical categories (nouns, verbs, adjectives). It assists in parsing sentences and understanding their structure.
Keyphrase Tagging
Keyphrase tagging locates and labels keywords or keyphrases in text, aiding in tasks like summarization or extracting key concepts from large text documents.
Entity Linking
Entity linking maps words in text to entities in a knowledge base, aiding in disambiguating entities' meanings and connecting them to larger datasets for contextual understanding.
3. Text Annotation use cases
(i) healthcare.
Text annotation significantly transforms healthcare operations by leveraging AI and machine learning techniques to enhance patient care, streamline processes, and improve overall efficiency:
Automatic Data Extraction: Text annotation aids in extracting critical information from clinical trial records, facilitating better access and analysis of medical documents. It expedites research efforts and supports comprehensive data-driven insights.
Patient Record Analysis: Annotated data enables thorough analysis of patient records, leading to improved outcomes and more accurate medical condition detection. It aids healthcare professionals in making informed decisions and providing tailored treatments.
Insurance Claims Processing: Within healthcare insurance, text annotation helps recognize medically insured patients, identify loss amounts, and extract policyholder information. This speeds up claims processing, ensuring faster service delivery to policyholders.

(II) Insurance
Text annotation in the insurance industry revolutionizes various facets of operations, making tasks more efficient and accurate:
Risk Evaluation: By annotating and extracting contextual data from contracts and forms, text annotation supports risk evaluation, enabling insurance companies to make more informed decisions while minimizing potential risks.
Claims Processing: Annotated data assists in recognizing entities like involved parties and loss amounts, significantly expediting the claims processing workflow. It aids in detecting dubious claims, contributing to fraud detection efforts.
Fraud Detection: Through text annotation, insurance firms can monitor and analyze documents and forms more effectively, enhancing their capabilities to detect fraudulent claims and irregularities.

(III) Banking
The banking sector utilizes text annotation to revolutionize operations and ensure better accuracy and customer satisfaction:
Fraud Identification: Text annotation techniques aid in identifying potential fraud and money laundering patterns, allowing banks to take proactive measures and ensure security.
Custom Data Extraction: Annotated text facilitates the extraction of critical information from contracts, improving workflows and ensuring compliance. It enables efficient data extraction for various attributes like loan rates and credit scores, supporting compliance monitoring.

(IV) Government
In government operations, text annotation facilitates various tasks, ensuring better efficiency and compliance:
Regulatory Compliance: Text annotation streamlines financial operations by ensuring regulatory compliance through advanced analytics . It helps maintain compliance standards more effectively.
Document Classification: Through text classification and annotation, different types of legal cases can be categorized, ensuring efficient document management and access to digital documents.
Fraud Detection & Analytics: Text annotation assists in the early detection of fraudulent activities by utilizing linguistic annotation, semantic annotation, tone detection , and entity recognition. It enables analytics on vast amounts of data for insights.

(V) Logistics
Text annotation in logistics plays a pivotal role in handling massive volumes of data and improving customer experiences:
Invoice Annotation: Annotated text assists in extracting crucial details such as amounts, order numbers, and names from invoices. It streamlines billing and invoicing processes.
Customer Feedback Analysis: By utilizing sentiment and entity annotation, logistics companies can analyze customer feedback, ensuring better service improvements and customer satisfaction.

(VI) Media and News
Text annotation's role in the media industry is indispensable for content categorization and credibility:
Content Categorization: Annotation is crucial for categorizing news content into various segments such as sports, education, government, etc., enabling efficient content management and retrieval.
Entity Recognition: Annotating entities like names, locations, and key phrases in news articles aids in information retrieval and fact-checking. It contributes to credibility and accurate reporting.
Fake News Detection: Utilizing text annotation techniques such as NLP annotation and sentiment analysis enables the identification of fake news by analyzing the credibility and sentiment of the content.

These comprehensive applications across sectors showcase how text annotation significantly impacts various industries, making operations more efficient, accurate, and streamlined.
4. Text Annotation Guidelines
Annotation guidelines serve as a comprehensive set of instructions and rules for annotators when labeling or annotating text data for machine learning tasks. These guidelines are crucial as they define the objectives of the modeling task and the purpose behind the labels assigned to the data. They are crafted by a team familiar with the data and the intended use of the annotations.
Starting with defining the modeling problem and the desired outcomes, annotation guidelines cover various aspects:
(i) Annotation Techniques: Guidelines may start by choosing appropriate annotation methods tailored to the specific problem being addressed.
(ii) Case Definitions: They define common and potentially ambiguous cases that annotators might encounter in the data, along with instructions on how to handle each scenario.
(iii) Handling Ambiguity: Guidelines include examples from the data and strategies to deal with outliers, ambiguous instances, or unusual cases that might arise during annotation.
Text Annotation Workflow
An annotation workflow typically consists of several stages:
(i) Curating Annotation Guidelines: Define the problem, set the expected outcomes, and create comprehensive guidelines that are easy to follow and revisit.
(ii) Selecting a Labeling Tool: Choose appropriate text annotation tools, considering options like Labellerr or other available tools that suit the task's requirements.
(iii) Defining Annotation Process: Create a reproducible workflow that encompasses organizing data sources, utilizing guidelines, employing annotation tools effectively, documenting step-by-step annotation processes, defining formats for saving and exporting annotations, and reviewing each labeled sample.
(iv) Review and Quality Control: Regularly review labeled data to prevent generic label errors, biases, or inconsistencies. Multiple annotators may label the same samples to ensure consistency and reduce interpretational bias. Statistical measures like Cohen's kappa statistic can assess annotator agreement to identify and address discrepancies or biases in annotations.
Ensuring a streamlined flow of incoming data samples, rigorous review processes, and consistent adherence to annotation guidelines are crucial for generating high-quality labeled datasets for machine learning models. Regular monitoring and quality checks help maintain the reliability and integrity of the annotated data.
5. Text Annotation Tools and Technologies

Text annotation tools play a vital role in preparing data for AI and machine learning, particularly in natural language processing (NLP) applications. These tools fall into two main categories: open-source and commercial offerings. Open-source tools, available at no cost, are customizable and widely used in startups and academic projects for their affordability. Conversely, commercial tools offer advanced functionalities and support, making them suitable for large-scale and enterprise-level projects.
Commercial Text Annotation Tools
(i) labellerr.
Labellerr is a text annotation tool that provides high-quality and accurate text annotations for training AI models at scale. The tool, Labellerr, offers various features and services tailored to text annotation needs.

Labellerr boasts the following functionalities and services:
Text Annotation Features:
(i) Sentiment Analysis: Identifies sentiments and emotions in text, categorizing statements as positive, negative, or neutral.
(ii) Summarization: Highlights key sentences or phrases within text to create a summarized version.
(iii) Translation: Translates selected text segments into different languages, such as English to French or German to Italian.
(iv) Named-Entity Recognition: Tags named entities (e.g., ID, Name, Place, Price) in text based on predefined categories.
(v) Text Classification: Classifies text by assigning appropriate classes based on their content.
(vi) Question Answering: Matches questions with their respective answers to train models for generating accurate responses.
Automated Workflows:
(i) Customization: Allows users to create custom automated data workflows, collaborate in real-time, perform QA reviews, and gain complete visibility into AI operations.
(ii) Pipeline Management: Enables the creation and automation of text labeling workflows, multiple user roles, review cycles, inter-annotator agreements, and various annotation stages.
Text Labeling Services:
(i) Provides professional text annotators and linguists focused on ensuring quality and accuracy in annotations.
(ii) Offers fully managed services, allowing users to concentrate on other important aspects while delegating text annotation tasks.

Labellerr emerges as a comprehensive and versatile commercial text annotation tool that streamlines the process of annotating large text datasets for AI model training purposes. It provides a wide array of annotation capabilities and customizable workflows, catering to diverse text annotation requirements.
(II) SuperAnnotate
SuperAnnotate is an advanced text annotation tool designed to facilitate the creation of high-quality and accurate annotations essential for training top-performing AI models. This tool offers a wide array of features and functionalities aimed at streamlining text annotation processes for various industries and use cases.

Key Features of SuperAnnotate's Text Annotation Tool:
Cloud Integrations: Supports integration with various cloud storage systems, allowing users to easily add items from their cloud repositories to the SuperAnnotate platform.
Versatile Use Cases: Encompasses all use cases, ensuring its applicability across different industries and scenarios.
Advanced Annotation Tools: Equipped with an array of advanced tools tailored for efficient text annotation.
Functionalities Offered by SuperAnnotate:
Sentiment Analysis: Capable of identifying sentiments expressed in text, determining whether statements are positive, negative, or neutral, and even detecting emotions like happiness or anger.
Summarization: Annotations can focus on key sentences or phrases within text, aiding in the creation of summarized versions.
Translation Assistance: Annotations assist in identifying elements for translation, such as sentences, terms, and specific entities.
Named-Entity Recognition: Detects and classifies named entities within text, sorting them into predefined categories like dates, locations, names of individuals, and more.
Text Classification: Assigns classes to texts based on their content and characteristics.
Question Answering: Enables the pairing of questions with corresponding answers to train models for generating accurate responses.
Efficiency-Boosting Features:
Token Annotation: Splits texts into units using linguistic knowledge, ensuring seamless and accurate annotation.
Classify All: Instantly assigns the same class to every occurrence of a word or phrase in a text, enhancing efficiency.
Quality-Focused Elements:
Collaboration System: Involves stakeholders in the quality review process through comments, fostering seamless collaboration and task distribution.
Status Tracking: Provides visibility into the status of items and projects, allowing users to track progress effectively.
Detailed Instructions: Sets a solid foundation for project execution by offering comprehensive project instructions to the team.
(III) V7 Labs
The V7 Text Annotation Tool is a feature within the V7 platform that facilitates the annotation of text data within images and documents. This tool automates the process of detecting and reading text from various types of visual content, including images, photos, documents, and videos.

Key features and steps associated with the V7 Text Annotation Tool include:
Text Scanner Model : V7 has incorporated a public Text Scanner model within its Neural Networks page. This model is designed to automatically detect and read text within images and documents.
Integration into Workflow : Add a model stage to the workflow under the Settings page of your dataset. Select the Text Scanner model from the dropdown list and map the newly created text class. If desired, enable the Auto-Start option to automatically process new images through the model at the beginning of the workflow.
Automatic Text Detection and Reading : Once set up, the V7 Text Annotation Tool will automatically scan and read text from different types of images, including documents, photos, and videos. The tool is extensively pre-trained, enabling it to interpret characters that might be challenging for humans to decipher accurately.
Overall, the V7 Text Annotation Tool streamlines the process of text annotation by leveraging a pre-trained model to automatically detect and read text within visual content, providing an efficient and accurate solution for handling text data in images and documents.
Open Source Text Annotation Tools
(i) piaf platform.
- Led by Etalab, this tool aims to create a public Q&A dataset in French.
- Initially designed for question/answer annotation, it allows users to write questions and highlight text segments that answer them.
- Offers an easy installation process and collaborative annotation capabilities.
- Export annotations in the format of the Stanford SQuAD dataset.
- Limited to question/answer annotation but has potential for adaptation to other use cases like sentiment analysis or named entity recognition.

(II) Label Studio
- Free and open-source tool suitable for various tasks like natural language processing, computer vision, and more.
- Highly scalable and configurable labeling interface.
- Provides templates for common tasks (sentiment analysis, named entities, object detection) for easy setup.
- Allows exporting labeled data in multiple formats, compatible with learning algorithms.
- Supports collaborative annotation and can be deployed on servers for simultaneous annotation by multiple collaborators.

(III) Doccano

- Originally designed for text annotation tasks and recently extended to image classification, object detection, and speech-to-text annotations.
- Offers local installation via pip, supporting SQLite3 or PostgreSQL databases for saving annotations and datasets.
- Docker image available for deployment on various cloud providers.
- Simple user interface, collaborative features, and customizable labeling templates.
- Allows importing datasets in various formats (CSV, JSON, fastText) and exporting annotations accordingly.

These open-source tools provide valuable solutions for annotating text data, with each tool having its unique features and suitability for specific annotation tasks. While PIAF is focused on Q&A datasets in French, Label Studio offers extensive customization, and Doccano supports diverse annotation tasks, expanding beyond text to cover image and speech annotations.
Open-source NLP Service Toolkits
- spaCy : A Python library designed for production-level NLP tasks. While not a standalone annotation tool, it's often used with tools like Prodigy or Doccano for text annotation.
- NLTK (Natural Language Toolkit) : A popular Python platform that provides numerous text-processing libraries for various language-related tasks. It can be combined with other tools for text annotation purposes.
- Stanford CoreNLP : A Java-based toolkit capable of performing diverse NLP tasks like part-of-speech tagging, named entity recognition, parsing, and coreference resolution. It's typically used as a backend for annotation tools.
- GATE (General Architecture for Text Engineering) : An extensive open-source toolkit equipped with components for text processing, information extraction, and semantic annotation.
- Apache OpenNLP : A machine learning-based toolkit supporting tasks such as tokenization, part-of-speech tagging, entity extraction, and more. It's used alongside other tools for text annotation.
- UIMA (Unstructured Information Management Architecture) : An open-source framework facilitating the development of applications for analyzing unstructured information like text, audio, and video. It's used in conjunction with other tools for text annotation.
Commercial NLP Service Platforms
- Amazon Comprehend : A machine learning-powered NLP service offering entity recognition, sentiment analysis, language detection, and other text insights. APIs facilitate easy integration into applications.
- Google Cloud Natural Language API : Provides sentiment analysis, entity analysis, content classification, and other NLP features. Part of Google Cloud's Machine Learning APIs.
- Microsoft Azure Text Analytics : Offers sentiment analysis, key phrase extraction, language detection, and named entity recognition among its text processing capabilities.
- IBM Watson Natural Language Understanding : Utilizes deep learning to extract meaning, sentiment, entities, relations, and more from unstructured text. Available through IBM Cloud with REST APIs and SDKs for integration.
- MeaningCloud : A text analytics platform supporting sentiment analysis, topic extraction, entity recognition, and classification across multiple languages through APIs and SDKs.
- Rosette Text Analytics : Provides entity extraction, sentiment analysis, relationship extraction, and language identification functionalities across various languages. Can be integrated into applications using APIs and SDKs.
6. Challenges in Text Annotation
AI and ML companies face numerous hurdles in text annotation processes. These encompass ensuring data quality, efficiently handling large datasets, mitigating annotator biases, safeguarding sensitive information, and scaling operations as data volumes expand. Tackling these issues is crucial to achieving precise model training and robust AI outcomes.

(i) Ambiguity
This occurs when a word, phrase, or sentence holds multiple meanings, leading to inconsistencies in annotations. Resolving such ambiguities is vital for accurate machine learning model training. For instance, the phrase "I saw the man with the telescope" can be interpreted in different ways, impacting annotation accuracy.
(ii) Subjectivity
Annotating subjective language, containing personal opinions or emotions, poses challenges due to differing interpretations among annotators. Labeling sentiment in customer reviews can vary based on annotators' perceptions, resulting in inconsistencies in annotations.
(iii) Contextual Understanding
Accurate annotation relies on understanding the context in which words or phrases are used. Failing to consider context, such as the dual meaning of "bank" referring to a financial institution or a river side, can lead to incorrect annotations and hinder model performance.
(iv) Language Diversity
The need for proficiency in multiple languages poses challenges in annotating diverse datasets. Finding annotators proficient in less common languages or dialects is difficult, leading to inconsistencies in annotations and proficiency levels among annotators.
(v) Scalability
Annotating large volumes of data is time-consuming and resource-intensive. Handling increasing data volumes demands more annotators, posing challenges in efficiently scaling annotation efforts.
Hiring and training annotators and investing in annotation tools can be expensive. The significant investment required in the data labeling market emphasizes the challenge of balancing accurate annotations with the associated costs for AI and machine learning implementation.
7. The Future of Text Annotation
Text annotation, an integral part of data annotation, is experiencing several future trends that align with the broader advancements in data annotation processes. These trends are likely to shape the landscape of text annotation in the coming years:

(i) Natural Language Processing (NLP) Advancements
With the rapid progress in NLP technologies, text annotation is expected to witness the development of more sophisticated tools that can understand and interpret textual data more accurately. This includes improvements in sentiment analysis, entity recognition, named entity recognition, and other text categorization tasks.
(ii) Contextual Understanding
Future trends in text annotation will likely focus on capturing contextual understanding within language models. This involves annotating text with a deeper understanding of nuances, tone, and context, leading to the creation of more context-aware and accurate language models.
(iii) Multilingual Annotation
As the demand for multilingual AI models grows, text annotation will follow suit. Future trends involve annotating and curating datasets in multiple languages, enabling the training of AI models that can understand and generate content in various languages.
(iv) Fine-grained Annotation for Specific Applications
Industries such as healthcare, legal, finance, and customer service are increasingly utilizing AI-driven solutions. Future trends will involve more fine-grained and specialized text annotation tailored to these specific domains, ensuring accurate and domain-specific language models.
(v) Emphasis on Bias Mitigation
Recognizing and mitigating biases within text data is crucial for fair and ethical AI. Future trends in text annotation will focus on identifying and mitigating biases in textual datasets to ensure AI models are fair and unbiased across various demographics and social contexts.
(vi) Semi-supervised and Active Learning Approaches
To optimize annotation efforts, future trends in text annotation might include the integration of semi-supervised and active learning techniques. These methods intelligently select the most informative samples for annotation, reducing the annotation workload while maintaining model performance.
(vii) Privacy-Centric Annotation Techniques
In alignment with broader data privacy concerns, text annotation will likely adopt techniques that ensure the anonymization and protection of sensitive information within text data, balancing the need for annotation with privacy preservation.
(viii) Enhanced Collaboration and Crowdsourcing Platforms
Similar to other data annotation domains, text annotation will benefit from collaborative and crowdsourced platforms that allow distributed teams to annotate text data efficiently. These platforms will offer improved coordination, quality control mechanisms, and scalability.
(ix) Continual Learning and Adaptation
As language evolves and new linguistic patterns emerge, text annotation will evolve towards continual learning paradigms. This will enable AI models to adapt and learn from ongoing annotations, ensuring they remain relevant and up-to-date.
(x) Explainable AI through Annotation
Text annotation may involve creating datasets that facilitate the development of explainable AI models. Annotations focused on explaining decisions made by AI systems can aid in building transparent and interpretable language models.
These future trends in text annotation are driven by the evolving nature of AI technology, the increasing demands for more accurate and specialized AI models, ethical considerations, and the need for scalable and efficient annotation processes.
The exploration of text annotation highlights its crucial role in AI's language understanding. This journey revealed:
(i) Text annotation is vital for AI to interpret human language nuances across industries like healthcare, finance, and more.
(ii) Challenges in annotation, like dealing with ambiguity and subjectivity, stress the need for ongoing innovation.
(iii) The best practices and guidelines for text annotation and various available text annotation tools.
(iv) The future promises advancements in language processing, bias mitigation, and contextual understanding.
Overall, text annotation is a cornerstone in AI's language comprehension, fostering innovation and laying the groundwork for seamless human-machine communication in the future.
Frequently Asked Questions
1. what is text annotation & why is it important.
Text annotation enriches raw text by labeling entities, sentiments, parts of speech , etc. This labeled data trains AI models for better language understanding. It's crucial for improving accuracy in tasks like sentiment analysis, named entity recognition, and more. Annotation aids in creating domain-specific AI models and standardizing data, facilitating precise human-AI interactions.
2. What are the different types of annotation techniques?
Annotation techniques involve labeling different aspects of text data for training AI models. Types include Entity Annotation (identifying entities), Sentiment Annotation (labeling emotions), Intent Annotation (categorizing purposes), Linguistic Annotation (marking grammar), Relation Extraction, Coreference Resolution, Temporal Annotation , and Speech Recognition Annotation .
These techniques are vital for training models in various natural language processing tasks, aiding accurate comprehension and response generation by AI systems.
3. What is in-text annotation?
In-text annotation involves adding labels directly within the text to highlight attributes like phrases, keywords, or sentences. These labels guide machine learning models. Quality in-text annotations are essential for building accurate models as they provide reliable training data for AI systems to understand and process language more effectively.
Book our demo with one of our product specialist
Sign up for more like this.

How to Annotate Texts
Use the links below to jump directly to any section of this guide:
Annotation Fundamentals
How to start annotating , how to annotate digital texts, how to annotate a textbook, how to annotate a scholarly article or book, how to annotate literature, how to annotate images, videos, and performances, additional resources for teachers.
Writing in your books can make you smarter. Or, at least (according to education experts), annotation–an umbrella term for underlining, highlighting, circling, and, most importantly, leaving comments in the margins–helps students to remember and comprehend what they read. Annotation is like a conversation between reader and text. Proper annotation allows students to record their own opinions and reactions, which can serve as the inspiration for research questions and theses. So, whether you're reading a novel, poem, news article, or science textbook, taking notes along the way can give you an advantage in preparing for tests or writing essays. This guide contains resources that explain the benefits of annotating texts, provide annotation tools, and suggest approaches for diverse kinds of texts; the last section includes lesson plans and exercises for teachers.
Why annotate? As the resources below explain, annotation allows students to emphasize connections to material covered elsewhere in the text (or in other texts), material covered previously in the course, or material covered in lectures and discussion. In other words, proper annotation is an organizing tool and a time saver. The links in this section will introduce you to the theory, practice, and purpose of annotation.
How to Mark a Book, by Mortimer Adler
This famous, charming essay lays out the case for marking up books, and provides practical suggestions at the end including underlining, highlighting, circling key words, using vertical lines to mark shifts in tone/subject, numbering points in an argument, and keeping track of questions that occur to you as you read.
How Annotation Reshapes Student Thinking (TeacherHUB)
In this article, a high school teacher discusses the importance of annotation and how annotation encourages more effective critical thinking.
The Future of Annotation (Journal of Business and Technical Communication)
This scholarly article summarizes research on the benefits of annotation in the classroom and in business. It also discusses how technology and digital texts might affect the future of annotation.
Annotating to Deepen Understanding (Texas Education Agency)
This website provides another introduction to annotation (designed for 11th graders). It includes a helpful section that teaches students how to annotate reading comprehension passages on tests.
Once you understand what annotation is, you're ready to begin. But what tools do you need? How do you prepare? The resources linked in this section list strategies and techniques you can use to start annotating.
What is Annotating? (Charleston County School District)
This resource gives an overview of annotation styles, including useful shorthands and symbols. This is a good place for a student who has never annotated before to begin.
How to Annotate Text While Reading (YouTube)
This video tutorial (appropriate for grades 6–10) explains the basic ins and outs of annotation and gives examples of the type of information students should be looking for.
Annotation Practices: Reading a Play-text vs. Watching Film (U Calgary)
This blog post, written by a student, talks about how the goals and approaches of annotation might change depending on the type of text or performance being observed.
Annotating Texts with Sticky Notes (Lyndhurst Schools)
Sometimes students are asked to annotate books they don't own or can't write in for other reasons. This resource provides some strategies for using sticky notes instead.
Teaching Students to Close Read...When You Can't Mark the Text (Performing in Education)
Here, a sixth grade teacher demonstrates the strategies she uses for getting her students to annotate with sticky notes. This resource includes a link to the teacher's free Annotation Bookmark (via Teachers Pay Teachers).
Digital texts can present a special challenge when it comes to annotation; emerging research suggests that many students struggle to critically read and retain information from digital texts. However, proper annotation can solve the problem. This section contains links to the most highly-utilized platforms for electronic annotation.
Evernote is one of the two big players in the "digital annotation apps" game. In addition to allowing users to annotate digital documents, the service (for a fee) allows users to group multiple formats (PDF, webpages, scanned hand-written notes) into separate notebooks, create voice recordings, and sync across all sorts of devices.
OneNote is Evernote's main competitor. Reviews suggest that OneNote allows for more freedom for digital note-taking than Evernote, but that it is slightly more awkward to import and annotate a PDF, especially on certain platforms. However, OneNote's free version is slightly more feature-filled, and OneNote allows you to link your notes to time stamps on an audio recording.
Diigo is a basic browser extension that allows a user to annotate webpages. Diigo also offers a Screenshot app that allows for direct saving to Google Drive.
While the creators of Hypothesis like to focus on their app's social dimension, students are more likely to be interested in the private highlighting and annotating functions of this program.
Foxit PDF Reader
Foxit is one of the leading PDF readers. Though the full suite must be purchased, Foxit offers a number of annotation and highlighting tools for free.
Nitro PDF Reader
This is another well-reviewed, free PDF reader that includes annotation and highlighting. Annotation, text editing, and other tools are included in the free version.
Goodreader is a very popular Mac-only app that includes annotation and editing tools for PDFs, Word documents, Powerpoint, and other formats.
Although textbooks have vocabulary lists, summaries, and other features to emphasize important material, annotation can allow students to process information and discover their own connections. This section links to guides and video tutorials that introduce you to textbook annotation.
Annotating Textbooks (Niagara University)
This PDF provides a basic introduction as well as strategies including focusing on main ideas, working by section or chapter, annotating in your own words, and turning section headings into questions.
A Simple Guide to Text Annotation (Catawba College)
The simple, practical strategies laid out in this step-by-step guide will help students learn how to break down chapters in their textbooks using main ideas, definitions, lists, summaries, and potential test questions.
Annotating (Mercer Community College)
This packet, an excerpt from a literature textbook, provides a short exercise and some examples of how to do textbook annotation, including using shorthand and symbols.
Reading Your Healthcare Textbook: Annotation (Saddleback College)
This powerpoint contains a number of helpful suggestions, especially for students who are new to annotation. It emphasizes limited highlighting, lots of student writing, and using key words to find the most important information in a textbook. Despite the title, it is useful to a student in any discipline.
Annotating a Textbook (Excelsior College OWL)
This video (with included transcript) discusses how to use textbook features like boxes and sidebars to help guide annotation. It's an extremely helpful, detailed discussion of how textbooks are organized.
Because scholarly articles and books have complex arguments and often depend on technical vocabulary, they present particular challenges for an annotating student. The resources in this section help students get to the heart of scholarly texts in order to annotate and, by extension, understand the reading.
Annotating a Text (Hunter College)
This resource is designed for college students and shows how to annotate a scholarly article using highlighting, paraphrase, a descriptive outline, and a two-margin approach. It ends with a sample passage marked up using the strategies provided.
Guide to Annotating the Scholarly Article (ReadWriteThink.org)
This is an effective introduction to annotating scholarly articles across all disciplines. This resource encourages students to break down how the article uses primary and secondary sources and to annotate the types of arguments and persuasive strategies (synthesis, analysis, compare/contrast).
How to Highlight and Annotate Your Research Articles (CHHS Media Center)
This video, developed by a high school media specialist, provides an effective beginner-level introduction to annotating research articles.
How to Read a Scholarly Book (AndrewJacobs.org)
In this essay, a college professor lets readers in on the secrets of scholarly monographs. Though he does not discuss annotation, he explains how to find a scholarly book's thesis, methodology, and often even a brief literature review in the introduction. This is a key place for students to focus when creating annotations.
A 5-step Approach to Reading Scholarly Literature and Taking Notes (Heather Young Leslie)
This resource, written by a professor of anthropology, is an even more comprehensive and detailed guide to reading scholarly literature. Combining the annotation techniques above with the reading strategy here allows students to process scholarly book efficiently.
Annotation is also an important part of close reading works of literature. Annotating helps students recognize symbolism, double meanings, and other literary devices. These resources provide additional guidelines on annotating literature.
AP English Language Annotation Guide (YouTube)
In this ~10 minute video, an AP Language teacher provides tips and suggestions for using annotations to point out rhetorical strategies and other important information.
Annotating Text Lesson (YouTube)
In this video tutorial, an English teacher shows how she uses the white board to guide students through annotation and close reading. This resource uses an in-depth example to model annotation step-by-step.
Close Reading a Text and Avoiding Pitfalls (Purdue OWL)
This resources demonstrates how annotation is a central part of a solid close reading strategy; it also lists common mistakes to avoid in the annotation process.
AP Literature Assignment: Annotating Literature (Mount Notre Dame H.S.)
This brief assignment sheet contains suggestions for what to annotate in a novel, including building connections between parts of the book, among multiple books you are reading/have read, and between the book and your own experience. It also includes samples of quality annotations.
AP Handout: Annotation Guide (Covington Catholic H.S.)
This annotation guide shows how to keep track of symbolism, figurative language, and other devices in a novel using a highlighter, a pencil, and every part of a book (including the front and back covers).
In addition to written resources, it's possible to annotate visual "texts" like theatrical performances, movies, sculptures, and paintings. Taking notes on visual texts allows students to recall details after viewing a resource which, unlike a book, can't be re-read or re-visited ( for example, a play that has finished its run, or an art exhibition that is far away). These resources draw attention to the special questions and techniques that students should use when dealing with visual texts.
How to Take Notes on Videos (U of Southern California)
This resource is a good place to start for a student who has never had to take notes on film before. It briefly outlines three general approaches to note-taking on a film.
How to Analyze a Movie, Step-by-Step (San Diego Film Festival)
This detailed guide provides lots of tips for film criticism and analysis. It contains a list of specific questions to ask with respect to plot, character development, direction, musical score, cinematography, special effects, and more.
How to "Read" a Film (UPenn)
This resource provides an academic perspective on the art of annotating and analyzing a film. Like other resources, it provides students a checklist of things to watch out for as they watch the film.
Art Annotation Guide (Gosford Hill School)
This resource focuses on how to annotate a piece of art with respect to its formal elements like line, tone, mood, and composition. It contains a number of helpful questions and relevant examples.
Photography Annotation (Arts at Trinity)
This resource is designed specifically for photography students. Like some of the other resources on this list, it primarily focuses on formal elements, but also shows students how to integrate the specific technical vocabulary of modern photography. This resource also contains a number of helpful sample annotations.
How to Review a Play (U of Wisconsin)
This resource from the University of Wisconsin Writing Center is designed to help students write a review of a play. It contains suggested questions for students to keep in mind as they watch a given production. This resource helps students think about staging, props, script alterations, and many other key elements of a performance.
This section contains links to lessons plans and exercises suitable for high school and college instructors.
Beyond the Yellow Highlighter: Teaching Annotation Skills to Improve Reading Comprehension (English Journal)
In this journal article, a high school teacher talks about her approach to teaching annotation. This article makes a clear distinction between annotation and mere highlighting.
Lesson Plan for Teaching Annotation, Grades 9–12 (readwritethink.org)
This lesson plan, published by the National Council of Teachers of English, contains four complete lessons that help introduce high school students to annotation.
Teaching Theme Using Close Reading (Performing in Education)
This lesson plan was developed by a middle school teacher, and is aligned to Common Core. The teacher presents her strategies and resources in comprehensive fashion.
Analyzing a Speech Using Annotation (UNC-TV/PBS Learning Media)
This complete lesson plan, which includes a guide for the teacher and relevant handouts for students, will prepare students to analyze both the written and presentation components of a speech. This lesson plan is best for students in 6th–10th grade.
Writing to Learn History: Annotation and Mini-Writes (teachinghistory.org)
This teaching guide, developed for high school History classes, provides handouts and suggested exercises that can help students become more comfortable with annotating historical sources.
Writing About Art (The College Board)
This Prezi presentation is useful to any teacher introducing students to the basics of annotating art. The presentation covers annotating for both formal elements and historical/cultural significance.
Film Study Worksheets (TeachWithMovies.org)
This resource contains links to a general film study worksheet, as well as specific worksheets for novel adaptations, historical films, documentaries, and more. These resources are appropriate for advanced middle school students and some high school students.
Annotation Practice Worksheet (La Guardia Community College)
This worksheet has a sample text and instructions for students to annotate it. It is a useful resource for teachers who want to give their students a chance to practice, but don't have the time to select an appropriate piece of text.
- PDFs for all 136 Lit Terms we cover
- Downloads of 1902 LitCharts Lit Guides
- Teacher Editions for every Lit Guide
- Explanations and citation info for 40,034 quotes across 1902 books
- Downloadable (PDF) line-by-line translations of every Shakespeare play
Need something? Request a new guide .
How can we improve? Share feedback .
LitCharts is hiring!
Writers' Center
Eastern Washington University
Reading and Study Strategies
What is annotating and why do it, annotation explained, steps to annotating a source, annotating strategies.
- Using a Dictionary
- Study Skills
[ Back to resource home ]

[email protected] 509.359.2779
Cheney Campus JFK Library Learning Commons
Spokane Campus Catalyst Building C451 and C452
Stay Connected! Instagram Facebook
Helpful Links
Software for Annotating
ProQuest Flow (sign up with your EWU email)
FoxIt PDF Reader
Adobe Reader Pro - available on all campus computers
Track Changes in Microsoft Word
What is Annotating?
Annotating is any action that deliberately interacts with a text to enhance the reader's understanding of, recall of, and reaction to the text. Sometimes called "close reading," annotating usually involves highlighting or underlining key pieces of text and making notes in the margins of the text. This page will introduce you to several effective strategies for annotating a text that will help you get the most out of your reading.
Why Annotate?
By annotating a text, you will ensure that you understand what is happening in a text after you've read it. As you annotate, you should note the author's main points, shifts in the message or perspective of the text, key areas of focus, and your own thoughts as you read. However, annotating isn't just for people who feel challenged when reading academic texts. Even if you regularly understand and remember what you read, annotating will help you summarize a text, highlight important pieces of information, and ultimately prepare yourself for discussion and writing prompts that your instructor may give you. Annotating means you are doing the hard work while you read, allowing you to reference your previous work and have a clear jumping-off point for future work.
1. Survey : This is your first time through the reading
You can annotate by hand or by using document software. You can also annotate on post-its if you have a text you do not want to mark up. As you annotate, use these strategies to make the most of your efforts:
- Include a key or legend on your paper that indicates what each marking is for, and use a different marking for each type of information. Example: Underline for key points, highlight for vocabulary, and circle for transition points.
- If you use highlighters, consider using different colors for different types of reactions to the text. Example: Yellow for definitions, orange for questions, and blue for disagreement/confusion.
- Dedicate different tasks to each margin: Use one margin to make an outline of the text (thesis statement, description, definition #1, counter argument, etc.) and summarize main ideas, and use the other margin to note your thoughts, questions, and reactions to the text.
Lastly, as you annotate, make sure you are including descriptions of the text as well as your own reactions to the text. This will allow you to skim your notations at a later date to locate key information and quotations, and to recall your thought processes more easily and quickly.
- Next: Using a Dictionary >>
- Last Updated: Jul 21, 2021 3:01 PM
- URL: https://research.ewu.edu/writers_c_read_study_strategies
Text Annotation for Natural Language Processing – A Comprehensive Guide

Explore the pivotal role of text annotation in shaping NLP algorithms as we walk you through diverse types of text annotation, annotation tools, case studies, trends, and industry applications. The comprehensive guide throws insights into the Human-in-the-loop approach in text annotation.
Text annotation is a crucial part of natural language processing (NLP), through which textual data is labeled to identify and classify its components. Essential for training NLP models, text annotation involves tasks like named entity recognition, sentiment analysis, and part-of-speech tagging. By providing context and meaning to raw text, it plays a central role in enhancing the performance and accuracy of NLP applications.
Text annotation is not just a technical requirement, but a foundation for the growing NLP market, which witnessed a turnover of over $12 billion in 2020. According to Statista, the market for NLP is projected to grow at a compound annual growth rate (CAGR) of about 25% from 2021 to 2025.

Recent studies have shown that around two-thirds of NLP systems fail after they are put to use. The primary reason for this failure is their inability to deal with the complex data encountered outside of testing environments, highlighting the importance of high-quality text annotation .
Challenges in annotating text for NLP projects
Popular text annotation techniques, process of annotating text for nlp, how does hitl (human-in-the-loop) approach help, how ai companies benefit from text annotation for domain-based ai apps, types of text annotation in nlp and their effective use cases, text annotation tools, the future of text annotation.
Text annotation is a critical step in preparing data for Natural Language Processing (NLP) systems, which rely heavily on accurately labeled datasets. However, it faces many challenges ranging from data volumes and speed to consistency and data security.
- Volume of Data: NLP projects often require large datasets to be effective. Annotators face the daunting task of labeling vast amounts of text, which can be time consuming and mentally taxing. For instance, a project aimed at understanding customer sentiment might need to process millions of product reviews. This sheer volume can lead to fatigue, affecting the quality of the annotation.
- Speed of Production: In our fast-paced digital world, the speed at which text data is produced and needs to be processed is staggering. Social media platforms generate enormous amounts of data daily. Annotators are under pressure to work quickly, which can sometimes compromise the accuracy and depth of annotation. This need for speed can also lead to burnout among annotators.
- Resource Intensiveness: Text annotation is often a time-consuming and labor-intensive process. It requires a significant amount of human effort, which can be costly and inefficient, especially for large datasets.
- Scalability: As the amount of data increases, scaling the annotation process efficiently while maintaining quality is a major challenge. Automated tools can help, but they often require human validation to ensure accuracy.
- Ambiguity in Language: Natural language is inherently ambiguous and context-dependent. Capturing the correct meaning, especially in cases of idiomatic expressions, sarcasm, or context-specific usage, can be difficult. This ambiguity can lead to challenges in ensuring that the annotations accurately reflect the intended meaning.
- Language and Cultural Diversity: Dealing with multiple languages and cultural contexts increases the complexity of annotation. It’s challenging to ensure that annotators understand the nuances of different languages and cultural references.
- Domain-Specific Knowledge: Certain NLP applications require domain-specific knowledge (such as legal, medical, or technical fields). Finding annotators with the right expertise can be difficult and expensive.
- Annotation Guidelines and Standards: Developing clear, comprehensive annotation guidelines is crucial for consistency. These guidelines must be regularly updated and annotators adequately trained, which adds to the complexity and costs.
- Subjectivity in Interpretation: Different annotators may interpret the same text differently. Achieving consensus or a standardized interpretation can be challenging.
- Adaptation to Evolving Language: Language is dynamic and constantly evolving. Keeping the annotation process and guidelines up to date with new slang, terminologies, and language usage patterns is an ongoing challenge.
- Human Bias: Annotators, being human, bring their own perspectives and biases to the task. This can affect how the text is interpreted and labeled. For example, in sentiment analysis, what one annotator might label as a negative sentiment, another might view as neutral. This subjectivity can lead to inconsistencies in the dataset, which in turn can skew the NLP model’s learning and outputs.
- Consistency: Maintaining consistency in annotation across different annotators and over time is a significant challenge. Different interpretations of guidelines, varying levels of understanding, and even changes in annotators’ perceptions over time can lead to inconsistent labeling. Inconsistent annotations can confuse the NLP models, leading to poor performance.
- Data Security: Annotators often work with sensitive data, which might include personal information. Ensuring the security and privacy of this data is paramount. Data breaches can have serious consequences, not just for the individuals whose data is compromised, but also for the organizations handling the data. Annotators and their employers must adhere to strict data protection protocols, adding another layer of complexity to their work.
Get your solutions to text annotation challenges.
In Natural Language Processing (NLP), the method of text annotation plays a pivotal role in shaping the effectiveness of the technology. Understanding the different text annotation techniques is crucial for selecting the most appropriate method for a given project and address the regular challenges generally involved in them. Here are three primary annotation techniques: Manual, Automated, and Semi-Automated Annotation, each with its unique attributes and applications.
By leveraging these different annotation techniques, organizations and researchers can tailor their approach to suit the specific needs and constraints of their NLP projects, balancing factors like accuracy, speed, and cost-effectiveness.
Confused about what type of text annotation meets your project needs?
Text annotation in NLP is a systematic process in which raw text data is methodically labeled to identify specific linguistic elements, such as entities, sentiments, and syntactic structures. This process not only aids in the training of NLP models, but also significantly improves their ability to understand and process natural language. The stages in this process, from data collection to building an effective annotation team, are crucial for ensuring high-quality data annotation and, consequently, superior model performance in NLP applications.
This comprehensive table encapsulates the entire process of text annotation for NLP, providing a clear roadmap from the initial stages of data collection to the integration of annotated data with machine learning models.
The Human-in-the-Loop (HITL) approach significantly enhances AI-driven data annotation by integrating human expertise into the AI workflow, thereby ensuring greater accuracy and quality. This collaborative technique addresses the limitations of AI, enabling it to navigate complex data more effectively. Key benefits of the HITL approach in text annotation for NLP include:
- Improved Accuracy and Quality: Human experts are better at understanding ambiguous and complex data, allowing them to identify and correct errors that automated systems might overlook. This is particularly beneficial in scenarios involving rare data or languages with limited examples, where machine learning algorithms alone may struggle.
- Enhanced Contextual Understanding: Humans bring nuanced judgment and contextual knowledge to the annotation process, crucial for tasks requiring subjective interpretations, such as sentiment analysis. This human involvement ensures more precise and meaningful labeling of data.
- Edge Case Resolution: HITL is valuable in addressing challenging edge cases that require human judgment and reasoning, which are often difficult for AI to handle accurately. Human annotators can ensure that these rare or complex instances are correctly labeled, enhancing the reliability and performance of the AI models trained on this data.
- Continuous Improvement: The HITL approach facilitates an iterative feedback loop, where human annotators provide insights and feedback to improve automated systems. This collaboration leads to ongoing refinements in the accuracy and quality of annotations over time.
- Active Learning and Querying: HITL systems can use active learning techniques, where the model queries humans for annotations on uncertain or challenging examples, thereby focusing human effort on the most informative instances. This optimizes the annotation process and improves annotation accuracy while reducing overall effort.
- Quality Control: Human annotators adhere to specific quality control measures and guidelines, ensuring that annotations meet the desired standards. Techniques like involving a third-party annotator for consensus or employing consensus-building strategies among multiple annotators enhance the reliability and reduce the impact of individual biases .
HabileData leverages the HITL approach in text annotation and combines the strengths of human intelligence and AI capabilities, resulting in more reliable, accurate, and contextually nuanced NLP models. This synergy is pivotal in advancing the effectiveness of AI-driven data annotation, particularly in complex, ambiguous, or highly subjective annotation tasks.
Text annotation in NLP is essential for training AI to understand and process language in various industries, enhancing domain-specific applications:

Text annotation involves categorizing and labeling text data, which is crucial for training NLP models. Each type of annotation serves a specific purpose and finds unique applications in various industries.
Entity Annotation: This involves identifying and labeling specific entities in the text, such as names of people, organizations, locations, and more.
Use cases in NLP
- In healthcare, it’s used to extract key patient information from clinical documents, aiding in patient care and research.
- In legal contexts, it helps in identifying and organizing pertinent details like names, dates, and legal terms from vast documents.
- Useful for extracting company names and financial terms from business reports for market analysis.
Entity Linking: This process connects entities in the text to a larger knowledge base or other entities.
- In journalism, it enriches articles by linking people, places, and events to related information or historical databases.
- In financial analysis, it can link company names to their stock profiles or corporate histories.
Text Classification: This involves categorizing text into predefined groups or classes.
- In customer support, it’s used to sort customer inquiries into categories like complaints, queries, or requests, streamlining the response process.
- In content management, it helps in organizing and classifying articles, blogs, and other written content by topics or themes.
Sentiment Annotation: This type of annotation identifies and categorizes the sentiment expressed in a text segment as positive, negative, or neutral.
- In market research, it’s widely used to analyze customer feedback on products or services.
- In social media monitoring, it helps in gauging public sentiment towards events, brands, or personalities.
- In ecommerce, it is used to evaluate customer feedback to assess product satisfaction levels.
Linguistic Annotation: This adds information about the linguistic properties of the text, such as syntax (sentence structure) and semantics (meaning).
- In language learning applications, it provides detailed grammatical analysis to aid language comprehension.
- For text-to-speech systems, it helps in understanding the context for accurate pronunciation and intonation.
Part-of-Speech (POS) Tagging: This involves labeling each word with its corresponding part of speech, such as noun, verb, adjective, etc.
- In search engines, it assists in parsing queries to deliver more relevant results.
- In content creation, it aids in keyword optimization for SEO purposes.
- In transcription, it is used to enhance voice recognition systems by tagging words in speech transcripts for more accurate context understanding.
Document Classification: Similar to text classification, but on a broader scale, it categorizes entire documents.
- In legal tech, it assists in sorting various legal documents into categories such as ‘contracts’, ‘briefs’, or ‘judgments’ for easier retrieval and analysis.
- In academic research, it aids in organizing scholarly articles and papers by fields and topics.
Coreference Resolution: This identifies when different words or phrases refer to the same entity in a text.
- In news aggregation, it’s crucial for linking different mentions of the same person, place, or event across multiple articles.
- In literature analysis, it helps in tracking characters and themes throughout a narrative.
These examples showcase how text annotation empowers various NLP applications, enhancing their functionality and utility across different domains.
How HabileData nailed text annotation for a German construction company
A Germany-based construction technology company sought to enhance its in-house construction leads data platform for sharing comprehensive construction project data across USA and Europe. Their clientele ranged from small businesses to Fortune 500 companies in the real estate and construction sectors. The company used automated crawlers to gather real-time data on construction projects, which was auto-classified into segments like property type, project dates, location, size, cost, and phases.
However, for accuracy and to append missing information, they partnered with HabileData to verify, validate, and manually annotate 20% of the data that couldn’t be auto-classified.
The project involved comprehending and extracting relevant information from articles, tagging this information based on categories like project size and location, and managing large volumes of articles within a tight 24-hour timeline.
The HabileData team conducted an in-depth assessment of the client’s needs, received domain-specific training, and carried out a rigorous two-step quality check on the classified data. Over 10,000 construction-related articles were processed with effective text annotation techniques , significantly improving the accuracy of the AI algorithms used by the company. This collaboration led to enhanced AI model performance, a 50% cost reduction on the project, and a superior customer experience.
Other than understanding the HITL approach, it is crucial to also understand the tools and software that facilitate this process. Text annotation tools are specialized software designed to streamline the labeling of textual data for NLP applications.

Text annotation tools provide an interface for annotators to label data efficiently. These tools often support various annotation types, such as entity recognition, sentiment analysis, and part-of-speech tagging. They range from simple, user-friendly platforms to more advanced systems that offer automation and integration capabilities.
Popular text annotation tools
- Prodigy: A highly interactive and user-friendly tool, Prodigy allows for efficient manual annotation. It supports active learning and is particularly useful in iterative annotation processes.
- Labelbox: This tool is known for its ability to handle large datasets. Labelbox offers a combination of manual and semi-automated annotation features, making it suitable for projects of varying complexity.
- spaCy: spaCy is not just a text annotation tool, but a full-fledged NLP library. It provides functionalities for both annotation and building NLP models, suitable for projects requiring the integration of annotation and model training.
Choosing the right text annotation tool
Selecting an appropriate text annotation tool depends on several factors:
- Project Size and Complexity: For large-scale projects, tools like Labelbox that handle high volumes efficiently are preferable. For more complex annotation tasks, Prodigy with its active learning capabilities, may be more suitable.
- Annotation Type: Different tools excel in different types of annotations. It’s important to choose a tool that aligns well with the specific annotation needs of your project.
- Integration Needs: If integration with other NLP tools or model training is a requirement, spaCy could be an ideal choice.
- Budget and Resource Availability: Some tools are more cost-effective than others and require varying levels of expertise to operate effectively.
The choice of text annotation tools plays a critical role in the efficiency and effectiveness of the text annotation process in NLP projects. The selection should be tailored to the specific needs of the project, considering factors like project scope, annotation requirements, and available resources.
Recent advancements in NLP have introduced important trends, such as transfer learning, where a model trained for one task is repurposed for a related task, thus requiring less labeled data. The introduction of machine learning models like GPT and advancements in BERT and ELMo models have revolutionized the understanding of word context in NLP. Additionally, the emergence of low-code/no-code tools has democratized NLP, enabling non-technical users to perform tasks previously limited to data scientists.
As we look toward the future of text annotation in NLP, several key developments are poised to shape this evolving field:
- Advancements in AI-Powered Annotation Tools: Future annotation tools are expected to be more sophisticated, leveraging AI to a greater extent. This could include enhanced automation capabilities, better context understanding, and more efficient handling of large datasets.
- Enhanced Guidelines and Standards: There will probably be a push toward more standardized and universally accepted annotation guidelines, which will help in improving the consistency and quality of annotated data across different projects and domains.
- The Role of Synthetic Data in Annotation: Synthetic data generation is an emerging area that could revolutionize text annotation. By creating artificial yet realistic text data, it offers the potential to train NLP models in more diverse scenarios, reducing reliance on labor-intensive manual annotation.
These developments indicate a future in which text annotation becomes more efficient, accurate, and adaptable, significantly impacting the capabilities and applications of NLP technologies.
Text annotation plays a vital role in the field of Natural Language Processing (NLP), acting as the backbone for training and improving NLP models. From the initial stages of data collection and preparation to the detailed processes of annotation workflow, quality control, and integration with machine learning models, each step is crucial for ensuring the effectiveness and accuracy of NLP applications.
The future of text annotation, marked by advancements in AI-powered tools, enhanced guidelines, and the utilization of synthetic data, points toward a more efficient and sophisticated landscape. The key takeaway is that, as NLP continues to evolve, the importance of meticulous and advanced text annotation processes will become increasingly important, shaping the future capabilities of AI in understanding and processing human language.
Experience the power of precision in your text annotation projects.

About Author
Snehal Joshi heads the business process management vertical at HabileData , the company offering quality data processing services to companies worldwide. He has successfully built, deployed and managed more than 40 data processing management, research and analysis and image intelligence solutions in the last 20 years. Snehal leverages innovation, smart tooling and digitalization across functions and domains to empower organizations to unlock the potential of their business data.
Related Articles

10 Best Data Cleansing Companies in 2024

5 Images Annotation Types Explained with Common Use Cases

- Privacy Policy
Copyright © 2024 HabileData. All Rights Reserved.
Email: [email protected] Phone: +91-794-000-3251
Disclaimer:
HitechDigital Solutions LLP and HabileData will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at [email protected]
Narrative Essay
How to write an annotation.
One of the greatest challenges students face is adjusting to college reading expectations. Unlike high school, students in college are expected to read more “academic” type of materials in less time and usually recall the information as soon as the next class.
The problem is many students spend hours reading and have no idea what they just read. Their eyes are moving across the page, but their mind is somewhere else. The end result is wasted time, energy, and frustration…and having to read the text again.
Although students are taught how to read at an early age, many are not taught how to actively engage with written text or other media. Annotation is a tool to help you learn how to actively engage with a text or other media.
View the following video about how to annotate a text.
Annotating a text or other media (e.g. a video, image, etc.) is as much about you as it is the text you are annotating. What are YOUR responses to the author’s writing, claims and ideas? What are YOU thinking as you consider the work? Ask questions, challenge, think!
When we annotate an author’s work, our minds should encounter the mind of the author, openly and freely. If you met the author at a party, what would you like to tell to them; what would you like to ask them? What do you think they would say in response to your comments? You can be critical of the text, but you do not have to be. If you are annotating properly, you often begin to get ideas that have little or even nothing to do with the topic you are annotating. That’s fine: it’s all about generating insights and ideas of your own. Any good insight is worth keeping because it may make for a good essay or research paper later on.
The Secret is in the Pen
One of the ways proficient readers read is with a pen in hand. They know their purpose is to keep their attention on the material by:
- Predicting what the material will be about
- Questioning the material to further understanding
- Determining what’s important
- Identifying key vocabulary
- Summarizing the material in their own words, and
- Monitoring their comprehension (understanding) during and after engaging with the material
The same applies for mindfully viewing a film, video, image or other media.
Annotating a Text
Review the video, “How to Annotate a Text.” Pay attention to both how to make annotations and what types of thoughts and ideas may be part of your annotations as you actively read a written text.
Example Assignment Format: Annotating a Written Text
For the annotation of reading assignments in this class, you will cite and comment on a minimum of FIVE (5) phrases, sentences or passages from notes you take on the selected readings.
Here is an example format for an assignment to annotate a written text:
Example Assignment Format: Annotating Media
In addition to annotating written text, at times you will have assignments to annotate media (e.g., videos, images or other media). For the annotation of media assignments in this class, you will cite and comment on a minimum of THREE (3) statements, facts, examples, research or any combination of those from the notes you take about selected media.
Here is an example format for an assignment to annotate media:
- Provided by : Lumen Learning. Located at : http://www.lumenlearning.com/ . License : CC BY: Attribution
- Authored by : Paul Powell . Provided by : Central Community College. Project : Kaleidoscope Open Course Initiative. License : CC BY: Attribution
- Authored by : Elisabeth Ellington and Ronda Dorsey Neugebauer . Provided by : Chadron State College. Project : Kaleidoscope Open Course Initiative. License : CC BY: Attribution
- Annotating a Text. Authored by : HaynesEnglish. Located at : http://youtu.be/pf9CTJj9dCM . License : All Rights Reserved . License Terms : Standard YouTube license
- How to Annotate a Text. Authored by : Kthiebau90. Located at : http://youtu.be/IzrWOj0gWHU . License : All Rights Reserved . License Terms : Standard YouTube License
Text Annotation: What is it & why is it important in 2024?
ML models and their subset Natural Language Processing ( NLP ) offer crucial advantages to companies in various industries. They help in analyzing text data, accelerating customer responses via chatbots , recognizing human emotions thanks to sentiment analysis, etc. The success of speech-related applications depends on correctly annotated text data.
What is text annotation?
Supervised ML models need data labeling to work effectively. Text annotation is a subset of data annotation where the annotation process focuses only on text data such as PDFs, DOCs, ODTs etc.
Text annotation requires manual work. Data scientists determine the labels or “tags” and passes the text-specific information to the NLP model being trained. This process can be thought of as a child’s language learning process. Under the guidance of the parents who determine the labels, the child first learns the meaning of the words and then distinguishes the satire, metaphor, allusion, and emotion behind the sentence.
Why is text annotation important now?
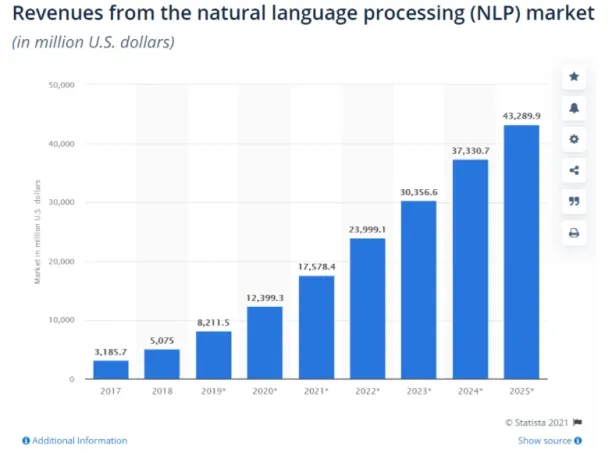
Statista shows that the global NLP market generated turnovers of over $12 billion in 2020, and it is predicted that the market will grow at a compound annual growth rate (CAGR) of about 25% from 2021 to 2025, reaching revenues of over $43 billion. Since text annotation is the fundamental process in developing an NLP, it is reasonable to consider text annotation as an important phenomenon.
In addition, customers demand digitized and fast customer services, and the Covid-19 pandemic has increased this demand. Consequently, chatbots have become an integral part of customer service. No company would want to serve its customers with a weakly trained NLP algorithm that is not able to distinguish a simple metaphor.
What are the techniques for text annotation?
There are four main techniques of text annotation, namely:
Named entity recognition
Entity linking, sentiment annotation, intent annotation.
Named entity recognition labels the words in the text with predefined categories such as date, name, location, etc. It is useful for machines to understand the topic of the text as AI learns keywords thanks to this labeling method. Therefore, named entity recognition is often used in the development of chatbots.

While entity annotation is about marking specific entities in a text, entity linking is about linking those entities to larger data sets such as Wikipedia links.
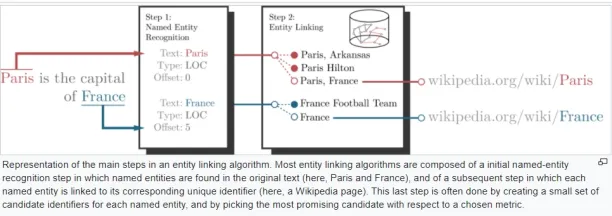
Sentiment annotation is the tagging of emotions and opinions contained in a text. Annotators choose which tag best represents the emotion of the document.
Understanding human emotions is crucial for companies to evaluate their position in the market. Sentiment annotation helps companies to improve customer satisfaction. Customer review analysis is an example of sentiment annotation, where data labelers read reviews and determine whether they are positive, neutral, or negative.
Here are the top sentiment analysis services on that market.
For effective chatbots in customer service, it is crucial to understand the reason for the conversation. Is the customer asking for something, reporting an unpleasant experience, waiting for a response or confirmation, etc.? Data analysts classify texts into different categories, such as request, command, or confirmation to train chatbots.
How to annotate text data?
Companies need software that specializes in text annotation to apply the text annotation techniques. It is possible to outsource the process to vendors that offer open-source and closed-source text annotation tools.
Open-source text annotation tools are free, and since the code is open to anyone, it can be modified to meet your organization’s needs. Closed-source tools, on the other hand, have a team to help you set up and use the software for your business. However they charge a fee for such a service.
Developing your own software for text annotation could be an alternative to outsourcing. However, this is a costly and slow process. The main advantage is that in-house tools provide greater data security.
In-housing vs outsourcing vs crowdsourcing
In-housing, outsourcing and crowdsourcing are ways to perform the manual work of text annotation. They are associated with different costs, output quality and data security. Therefore, it is an important strategic decision for companies which method to use.
Of course, the optimal strategy will vary from organization to organization, as the conditions and needs of organizations are different. Nevertheless, the following table might be helpful for you to choose the optimal strategy. For more, you can check our article on outsourcing data labeling .
Don’t forget to check our sortable/filterable list of data labeling/annotation/classification vendors list. You can also check our open-source data labeling platforms list.
You might also want to see our image and audio annotation articles to learn more about data labeling. If needed, we can introduce you to some of the best text annotation companies:

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month. Cem's work has been cited by leading global publications including Business Insider , Forbes, Washington Post , global firms like Deloitte , HPE, NGOs like World Economic Forum and supranational organizations like European Commission . You can see more reputable companies and media that referenced AIMultiple. Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization. He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider . Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Next to Read
Data labeling for natural language processing (nlp) in 2024, top 10 open source data labeling/annotation platforms in 2024, data annotation in 2024: why it matters & top 8 best practices.
Your email address will not be published. All fields are required.
Related research

Human Annotated Data: Benefits & Recommendations in 2024

Quick Guide to Video Annotation Tools and Types in 2024
Understanding Annotation: A Comprehensive Guide
What is annotation, the purpose of annotation, types of annotation, how to annotate effectively, annotation tools, annotation examples, annotation in different disciplines, annotation vs. abstract, annotation in digital learning, the future of annotation.
Let's take a journey into the world of annotation, a concept that often makes students cringe and researchers sigh. But, don't worry — this guide will help you understand annotation in a simple, friendly, and clear way. Whether you're a newbie or someone who just needs a refresher, this comprehensive guide will provide a clear definition of annotation and its many uses.
So, what exactly is the definition of annotation? In its simplest form, annotation refers to adding notes or comments to a text or a diagram. It's like having a personal conversation with the author, or making sense of a complex graph. It doesn't stop there, though. The process of annotation is much more than just dropping notes — it's about understanding, interpreting, and engaging with the material. Let's break it down:
- Understanding: Annotations help you to grasp the ideas and concepts presented in the text or diagram. You might underline key phrases or highlight important data points, all in the service of better understanding what you're reading or viewing.
- Interpreting: By providing your own insights or explanations, you're not merely reading or looking at the material, but actively interpreting it. This could be as simple as jotting down "This means..." or "The author is saying..." next to a paragraph.
- Engaging: When you annotate, you're not just a passive reader anymore. You're actively engaging with the material, questioning it, agreeing or disagreeing, even arguing with the author! This active engagement helps to deepen your understanding and retention of the material.
To sum it up, the definition of annotation isn't just about making notes — it's a method to read, understand, interpret, and engage with any piece of content more effectively. And guess what? There's more to annotation than you might think! Stick around as we delve deeper into the purpose, types, and tools of annotation in the following sections.
Now that we've nailed down the definition of annotation, let's talk about why it's so important. Why do teachers, professors, and researchers keep insisting on it? Well, there are several reasons:
- Improves comprehension: Annotating helps you understand the text or diagram better. It's like having a personal guide walking you through a dense forest of words or a complex maze of data. By highlighting and commenting, you can make sense of the material more easily.
- Enhances retention: We've all been there. You read a page, flip it, and — poof! — everything's gone. But with annotation, you can remember more. When you actively engage with the material, you're more likely to remember it. It's like the difference between watching a movie and participating in it.
- Facilitates analysis: Annotation is not just about understanding, but also about analyzing. By adding your own thoughts, insights, and interpretations, you can dig deeper into the material, uncovering layers of meaning that might not be immediately apparent.
- Promotes critical thinking: When you annotate, you're not just accepting information passively — you're actively questioning, evaluating, and critiquing it. This cultivates critical thinking skills, which are crucial in today's information-saturated world.
Remember, the purpose of annotation is not to make your book look like a rainbow or to fill the margins with a clutter of notes. It's about making the material work for you, helping you to understand, remember, analyze, and think critically. So next time someone mentions annotation, don't cringe. Embrace it. It's your secret weapon in the world of learning!
Now that we've got a grip on the definition of annotation and its purpose, it's time to dive into the different types of annotation. You might be thinking, "Wait a minute, there's more than one type?" Yes, indeed! And picking the right one can make a world of difference. So, let's explore:
- Descriptive Annotation: This kind of annotation is like a sneak peek of a movie. It gives an overview of the main points, themes, or arguments without revealing too much. It's like a book cover — enticing enough to draw you in, but not revealing all the secrets.
- Critical Annotation: This type goes a step further. It not only describes the content but also evaluates it. It's like a movie review, discussing the strengths and weaknesses, the relevance of the content, and the author's credibility. It helps you decide whether the material is worth your time.
- Informative Annotation: This annotation is like an all-you-can-eat buffet. It provides a summary of the material, including all the significant findings and conclusions. It's ideal when you need a detailed understanding of the content without having to read the whole thing.
- Reflective Annotation: This type of annotation is a bit more personal. It includes your thoughts, reactions, and reflections on the material. It's like a diary entry, capturing your intellectual journey as you engage with the material.
So, next time you're tasked with annotating, consider the type of annotation that best suits your needs. Remember, the goal is not to make your work harder, but to make it easier and more effective. Happy annotating!
Here you are, equipped with the definition of annotation and an overview of its types. But, how do you do it effectively? Let's break it down:
- Get clear on your purpose: Why are you annotating? Is it to understand better, remember, or critique? Your purpose will guide your annotation process.
- Take a quick preview: Before you start annotating, skim through the material. Get a feel for its structure and main ideas. This way, you'll know what to pay special attention to.
- Be selective: Resist the urge to highlight or underline everything. Limit your annotations to crucial points, unfamiliar concepts, and interesting ideas. The goal is to create signposts that can guide you back to key information when needed.
- Make it meaningful: Don’t just underline or highlight. Write brief notes that summarize, question, or react to the content. This makes your annotations a tool for active learning.
- Use symbols or codes: Develop your own system of symbols or codes to denote different types of information. For example, a question mark could indicate parts you don’t understand, while an exclamation mark could point to surprising or important insights.
Remember, effective annotation is not about how much you mark, but about how well you understand and engage with the material. Keep practicing and refining your approach, and soon you'll become an annotation pro!
So, now that we know how to annotate effectively, let's talk about some tools that can make this process even smoother. These are especially handy if you're dealing with digital content, or if you want to share your annotations with others. Here are some noteworthy ones:
- Pencil and Paper: Sometimes, the old ways are the best ways. Nothing beats the flexibility and simplicity of annotating with a good old-fashioned pencil. You can underline, highlight, make notes in the margin — the possibilities are endless!
- Highlighters: These are great for emphasizing key points in your text. Just remember not to go overboard and turn your page into a rainbow!
- Post-it Notes: If you don't want to write directly on your material, or if you need more space for your thoughts, these little sticky notes can be a lifesaver.
- PDF Annotation Tools: If you're working with digital documents, tools like Adobe Reader, Preview, and others offer built-in annotation features. These can include highlighting, underlining, and adding comments.
- Online Annotation Tools: Websites like Hypothesis and Genius let you annotate web pages and share your annotations with others. They're like social media for readers!
These tools are just the tip of the iceberg. There are many other annotation tools out there, each with its own strengths and weaknesses. So, don't be afraid to experiment and find the ones that work best for you!
Let's put the definition of annotation into real-world scenarios. Here are some examples to help you get a better sense of how annotation works.
- Novels: You're reading a gripping mystery novel and you come across a clue. You underline it and jot down your theories in the margin. That's annotation!
- Textbooks: Remember the last time you studied for an exam? You probably highlighted important information and made notes to help you remember key points. That's annotation too!
- Articles: When reading a long article online, you might use a tool to underline key sections and add your own thoughts. This not only helps you understand the content better but also lets you share your insights with others. Yep, that's annotation.
- Research Papers: If you're conducting research, annotation is your best friend. Underlining important data, writing summaries of complex sections, and noting down your ideas can make the whole process much easier.
- Social Media: Ever added a funny caption to a photo before sharing it with your friends? Guess what? That's annotation too!
As you can see, annotations can be as simple or as complex as you need them to be. They're all about adding extra information to make the original content more useful or meaningful for you. So, next time you're reading something, why not give annotation a try? Who knows, you might discover some fascinating insights!
Now that we've nailed down the definition of annotation, let's see how it's applied across different disciplines. You might be surprised to know that annotation isn't just for the world of literature or academia. Here's how different fields use annotation:
- Sciences: Scientists use annotations to note down observations during experiments. They can also annotate diagrams to explain complex processes.
- Arts: Artists often annotate their sketches with notes about colors, textures, or ideas for future works. Art historians may also use annotations to provide deeper insight into famous paintings or sculptures.
- Computer Science: In the world of coding, annotations can provide extra details about how a piece of code functions. They're like a roadmap for other programmers who might need to understand or modify the code later.
- Geography: Geographers use annotations on maps to highlight specific features or explain certain phenomena. For example, they might annotate a map to show the path of a storm or the spread of a forest fire.
- Business: Business professionals annotate reports and presentations to highlight key points. This helps everyone stay on the same page and understand the main takeaways.
As you can see, no matter the discipline, the power of annotation is universal. It's all about enhancing understanding and fostering communication! So, the next time you're working on a project, why not consider how annotation could help you?
Dealing with academic or professional texts, you've probably come across both annotations and abstracts. But do you know the difference? Many people get confused between the two, but they serve unique roles. Let's clear the air by exploring the definition of annotation versus an abstract:
Annotation: An annotation adds extra information to a text. It could be a comment, explanation, or even a question. Imagine you're reading a complex scientific paper. You might annotate it by jotting down a simpler explanation of a concept in the margins. That's annotation—helping to make the text more accessible and understandable for you.
Abstract: On the other hand, an abstract is a short summary of a document's main points. Think of it as a mini version of the text. If you've ever written a research paper, you've probably had to include an abstract at the beginning. It gives readers a snapshot of what the document covers so they can decide if they want to read the whole thing.
So, in a nutshell, an annotation is more about adding value to the text, while an abstract is about summarizing it. Both have their places and can be super helpful when dealing with complex or lengthy texts. Understanding the difference between the two is another step in mastering the art of reading and writing effectively.
Now, let's shift gears and explore how annotation plays a role in the digital learning space. With the advent of technology, education isn't limited to chalkboards and textbooks anymore. We've moved onto laptops, tablets, and even mobile phones. So, where does the definition of annotation fit in this digital world?
In digital learning, annotation takes on a slightly different form. Instead of scribbling in the margins of a book, you're adding notes to a PDF, highlighting text in an eBook, or leaving comments on a shared document.
Let's say you're studying for a history exam with a friend, and you're both using the same digital textbook. You come across a paragraph that you think is particularly important, so you highlight it and leave a note saying, "Must remember for the exam!" When your friend opens the book on their device, they can see your annotation and benefit from it. This is the power of annotation in digital learning—it promotes collaboration and makes studying a more interactive experience.
And it's not just for students, either. Teachers can use digital annotation to provide feedback on assignments, clarify points in a lecture, or share additional resources. In a world where online learning is becoming the norm, understanding and using digital annotation is a skill worth mastering.
Having explored the definition of annotation in various contexts, it's exciting to imagine where it might head in the future. As we continue to integrate technology into our lives, the role and methods of annotation are likely to evolve with it.
Imagine a world where every bit of text you interact with—be it a digital book, an online article, or even a social media post—can be annotated with your thoughts, questions, or insights. And not just that, imagine those annotations being instantly shareable with anyone around the globe. We're already seeing glimpses of this in digital learning platforms, as we previously discussed.
Moreover, the rise of artificial intelligence might add another layer to annotation. Imagine AI systems that can automatically highlight important parts of a text, suggest resources for further reading, or even generate annotations based on your personal learning style. Now that's a future worth looking forward to!
While we are not there yet, the journey towards that future is already underway. And as we make strides in this direction, the definition of annotation will continue to expand and adapt. It's a fascinating field that underscores the importance of understanding, interpreting, and communicating information in our increasingly interconnected world.
If you're looking to improve your annotation skills and learn more about organizing your creative projects, check out Ansh Mehra's workshop, ' Documentation for Creative People on Notion .' This workshop will provide you with practical tips and techniques for effective annotation, as well as help you develop a comprehensive documentation system for your creative work.

Live classes every day
Learn from industry-leading creators
Get useful feedback from experts and peers
Best deal of the year
* billed annually after the trial ends.
*Billed monthly after the trial ends.
- Productivity
- Thoughtful learning
How to annotate: 5 strategies for success

Have you ever written inside of a book?
It can feel a little mischievous to write on the pages of a book, as if we're breaking some rule. As children, we were taught not to write in our school books or library books, so annotations seemed taboo.
But what if writing in a book was not only OK but also encouraged?
Annotation is a practical and valuable way to engage with text, whether it’s a novel, textbook, or article. When done correctly, annotation can help you engage with the text, identify key points and themes, and even improve your comprehension.
In this article, we'll discuss what it means to annotate and how it can benefit your learning and comprehension. Get ready to learn how to annotate effectively with this five-step guide.
What is annotation?

Annotating is the act of adding notes, comments, or highlighting to a text as we read through it. These notes can be about anything — our thoughts, reactions, questions — and they can be written in any way we want, from symbols to complete sentences. This form of note-taking can help us remember key information in any text, whether it's a textbook for school or a novel we enjoy.
Although writing inside books has generally been discouraged and frowned upon in recent decades, the practice of annotation dates back centuries. The word “annote” from Latin “ad” meaning "to" + “notare” meaning "to mark or note," was first recorded in the mid-15th century.
Annotation has traditionally been used for scholars, researchers, and students to engage with texts. But it's also widely used by many others, from business professionals to authors like Mark Twain. His humorous marginalia is now collected and exhibited in libraries.
There are many ways to annotate a document, from underlining and highlighting to writing notes in the margins. Regardless of their form, annotations serve the same purpose — to help us better engage with and understand the text.
Why annotate?

Annotating is an active reading strategy that facilitates the critical understanding of information in a text. As we note our thoughts and reflections, we can better engage with the material, identify main points and themes, and even improve our comprehension.
There are many benefits to annotating, whether we're reading for school or pleasure. Among the most significant are the following:
- Encourages active reading. Annotation helps us move beyond passive reading and enables us to engage more with the text. Those who skim or scan when reading can benefit significantly, as it's easier to stay engaged and pay attention when we use annotation and focus on note-taking .
- It helps the brain process information. Annotating means actively engaging with the text as we read through it. As a result, we can immerse ourselves in learning and engage our information processing system . The brain can encode and store information more effectively for long-term storage by processing information.
- Annotating helps identify key points. As part of the annotation process, we perform an initial skim, highlighting or underlining the most important information and main points. This allows us to quickly identify and review key points later when we re-read, which is especially helpful when reading a long or complicated text.
- A well-annotated text improves comprehension. When we thoroughly process and engage with the text, annotation can enhance our comprehension. In addition, social annotation, the practice of sharing and discussing annotations with others, can also increase understanding. Research has found that reading peer annotations helped students confirm their ideas, examine different viewpoints, and better understand course content.
- It sparks creativity and critical thinking. As we annotate, we have to think about what we're reading and how it relates to what we already know. This process can help us see the text in new ways and use annotations to make connections we may not have otherwise made. This can lead to more creative and critical thinking about the content.
- Annotation encourages further exploration. As we read, we may have questions about the text. Taking notes opens a dialogue with the text and encourages further learning. Research shows that annotation can lead to increased engagement and thus increased performance. In one study, student engagement and performance on equation- or procedural-based questions improved when instructors and students shared homework annotations on tablets .

Boost your productivity with ABLE
Highlight, annotate or take notes from anywhere, and it's easily linked to a selected topic in your Knowledge Base.
How to annotate in 5 easy steps

Knowing how to annotate is a valuable skill for anyone, whether you're a student, professional, or lifelong self-learner. If you'd like to use annotation to discover and recall key information from your reading, here are a handful of steps to get started.
1. Choose your annotation tools
The first step is to choose your annotation tools. The tools that you choose will depend on the format of your text. If you’re annotating the pages of a book or printed text on a piece of paper, you will need different tools than if you’re annotating an electronic document on a computer or tablet.
Some standard annotation tools for paper texts include:
- Pens and pencils
- Highlighters in different colors
- Sticky notes, tabs, or Post-it Notes
If you're using a physical book, choose materials that won't damage the pages. This means avoiding pens and markers with bleed-through ink and opting for pencils instead. Highlighters are also a good option, as long as they don't bleed through the pages.
For electronic texts, you can use digital versions of many of the same tools as you would for paper texts. However, some annotation-specific tools may come in handy. These include:
- A digital pen or stylus
- Note-taking software or apps like Evernote or Diigo
- A bookmarking tool like Pocket
- A tool that incorporates a native annotation process and records it automatically into your knowledge base, like ABLE .
If you're reading on a Kindle or other e-reader, you may be limited in the tools you can use. Check your device's documentation to see what options are available. No matter what format you're using, choosing tools you're comfortable with is key. This will make annotation more enjoyable and effective.
2. Select an annotation strategy
Now that you've selected tools, it's time to choose an annotation strategy. There are many ways to annotate, so experiment to find what works best for you. There are several common annotation strategies to try:
- Descriptive: This strategy aims to summarize the most important points of the text. Briefly paraphrase the main points and state the essential information in your annotations. The exact format is flexible to your preferences. For example, you may link topics with their chapter titles or page numbers to make it easier to reference them, or write a brief summary of each section.
- Evaluative: This version of annotation encourages critical thinking . In addition to summarizing the text, you'll analyze the work using this method. Evaluate the author's qualifications, the accuracy of the information, and any blatant bias in the text. In addition, you should also assess the research source's relevance to your overall research purpose and how it compares with others on your topic.
- Informative: This method is similar to evaluation but focuses on the author's point of view rather than your own. In your summary of the source, you will take a neutral stance rather than express personal feelings about its relevance or quality. Provide only the facts the author provides, noting their main points, arguments, proof, and conclusions.
- Combination: This is the most common form of annotation that uses a combination of two or more of the systems above. You can choose which elements of the other methods are most beneficial for your purposes. Take note of anything in the text that is new to you, such as unfamiliar words, concepts, places, or people. You could also highlight key information that confirms ideas or fills gaps in your understanding.
Once you choose a strategy that fits your reading intent, you're ready to start annotating.
3. Scan the text
Armed with your tools and strategy, you're ready to annotate For your first read, you will simply scan the text. During this initial read-through, there are a few key things to look for:
- Title, headings, and subheadings. These will help you identify the topic and main ideas you'll focus on when you complete a close read.
- Author or publisher attribution. This is the first step in analyzing the research source and evaluating reliability.
- The abstract, and words and phrases in bold or italics. Further clues about the intended audience and purpose of the text can be revealed in these details.
As you scan, note anything that confuses you or doesn't make sense. When you do a close reading, you'll want to pay attention to these areas.
4. Skim for major ideas

After a quick scan of the text, it's time for a closer look. Read the text again, focusing on the bigger picture to identify the author's main points. This step doesn't include close reading of the text, but you'll want to take a little more time and skim the text more closely than in your initial scan.
During this read-through, your goal is to discover the thesis or central argument of the text. Take some time to note the format of the text, how the information is structured, and how the author supports their claims. Underline or highlight the major ideas of each section as you skim. Lastly, paraphrase the article in your own words near the header or at the end of the text.
5. Complete a close read
Once you understand the main points, you're ready to do a close reading. This is where you'll finally slow down, focus on the details, and do some note-taking.
Start at the beginning and slowly re-read the text. Keep your annotation strategy in mind as you read. Knowing whether you want to take a descriptive approach, use the evaluative method, or try another strategy will help you look for the areas you should annotate.
Whichever strategy you use, there are a few helpful things to keep in mind:
- Be consistent with how you mark the text. Pick one color and use it throughout the text, or assign specific colors to specific points. For instance, yellow for key points, green for supporting information, red for questions, etc. Being consistent will ensure you can understand your annotations when you review them later.
- Include a key or legend. If you use symbols — stars, arrows, question marks, or underlining — in your note-taking, it's helpful to create a key. It can be a simple list or chart; just explain what each marking means. For example, a star could mean further research is required while an underline indicates an important point. A key will help you (or any peers reading your annotations) identify and access relevant content.
- Don't be afraid to use marginalia. If something confuses you, make a note of it. If you disagree with the author, jot down why. The insights found in marginalia are helpful in many ways, whether they encourage you to further research or offer your peers a different perspective.
- Avoid over- or under-annotating. It can be tempting to highlight everything as you read, but this isn't helpful and can make it challenging to identify the most important information. Similarly, if you don't annotate enough, you might miss important details. Try to find a happy medium so you're not overwhelmed when reviewing your annotations later.
Adding annotations to a text is an individual process, so there’s no right or wrong way. However, you can use these tips to maximize your annotations and ensure they're helpful.
Enhance your learning with effective annotation
Whether reading for leisure or learning, knowing how to annotate can benefit your experience. Using annotations effectively improves your understanding of a text and enhances your memory and comprehension. Annotating allows you to take a more active role in your self-learning so you're not just passively reading but critically engaging with the material.
If you're new to annotation, start small. Pick one article or chapter and experiment with different annotation strategies. As you become more comfortable, you can try different approaches and find the one(s) that work best for you. With time and practice, annotating will become second nature — and you'll be able to reap all the benefits of this powerful learning tool.
ABLE - the next-level all-in-one knowledge acquisition and productivity tool
I hope you have enjoyed reading this article. Feel free to share, recommend and connect 🙏
Connect with me on Twitter 👉 https://twitter.com/iamborisv
And follow Able's journey on Twitter: https://twitter.com/meet_able
And subscribe to our newsletter to read more valuable articles before it gets published on our blog.
Now we're building a Discord community of like-minded people, and we would be honoured and delighted to see you there.

Erin E. Rupp
Read more posts by this author
Task batching: 5 steps to become more productive in less time
Information processing model: understanding our mental mechanisms.

What is abstract thinking? 10 activities to improve your abstract thinking skills

5 examples of cognitive learning theory (and how you can use them)
0 results found.
- Aegis Alpha SA
- We build in public
Building with passion in
The SunTec AI Blog
A beginner’s guide to text annotation.
- Post author By Admin
- Post date May 6, 2022

Like humans, machines also need to learn, understand and analyze things to produce desirable outcomes. One of the most efficient ways to make machines learn is using text annotation services. With advancements in time and technology, machines have leveled up their ability to understand human language.
Therefore, the text annotation technique is used widely to train machines and help them communicate with humans efficiently. High-quality datasets created by annotators using the text annotation process have given a big push to the machine learning and AI models.
In this blog post, we will learn everything about text annotation and its various types.
What Is Text Annotation & How Is It Used in AI Training?
Text annotation is labeling the text, phrases, and sentences using additional metadata to make the machines learn about objects and things. Depending upon the project requirements and complexity, data sets are created by labeling the important parts of a speech, syntax, sentence, etc. After the required text is annotated, the datasets are used in AI training to make machines learn the diversity of the human language to communicate with humans effectively.
To provide efficient training to the machines you need high-quality data sets as poorly annotated text can make your machines dumb and less responsive. Therefore, it is wise to let professionals annotate the text as it requires experience and expertise. To annotate text professionally and achieve high-quality datasets, outsource the work to text annotation services providers.
Are you looking for experts who perform text annotation to produce high-quality datasets?
Click Here!
Types of Text Annotation Techniques

Large annotated text datasets are required to train NLP algorithms depending on the project requirements. Therefore, human annotators use various types of text annotation machine learning to create datasets for AI training. In this section, we will discuss each of them.
1. Sentiment Annotation
Machines can not understand emotions and sentiments like humans can. But at times, humans also find it hard to understand the sentiments behind a phrase or a conversation. Therefore, sentiment annotation is used to train the machines and help them understand texts that have sentiments. Sentiment annotation is a type in which sentiments, opinions, and emotions hidden within the text are labeled. At first, the annotators analyze the required text to understand the sentiments and later select the best label for them to make the machines understand the emotions easily.
A real-time example of sentiment annotation can be analyzing and labeling the customer feedback to help the machines understand the intent behind them and respond accordingly. Machines trained using accurate data sets can become part of the sentiment analysis model to track correct public opinion about a product or a service.
2. Entity Annotation
Entity annotation is used to generate training datasets for the machines by analyzing, locating, and tagging multiple entities present inside the text. Using entity annotation, the annotators can make the machines learn to identify entities in different parts of the text and the speech. Annotators go through the text thoroughly and gather all the entities in the text. After that annotators highlight the entities and provide a suitable tag for them to create the required datasets.
There are three types of entity annotation, which are provided below:
- Keyphrase Tagging – In this type of entity annotation, annotators analyze, locate and label the keywords in the given text.
- Named Entity Recognition – NER is another type of entity annotation in which annotators first locate the names of people, objects, and places in the text and then label them accordingly.
- Parts Of Speech Annotation – In this type of annotation, the annotators locate various parts of the speech in a given phrase including, adjectives, nouns, punctuations, verbs, prepositions, etc.
3. Intent Annotation
Intent annotation is one of the most important types of text annotation techniques used to create high-quality datasets for machine learning and AI-based training. Using intent annotation, the annotators create datasets that help the machines determine the intention of the users behind creating the text. The text can be created as a command, request, or confirmation, and intent annotation helps machines differentiate the different categories of the text. For eg: While communicating with automated chatbots, customers write sentences in different sentences. Customers can either request, confirm, or give a command to the chatbots. Therefore datasets created by intent annotation help machines understand the nature and intent of different types of conversations.
4. Text Classification
Text classification is also called text categorization or document classification. With text classification, the annotators read the sentences, phrases, and paragraphs and understand the intentions and sentiments for which they were created. After the annotators determine the intentions and sentiments behind the text, they classify the text into different predefined categories depending upon the type. It is quite similar to categorizing different types of products in an eStore. Text classification may sound a lot similar to Entity annotation, but it is different. In Entity annotation, annotators provide different labels to individual sentences or phrases, while in text classification an entire paragraph or sentence is annotated using a single label.
5. Linguistic Annotation
Linguistic annotation, popularly known as corpus annotation, is used for labeling the language data present within the text or the audio recordings. While using linguistic annotation, annotators identify phonetic, grammatical, and semantic elements in the text or audio data and label them to create the required datasets to train the machines.
Usually, there are four types of linguistic annotation, which are as followed:
- Phonetic annotation: In this type of annotation, the annotator label pauses, stress, and intonation that are part of the speech.
- Part-of-speech (POS) tagging: In POS, the experts annotate different function words that are present inside the text.
- Semantic annotation: In semantic annotation, the professionals annotate word definitions.
- Discourse annotation: In discourse annotation, the experts link anaphors and cataphors to their antecedent or postcedent subjects and create the required datasets.
Using linguistic annotation, annotators create datasets for various AI training modules including search engines, chatbots, virtual machines, etc. Such datasets help the machine learning modules to understand the language data and generate correct responses.
How To Annotate Text?
You can annotate the text by taking help from professional human annotators that know how to label text data. Human annotators hold expertise in analyzing and tagging different parts of the text like sentiments, intentions, and others. Nowadays, human annotators have started using automated tools to speed up the text annotation process and create the required data sets quickly. The automated tools help the annotators automatically label different parts of the speech or the phrase. Annotators can then view the labeled data and accept or edit the suggestions as required.
In this blog post, we discussed how text annotation is used to train machines and what are the different types of text annotation used to create high-quality data sets. If you do not have the correct tools to annotate the required text, you will not be able to achieve the desired results. Therefore it is recommended to ask professionals to help you by providing text annotation services. Text annotation experts like SunTec.AI can help you achieve high-quality datasets to train your machine learning models. We use all types of text annotations from Sentiment to Relationship annotation to annotate the required text and provide you out-of-the-box experience. To know more about us you can visit our website www.suntec.ai today.
Do you want to annotate your text and get high-quality datasets for your machine learning model?
1. how can you effectively annotate text.
There are numerous tips and tricks to follow to annotate your text effectively. A few of these tips are listed below:
- First, analyze the text thoroughly and then try to summarize the text in your own words using bullets.
- Now, you can highlight the important phrases and the key concepts in your text.
- To annotate, start writing questions and comments in the margins.
- To keep the datasets crisp, label the text using symbols and abbreviations.
- After you have completed annotating the text, re-check if you have left any important phrase or sentence that needs to be annotated.
2. What is the purpose behind annotating text?
The main motive to annotate text is to make learning easy for the machines. Annotating text favors the ability of the machines to read, understand and learn things quickly. It also makes machines understand human language and communicate with them effectively. With text annotation, there are fewer chances that machines will make mistakes in providing resolutions to the customers and answering their queries.
3. What are the benefits of text annotation?
Text annotation has an array of benefits in various sectors and a few of them are listed below:
- Helps in gathering the idea behind creating the text.
- Helps in elaborating the hidden thoughts in the text which favors deep understanding and quick learning.
- Helps the readers in analyzing and interpreting the text without putting effort.
- Helps the readers to make conclusions about the text.
4. Can we automate text annotation?
Yes, the tools that annotators use for text annotation support automation. With automation functionality, the text annotation tools label the required text automatically using artificial intelligence. After the text is automatically labeled, the annotators can either confirm or edit the label suggestions. Auto labeling saves time for annotators and using automated tools, they can perform text annotation quickly.
5. What resources do you need for text annotation?
For annotating text, you need a team of professional annotators as the primary resource. Annotators are required to process your data, create datasets and build models as per the requirement. Besides the experts, you will require annotation tools that will help the annotators to perform efficient text annotation.
- Tags text annotation machine learning , Text Annotation Services , what is text annotation
What is Text Annotation in Machine Learning?

Everything You Need to Know About Text Annotation with Yao Xu
Every day, we interact with different media (such as text, audio, images, and video), relying on our brain to process what media we are seeing and make meaning out of it to influence what we do. One of the most common types of media is text, which makes up the languages we use to communicate. Because it is so commonly used, text annotation needs to be done with accuracy and comprehensiveness.With machine learning (ML), machines are taught how to read, understand, analyze, and produce text in a valuable way for technological interactions with humans. Per the 2020 State of AI and Machine Learning report, 70% of companies reported that text is a type of data they use as part of their AI solutions. Understandably so, as the cost-savings and revenue-generating implications of text-based solutions across all industries are enormous.As machines improve their ability to interpret human language, the importance of training using high-quality text data becomes increasingly indisputable. In all cases, preparing accurate training data must begin with accurate, comprehensive text annotation.
What is Text Annotation?

Algorithms use large amounts of annotated data to train AI models, which is part of a larger data labeling workflow. During the annotation process, a metadata tag is used to mark up characteristics of a dataset. With text annotation, that data includes tags that highlight criteria such as keywords, phrases, or sentences. In certain applications, text annotation can also include tagging various sentiments in text, such as “angry” or “sarcastic” to teach the machine how to recognize human intent or emotion behind words.The annotated data, known as training data , is what the machine processes. The goal? Help the machine understand the natural language of humans. This procedure, combined with data pre-processing and annotation, is known as natural language processing, or NLP.These tags must be accurate and comprehensive. Poorly done text annotations will lead a machine to exhibit grammatical errors or issues with clarity or context. If you ask your bank’s chatbot, “How do I put a hold on my account?” and it responds with, “Your account does not have a hold on it,” then clearly the machine misunderstood the question and needs retraining on more accurately-annotated data.A machine will learn to communicate efficiently enough in natural language after being trained on accurately annotated text data. It can carry out the more repetitive and mundane tasks humans would otherwise do. This frees up time, money, and resources in an organization to enable focus on more strategic endeavors.The applications of natural language-based AI systems are endless: smart chatbots , e-commerce experience improvements, voice assistants, machine translators, more efficient search engines, and more. The ability to streamline transactions by leveraging high-quality text data has far-reaching implications for customer experience and organizations’ bottom line across all major industries.
Types of Text Annotation
Annotations for text include a wide range of types, such as sentiment, intent, semantic, and relationship. These options are available across a wide array of human languages.
Sentiment Annotation
Sentiment annotation evaluates attitudes and emotions behind a text by labeling that text as positive, negative, or neutral.
Intent Annotation
Intent annotation analyzes the need or desire behind a text, classifying it into several categories, such as request, command, or confirmation.
Semantic Annotation
Semantic annotation attaches various tags to text that reference concepts and entities, such as people, places, or topics.
Relationship Annotation
Relationship annotation seeks to draw various relationships between different parts of your document. Typical tasks include dependency resolution and coreference resolution.The type of project and associated use cases will determine which text annotation technique should be selected.
How is Text Annotated?
Most organizations seek out human annotators to label text data. Human annotators are especially valuable in analyzing sentiment data, as this can often be nuanced and is dependent on modern trends in slang and other uses of language.Still, large-scale text annotation and classification tools out there can help you achieve the deployment of your AI model quickly and more inexpensively. The route you take will depend on the complexity of the problem you’re trying to solve, as well as the resources and financial commitment your organization is willing to make.Refer to data labeling methods for a comprehensive look at the annotation options available to your organization.
Appen’s Text Annotation Expert - Yao Xu
At Appen, we rely on our team of experts to help provide text annotation for our customers’ machine learning tools. Yao Xu, one of our product managers, helps ensure the Appen Data Annotation Platform exceeds industry standards in providing high-quality text annotation services. She came from a science and linguistic academic background, speaks three languages, and has extensively studied ML and NLP. Her top insights when evaluating and fulfilling your text annotation needs include: Know your current goal and long-term vision
- What kind of data do you need
Define what types of annotation are needed as your model’s training data - whether it’s document level labeling or token level labeling, whether it’s collecting data from scratch or labeling data or reviewing machine prediction. It’s an essential first step to have your goal defined.
- How much data do you need and how soon
The volume data and your required data throughput is a significant factor in deciding your data annotation strategy. When your needs are low, it may be a good idea to start from open-source annotation tools or subscribe to self-serve platforms. But if you foresee a fast-growing need in annotated text data in your team, it might be a good idea to spend time to evaluate your options and choose a platform or service partner that could work in the long run.
- Is your data in a specialized domain or non-English languages
Text data in specialized domains or non-English languages may require annotators to have relevant knowledge and skills. This may pose a constraint when you’re scaling your data annotation effort. Choosing the right partner that could fulfill these special needs becomes essential in this case.
- What resources do you have
You may have an experienced engineering team to process your data and build models. You may already have a team of expert annotators. You may even have your own annotation tools. Whatever resources you have, you want to maximize their value when acquiring external resources.
- Look beyond text-based data
Text data can also be extracted from images, audio, and video files. If such needs occur, you’d need your annotation platform or service provider to be able to handle the transcription task from these non-text data. This is also something that you should take into consideration when choosing your annotation solutions.
What Appen Can Do For You
At Appen, our data annotation experience spans over 20 years, over which time we have acquired advanced resources and expertise on the best formula for successful annotation projects. By combining our intelligent annotation platform, a team of annotators tailored for your projects, and meticulous human supervision by our AI crowd-sourcing specialists, we give you the high-quality training data you need to deploy world-class models at scale. Our text annotation, image annotation, audio annotation, and video annotation capabilities will cover the short-term and long-term demands of your team and your organization. Whatever your data annotation needs may be, our platform, our crowd, and managed services team are standing by to assist you in deploying and maintaining your AI and ML projects.Learn more about what solutions are available to help you with your text annotation projects, or contact us today to speak with someone directly.
Related posts
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
- Trending Now
- Foundational Courses
- Data Science
- Practice Problem
- Machine Learning
- System Design
- DevOps Tutorial
- Word Embedding using Word2Vec
- Python | Lemmatization with NLTK
- Removing stop words with NLTK in Python
- Machine Translation in AI
- seq2seq Model in Machine Learning
- What is Sentiment Analysis?
- Self - attention in NLP
- Different Techniques for Sentence Semantic Similarity in NLP
- Artificial Intelligence | Natural Language Generation
- Introduction to Stemming
- Pre-trained Word embedding using Glove in NLP models
- Named Entity Recognition
- Hugging Face Transformers Introduction
- Top 5 PreTrained Models in Natural Language Processing (NLP)
- Translatotron 2 Speech-to-Speech Translation Architecture
- What is Retrieval-Augmented Generation (RAG) ?
- Hidden Markov Model in Machine learning
- Text augmentation techniques in NLP
- Explanation of BERT Model - NLP
What’s Text Annotation and its Types in Machine Learning?
Ever been stunned by how your smartphone seems to accurately predict what you have in mind as you type your text responses? Or, have you ever been in awe of how you got your questions answered or money refunded by a customer service associate who was not even a human after all? Well, behind every such surprising incident, there are concepts in action like Artificial Intelligence , Machine Learning , and most importantly, NLP (Natural Language Processing) . One of the biggest breakthroughs of our recent times is NLP, where machines are gradually evolving to understand how humans talk, emote, comprehend, respond, analyze, and even mimic human conversations and sentiment-driven behaviors. This concept has been highly influential in the development of chatbots, text-to-speech tools, voice recognition, virtual assistants, and more.
If Alexa or Siri could come back with quirky responses to our bizarre questions, that’s because NLP and its allied technologies like artificial intelligence and machine learning have evolved to an extent that they could almost crack the Turing Test. However, reaching here wasn’t easy, and going forward won’t be, either. To push the boundaries, we need to train machine learning modules with more and more volumes of data and this can happen only with proper data annotation techniques. For the uninitiated, data annotation is the process of labeling data with descriptions or information to make it understandable by machines. As far as NLP is concerned, the data annotation technique we apply is called text annotation. Let’s explore this a little more.
What is Text Annotation?
Text annotation is identifying and labeling sentences with additional information or metadata to define the characteristics of sentences. This information could be highlighting parts of speech in a sentence, grammar syntax, keywords, phrases, emotions, sarcasm, sentiments and more depending on the scope of a project. Machine learning modules are fed with such AI training data, where they learn diverse aspects of sentences, sentence formation, and more to understand human conversations better. As they learn with properly annotated data, they become better at mimicking human conversations (current virtual assistants). However, feed them with poorly annotated data, and you will find them deliver irrelevant, dumb, or misleading responses. That’s why text labeling should be done by experts, who meticulously tag every single aspect of a sentence to ensure nothing crucial for machines to understand and learn is overlooked. To achieve precision, experts deploy distinct text annotation techniques. What are they? Let’s find out.
Types of Text Annotation Techniques
- Sentiment Annotation : Often, humans tend to be sarcastic in their responses. Especially on websites and reviews, we tend to share our bad experiences with a restaurant or a hotel through sarcasm and machines could easily misinterpret them as compliments. If every sarcastic comment is learned as a compliment by machines, this would completely skew the results. That’s why sentiment annotation becomes crucial. This technique specifies the emotion or attitude behind a sentence (sarcasm in this case) and every sentence is labelled as neutral, positive, or negative.
- Intent Annotation : This technique differentiates the intentions of users. When interacting with chatbots, different users respond with different intentions. Some request statements, others command responses for overcharges, a few confirm the debit of money, and more. These distinct types of desires are classified through appropriate labels in this technique.
- Keyphrase tagging – this involves locating and identifying keywords in a text.
- Named Entity Recognition – this involves annotating proper names such as names of people, places, countries, and more.
- Parts Of Speech Annotation – this involves identifying nouns, verbs, adjectives, punctuations, prepositions, and more in a sentence.
- Text Classification : Otherwise, known as document classification or text categorization, annotators read chunks of paragraphs or sentences and understand the sentiments, emotions, and intentions behind them. They then classify the text based on their comprehension into categories specified by their projects. It could be as simple as classifying a piece of the article under entertainment or sports or as complex as categorizing products in an eCommerce store.
- Linguistic Annotation : Linguistic annotation involves a bit of everything we discussed so far but the only difference here is that the annotation process is done on language data. Because of this, this technique involves an additional type of annotation type called phonetics annotation, where intonations, natural pauses, stress, and more are tagged as well.
Text Annotation Use Cases
Text annotation is used in a variety of industries and sectors where natural language processing (NLP) and machine learning are used. Here are a few industries where text annotation is commonly used:
Medical Research and Healthcare:
- Annotators may annotate text in medical literature with terms related to illnesses, ailments, and treatments in order to create datasets for knowledge discovery and information extraction.
- Financial institutions measure market sentiment by using text annotation for sentiment analysis of news stories, social media posts, and financial reports.
- Financial documents are annotated to extract pertinent information for risk assessment and decision-making .
Retail and E-commerce:
- Text annotation is used in e-commerce to extract product attributes, analyse customer sentiment from reviews, and categorize products.
- It aids in comprehending trends, product preferences, and customer feedback.
Customer service and support:
- Businesses classify and examine email correspondence, chat transcripts, and customer support tickets using text annotation to speed up response times and spot recurring problems.
Legal and Compliance:
- Text annotation is used in the legal field to categorise and extract data for legal research and compliance from contracts, case law, and legal documents.
Marketing and Social Media:
- Text annotation is used by social media platforms for user profiling, sentiment analysis, and content classification.
- Marketing teams use annotated data to run targeted campaigns, assess consumer sentiment, and understand customer opinions.
Data Extraction and Search Engine Optimisation:
- By comprehending the purpose and context of user queries, search engines employ text annotation to enhance search results.
- Search engine algorithms benefit from the structured data created by annotating web pages.
Human Resources:
- Text annotation is used in recruitment to match candidates with job requirements by analysing resumes, cover letters, and job descriptions.
- Performance evaluations and employee comments are also annotated for sentiment analysis.
Academic Research:
- Scholars employ text annotation techniques to classify and examine scholarly articles, journals, and papers in order to conduct literature reviews and retrieve relevant information.
Public Services and Government:
- Government agencies use text annotation to analyse public opinion, classify citizen feedback, and extract data from documents.
So, these were the different types of text annotation techniques. We believe you now have a better idea of how even simple applications of NLP perform so accurately on our smartphones. As projects become more complex, text data sourcing and labeling become equally complex as well. That’s why it is important to collaborate with data annotation experts to get the most precise AI training data for your modules.
Frequently Asked Questions (FAQs)
Q. what is text annotation and labeling.
The process of adding metadata or labels to unstructured text data is known as text annotation and labelling. This helps with natural language processing (NLP) and machine learning tasks by making the text more machine-readable and structured.
Q. What makes text annotation significant?
In NLP tasks, text annotation is essential for training machine learning models. By linking distinct characteristics or categories to various textual segments, it facilitates the understanding and learning process of algorithms.
Q. What kinds of text annotations are most common?
Text classification, named entity recognition (NER), sentiment analysis, part-of-speech tagging, event extraction, and relation extraction are examples of common types text annotations.
Q. What is the connection between text annotation and supervised learning?
Annotated text data is used in supervised learning to train machine learning models. In order to predict outcomes for newly uncovered data, models acquire patterns from labelled examples.
Please Login to comment...
Similar reads.

- How to Use ChatGPT with Bing for Free?
- 7 Best Movavi Video Editor Alternatives in 2024
- How to Edit Comment on Instagram
- 10 Best AI Grammar Checkers and Rewording Tools
- 30 OOPs Interview Questions and Answers (2024)
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
Skip to content. | Skip to navigation
Masterlinks
- About Hunter
- One Stop for Students
- Make a Gift
- Access the Student Guide
- Apply to Become a Peer Tutor
- Access the Faculty Guide
- Request a Classroom Visit
- Refer a Student to the Center
- Request a Classroom Workshop
- The Writing Process
- The Documented Essay/Research Paper
- Writing for English Courses
- Writing Across the Curriculum
- Grammar and Mechanics
- Business and Professional Writing
- CUNY TESTING
- | Workshops
- Research Information and Resources
- Evaluating Information Sources
- Writing Tools and References
- Reading Room
- Literary Resources
- ESL Resources for Students
- ESL Resources for Faculty
- Teaching and Learning
- | Contact Us
Annotating a text, or marking the pages with notes, is an excellent, if not essential, way to make the most out of the reading you do for college courses. Annotations make it easy to find important information quickly when you look back and review a text. They help you familiarize yourself with both the content and organization of what you read. They provide a way to begin engaging with ideas and issues directly through comments, questions, associations, or other reactions that occur to you as you read. In all these ways, annotating a text makes the reading process an active one, not just background for writing assignments, but an integral first step in the writing process.
A well-annotated text will accomplish all of the following:
- clearly identify where in the text important ideas and information are located
- express the main ideas of a text
- trace the development of ideas/arguments throughout a text
- introduce a few of the reader’s thoughts and reactions
Ideally, you should read a text through once before making major annotations. You may just want to circle unfamiliar vocabulary or concepts. This way, you will have a clearer idea about where major ideas and important information are in the text, and your annotating will be more efficient.
A brief description and discussion of four ways of annotating a text— highlighting/underlining, paraphrase/summary of main ideas, descriptive outline, and comments/responses —and a sample annotated text follow:
HIGHLIGHTING/UNDERLINING
Highlighting or underlining key words and phrases or major ideas is the most common form of annotating texts. Many people use this method to make it easier to review material, especially for exams. Highlighting is also a good way of picking out specific language within a text that you may want to cite or quote in a piece of writing. However, over-reliance on highlighting is unwise for two reasons. First, there is a tendency to highlight more information than necessary, especially when done on a first reading. Second, highlighting is the least active form of annotating. Instead of being a way to begin thinking and interacting with ideas in texts, highlighting can become a postponement of that process.
On the other hand, highlighting is a useful way of marking parts of a text that you want to make notes about. And it’s a good idea to highlight the words or phrases of a text that are referred to by your other annotations.
PARAPHRASE/SUMMARY OF MAIN IDEAS
Going beyond locating important ideas to being able to capture their meaning through paraphrase is a way of solidifying your understanding of these ideas. It’s also excellent preparation for any writing you may have to do based on your reading. A series of brief notes in the margins beside important ideas gives you a handy summary right on the pages of the text itself, and if you can take the substance of a sentence or paragraph and condense it into a few words, you should have little trouble clearly demonstrating your understanding of the ideas in question in your own writing.
DESCRIPTIVE OUTLINE
A descriptive outline shows the organization of a piece of writing, breaking it down to show where ideas are introduced and where they are developed. A descriptive outline allows you to see not only where the main ideas are but also where the details, facts, explanations, and other kinds of support for those ideas are located.
A descriptive outline will focus on the function of individual paragraphs or sections within a text. These functions might include any of the following:
- summarizing a topic/argument/etc.
- introducing an idea
- adding explanation
- giving examples
- providing factual evidence
- expanding or limiting the idea
- considering an opposing view
- dismissing a contrary view
- creating a transition
- stating a conclusion
This list is hardly exhaustive and it’s important to recognize that several of these functions may be repeated within a text, particularly ones that contain more than one major idea.
Making a descriptive outline allows you to follow the construction of the writer’s argument and/or the process of his/her thinking. It helps identify which parts of the text work together and how they do so.
COMMENTS/RESPONSES
You can use annotation to go beyond understanding a text’s meaning and organization by noting your reactions—agreement/disagreement, questions, related personal experience, connection to ideas from other texts, class discussions, etc. This is an excellent way to begin formulating your own ideas for writing assignments based on the text or on any of the ideas it contains.

Document Actions
- Public Safety
- Website Feedback
- Privacy Policy
- CUNY Tobacco Policy
- Academic Success
Annotating Texts
What is annotation.
Annotation can be:
- A systematic summary of the text that you create within the document
- A key tool for close reading that helps you uncover patterns, notice important words, and identify main points
- An active learning strategy that improves comprehension and retention of information
Why annotate?
- Isolate and organize important material
- Identify key concepts
- Monitor your learning as you read
- Make exam prep effective and streamlined
- Can be more efficient than creating a separate set of reading notes
How do you annotate?
Summarize key points in your own words.
- Use headers and words in bold to guide you
- Look for main ideas, arguments, and points of evidence
- Notice how the text organizes itself. Chronological order? Idea trees? etc.
Circle Key Concepts and Phrases
- What words would it be helpful to look-up at the end?
- What terms show up in lecture? When are different words used for similar concepts? Why?
Write Brief Comments and Questions in the Margins
- Be as specific or broad as you would like—use these questions to activate your thinking about the content
- See the guide on reading comprehension tips for some examples
Use Abbreviations and Symbols
- Try ? when you have a question or something you need to explore further
- Try ! When something is interesting, a connection, or otherwise worthy of note
- Try * For anything that you might use as an example or evidence when you use this information.
- Ask yourself what other system of symbols would make sense to you.
Highlight/Underline
- Highlight or underline, but mindfully. Check out the resource on strategic highlighting for tips on when and how to highlight.
Use Comment and Highlight Features Built into PDFs, Online/Digital Textbooks, or Other Apps and Browser Add-ons
- Are you using a pdf? Explore its highlight, edit, and comment functions to support your annotations
- Some browsers have add-ons or extensions that allow you to annotate web pages or web-based documents
- Does your digital or online textbook come with an annotation feature?
- Can your digital text be imported into a note-taking tool like OneNote, EverNote, or Google Keep? If so, you might be able to annotate texts in those apps
What are the most important takeaways?
- Annotation is about increasing your engagement with a text
- Increased engagement, where you think about and process the material then expand on your learning, is how you achieve mastery in a subject
- As you annotate a text, ask yourself: "How would I explain this to a friend?"
- Put things in your own words and draw connections to what you know and wonder
The table below demonstrates this process using a geography textbook excerpt (Press 2004):

A common concern about annotating texts: It takes time!
Yes, it can, but that time isn’t lost—it’s invested.
Spending the time to annotate on the front end does two important things:
- It saves you time later when you’re studying. Your annotated notes will help speed up exam prep, because you can review critical concepts quickly and efficiently.
- It increases the likelihood that you will retain the information after the course is completed. This is especially important when you are supplying the building blocks of your mind and future career.
One last tip: Try separating the reading and annotating processes! Quickly read through a section of the text first, then go back and annotate.
Works Consulted
Nist, S., & Holschuh, J. (2000). Active learning: strategies for college success. Boston: Allyn and Bacon. 202-218.
Simpson, M., & Nist, S. (1990). Textbook annotation: An effective and efficient study strategy for college students. Journal of Reading, 34 : 122-129.
Press, F. (2004). Understanding earth (4th ed). New York: W.H. Freeman. 208-210.
Developed and shared by The Learning Center , University of North Carolina at Chapel Hill.
- Class Attendance
- Semester-At-A-Glance Calendar
- Semester Action Plan
- Using Calendars and Planners
- Studying 101
Watch Asking for Help Video
Ask for Help - We Want You to Succeed
View All Student Tips
815-753-6636 [email protected]
Connect with us
Please enable JavaScript to view this site.
A Complete Guide to Text Annotation
What is text annotation, what are some types of annotation styles, how is text annotated, text annotation: key takeaways.

Have you ever considered the sources from which AI models acquire language? Or the extensive effort required to curate high-quality data to power today's sophisticated language systems?
By the end of the guide, you will be able to answer the following questions:
- What is text annotation?
- What are some types of text annotation?
- How is text annotation?
Traditionally, text annotation involves adding comments, notes, or footnotes to a body of text. This practice is commonly seen when editors review a draft, adding notes or useful comments (i.e. annotations) before passing it on for corrections.
In the context of machine learning , the term takes on a slightly different meaning. It refers to the systematic process of labeling pieces of text to generate a ground-truth . The labeled data ensures that a supervised machine learning algorithm can accurately interpret and understand the data.
What Does it Mean to Annotate Text?
In the data science world, annotating text is a process that requires a deep understanding of both the problem at hand and the data itself to identify relevant features and label them so. This can be likened to the task of labeling cats and dogs in several images for image classification .
In text classification, annotating text would mean looking at sentences and marking them, putting each in predefined categories; like labeling online reviews as positive or negative, or news clippings as fake or real.
More tasks, such as labeling parts of speech (like nouns, verbs, subjects, etc.), labeling key phrases or words in a text for named entity recognition (ner) or to summarize a long article or research paper in a few hundred words all come under annotating text.

A Comprehensive Guide to Named Entity Recognition (NER) (Turing.com)
What are the Benefits of Text Annotation?
Doing what we described above enables a machine learning algorithm to identify different categories and use the data corresponding to these labels to learn what the data from each category typically looks like. This speeds up the learning task and improves the algorithm’s performance in the real world.
Learning without labels, while common today in NLP, is challenging as it is left to the algorithm to identify the nuances of the English language without any additional help and also recognize them when the model is put out in the real world. In text classification, for instance, a negative piece of text might be veiled in sarcasm—something that a human reader would instantly recognize, but an algorithm might just see the sarcastically positive words as just positive! Text annotations and labels are invaluable in these cases.
Large companies that are developing powerful language models today also, on the other hand, rely on text annotation for a number of important use cases. For social media companies, that includes flagging inappropriate comments or posts, online forums to flag bots and spammy content, or news websites to remove fake or low-quality pieces. Even apps for basic search engines and chatbots can be trained to extract information from their queries.

Image by Author
Since there are several tasks of varying nature for language interpretation in natural language processing, annotating and preparing the training data for each of them has a different objective. However, there are some standard approaches that cover the basic NLP tasks like classifying text and parts of text. While these may not cover generative text tasks like text summarization, they are important in understanding the different approaches to label a text.
Text Classification
Just as it sounds, a text classification model is meant to take a piece of text (sentence, phrase or paragraph) and determine what category it belongs to. Document classification involves the categorization of long texts, often with multiple pages. This annotation process involves the annotators reading every text sample and determining which one of the context-dependent predefined categories each sample belongs to.
Typical examples are binning news clippings into various topics, sorting documents based on their contents, or as simple as looking at movie plot summaries and mapping them to a genre (as shown in some examples below).

Genre Classification Dataset IMDb | Kaggle
Sentiment Annotation
Similar to text classification in process and strategy, the annotator plays a larger role in labeling a dataset for sentiment-related tasks. This task requires the annotator to interpret the text and look for the emotion and implicit context behind it—something that is not readily apparent to humans or machines when looking at the text.
Typical examples include sentiment analysis of a subject from social media data, analyzing customer feedback or product reviews, or gauging the shift in public opinion over a period of time by tracking historical texts.
Entity Annotation
Often understanding natural language extends to recalling or extracting important information from a given text, such as names, various numbers, topics of interest, etc. Annotating such information (in the form of words or phrases) is called entity annotation.
Annotators look for terms in a text of interest and classify them into predefined categories such as dates, countries, topics, names, addresses, zip codes, etc. A user can look up or extract only the pertinent information from large documents by using models trained on such a dataset to quickly label portions of the text. Semantic annotation involves a similar process, but the tags are often concepts and topics.
Keyphrase tagging (looking for topic-dependent keywords), NER (or named entity recognition) (covering a more extensive set of entities), and parts of speech tagging (understanding grammatical structure) come under entity annotation.
Intent Annotation
Another approach to annotating text is to direct the interpretation of a sentence towards an action. Typically used for chatbots, intent annotation helps create datasets that can train machine learning models to determine what the writer of the text wants. In the context of a virtual assistant, a message might be a greeting, an inquiry for information, or an actionable request. A model trained on a dataset where the text is labeled using intent annotation can classify each incoming message into a fixed category and simplify the conversation ahead.
Linguistic Annotation
This kind of text annotation focuses on how humans engage with the language—in pronunciation, phonetic sound, parts of speech, word meanings, and structure. Some of these are important in building a text-to-speech converter that creates human-sounding voices with different accents.

FLORS - Part-of-Speech Tagger
Now that we have established the various perspectives from which an annotator can look at their task, we can look at what a standard process of text annotation would be and how to annotate text for a machine learning problem. There is no all-encompassing playbook, but a well-defined workflow to go through the process step-by-step and a clear annotation guideline helps a ton.
What are Annotation Guidelines?
Text annotation guidelines are a set of rules and suggestions that act as a reference guide for annotators. An annotator must look at it and be able to understand the modeling objective and the purpose the labels would serve to that end. Since these guidelines dictate what is required of the final annotations, they must be set by the team familiar with the data and will use the annotations.
These guidelines can begin with one of the annotation techniques, or something customized that defines the problem and what to look for in the data. They must also define various cases, common and potentially ambiguous, the annotator might face in the data and actions to perform for each such problem.
For that purpose, they must also cover common examples found in the data and guidelines to deal with outliers, out-of-distribution samples, or other cases that might induce ambiguity while annotating. You can create an annotation workflow by beginning with a skeleton process, as shown below.
Curate Annotation Guidelines
Selecting a labeling tool, defining an annotation process, review and quality control.
- First, define the modeling problem (classification, generation, clustering, etc.) that the team is trying to tackle with the data and the expected outcome of the annotation process like the fixed set of labels/categories , data format, and exporting instructions.
- This can be extended to curating the actual guidelines that are comprehensive yet easy to revisit.
- Getting the right text annotation tools can make all the difference between a laborious and menial task and a long but efficient process.
- Given the prevalence of text modeling, there are several open-source labeling tools available.
Below is an illustration of Doccano that shows how straightforward annotating intent detection and NER is!

Open Source Annotation Tool for Machine Learning Practitioners
- Once the logistics are in place, it is important to have a reproducible and error-free workflow that can accommodate multiple annotators and a uniform collection of labeled samples.
- Defining an annotation process includes organizing the data source and labeled data, defining the usage of the guidelines and the annotation tool, a step-by-step guide to performing the actual text annotation, the format of saving and exporting the annotations, and the review every labeled sample.
- Given the commonly large sizes of text data teams usually work with, ensuring a streamlined flow of incoming samples and outgoing labels and reviewing each sample (which might get challenging as one sample can be as big as a multi-page document) is essential.
- Along with on-the-fly review, have a collective look at the labeled data periodically to avoid generic label errors or any bias in labeling that might have come in over time.
- It is also common to have multiple annotators label the same sample for consistency and to avoid any bias in interpretation, especially in cases where sentiment or contextual interpretation is crucial.
- To check for the bias and reliability of multiple human annotators, there are statistical measures that can be used to highlight undesirable trends. Comparison metrics such as Cohen’s kappa statistic measure how often two annotators agree with each other on the same set of samples, given the likelihood they would agree by chance. An example of interpreting Cohen’s kappa is shown below. Monitoring such metrics would flag disagreement and expose potential caveats in understanding the data and the problem.

Understanding Interobserver Agreement: The Kappa Statistic
This article underlines the roles text annotation plays for natural language processing use cases and details how you can get started with data annotation for text. You saw how:
- high-quality data can significantly impact the training process for a machine learning model.
- different tasks require different approaches and perspectives to annotating a text corpus; some require understanding the meaning of the text, while others require grammar and structure.
- guidelines and choosing the right text annotation tool can simplify large-scale data annotation and improve reliability.
- using strategies such as multiple annotators, quality metrics , and more can help generate high-quality labels.

Build better ML models with Encord
Discuss this blog on slack.
Join the Encord Developers community to discuss the latest in computer vision, machine learning, and data-centric AI
Related Blogs

With data becoming a pillar stone of a company’s growth strategy, the market for visualization tools is growing rapidly, with a projected compound annual growth rate (CAGR) of 10.07% between 2023 and 2028. The primary driver of these trends is the need for data-driven decision-making, which involves understanding complex data patterns and extracting actionable insights to improve operational efficiency. PowerBI and Tableau are traditional tools with interactive workspaces for creating intuitive dashboards and exploring large datasets. However, other platforms are emerging to address the ever-changing nature of the modern data ecosystem. In this article, we will discuss the visualizations offered by Databricks - a modern enterprise-scale platform for building data, analytics, and artificial intelligence (AI) solutions. Databricks Databricks is an end-to-end data management and model development solution built on Apache Spark. It lets you create and deploy the latest generative AI (Gen AI) and large language models (LLMs). The platform uses a proprietary Mosaic AI framework to streamline the model development process. It provides tools to fine-tune LLMs seamlessly through enterprise data and offers a unified service for experimentation through foundation models. In addition, it features Databricks SQL, a state-of-the-art lakehouse for cost-effective data storage and retrieval. It lets you centrally store all your data assets in an open format, Delta Lake, for effective governance and discoverability. Further, Databricks SQL has built-in support for data visualization, which lets you extract insights from datasets directly from query results in the SQL editor. Users also benefit from the visualization tools featured in Databricks Notebooks, which help you build interactive charts by using the Plotly library in Python. Through these visualizations, Databricks offers robust data analysis for monitoring data assets critical to your AI models. So, let’s discuss in more detail the types of chart visualizations, graphs, diagrams, and maps available on Databricks to help you choose the most suitable visualization type for your use case. Effective visualization can help with effortless data curation. Learn more about how you can use data curation for computer vision Visualizations in Databricks As mentioned earlier, Databricks provides visualizations through Databricks SQL and Databricks Notebooks. The platform lets you run multiple SQL queries to perform relevant aggregations and apply filters to visualize datasets according to your needs. Databricks also allows you to configure settings related to the X and Y axes, legends, missing values, colors, and labels. Users can also download visualizations in PNG format for documentation purposes. The following sections provide an overview of the various visualization types available in these two frameworks, helping you select the most suitable option for your project. Bar Chart Bar charts are helpful when you want to compare the frequency of occurrence of different categories in your dataset. For instance, you can draw a bar chart to compare the frequency of various age groups, genders, ethnicities, etc. Additionally, bar charts can be used to view the sum of the prices of all orders placed in a particular month and group them by priority. Bar chart The result will show the months on the X-axis and the sum of all the orders categorized by priority on the Y-axis. Line Line charts connect different data points through straight lines. They are helpful when users want to analyze trends over some time. The charts usually show time on the X-axis and some metrics whose trajectory you want to explore on the Y-axis. Line chart For instance, you can view changes in the average price of orders over the years grouped by priority. The trends can help you predict the most likely future values, which can help you with financial projections and budget planning. Pie Chart Pie charts display the proportion of different categories in a dataset. They divide a circle into multiple segments, each showing the proportion of a particular category, with the segment size proportional to the category’s percentage of the total. Pie chart For instance, you can visualize the proportion of orders for each priority. The visualization is helpful when you want a quick overview of data distribution across different segments. It can help you analyze demographic patterns, market share of other products, budget allocation, etc. Scatter Plot A scatter plot displays each data point as a dot representing a relationship between two variables. Users can also control the color of each dot to reflect the relationship across different groups. Scatter Plot For instance, you can plot the relationship between quantity and price for different color-coded item categories. The visualization helps in understanding the correlation between two variables. However, users must interpret the relationship cautiously, as correlation does not always imply causation. Deeper statistical analysis is necessary to uncover causal factors. Area Charts Area charts combine line and bar charts by displaying lines and filling the area underneath with colors representing particular categories. They show how the contribution of a specific category changes relative to others over time. Area Charts For instance, you can visualize which type of order priority contributed the most to revenue by plotting the total price of different order priorities across time. The visualization helps you analyze the composition of a specific metric and how that composition varies over time. It is particularly beneficial in analyzing sales growth patterns for different products, as you can see which product contributed the most to growth across time. Box Chart Box charts concisely represent data distributions of numerical values for different categories. They show the distribution’s median, skewness, interquartile, and value ranges. Box Chart For instance, the box can display the median price value through a line inside the box and the interquartile range through the top and bottom box enclosures. The extended lines represent minimum and maximum price values to compute the price range. The chart helps determine the differences in distribution across multiple categories and lets you detect outliers. You can also see the variability in values across different categories and examine which category was the most stable. Bubble Chart Bubble charts enhance scatter plots by allowing you to visualize the relationship of three variables in a two-dimensional grid. The bubble position represents how the variable on the X-axis relates to the variable on the Y-axis. The bubble size represents the magnitude of a third variable, showing how it changes as the values of the first two variables change. Bubble chart The visualization is helpful for multi-dimensional datasets and provides greater insight when analyzing demographic data. However, like scatter plots, users must not mistake correlation for causation. Combo Chart Combo charts combine line and bar charts to represent key trends in continuous and categorical variables. The categorical variable is on the X-axis, while the continuous variable is on the Y-axis. Combo Chart For instance, you can analyze how the average price varies with the average quantity according to shipping date. The visualization helps summarize complex information involving relationships between three variables on a two-dimensional graph. However, unambiguous interpretation requires careful configuration of labels, colors, and legends. Heatmap Chart Heatmap charts represent data in a matrix format, with each cell having a different color according to the numerical value of a specific variable. The colors change according to the value intensity, with lower values typically having darker and higher values having lighter colors. Heatmap chart For instance, you can visualize how the average price varies according to order priority and order status. Heatmaps are particularly useful in analyzing correlation intensity between two variables. They also help detect outliers by representing unusual values through separate colors. However, interpreting the chart requires proper scaling to ensure colors do not misrepresent intensities. Histogram Histograms display the frequency of particular value ranges to show data distribution patterns. The X-axis contains the value ranges organized as bins, and the Y-axis shows the frequency of each bin. Histogram For instance, you can visualize the frequency of different price ranges to understand price distribution for your orders. The visualization lets you analyze data spread and skewness. It is beneficial in deeper statistical analysis, where you want to derive probabilities and build predictive models. Pivot Tables Pivot tables can help you manipulate tabular displays through drag-and-drop options by changing aggregation records. The option is an alternative to SQL filters for viewing aggregate values according to different conditions. Pivot Tables For instance, you can group total orders by shipping mode and order category. The visualization helps prepare ad-hoc reports and provides important summary information for decision-making. Interactive pivot tables also let users try different arrangements to reveal new insights. Choropleth Map Visualization Choropleth map visualization represents color-coded aggregations categorized according to different geographic locations. Regions with higher value intensities have darker colors, while those with lower intensities have lighter shades. Choropleth map visualization For instance, you can visualize the total revenue coming from different countries. This visualization helps determine global presence and highlight disparities across borders. The insights will allow you to develop marketing strategies tailored to regional tastes and behavior. Funnel Visualization Funnel visualization depicts data aggregations categorized according to specific steps in a pipeline. It represents each step from top to bottom with a bar and the associated value as a label overlay on each bar. It also displays cumulative percentage values showing the proportion of the aggregated value resulting from each stage. Funnel Visualization For instance, you can determine the incoming revenue streams at each stage of the ordering process. This visualization is particularly helpful in analyzing marketing pipelines for e-commerce sites. The tool shows the proportion of customers who view a product ad, click on it, add it to the cart, and proceed to check out. Cohort Analysis Cohort analysis offers an intuitive visualization to track the trajectory of a particular metric across different categories or cohorts. Cohort Analysis For instance, you can analyze the number of active users on an app that signed up in different months of the year. The rows will depict the months, and the columns will represent the proportion of active users in a particular cohort as they move along each month. The visualization helps in retention analysis as you can determine the proportion of retained customers across the user lifecycle. Counter Display Databricks allows you to configure a counter display that explicitly shows how the current value of a particular metric compares with the metric’s target value. Counter display For instance, you can check how the average total revenue compares against the target value. In Databricks, the first row represents the current value, and the second is the target. The visualization helps give a quick snapshot of trending performance and allows you to quantify goals for better strategizing. Sankey Diagrams Sankey diagrams show how data flows between different entities or categories. It represents flows through connected links representing the direction, with entities displayed as nodes on either side of a two-dimensional grid. The width of the connected links represents the magnitude of a particular value flowing from one entity to the other. Sankey Diagram For instance, you can analyze traffic flows from one location to the other. Sankey diagrams can help data engineering teams analyze data flows from different platforms or servers. The analysis can help identify bottlenecks, redundancies, and resource constraints for optimization planning. Sunburst Sequence The sunburst sequence visualizes hierarchical data through concentric circles. Each circle represents a level in the hierarchy and has multiple segments. Each segment represents the proportion of data in the hierarchy. Furthermore, it color codes segments to distinguish between categories within a particular hierarchy. Sunburst Sequence For instance, you can visualize the population of different world regions through a sunburst sequence. The innermost circle represents a continent, the middle one shows a particular region, and the outermost circle displays the country within that region. The visualization helps data science teams analyze relationships between nested data structures. The information will allow you to define clear data labels needed for model training. Table A table represents data in a structured format with rows and columns. Databricks offers additional functionality to hide, reformat, and reorder data. Tables help summarize information in structured datasets. You can use them for further analysis through SQL queries. Word Cloud Word cloud visualizations display words in different sizes according to their frequency in textual data. For instance, you can analyze customer comments or feedback and determine overall sentiment based on the highest-occurring words. Word Cloud While word clouds help identify key themes in unstructured textual datasets, they can suffer from oversimplification. Users must use word clouds only as a quick overview and augment textual analysis with advanced natural language processing techniques. Visualization is critical to efficient data management. Find out the top tools for data management for computer vision Visualizations in Databricks: Key Takeaways With an ever-increasing data volume and variety, visualization is becoming critical for quickly communicating data-based insights in a simplified manner. Databricks is a powerful tool with robust visualization types for analyzing complex datasets. Below are a few key points to remember regarding visualization in Databricks. Databricks SQL and Databricks Notebooks: Databricks offers advanced visualizations through Databricks SQL and Databricks Notebooks as a built-in functionality. Visualization configurations: Users can configure multiple visualization settings to produce charts, graphs, maps, and diagrams per their requirements. Visualization types: Databricks offers multiple visualizations, including bar charts, line graphs, pie charts, scatter plots, area graphs, box plots, bubble charts, combo charts, heatmaps, histograms, pivot tables, choropleth maps, funnels, cohort tables, counter display, Sankey diagrams, sunburst sequences, tables, and word clouds.

What is Mora? Mora is a multi-agent framework designed for generalist video generation. Based on OpenAI's Sora, it aims to replicate and expand the range of generalist video generation tasks. Sora, famous for making very realistic and creative scenes from written instructions, set a new standard for creating videos that are up to a minute long and closely match the text descriptions given. Mora distinguishes itself by incorporating several advanced visual AI agents into a cohesive system. This lets it undertake various video generation tasks, including text-to-video generation, text-conditional image-to-video generation, extending generated videos, video-to-video editing, connecting videos, and simulating digital worlds. Mora can mimic Sora’s capabilities using multiple visual agents, significantly contributing to video generation. In this article, you will learn: Mora's innovative multi-agent framework for video generation. The importance of open-source collaboration that Mora enables. Mora's approach to complex video generation tasks and instruction fidelity. About the challenges in video dataset curation and quality enhancement. TL; DR Mora's novel approach uses multiple specialized AI agents, each handling different aspects of the video generation process. This innovation allows various video generation tasks, showcasing adaptability in creating detailed and dynamic video content from textual descriptions. Mora aims to fix the problems with current models like Sora, which is closed-source and does not let anyone else use it or do more research in the field, even though it has amazing text-to-video conversion abilities 📝🎬. Unfortunately, Mora still has problems with dataset quality, video fidelity, and ensuring that outputs align with complicated instructions and people's preferences. These problems show where more work needs to be done in the future. OpenAI Sora’s Closed-Source Nature The closed-source nature of OpenAI's Sora presents a significant challenge to the academic and research communities interested in video generation technologies. Sora's impressive capabilities in generating realistic and detailed videos from text descriptions have set a new standard in the field. Related: New to Sora? Check out our detailed explainer on the architecture, relevance, limitations, and applications of Sora. However, the inability to access its source code or detailed architecture hinders external efforts to replicate or extend its functionalities. This limits researchers from fully understanding or replicating its state-of-the-art performance in video generation. Here are the key challenges highlighted due to Sora's closed-source nature: Inaccessibility to Reverse-Engineer Without access to Sora's source code, algorithms, and detailed methodology, the research community faces substantial obstacles in dissecting and understanding the underlying mechanisms that drive its exceptional performance. This lack of transparency makes it difficult for other researchers to learn from and build upon Sora's advancements, potentially slowing down the pace of innovation in video generation. Extensive Training Datasets Sora's performance is not just the result of sophisticated modeling and algorithms; it also benefits from training on extensive and diverse datasets. But the fact that researchers cannot get their hands on similar datasets makes it very hard to copy or improve Sora's work. High-quality, large-scale video datasets are crucial for training generative models, especially those capable of creating detailed, realistic videos from text descriptions. However, these datasets are often difficult to compile due to copyright issues, the sheer volume of data required, and the need for diverse, representative samples of the real world. Creating, curating, and maintaining high-quality video datasets requires significant resources, including copyright permissions, data storage, and management capabilities. Sora's closed nature worsens these challenges by not providing insights into compiling the datasets, leaving researchers to navigate these obstacles independently. Computational Power Creating and training models like Sora require significant computational resources, often involving large clusters of high-end GPUs or TPUs running for extended periods. Many researchers and institutions cannot afford this much computing power, which makes the gap between open-source projects like Mora and proprietary models like Sora even bigger. Without comparable computational resources, it becomes challenging to undertake the necessary experimentation—with different architectures and hyperparameters—and training regimes required to achieve similar breakthroughs in video generation technology. Learn more about these limitations in the technical paper. Evolution: Text-to-Video Generation Over the years, significant advancements in text-to-video generation technology have occurred, with each approach and architecture uniquely contributing to the field's growth. Here's a summary of these evolutionary stages, as highlighted in the discussion about text-to-video generation in the Mora paper: GANs (Generative Adversarial Networks) Early attempts at video generation leveraged GANs, which consist of two competing networks: a generator that creates images or videos that aim to be indistinguishable from real ones, and a discriminator that tries to differentiate between the real and generated outputs. Despite their success in image generation, GANs faced challenges in video generation due to the added complexity of temporal coherence and higher-dimensional data. Generative Video Models Moving beyond GANs, the field saw the development of generative video models designed to produce dynamic sequences. Generating realistic videos frame-by-frame and maintaining temporal consistency is a challenge, unlike in static image generation. Auto-Regressive Transformers Auto-regressive transformers were a big step forward because they could generate video sequences frame-by-frame. These models predicted each new frame based on the previously generated frames, introducing a sequential element that mirrors the temporal progression of videos. But this approach often struggled with long-term coherence over longer sequences. Large-Scale Diffusion Models Diffusion models, known for their capacity to generate high-quality images, were extended to video generation. These models gradually refine a random noise distribution toward a coherent output. They apply this iterative denoising process to the temporal domain of videos. Related: Read our guide on HuggingFace’s Dual-Stream Diffusion Net for Text-to-Video Generation. Image Diffusion U-Net Adapting the U-Net architecture for image diffusion models to video content was critical. This approach extended the principles of image generation to videos, using a U-Net that operates over sequences of frames to maintain spatial and temporal coherence. 3D U-Net Structure The change to a 3D U-Net structure allowed for more nuance in handling video data, considering the extra temporal dimension. This change also made it easier to model time-dependent changes, improving how we generate coherent and dynamic video content. Latent Diffusion Models (LDMs) LDMs generate content in a latent space rather than directly in pixel space. This approach reduces computational costs and allows for more efficient handling of high-dimensional video data. LDMs have shown that they can better capture the complex dynamics of video content. Diffusion Transformers Diffusion transformers (DiT) combine the strengths of transformers in handling sequential data with the generative capabilities of diffusion models. This results in high-quality video outputs that are visually compelling and temporally consistent. Useful: Stable Diffusion 3 is an example of a multimodal diffusion transformer model that generates high-quality images and videos from text. Check out our explainer on how it works. AI Agents: Advanced Collaborative Multi-agent Structures The paper highlights the critical role of collaborative, multi-agent structures in developing Mora. It emphasizes their efficacy in handling multimodal tasks and improving video generation capabilities. Here's a concise overview based on the paper's discussion on AI Agents and their collaborative frameworks: Multimodal Tasks Advanced collaborative multi-agent structures address multimodal tasks involving processing and generating complex data across different modes, such as text, images, and videos. These structures help integrate various AI agents, each specialized in handling specific aspects of the video generation process, from understanding textual prompts to creating visually coherent sequences. Cooperative Agent Framework (Role-Playing) The cooperative agent framework, characterized by role-playing, is central to the operation of these multi-agent structures. Each agent is assigned a unique role or function in this framework, such as prompt enhancement, image generation, or video editing. By defining these roles, the framework ensures that an agent with the best skills for each task is in charge of that step in the video generation process, increasing overall efficiency and output quality. Multi-Agent Collaboration Strategy The multi-agent collaboration strategy emphasizes the orchestrated interaction between agents to achieve a common goal. In Mora, this strategy involves the sequential and sometimes parallel processing of tasks by various agents. For instance, one agent might enhance an initial text prompt, convert it into another image, and finally transform it into a video sequence by yet another. This collaborative approach allows for the flexible and dynamic generation of video content that aligns with user prompts. AutoGen (Generic Programming Framework) A notable example of multi-agent collaboration in practice is AutoGen. This generic programming framework is designed to automate the assembly and coordination of multiple AI agents for a wide range of applications. Within the context of video generation, AutoGen can streamline the configuration of agents according to the specific requirements of each video generation task to generate complex video content from textual or image-based prompts. Mora drone to butterfly flythrough shot. | Image Source. Role of an AI Agent The paper outlines the architecture involving multiple AI agents, each serving a specific role in the video generation process. Here's a closer look at the role of each AI agent within the framework: Illustration of how to use Mora to conduct video-related tasks Prompt Selection and Generation Agent This agent is tasked with processing and optimizing textual prompts for other agents to process them further. Here are the key techniques used for Mora: GPT-4: This agent uses the generative capabilities of GPT-4 to generate high-quality prompts that are detailed and rich in context. Prompt Selection: This involves selecting or enhancing textual prompts to ensure they are optimally prepared for the subsequent video generation process. This step is crucial for setting the stage for generating images and videos that closely align with the user's intent. Good Read: Interested in GPT-4 Vision alternatives? Check out our blog post. Text-to-Image Generation Agent This agent uses a retrained large text-to-image model to convert the prompts into initial images. The retraining process ensures the model is finely tuned to produce high-quality images, laying a strong foundation for the video generation process. Image-to-Image Generation Agent This agent specializes in image-to-image generation, taking initial images and editing them based on new prompts or instructions. This ability allows for a high degree of customization and improvement in video creation. Image-to-Video Generation Agent This agent transforms static images into dynamic video sequences, extending the visual narrative by generating coherent frames. Here are the core techniques and models: Core Components: It incorporates two pre-trained models: GPT-3 for understanding and generating text-based instructions, and Stable Diffusion for translating these instructions into visual content. Prompt-to-Prompt Technique: The prompt-to-prompt technique guides the transformation from an initial image to a series of images that form a video sequence. Classifier-Free Guidance: Classifier-free guidance is used to improve the fidelity of generated videos to the textual prompts so that the videos remain true to the users' vision. Text-to-Video Generation Agent: This role is pivotal in transforming static images into dynamic videos that capture the essence of the provided descriptions. Stable Video Diffusion (SVD) and Hierarchical Training Strategy: A model specifically trained to understand and generate video content, using a hierarchical training strategy to improve the quality and coherence of the generated videos. Video Connection Agent This agent creates seamless transitions between two distinct video sequences for a coherent narrative flow. Here are the key techniques used: Pre-Trained Diffusion-Based T2V Model: This model uses a pre-trained diffusion-based model specialized in text-to-video (T2V) tasks to connect separate video clips into a cohesive narrative. Text-Based Control: This method uses textual descriptions to guide the generation of transition videos that seamlessly connect disparate video clips, ensuring logical progression and thematic consistency. Image-to-Video Animation and Autoregressive Video Prediction: These capabilities allow the agent to animate still images into video sequences, predict and generate future video frames based on previous sequences, and create extended and coherent video narratives. Mora’s Video Generation Process Mora's video-generation method is a complex, multi-step process that uses the unique capabilities of specialized AI agents within its framework. This process allows Mora to tackle various video generation tasks, from creating videos from text descriptions to editing and connecting existing videos. Here's an overview of how Mora handles each task: Mora’s video generation process. Text-to-Video Generation This task begins with a detailed textual prompt from the user. Then, the Text-to-Image Generation Agent converts the prompts into initial static images. These images serve as the basis for the Image-to-Video Generation Agent, which creates dynamic sequences that encapsulate the essence of the original text and produce a coherent video narrative. Text-Conditional Image-to-Video Generation This task combines textual prompts with a specific starting image. Mora first improves the input with the Prompt Selection and Generation Agent, ensuring that the text and image are optimally prepared for video generation. Then, the Image-to-Video Generation Agent takes over, generating a video that evolves from the initial image and aligns with the textual description. Extend Generated Videos To extend an existing video, Mora uses the final frame of the input video as a launchpad. The Image-to-Video Generation Agent crafts additional sequences that logically continue the narrative from the last frame, extending the video while maintaining narrative and visual continuity. Video-to-Video Editing In this task, Mora edits existing videos based on new textual prompts. The Image-to-Image Generation Agent first edits the video's initial frame according to the new instructions. Then, the Image-to-Video Generation Agent generates a new video sequence from the edited frame, adding the desired changes to the video content. Connect Videos Connecting two videos involves creating a transition between them. Mora uses the Video Connection Agent, which analyzes the first video's final frame and the second's initial frame. It then generates a transition video that smoothly links the two segments into a cohesive narrative flow. Simulating Digital Worlds Mora generates video sequences in this task that simulate digital or virtual environments. The process involves appending specific style cues (e.g., "in digital world style") to the textual prompt, guiding the Image-to-Video Generation Agent to create a sequence reflecting the aesthetics of a digital realm. This can involve stylistically transforming real-world images into digital representations or generating new content within the specified digital style. See Also: Read our explainer on Google’s Video Gaming Companion: Scalable Instructable Multiworld Agent [SIMA]. Mora: Experimental Setup As detailed in the paper, the experimental setup for evaluating Mora is comprehensive and methodically designed to assess the framework's performance across various dimensions of video generation. Here's a breakdown of the setup: Baseline The baseline for comparison includes existing open-sourced models that showcase competitive performance in video generation tasks. These models include Videocrafter, Show-1, Pika, Gen-2, ModelScope, LaVie-Interpolation, LaVie, and CogVideo. These models are a reference point for evaluating Mora's advancements and position relative to the current state-of-the-art video generation. Basic Metrics The evaluation framework comprises several metrics to quantify Mora's performance across different dimensions of video quality and condition consistency: Video Quality Measurement Object Consistency: Measures the stability of object appearances across video frames. Background Consistency: Assesses the uniformity of the background throughout the video. Motion Smoothness: Evaluates the fluidity of motion within the video. Aesthetic Score: Gauges the artistic and visual appeal of the video. Dynamic Degree: Quantifies the video's dynamic action or movement level. Imaging Quality: Assesses the overall visual quality of the video, including clarity and resolution. Video Condition Consistency Metric Temporal Style: Measures how consistently the video reflects the temporal aspects (e.g., pacing, progression) described in the textual prompt. Appearance Style: Evaluates the adherence of the video's visual style to the descriptions provided in the prompt, ensuring that the generated content matches the intended appearance. Self-Defined Metrics Video-Text Integration (VideoTI): Measures the model’s fidelity to textual instructions by comparing text representations of input images and generated videos. Temporal Consistency (TCON): Evaluates the coherence between an original video and its extended version, providing a metric for assessing the integrity of extended video content. Temporal Coherence (Tmean): Quantifies the correlation between the intermediate generated and input videos, measuring overall temporal coherence. Video Length: This parameter quantifies the duration of the generated video content, indicating the model's capacity for producing videos of varying lengths. Implementation Details The experiments use high-performance hardware, specifically TESLA A100 GPUs with substantial VRAM. This setup ensures that Mora and the baseline models are evaluated under conditions allowing them to fully express their video generation capabilities. The choice of hardware reflects the computational intensity of training and evaluating state-of-the-art video generation models. Mora video generation - Fish underwater flythrough Limitations of Mora The paper outlines several limitations of the Mora framework. Here's a summary of these key points: Curating High-Quality Video Datasets Access to high-quality video datasets is a major challenge for training advanced video generation models like Mora. Copyright restrictions and the sheer volume of data required make it difficult to curate diverse and representative datasets that can train models capable of generating realistic and varied video content. Read Also: The Full Guide to Video Annotation for Computer Vision. Quality and Length Gaps While Mora demonstrates impressive capabilities, it has a noticeable gap in quality and maximum video length compared to state-of-the-art models like Sora. This limitation is particularly evident in tasks requiring the generation of longer videos, where maintaining visual quality and coherence becomes increasingly challenging. Simulating videos in Mora vs in Sora. Instruction Following Capability Mora sometimes struggles to precisely follow complex or detailed instructions, especially when generating videos that require specific actions, movements, or directionality. This limitation suggests that further improvement in understanding and interpreting textual prompts is needed. Human Visual Preference Alignment The experimental results may not always align with human visual preferences, particularly in scenarios requiring the generation of realistic human movements or the seamless connection of video segments. This misalignment highlights the need to incorporate a more nuanced understanding of physical laws and human dynamics into the video-generation process. Mora Vs. Sora: Feature Comparisons The paper compares Mora and OpenAI's Sora across various video generation tasks. Here's a detailed feature comparison based on their capabilities in different aspects of video generation: Check out the project repository on GitHub. Mora Multi-Agent Framework: Key Takeaways The paper "Mora: Enabling Generalist Video Generation via a Multi-Agent Framework" describes Mora, a new framework that advances video technology. Using a multi-agent approach, Mora is flexible and adaptable across various video generation tasks, from creating detailed scenes to simulating complex digital worlds. Because it is open source, it encourages collaboration, which leads to new ideas, and lets the wider research community add to and improve its features. Even though Mora has some good qualities, it needs high-quality video datasets, video quality, length gaps, trouble following complicated instructions correctly, and trouble matching outputs to how people like to see things. Finding solutions to these problems is necessary to make Mora work better and be used in more situations. Continuing to improve and develop Mora could change how we make video content so it is easier for creators and viewers to access and have an impact.

Panoptic Segmentation Updates in Encord Over the past 6 months, we have updated and built new features within Encord with a strong focus on improving your panoptic segmentation workflows across data, labeling, and model evaluation. Here are some updates we’ll cover in this article: Bitmask lock. SAM + Bitmask lock + Brush for AI-assisted precision labeling. Fast and performant rendering of fully bitmask-segmented images and videos. Panoptic Quality model evaluation metrics. Bitmask Lock within Encord Annotate to Manage Segmentation Overlap Our Bitmask Lock feature introduces a way to prevent segmentation and masks from overlapping, providing pixel-perfect accuracy for your object segmentation tasks. By simply toggling the “Bitmask cannot be drawn over” button, you can prevent any part of a bitmask label from being included in another label. This feature is crucial for applications requiring precise object boundaries and pixel-perfect annotations, eliminating the risk of overlapping segmentations. Let’s see how to do this within Encord Annotate: Step 1: Create your first Bitmask Initiating your labeling process with the Bitmask is essential for creating precise object boundaries. If you are new to the Bitmask option, check out our quickstart video walkthrough on creating your first Bitmask using brush tools for labeling. Step 2: Set Bitmask Overlapping Behavior Managing how bitmasks overlap is vital for ensuring accurate segmentation, especially when dealing with multiple objects that are close to each other or overlapping. After creating your first bitmask, adjust the overlapping behavior settings to dictate how subsequent bitmasks interact with existing ones. This feature is crucial for delineating separate objects without merging their labels—perfect for panoptic segmentation. This prevents any part of this bitmask label from being included in another label. This is invaluable for creating high-quality datasets for training panoptic segmentation models. Step 3: Lock Bitmasks When Labeling Multiple Instances Different images require different approaches. Beyond HSV, you can use intensity values for grayscale images (like DICOM) or RGB for color-specific labeling. This flexibility allows for tailored labeling strategies that match the unique attributes of your dataset. Experiment with the different settings (HSV, intensity, and RGB) to select the best approach for your specific labeling task. Adjust the criteria to capture the elements you need precisely. Step 4: Using the Eraser Tool Even with careful labeling, adjustments may be necessary. The eraser tool can remove unwanted parts of a bitmask label before finalizing it, providing an extra layer of precision. If you've applied a label inaccurately, use the eraser tool to correct any errors by removing unwanted areas of the bitmask. See our documentation to learn more. Bitmask-Segmented Images and Videos Got a Serious Performance Lift (At Least 5x) Encord's commitment to enhancing user experience and efficiency is evident in the significant performance improvements made to the Bitmask-segmented annotation within the Label Editor. Our Engineering team has achieved a performance lift of at least 5x by directly addressing user feedback and pinpointing critical bottlenecks. This improves how fast the editor loads for your panoptic segmentation labeling instances. Here's a closer look at the differences between the "before" and "after" scenarios, highlighting the advancements: Before the Performance Improvements: Performance Lag on Zoom: Users experienced small delays when attempting to zoom in on images, with many instances (over 100) that impacted the precision and speed of their labeling process. Slow Response to Commands: Basic functionalities like deselecting tools or simply navigating through the label editor were met with sluggish responses. Operational Delays: Every action, from image loading to applying labels, was hindered by "a few milliseconds" of delay, which accumulated significant time overheads across projects. After the Performance Enhancements: Quicker Image Load Time: The initial step of image loading has seen a noticeable speed increase! This sets a good pace for the entire labeling task. Responsiveness: The entire label editor interface, from navigating between tasks to adjusting image views, is now remarkably more responsive. This change eradicates previous lag-related frustrations and allows for a smoother user experience. Improved Zoom Functionality: Zooming in and out has become significantly more fluid and precise. This improvement is precious for detailed labeling work, where accuracy is paramount. The positive changes directly result from the Engineering team's responsiveness to user feedback. Our users have renewed confidence in handling future projects with the Label Editor. We are dedicated to improving Encord based on actual user experiences. Use Segment Anything Model (SAM) and Bitmask Lock for High Annotation Precision Starting your annotation process can be time-consuming, especially for complex images. Our Segment Anything Model (SAM) integration offers a one-click solution to create initial annotations. SAM identifies and segments objects in your image, significantly speeding up the annotation process while ensuring high accuracy. Step 1: Select the SAM tool from the toolbar with the Bitmask Lock enabled. Step 2: Click on the object you wish to segment in your image. SAM will automatically generate a precise bitmask for the object. Step 3: Use the bitmask brush to refine the edges for pixel-perfect segmentation if needed. See how to use the Segment Anything Model (SAM) within Encord in our documentation. Validate Segmentation with Panoptic Quality Metrics You can easily evaluate your segmentation model’s panoptic mask quality with new metrics: mSQ (mean Segmentation Quality) mRQ (mean Recognition Quality) mPQ (mean Panoptic Quality) The platform will calculate mSQ, mRQ, and mPQ for your predictions, labels, and dataset to clearly understand the segmentation performance and areas for improvement. Navigate to Active → Under the Model Evaluation tab, choose the panoptic model you want to evaluate. Under Display, toggle the Panoptic Quality Metrics (still in beta) option to see the model's mSQ, mRQ, and mPQ scores. Fast Rendering of Fully Bitmask-Segmented Images within Encord Active The performance improvement within the Label Editor also translates to how you view and load panoptic segmentation within Active. Try it yourself: Key Takeaways: Panoptic Segmentation Updates in Encord Here’s a recap of the key features and improvements within Encord that can improve your Panoptic Segmentation workflows across data and models: Bitmask Lock: This feature prevents overlaps in segmentation. it guarantees the integrity of each label, enhancing the quality of the training data and, consequently, the accuracy of machine learning models. This feature is crucial for projects requiring meticulous detail and precision. SAM + Bitmask Lock + Brush: The Lock feature allows you to apply Bitmasks to various objects within an image, which reduces manual effort and significantly speeds up your annotation process. The integration of SAM within Encord's platform, using Lock to manage Bitmask overlaps, and the generic brush tool empower you to achieve precise, pixel-perfect labels with minimal effort. Fast and Performant Rendering of Fully Bitmask-segmented Images and Videos: We have made at least 5x improvements to how Encord quickly renders fully Bitmask-segmented images and videos across Annotate Label Editor and Active. Panoptic Quality Model Evaluation Metrics: The Panoptic Quality Metrics—comprising mean Segmentation Quality (mSQ), mean Recognition Quality (mRQ), and mean Panoptic Quality (mPQ)—provide a comprehensive framework for evaluating the effectiveness of segmentation models.
Software To Help You Turn Your Data Into AI
Forget fragmented workflows, annotation tools, and Notebooks for building AI applications. Encord Data Engine accelerates every step of taking your model into production.
- Client Login
What is Text Annotation in Machine Learning?
By Appen. September 16, 2020
Everything You Need to Know About Text Annotation with Yao Xu
What is text annotation, types of text annotation, sentiment annotation, intent annotation, semantic annotation, relationship annotation, how is text annotated, appen’s text annotation expert – yao xu.
- What kind of data do you need
- How much data do you need and how soon
- Is your data in a specialized domain or non-English languages
- What resources do you have
- Look beyond text-based data
What Appen Can Do For You
More articles like this, the impending data crisis in the ai economy, deciphering ai from human generated text: the behavioral approach, building ai we can trust, appen and the ungc: defining sustainability and ethics in the ai era, how the human element balances ai and contributor efforts for optimal outcomes, appen's benchmarking solution: confidently choosing the right llm for your application , request a consult.
If you have any questions or would like more information about our services, please don’t hesitate to reach out. Our team is here to help and answer any questions you may have. Interested in joining our crowd? Click Here
Request a consult
- Our Products
- Case Studies
Take Your Reading Habit To The Next Level & Start Annotating Your Books
F or a minute there, it looked like books — and especially physical copies — might be going the way of the dinosaurs. But reading has taken on a whole new glamor thanks to the wild popularity of online communities like #booktok and #bookstagram . With so much inspiring book content now making the rounds, many people are flocking back to reading or looking for tricks to engage with this hobby in whole new ways.
Enter book annotation, the perfect activity to take your reading habit to the next level. Annotation is all about analyzing and responding to the books you consume, turning your passive reading experience into a truly interactive hobby.
Maybe you're already a regular bookworm who wants to get even more out of your reading time and bring your own insight and creativity to the table. Annotation provides the outlet you're looking for. Or perhaps you're an aspiring reader looking for habits that will help you read more . After all, many of us struggle to just relax and enjoy a book. Even if we do have the time, a tendency toward toxic productivity may mean that our attention span keeps wandering back to our to-do list and other responsibilities.
Wherever you are in your current reading journey, annotation can help you feel a sense of progress and focus when you pick up a book. This, in turn, can encourage you to dedicate more time to your reading hobby. Sound too good to be true? Try it for yourself! Here's everything you need to know about annotating books, and how to get started.
What Is Book Annotation, Exactly?
Book annotation is a way of recording your own thoughts and reactions to the text you're reading, whether you're marking ideas to return to later or simply emphasizing a turn of phrase you particularly loved. Often, these notes are written directly into the book itself or added with bookmarks and sticky notes.
Annotation is a helpful tool for close reading and analysis, as it turns reading into an active experience. Instead of just riding the wave of the narrative, your brain starts looking for opportunities to make observations, keeping your attention more focused. This can help improve your memory and comprehension of the text. But while annotation has traditionally been a learning technique used for studying and academia, it can also be used to connect more fully with a book you're reading for entertainment.
You can use various techniques to mark up your text, depending on your style and goals. Some common approaches include highlighting or underlining significant passages, writing brief notes in the margins, and bookmarking pages to revisit. But these are just the tip of the iceberg. Many book enthusiasts prefer finding their own ways to annotate, such as adding doodles, iconography, or even full summaries at the end of a chapter. The world — or in this case, the book — is your oyster.
Reasons To Annotate Your Books
Wondering whether annotation is really worth your time? Let's put it this way: Annotation is a fantastic method to get more out of any book. For instance, say you're trying to learn something. You can annotate books you're reading for school, work, or your own self-improvement to better remember and internalize information. Whether it's a volume on American history or discussing reliable ways to build new habits , annotation enables you to highlight the information that seems most important and lock it into your memory banks.
Book annotation also helps you interact with your just-for-fun reads on a deeper level. Have you ever read a sentence that made your heart and mind scream internally? Grab a highlighter and preserve that moment for posterity. This kind of reading is like the literary equivalent of mindful eating, letting you savor the book from beginning to end. Plus, next time you read this copy of the book, your notes will make it feel like you're re-experiencing the whole journey hand-in-hand with your past self.
Annotation can even help you become a more analytical reader to improve your own writing. Annotate books you love to identify what makes them work, from character development and plot progression to the beauty of descriptive language. Picking apart the mechanics hidden in your favorite books will make you a more thoughtful writer and suggest new elements to examine in your own work.
Annotation Is Perfect For Any Type Of Text
If you're only accustomed to taking notes on books you read for school, annotation may not seem quite natural at first. But this technique can be adapted to almost any kind of book. For instance, annotating a nonfiction book like a memoir or how-to guide is only a short jump from studying your textbooks of yore.
Annotation is also a great way to enhance your connection with fiction, encouraging you to look deeper into the story and characters. This can enrich your experience with any novel. You can even annotate texts like stage plays or books of poetry. Use close reading to really delve into the themes and language, annotating the phrases or imagery that resonate with you the most.
You don't even have to like a book to enjoy annotating it. Just as you might enjoy mocking a bad movie with friends, use annotation to roast a truly awful read. It can be cathartic and satisfying to scrawl your critiques into the margins, whether you're frustrated with unlikable characters or problems in the writing itself.
On the flip side, it can be a lot of fun annotating a book you love and want to share with a friend. Leaving behind notes, exclamations, and highlighted passages will create instant points of conversation as the book's next reader follows in your footsteps. This is especially entertaining if you have a regular reading buddy, as you can both annotate and swap books back and forth almost like trading notes in class.
Can You Annotate Books Without Writing In Them?
If you're the type of reader who won't even fold down page corners, then the idea of writing in a book may give you the heebie-jeebies. Fortunately, there are plenty of ways to annotate and personalize your copy of a favorite text without doing any permanent damage. One of the easiest and most popular ways to annotate a book without writing in it is the liberal use of sticky notes and tabs. Just scribble down your notes or questions and stick them to the page like an annotation bookmark.
If you have a lot to say, you can also pick up a separate notebook or bullet journal to serve as a one-stop shop for all your annotations. Record your thoughts, copy entire quotations, and take notes on informative content. For an even quicker, more helpful reference, jot down the page or chapter numbers you're referring to. Just keep in mind that page numbering may vary between editions of a particular text. Keeping a separate annotation notebook is especially handy if you prefer to read a lot of library books rather than purchasing your own copies. You may have to return a library book, but you can keep your annotation notebook in perpetuity.
But what if you're an aficionado of e-books? Good news, tech-savvy reader: You can also annotate digital copies of all your favorite tomes. Whether you're a fan of Amazon's Kindle, the Barnes & Noble Nook, or a third-party e-reader, chances are good that your app has annotation capabilities. These may include adding notes, bookmarks, and even highlighting passages. While annotating an e-book may not be as intimate and visceral as decorating a physical text, it still provides you with an outlet to track your thoughts and reactions.
How To Start Annotating Books
Once you decide to start experimenting with book annotation, a lot of it will be intuitive and specific to you. But before you get started, it can help to set yourself a few goals and ground rules to guide the arc of your annotation strategy. First, determine what kind of notes you want to make. Are you annotating purely for the joy of it? Then maybe your scribbled marginalia will be full of exclamations like "I love this!" and excited circles around your favorite phrases or moments.
If you're trying to emulate a book in your own writing, pick out a few specific facets you want to analyze and mark them as you go — whether you're more interested in big ideas like theme and structure or small flourishes like imagery and word choice. And if you're studying an educational book, you may want to start your annotation with an eye for unfamiliar terminology, key concepts, or useful explanations.
It can also help to create your own annotation color key before you begin, especially if you'll be making several different types of notes or remarks. For instance, use your favorite colored pen or highlighter to illuminate a phrase you loved, an aggressively neon color for things you want to remember, or a color you dislike for mistakes you'd want to avoid in your own writing.
You can also use colors to differentiate notes by purpose, such as using one hue to denote new vocabulary and another to highlight moments where the author cleverly derailed your expectations. Get creative and build this color code around your own annotation goals to make it work for you!
Book Annotation Supplies For Beginners
How you choose to annotate your book collection will obviously depend on your goals and style. But certain tools and supplies may be useful to keep on hand. After all, you don't want to miss a flash of inspiration just because you can't find a pen. And the more eye-catching you make your annotations, the more memorable and inspiring they'll become. To that end, your book annotation kit should probably include most or all of the following supplies.
First and foremost, treat yourself to some nice pens in various colors. Make sure they're pleasant to write with, but won't bleed through the page. Felt-tipped pens may be too heavy, so consider colorful ballpoints or classic gel pens. A ruler is also handy to help keep any arrows and underlining neat. A 12-inch ruler can be a bit unwieldy, though, so keep an eye out for shorter options, like a miniature six-inch ruler. You may also want to grab a pack of assorted highlighters, which are great for easily color-coding noteworthy phrases or paragraphs.
To take your book annotations further, consider including sticky notes, note cards, and annotation tabs among your supplies. These are all useful tools for including longer thoughts without cramming a page or making annotations without physically marking up the text. Plus, book annotation tabs make it fast and convenient to find sections where you left a lot of notes. Or, if you're trying to keep your notes entirely separate, don't forget a notebook for all your observations.
Annotating Informative Texts
When you're reading any kind of educational or informative book, annotation helps engage your brain by making studying more interactive. Plus, leaving yourself notes and bookmarks essentially creates a study guide as you go, so you know which chapters, pages, and passages to revisit when you want to review what you've learned.
To get the most out of an informative text, here are a few key ways to use annotation to your advantage. First, be sure to highlight any must-remember points. You can also mark passages you need clarification on, so you know where to dive deep or ask for outside help. By the same token, consider underlining moments where an explanation clicked for you, so you can cement the whole concept in your brain.
Sometimes, you may run across new ideas that aren't explained in the book itself. Mark any references you want to research more later, like unfamiliar scientific principles, mythological figures, or historical events. You can even broaden your vocabulary this way by tagging new words you didn't know before. In no time at all, your book will become more than the sum of its parts as you turn it into an index for your own education and growth.
Annotating Books Just For Fun
When it comes to annotating a book just for funsies, the options are nearly limitless. Highlight a favorite quote or a sensory detail that made your breath catch. Note down examples of successfully paced dialogue. Point out moments when someone seemed to behave out of character, and why you think so. Underline recurring imagery and motifs, then see if you can identify their significance as you read.
You can also record bigger ideas in your annotations, like plot predictions. Think you know who committed the murder or how the author is going to reveal a big twist? Make a note. Later, you can look back and see if you got it right. Sometimes, a book may even give you an idea for your own project. Go ahead and write it down in your annotations so you can keep reading without losing that spark of inspiration. And if you're the artistic type, there's no rule saying you can't draw in the pages of a book. Turn your favorite tome into a one-of-a-kind illuminated manuscript by doodling in the corners and margins.
In the end, book annotation is what you make of it. There are no hard and fast rules, just the gut feeling that something matters. Anytime a word, phrase, or plot development makes you pause, think about why it caught your attention. It's probably worth annotating!
Read this next: 13 Ways To Declutter And Organize Your Closet

How to annotate any website
Take notes, make suggestions, and collaborate with others.
By David Nield | Published Mar 30, 2024 2:11 PM EDT

The web doesn’t have to stay fixed and static. With the right tools, you can type and scribble over the websites you visit, adding all kinds of annotations for all kinds of purposes. Maybe you want to leave notes for yourself or maybe you’re working on a project with others and need to leave notes on a page.
How you go about this varies depending on your browser. It isn’t difficult to do with most of the popular browsers, though you’ll probably need a third-party add-on. The only browser that’s really left out is Apple Safari , which doesn’t offer native annotation tools or any decent extensions—at least on the desktop, which is our focus here.
Google Chrome

Annotation isn’t a built-in feature with Google Chrome , but you’ve got plenty of third-party extensions to choose from that’ll add the functionality. One of our favorites is simply called Annotate : Install the extension, sign up for a free account, and you’re ready to go. You get a floating Annotate icon on the right of the browser window as you navigate around the web, and you can click on this to bring up the annotation tools.
You can scribble on top of web pages, add in text, and temporarily highlight certain sections too. It’s perfect if you’re running a real-time presentation, as basic presentation tools are built right in, and you can also save pages for later. If you need more tools (like shapes), and longer presentation times (above 12 minutes), you can get a Pro account for $35 a year.
Also worth a mention is Awesome Screen Recorder & Screenshot . As its name suggests, this is first and foremost a screenshot tool, but when you’ve grabbed images of websites, you can easily annotate them in a host of ways. Once you’ve captured some or part of an image, you can jump to the annotation workspace in a couple of clicks, where there are tools like pens, text boxes, and shapes to play around with.
Like Annotate, Awesome Screen Recorder & Screenshot comes with some simple presentation tools built right in, and has a premium subscription plan (from $5 a month) available if you need more tools—such as stickers, callout boxes, and watermarking. You even get a small amount of cloud storage space for free, making it easy to sync your annotated website grabs between devices.
Microsoft Edge

Full marks to Microsoft Edge , which has native annotation tools integrated into it—you don’t have to rely on a third-party extension tool if you’re using Edge. However, the tools aren’t quite as advanced as they are with some separate add-ons, so you might find you need some extra help after all.
The website annotation tools are connected to the screenshot feature: Click the three dots (top right), then Screenshot , and you’ll be asked if you want to grab an area of a page or the page in its entirety (including the parts you can’t see on screen). Once you’ve made your choice, a new window pops up on screen with the capture inside it.
Click Draw to start scribbling—if you click the arrow just to the side of Draw , you can change the color and thickness of your digital pen. There’s also the Erase tool, if you want to remove any of the writing you’ve put on top of the page. The options in the top right corner let you save the image, copy it to the clipboard, or share it to other apps.
If that’s not quite enough for you, Nimbus is definitely worth a look. It supports capturing single screenshots and longer screen recordings, and they can be embellished with drawings, shapes, text, and arrows. There’s plenty of functionality included for free, but for $5 a month you can get some additional features, such as watermarking options.
Mozilla Firefox

As with Google Chrome, there’s no native website annotation function in Mozilla Firefox , but you can find several third-party extensions to do the job for you. Out of the ones we’ve seen, Zoho Annotator stands out: Click the extension icon in the toolbar, choose which part of the current website you want to grab, and you’re taken straight to the annotation screen.
All the key tools you might need are included here, letting you add shapes, lines, text, and arrows on top of the page you grabbed. When you’re done, the resulting file can be easily copied to the clipboard, saved to disk, or shared to other apps. The add-on is completely free to use, and you don’t even need to register an account.
Another similar tool worthy of your attention is Memex , which is designed primarily to help you with research projects (though you can actually use it for anything you like). The focus here is on selecting sections of websites, adding comments to them, and sharing them with other people—just as you might do with a document you were collaborating on with a group of people over the web.
The extension lets you save webpages into several custom spaces, pick out particular sections from pages, and add images and comments to them. It works with videos, PDFs and social media posts as well, so it’s a tool that’s comprehensive as well as slick. You’re able to save up to 25 pages per month free of charge, and after that you’ll need to pay from $6 a month for the premium package.

David Nield is a freelance contributor at Popular Science, producing how to guides and explainers for the DIY section on everything from improving your smartphone photos to boosting the security of your laptop. He doesn't get much spare time, but when he does he spends it watching obscure movies and taking long walks in the countryside.
Like science, tech, and DIY projects?
Sign up to receive Popular Science's emails and get the highlights.
- Business & Industry
- K-12 Education & Counseling/Social Work
- Natural Resources & Sustainability
- Certificates
- Conferences
- Lifelong Learning
- Coding Boot Camp
- Cloud Systems Administration Boot Camp
- Data Analytics Boot Camp
- Training Solutions
- UNH Violin Craftsmanship Institute
- Upcoming Business & Industry Workshops
- Upcoming Natural Resources & Sustainability Workshops
- Upcoming K-12 Education & Counseling/Social Work Workshops
- COVID-19 Protocols
- Welcome Information
- Sign-up For Email Updates
Like us on Facebook Follow us on Twitter UNH on YouTube Follow us on LinkedIn Sign Up for Email

Professional Development & Training
Tools & materials.

Teaching Proper Text Annotations & Evidence
This teacher professional development course emphasizes the significance of teaching students of various grade levels the skill of effective text annotation and explains its importance in helping them interact more deeply with the text. Participants will understand how to guide students in using context clues and text annotation to enhance their comprehension of reading assignments. Furthermore, the course provides insights into how students can employ annotation to answer assessment questions.
By the end of the course, you will have planned for the strategies and skills you will be teaching your students and will be ready to implement the ideas into your classroom using the provided resources, templates, and plans in this course.
Requirements:
Hardware Requirements:
- This course can be taken on either a PC, Mac, or Chromebook.
Software Requirements:
- PC: Windows 10 or later.
- Mac: macOS 10.6 or later.
- Browser: The latest version of Google Chrome or Mozilla Firefox is preferred. Microsoft Edge and Safari are also compatible.
- Microsoft Word Online
- Editing of a Microsoft Word document is required in this course. You may use a free version of Microsoft Word Online, or Google Docs if you do not have Microsoft Office installed on your computer. Model Teaching can provide support for this.
- Adobe Acrobat Reader
- Software must be installed and fully operational before the course begins.
- Email capabilities and access to a personal email account.
Instructional Material Requirements:
The instructional materials required for this course are included in enrollment and will be available online.
Teaching Proper Text Annotations & Evidence
- Open access
- Published: 10 April 2024
The genome of Citrus australasica reveals disease resistance and other species specific genes
- Upuli Nakandala 1 , 2 ,
- Agnelo Furtado 1 , 2 ,
- Ardashir Kharabian Masouleh 1 , 2 ,
- Malcolm W. Smith 3 ,
- Darren C. Williams 4 &
- Robert J. Henry ORCID: orcid.org/0000-0002-4060-0292 1 , 2
BMC Plant Biology volume 24 , Article number: 260 ( 2024 ) Cite this article
Metrics details
The finger lime ( Citrus australasica ), one of six Australian endemic citrus species shows a high natural phenotypic diversity and novel characteristics. The wide variation and unique horticultural features have made this lime an attractive candidate for domestication. Currently no haplotype resolved genome is available for this species. Here we present a high quality, haplotype-resolved reference genome for this species using PacBio HiFi and Hi-C sequencing.
Hifiasm assembly and SALSA scaffolding resulted in a collapsed genome size of 344.2 Mb and 321.1 Mb and 323.2 Mb size for the two haplotypes. The nine pseudochromosomes of the collapsed genome had an N50 of 35.2 Mb, 99.1% genome assembly completeness and 98.9% gene annotation completeness (BUSCO). A total of 41,304 genes were predicted in the nuclear genome. Comparison with C. australis revealed that 13,661 genes in pseudochromosomes were unique in C. australasica . These were mainly involved in plant-pathogen interactions, stress response, cellular metabolic and developmental processes, and signal transduction. The two genomes showed a syntenic arrangement at the chromosome level with large structural rearrangements in some chromosomes. Genetic variation among five C. australasica cultivars was analysed. Genes related to defense, synthesis of volatile compounds and red/yellow coloration were identified in the genome. A major expansion of genes encoding thylakoid curvature proteins was found in the C. australasica genome.
Conclusions
The genome of C. australasica present in this study is of high quality and contiguity. This genome helps deepen our understanding of citrus evolution and reveals disease resistance and quality related genes with potential to accelerate the genetic improvement of citrus.
Peer Review reports
Citrus are among the most valued fruits and are cultivated in more than 140 countries in the world [ 1 ]. There are six wild citrus species which are endemic to Australia. Citrus australasica F.Muell (Australian finger lime) is naturally found in southeast Queensland and northern New South Wales and commercially grown in a number of countries around the world. C. australasica is unique among the citrus with finger shaped cylindrical fruits with a distinct pulp which resembles a caviar [ 2 ]. The acidic fruit are often used to prepare jams, sauces and drinks, and dried peel is being used as a spice [ 3 ]. A high natural phenotypic diversity has been recorded for this species with over 65 cultivars described from the wild [ 4 ]. Many cultivars are also being developed by hybridization of C. australasica with other citrus species [ 3 ] and collectively these accessions have been vegetatively propagated by grafting onto a range of different rootstocks [ 5 ]. These accessions are diverse in skin colour [ 2 ], volatile constituents [ 6 ], phytochemical composition of the fruits [ 7 ], taste and seediness of the fruits, and size and shape of the trees [ 5 ]. Sexual compatibility between C. australasica and other citrus has led to the development of hybrids such as Blood lime ( C. limonia Osbeck X C. australasica ), Sunrise lime [( C. australasica X Fortunella sp. (Champ. ex Benth.) Swingle) X C. reticulata )], Sydney hybrid ( C. australasica X C. australis Planch.), Faustrime [ C. australasica X ( C. aurantifolia (Christm.) Swingle X F. japonica (Thunb.) Swingle))], and Minnie Finger Lime ( C. inodora F.M. Bailey X C. australasica ) [ 8 , 9 ].
Huanglongbing (HLB) disease is one of the most devastating diseases causing severe yield reductions and economic impacts to citrus industries [ 10 ]. The disease has caused large scale disruptions in citrus industries in more than 40 countries around the world including those in Asia, Africa and all citrus growing states in the United States [ 11 , 12 ]. HLB is caused by three species of closely related bacteria: Candidatus liberibacter asiaticus (CLas), C. liberibacter africanus (Claf) and C. liberibacter americanus (CLam), with the first strain of these species being the most destructive and widespread around the world. The disease is transmitted by an insect vector; Asian citrus psyllid ( Diaphorina citri ) [ 13 ]. Most commercial cultivars are susceptible to the disease, resulting in reduced yield and a deterioration of quality [ 14 , 15 ]. Tolerance to HLB disease has been identified in a limited number of citrus accessions and related genera including some citrus cultivars with citrons as a parent [ 16 ], Sugar Belle mandarin hybrid [ 17 ], C. maxima (Burm.) (pummelo) [ 18 ], C. hystrix DC. (Kaffir lime) [ 19 ], C. latipes Swingle (khasi papeda) [ 20 ], C. Cavalerie H. Lev. ex Cavalerie ‘2586’ [ 21 ], C. trifoliata L. (Syn. P. Trifoliata ) [ 22 ], and some accessions of Murraya paniculata (L.) [ 23 ]. Australian wild limes such as C. australasica , C. australis , C. glauca (Lindlay) Burkill, C. inodora and their hybrids, have been reported with tolerance/resistance/partial resistance to this disease [ 15 , 23 , 24 , 25 , 26 ].
High quality reference genomes provide a key resource to better understand the genetics underpinning complex plant agronomical/physiological traits. Here we present the high quality, haplotype resolved genome of C. australasica , assembled with PacBio Hifi reads, and Hi-C reads and further manually curated based on our previously assembled C. australis genome. The structural and functional characterization of this C. australasica genome was used to explore important defense related genes, the genetic variation present within five cultivars of the species, and for comparative genomic analysis against the haplotype resolved genome of C. australis [ 27 ]. The genome presented in this study should help to accelerate the genetic improvement of citrus by providing a valuable foundation to study genetic resistance to HLB, better understand the genomic diversity present within the species, and examine comparative biology and evolutionary relationships with other citrus species.
Sample collection, DNA and RNA extraction and sequencing, Hi-C sequencing
Young fresh immature leaves of five cultivars of Citrus australasica (cultivar names and their morphological characteristics are given in Table S1 ) were collected from Herbalistics Pty Ltd private orchard located in Maroochy River, Queensland, Australia. Cultivar 2 (Rainbow) was used for genome assembly and other four cultivars were used for variant analysis. Citrus species reported in this study were given their botanical authorities according to Mabberly, 2022 [ 28 ]. Genomic DNA was extracted from pulverized leaf tissues using a CTAB (Cetyltrimethyl ammonium bromide) DNA extraction protocol [ 29 ]. HiFi reads from Rainbow were generated from two PacBio Sequel II SMRT cells at The Australian Genome Research Facility (AGRF), The University of Queensland, Australia. Total RNA from Rainbow was extracted from pulverized leaves using Trizol and Qiagen kit methods [ 30 ] and was sequenced at the AGRF, The University of Queensland, Australia. Snap frozen fresh young leaves from the same individual were sent for Hi-C sequencing at The Ramaciotti Centre for Genomics, University of New South Wales, Australia. The Hi-C library preparation was done using Phase Genomics Proximo Plant Hi-C version 4.0. Illumina sequencing for other four cultivars were performed at AGRF, Victorian comprehensive cancer centre, Melbourne.
Genome assembly and annotation
Genome assembly was performed with PacBio high fidelity (HiFi) reads and Hi-C reads using the Hifiasm Denovo assembler [ 31 ]. Detailed assembly pipeline with different parameters in HiFiasm algorithm can be referred in our previous publication [ 27 ]. Contig assemblies generated by hifiasm was scaffolded by Hi-C data using three aligners [Bowtie2 [ 32 ], Chromap [ 33 ], and BWA [ 34 ]], and three latest scaffolding techniques [SALSA [ 35 ], YaHS [ 36 ], pin_hic [ 37 ]. The details for scaffolding are given in Figure S1 and Table S2 and Method S1. The BWA aligner + Arima mapping ( https://github.com/ArimaGenomics/mapping_pipeline ) + SALSA scaffolding pipeline was selected as the final assembly based on the high contiguity, and the presence of telomeres in scaffolds. In this pipeline, Hi-C reads were first mapped to the Hi-C integrated Hifiasm draft assembly with BWA aligner using Arima-HiC mapping pipeline. BWA first built an index of the contig assembly. Read pairs generated from sequencing were first independently aligned to the reference genome (as single-ends) using BWA-MEM using an end-to-end algorithm. Then 5’-side of the chimeric reads were filtered using filter five end.pl script. After filtering, the filtered single-end Hi-C reads were paired using “two_read_bam_combiner.pl,” which output a sorted, mapping quality filtered, paired-end BAM file for each lane of the sequencing. Read groups were added to the BAM file using Picard tools. Then the paired-end BAM files that were sequenced via two Illumina lanes from the same library were merged and PCR duplicated were removed using Picard tools. The final BAM file was converted to a BED file using bamToBed command from the Bedtools package and was sorted to be used by SALSA. SALSA was used in -e option by specifying the restriction site for the Sau3AI/DpnII endonucleases (GATC). Assigning of contigs to pseudo chromosomes were further supported by manual curation as explained in Table S3 .
Genome assembly and annotation completeness was determined using BUSCO in viridiplantae lineage (BUSCO v5.2.2) [ 38 ] and the contiguity was assessed using QUAST (version 5.0.2) [ 39 ]. Scaffolds were aligned with the previously published genome, C. australis [ 27 ] to assign them to pseudo chromosomes using D-Genies v.1.4 [ 40 ]. The telomeres in pseudochromosomes were identified manually and by telomere identification toolkit (tidk) ( https://github.com/tolkit/telomeric-identifier ). Ribosomal RNA gene repeats (5s/5.8s/18s/28S rRNA) and satellite repeats at the ends of the scaffolds were detected by nucleotide BLAST in NCBI. The K-mer analysis was performed using Jellyfish (v2.2.10) [ 41 ] and Genomescope [ 42 ]. Repeat elements in the genome were de novo detected by Repeatmodeler2 version 2.0.1 [ 43 ] followed by soft masking by Repeatmasker version 4.0.9_p2 [ 44 ]. Quality and adapter trimmed RNA-seq reads were aligned to the soft masked genome using HISAT2 [ 45 ]. Structural and functional annotations were performed as mentioned in our previous publication [ 27 ]. Gene prediction was performed using Braker3 ( https://github.com/Gaius-Augustus/BRAKER ).
Structural and functional differences between C. australasica and C. australis genomes
Orthologous gene clusters enriched in C. australasica and C. australis were identified using Orthofinder algorithm incorporated in Orthovenn3 [ 46 ]. Pairwise sequence similarities among the longest protein isoform of each protein coding gene of the two species were calculated with an e-value cut off of 1e − 5. The structure of orthologous clusters was defined with an inflation value of 1.5. Unique and shared gene families in C. australasica collapsed and haplotype genomes were identified using the above same parameters. The biological processes and molecular functions associated with unique genes were retrieved from combined graph module and the associated pathways were identified from KEGG analysis in OmicsBox 3.0.30. The structural and sequence differences between the two soft-masked genomes of C. australis and C. australasica at the whole genome level were predicted using Synteny and Rearrangement Identifier (SyRI) [ 47 ]. The whole genome alignments were conducted with nucmer with --maxmatch to get all alignments between the two genomes including the -c 100 -b 500 -l 50 parameters. The alignments were filtered using the delta-filter tool and subsequently converted to tab-delimited files using the show-coords command. Syri was used with default parameters and the genomic structures predicted by syri was plotted by plotsr.
The variant analysis for five different C. australasica cultivars
All analysis was undertaken using CLC Genomics Workbench v23,0.4 (Qiagen, USA). Illumina reads from the five cultivars (Table S1 ) were quality trimmed at 0.01 quality limit (Phred score of 20 and above). They were mapped to the chromosome level assembly of an unmasked reference genome of Rainbow. The reads were mapped using the “map reads to reference” algorithm and the mapping options of Match score (1), Mismatch cost (2), Linear gap cost [Insertion cost (3), Deletion cost (3)], Auto-detect paired distances – yes, Non-specific match handling – map randomly. Mapping was performed at four different mapping stringencies (Figure S2 ) to select the best mapping setting for the read alignment based on the mapping percentage. The mapping setting of Length fraction of 0.9 and similarity fraction of 0.9 were used as the optimal mapping setting for all the read alignments. The duplicated reads derived from PCR amplification during the sequencing library preparation were removed from the read mappings to avoid creating false positive SNPs in subsequent variant analysis. Structural variant analysis was performed to identify erroneous variants involving insertions, deletions, inversions, translocations, and tandem duplications. Then the local realignment was performed to improve the alignments of the reads in the initial read mapping typically around the erroneous INDEL regions with respect to the reference. The read mappings were then subjected to Fixed ploidy variant detection (FPVD) tool using five minimum frequencies (MF) (Figure S3 ) and 20% MF was selected as the optimal MF to capture the highest number of single nucleotide variant positions (SNVs). FPVD was performed at the settings of minimum coverage (10), minimum count (2) and minimum frequency (%) (20%). The number of homozygous SNVs (homozygous positions) filtered at 100% variant frequency and the number of heterozygous SNV positions with the frequency ranged between 20 − 80% for the two alleles were calculated in all the cultivars in the whole genome and in the CDS regions with respect to the reference Rainbow genome. The heterozygosity for each cultivar was determined by heterozygous SNV positions as a percentage of Rainbow genome size (344 Mb; estimated by genome assembly).
The identification of genes related to metabolic pathways and defense in C. australasica
The key genes involved in the biosynthesis of terpenoids, and anthocyanins were identified by KEGG pathway analysis [ 48 ] using Omics Box 3.0.30 and were further verified by BLAST homology search of other citrus species with an e-value of 1.0E-5, in CLC Genomics Workbench 23.0.4 as mentioned in our previous publication [ 27 ]. The antimicrobial proteins were identified based on functional annotation BLAST descriptions and stable antimicrobial peptide (SAMP) homologs were detected by BLAST homology searches against the published SAMP sequence of C. australasica [ 26 ]. The variations between the gene sequences and the corresponding amino acid sequences of SAMP of C. australasica were identified using Clone Manager Ver. 9. The whole genome short reads of C. australasica cultivars were mapped to the SAMP homolog of Rainbow genome in CLC using the map reads to reference option with mapping settings of Match score (1), Mismatch cost (2), Linear gap cost [Insertion cost (3), Deletion cost (3)], Length fraction of 0.9 and similarity fraction of 0.9. Defense related genes were mapped onto chromosomes using shinyCircos-V2.0 [ 49 ]. Collinear genes in C. australasica genome were identified using MCScanX toolkit. For MCScanX, the homology was first searched using the longest isoform of protein coding genes using BLASTP with an e-value threshold of 10 − 10 [ 50 ]. The collinear file was then trans-formatted for micro-synteny view using TBtools [ 51 ].
Chromosome scale genome assembly of C. australasica
Hifi reads with Q33 median read quality were generated from two PacBio SMRT cells yielding 39 Gb (115X) and 37 Gb (108X) of sequence respectively. Hi-C paired end Illumina reads generated from two lanes yielded a total of 768 M reads with a total of 116 Gb data. Hifiasm was run with two options; Hifi reads only and the Hi-C integrated (Hifi reads + Hi-C reads) option (Table S4 ). The Hifi-reads-only assembly yielded a slightly better contig assembly with a total size of 407 Mb (1,569 contigs), having a 99.3% complete BUSCO and an N50 of 31.7 Mb. The Hi-C integrated Hifi assembly yielded a collapsed assembly with 2,224 contigs (with a total size of 436 Mb), a 99.1% complete BUSCO and an N50 of 31.4 Mb. The two assemblies were independently subjected to scaffolding with Hi-C data.
Scaffolding was performed with Hi-C data using three scaffolding tools using two different pipelines (Figure S1 ). The results were compared by checking the telomeres at the ends of the scaffolds, the N50 for the whole assembly and by aligning the scaffold assemblies with the previously published genome of C. australis [ 27 ] (Table S2 a- S2 g). The Hi-C integrated assembly, assembled by BWA + Arima mapping and the SALSA pipeline was selected as the final best assembly based on the high contiguity, completeness, and the presence of telomeric repeats at the ends of the scaffolds (Method S1, Table S2 e). The scaffolds that could be assigned to chromosome level based on the alignments with C. australis are shown in Table S2 e. The scaffold assembly generated a total of 2,208 scaffolds (with a total length of 436 Mb) with a 99.1% complete BUSCO and an N50 of 33.5 Mb (Table S5 ).
The top eleven longest scaffolds in the collapsed genome were selected to represent the nine pseudochromosomes as they had the same total BUSCO score (99.1%) as the whole assembly and were anchored to pseudochromosomes by aligning with C. australis genome. (Table S5 ). The pseudochromosomes were labeled as Chr1-Chr9 based on the order of C. australis genome. The orientations of the C. australasica chromosomes were determined based on those of C. australis chromosomes (Figure S4 a). Seven pseudochromosomes were composed of one contig. Chr8 was composed of two contigs which were joined by Hi-C. Chr4 was generated by manually joining three scaffolds (manual adjustments) (Table S3 ). Four pseudochromosomes had telomeres at both terminals, three pseudochromosomes had telomeres at one terminal, one pseudochromosome had one telomere at one end and the other at the peri-terminal region, and one pseudochromosome with no telomeric sequences at either end (Figure S4 c). The N50 of the chromosome scale assembly was 35.2 Mb (Table S5 ). There were some scaffolds (SC9, SC10, SC8, SC11 and SC20) with 5.8 S and 28 S rRNA gene repeats at the terminal regions and some scaffolds (SC5, SC9) with high copy number tandem arrays of satellite DNA repeats at their terminal regions (Table S3 ).
Dotplots of scaffolds vs. contig assemblies revealed that some medium sized scaffolds (5 Mb – 1.4 Mb) might belong to the nuclear genome (Figure S4 b). Those scaffolds and two other small scaffolds (0.85 Mb and 0.7 Mb) with telomeres at the terminal regions were included in the final assembly as unplaced scaffolds as they might be parts of the nuclear genome The assembly containing nine pseudochromosomes and the unplaced scaffolds, totaling 344.2 Mb, is henceforth referred to as the “nuclear genome” of C. australasica . The alignment of scaffolds with the C. australasica chloroplast genome revealed the sites of insertion of chloroplast fragments in the nuclear genome (Figure S5 a and S5 b). Some scaffolds smaller than 1.4 Mb might belong to the chloroplast genome (Figure S5 c) and were excluded from the nuclear genome assembly. The heterozygosity of the genome was estimated as 1.28% by K-mer analysis.
The two haplotypes were also assembled using the same pipeline and some manual adjustments were done based on their homology with the collapsed genome. The orientation and chromosome numbers of the chromosome scale pseudomolecules were determined with respect to the collapsed assembly (Figure S6 , Table S3 ). The two haplotypes had 98.9% and 99% BUSCO and an N50 of 32.7 Mb and 34.4 Mb for hap1 and hap2 respectively.
Structural annotation of C. australasica genome
The genome was annotated for repeat elements, and protein coding genes. A large portion of the collapsed genome was covered by interspersed repeats (54.6%) with 34.5% unclassified repeats, 2.64% DNA transposons and 17.5% retro transposons. LTR elements were the dominant type of retroelements where Copia and Gypsy elements were present in equal proportions (6.78%) and Pao elements were found in a very small percentage (0.03%). The other types of repeat elements such as rolling circles (0.42%), small RNA repeats (0.67%), satellite repeats (0.39%), simple repeats (0.97%) and low complexity repeats (0.2%) were found in small proportions in the whole nuclear genome (Table S6 ). RNA-seq trimmed reads (320 million reads, 44 Gb representing 129X coverage of the genome) were used for gene prediction. A total of 36,597 genes were predicted in nine pseudochromosomes of the collapsed genome while 30,050 and 34,139 genes were found for the hap1 and hap2 nine pseudochromosomes respectively (Table 1 ). The annotation statistics of the nuclear genomes (including the unplaced scaffolds) are given in the Table S7 .
Functional annotation of C. australasica genome
The CDS sequences of the collapsed genome (45,935) and the two haplotypes (39,651 of hap1 and 41,516 of hap2) were independently annotated obtaining BLAST hits and GO terms associated with the CDS sequences. BLAST hits were obtained for 40,105 CDS sequences in the collapsed genome and for 35,286 and 39,395 sequences in hap1 and hap2 genomes respectively. Of the sequences with BLAST hits, 21,104 CDS in the collapsed genome, 20,899 CDS in the hap1 genome and 20,966 CDS in the hap2 genome underwent GO mapping and annotation. The majority of the CDS sequences of the collapsed and the two haplotypes received BLAST hits from other citrus species. The highest number of sequences received BLAST hits from C. sinensis (179,114 - collapsed genome, 166,574 - hap1 genome, and 175,964 - hap2 genome), followed by C. clementina (39,949 - collapsed genome, 39,304 - hap1 genome, 39,605 - hap2 genome) and C. unshiu (27,052 - collapsed genome, 26,723 - hap1 genome, 26,784 - hap2 genome) and a small percentage of sequences from other species (Figure S7 a, S7 b, S7 c). Sequences annotated with IPS, their families distribution, GO-levels and enzyme codes of the collapsed genome are shown in Figure S7 d, S7 e, S7 f. The coding potential assessment of the CDS sequences in the collapsed genome with no BLAST hits (5,830) revealed 99.8% and 99.1% CDS with coding potential based on the models from coding and non-coding sequences of Arabidopsis thaliana and citrus respectively. The coding potential of the sequences with no BLAST hits for the two haplotypes also indicated a high number with coding potential (Figure S8 a, S8 b, S8 c, S8 d).
Structural and functional comparison between C. australasica and C. australis genomes and among C. australasica assemblies
The inference of orthologs from orthovenn3 revealed 19,980 shared orthologous clusters between C. australasica and C. australis corresponding to 48,185 shared genes. The number of unique orthologous clusters (gene families) in C. australasica (870) were higher than C. australis (666) (Fig. 1 a). The 870 unique orthologous clusters of C. australasica included 12,748 unique protein coding genes and the 666 unique orthologous clusters of C. australis contained 4,191 unique protein coding genes. In addition to the unique orthologous clusters, there were 4,487 singletons in C. australasica and 5,566 singletons in C. australis, which had no orthologous genes identified in the other species and they could not be assigned to any cluster within the species. Therefore, the genes in unique orthologous clusters and singletons are henceforth referred to as unique genes in each species. Of them, 13,661 unique genes of C. australasica and 8,121 unique genes in C. australis were within their nine chromosomes.
The functional analysis of the unique genes of C. australasica revealed that they were enriched in biological processes including stress response, protein modification, cellular component organization, response to organic substance, transport and regulation of gene expression with molecular functions such as nucleic acid binding, hydrolase activity, protein binding, catalytic activities, ATP binding, oxidoreductase activity and transition metol ion binding. KEGG pathway analysis showed that the unique gene sequences of C. australasica were primarily involved in purine metabolism (155), thiamine metabolism (145), plant-pathogen interactions (92) (Table S8 ) (out of the total 345 genes related to plant-pathogen interactions in C. australsica , 92 genes were unique), phenylpropanoid biosynthesis (55), diterpenoid biosynthesis (48), and Tryptophan metabolism (44) (Figure S9 ). The 92 unique genes associated with plant-pathogen interactions encode disease resistance proteins [NB-ARC domain containing R proteins, nucleotide binding and leucine rich repeat proteins (NLRs), leucine-rich repeat receptor-like protein kinases (LRR-RLKs)], calcium sensor proteins [calcium-dependent protein kinases (CPDKs), calmodulin (CaM) and calmodulin-like proteins (CMLs)], retrovirus-related pol polyproteins, glycerol kinases, pathogenesis-related protein 1, cyclic nucleotide-gated ion channels, and many other hypothetical proteins. The functional analysis of the C. australis unique protein clusters indicated that they were associated with many biological processes including protein modification, cellular component organization, transport, defense response, phosphate containing compound metabolic process. The KEGG analysis showed that the unique genes in C. australis were mainly involved in purine metabolism (80), plant pathogen interactions (76) and Thiamine metabolism (75) (Figure S10 ).
The orthologs comparison among the three assemblies of C. australasica revealed 3,307 genes unique to collapsed genome, 1,676 unique to hap1 genome and 1,696 genes unique to hap2 genome which are in clusters as depicted in Fig. 1 b. In addition, there were 2,155, 1,610, 1,471 singletons identified in the collapsed, hap1 and hap2 assemblies respectively. There were 21,061 shared gene families containing 76,167 shared genes among the three assemblies. There were 13,801 genes (4,078 gene families) shared between collapsed and hap2 assemblies. 8,667 genes (2,745 gene families) were shared between the collapsed and hap1 assembly and 2,830 genes (841 gene families) were shared between the two haplotypes which were not present in the collapsed assembly. Functional characterization of the collapsed and haplotype assemblies specific genes revealed that they were associated with many different cellular, metabolic, biosynthetic processes, and stress responses (Figure S11 ).

The orthologous gene clusters in C. australasica and C. australis genomes identified using Orthovenn3. (a) The orthologous gene clusters present in C. australis and C. australasica . 19,980 orthologous clusters (48,185 genes) were shared between the two species and 666 gene clusters (4,191 genes) and 870 gene clusters (12,748 genes) were unique to C. australis and C. australasica respectively. (b) Orthologous gene clusters among C. australasica collapsed genome and the two haplotype genomes. 21,061 gene clusters (76,167 genes) were shared by three genomes and 709 clusters (3,307 genes), 445 clusters (1,676 genes), and 476 clusters (1,696 genes) were specific to the collapsed, hap1 and hap2 assemblies
Structural and local sequence variations between C. australasica and C. australis genomes revealed the conserved and rearranged regions of the two genomes (Fig. 2 a). Large inversions were found in Chr4 and Chr5 and small inversions were found in all chromosomes. Translocations and duplications were found in all chromosomes and large-scale translocations and duplications were found in Chr3, Chr4, Chr5, Chr7 and Chr8. A relatively smaller number of rearranged regions were found in Chr6, which was the smallest chromosome in both the species. Local sequence variations such as SNPs (5,437,677), insertions (542,557), deletions (445,565), highly diverged regions (4,915) and tandem repeats (137) were annotated in both syntenic and rearranged regions of the two genomes with the help of whole genome alignments (Fig. 2 a). The two haplotype assemblies of C. australasica were found to have many structural variations across the nine pseudochromosomes (Fig. 2 b). A large inversion was present in chr4, and small-scale inversions were found in all chromosomes. Translocations were prominent in chr4, and duplications were prominent in Chr5, Chr7 and Chr8.

Structural genomic differences between C. australasica and C. australis genomes and C. australasica haplotypes. Syntenic regions are indicated in grey color and unaligned regions are shown in white color. Different types of rearranged regions are shown with respective color codes. The analysis was done using Synteny and Rearrangement Identifier (SyRI) (a) The structural comparison between C. australasica and C. australis collapsed assemblies (b) The structural differences between C. australasica haplotypes
Genetic diversity in different C. australasica cultivars
The genetic diversity within C. australasica was determined using five cultivars, including Rainbow for which the genome was assembled in the present study. Illumina reads for the five cultivars (between 9 and 13 Gb data with coverage ranging from 28X – 39X genome size of C. australasica ) were used in the fix ploidy variant analysis using Rainbow as the reference (Table S9 ). Different variant types (insertions, deletions, single and multi-nucleotide variants, and replacements) ranging between 1.9 M and 3.5 M were found for the five cultivars where many of them were SNVs. At the whole genome level, the total number of SNV positions which include heterozygous SNVs and homozygous SNVs (at 100% variant frequency) were in the range between 1.6 M and 2.8 M (Figure S12 ). The total number of SNV variant positions in CDS regions were in the range between 0.1 M and 0.18 M for the five cultivars. Based on the total SNVs, C. australasica cv 3 (Red champagne) and C. australasica cv 1 were the most and less divergent cultivars respectively with respect to Rainbow (Figure S12 ). The heterozygosity estimated based on the Rainbow genome size was the highest for C. australasica cv 3 (Red champagne) (0.56) and the lowest for C. australasica cv 1 (0.35) (Table 2 ).
A selected set of important genes in C. australasica
Disease resistant genes.
A wide array of antimicrobial proteins/peptides (AMPs) were identified through functional annotation in C. australasica collapsed genome. Three antimicrobial genes [g22065 (Chr6), g32276 (Chr8), g34118 (Chr9)] coding for peptides containing stress-responsive A/B barrel domain were identified in the collapsed genome (Fig. 3 ). Of these three genes, g34118 was identified as a homolog to the previously detected short version of stable AMP (SAMP) in HLB resistant citrus species (204 bp) [ 26 ]. The gene g34118 was transcribed into three transcripts of 549 bp, 462 bp, and 330 bp. The third transcript having 330 bp (encoding 110 aa) showed the highest homology with a major portion of the 204 bp SAMP sequence (encoding 67 aa) of the previously reported SAMP of C. australasica with twelve single nucleotide polymorphisms. Similarly, the SAMP homologs, identified in Chr9 of the two haplotypes (hap1; g27559 of 330 bp and, hap2; g31668 of 330 bp) showed 100% identity with the corresponding collapsed SAMP gene (Figure S13 a, S13 b). The SAMP identified in the previous study had two cysteine residues, whereas the Rainbow SAMP homologs had no cysteine residues. In addition to the SAMP sequences, two other types of antimicrobial peptides having the stress-responsive A/B barrel domain were identified in the two haplotypes similar to the collapsed genome (Table S10 ).
The re-annotation of the C. australis genome [ 27 ] using Braker3 identified one SAMP homologous gene encoding two transcripts which are longer than those of C. australasica . The alignment of these two transcripts with C. australasica SAMP sequences showed a homology with them, however it was not as high as the sequence homology of C. australasica SAMP sequences (Figure S14 ). Furthermore, the alignments of the 110 aa antimicrobial peptides found in Rainbow and other HLB resistant and susceptible citrus species with 67 aa of SAMP sequence of C. australasica showed a high aa similarity among all of them (Figure S15 ).
In addition to stress-response A/B barrel domain-containing protein, other types of AMPs such as defensins, thionins, non-specific lipid transfer proteins, snakins, hevein-like proteins, knottin-type peptides were identified in the genome. Other defense-related genes including cysteine-rich receptor-like protein kinases (CRKs), of which 14 genes encoding CRK 10, one encoding CRK 25 and others encoding other types of CRKs were identified in the genome (Table S11 ). There were eleven genes for pathogenesis related (PR) proteins of which three were PR-1 proteins (Fig. 3 , Table S12 ). In addition, the annotation identified 61 leucine rich repeat proteins (LRR) genes, 13 guanine nucleotide-binding proteins (Fig. 3 , Table S13 ), 34 glutathione-S-transferase genes, 28 oxoglutarate (2OG) and Fe(II)-dependent oxygenases, 22 cellulose synthase genes, 26 β-1,3-Glucanase genes, and many other genes related to anthocyanins, terpenoids, amino acids (phenylalanine, tyrosine, and tryptophan) and antioxidants (flavonoids, carotenoids, tocopherols) in the Rainbow genome.

The Circos plot indicating the chromosomal locations of defense related genes in the C. australasica genome. Purple indicates the genes encoding leucine rich repeat proteins (LRR), red indicates the genes encoding pathogenesis related (PR) proteins, blue indicates the genes encoding guanine-nucleotide binding proteins and green indicate the genes encoding antimicrobial proteins (stress-responsive A/B barrel domain containing proteins, defensins, thionins, non-specific lipid transfer proteins, snakins, hevein-like proteins, knottin-type proteins). The innermost links indicate the collinear genes within the genome identified by whole genome self-homology and gene location information. Different colors for the links indicate the chromosome of origin of the links. Some collinear genes were identified within the same chromosome while others were identified between chromosomes. Collinear genes represent homologous genes in conserved orders on corresponding chromosomes. Circos plot was generated using shinyCircos-V2.0 and TBtools
Volatile compounds encoding genes
KEGG pathway analysis identified 112 genes involved in terpenoid backbone biosynthesis (Table S14 ), 82 genes for monoterpenoid biosynthesis (including geranyl phosphate, geraniol, linalool, myrcene, limonene, α-terpineol, camphene, neomenthol) (Table S15 ), 89 genes for diterpenoid biosynthesis (Table S16 ) and 48 genes for sesquiterpenoid and triterpenoid biosynthesis (α-farnesene, β-farnesene, germacrene, valencene, β-carophyllene, β-amyrin, α-amyrin, α-humulene) (Table S17 ) in the Rainbow genome.
Curvature thylakoid protein genes
A total of 8,314 genes encoding curvature thylakoid proteins (CURT1) which belong to four isoforms were identified in the genome. There was one gene encoding CURT1A on Chr5 with 495 bp, one gene encoding CURT1B in Chr5 having 510 bp and one gene for CURT1C in Chr1 transcribed into two CDS sequences (465 bp and 444 bp). There were 8,311 genes encoding CURT1D proteins (Table S18 ), with majority of them being identified within the 9 chromosomes. The lowest number of genes (572) were identified in Chr9, and the largest number of genes were identified in Chr8 (1,619) with open reading frames in the CDS sequences. The CURT1D proteins were present as large tandem arrays of gene clusters within the chromosomes with the smallest gene having 252 bp (encoding 84 aa) and the largest gene having 30,726 bp (encoding 10,242 aa). No CURT1 genes were identified in Chr3 and Chr6. In contrast, only 357 CURT1 genes were found in the C. australis genome (Table S19 ).
Red/orange coloration related genes
C. australasica cv Rainbow has a red/yellow warty skin and pink colored clear vesicles inside the fruit. Anthocyanins and β-citraurin are the two major pigments involved in the orange-reddish color of citrus fruits. The structural and regulatory genes involved in anthocyanin production were identified in C. australasica genome. Structural genes involved in the production of enzymes needed for the biosynthesis of anthocyanins are depicted in Figure S16 . A group of upstream genes encoding CHS, CHI, F3H and downstream genes encoding F3’M, F3’5’H, DFR, ANS, UFGT were known to play major roles in pigmentation [ 52 ]. The annotation identified 13 CHS genes, 3 CHI genes, 5 F3H genes, 2 F3’M genes, 1 F3’5’H gene, 2 DFR genes, 1 ANS gene, 2 genes of UFGT (Figure S16 ) (Table S20 ). A total of 11 genes involved in the biosynthesis of major anthocyanins including pelargonidin, pelargonidin-3-sambubioside, cyanidin, cyanidin 3-glucoside, cyanidin 5-glucoside, cyanidin 3,5-diglucoside, cyanidin-3-sambubioside, delphinidin, delphidin-3-sambubioside, delphinidin 3-glucoside were identified in the genome (Fig. 4 ).
Four types of regulatory genes are involved in anthocyanin gene expression in plants. There were two Ruby homologs in Chr6, one bHLH (Noemi) homolog on Chr5, five WD-40 protein encoding genes on Chr1, Chr2, Chr4 and Chr5, and 43 WRKY TF genes (Table S21 ) scattered on all chromosomes in the Rainbow genome.

Anthocyanin biosynthetic pathway of C. australasica reproduced with permission of Kanehisa Laboratories [ 48 ]. The main components in anthocyanin pathway are shown with red asterisks. Phenylalanine undergoes catalysis via a series of steps producing Cinnamic acid, Coumaric acid, 4-Coumaroyl-CoA, Naringenin chalcone, Naringenin, Dihydrokaempferol, Dihydroquercetin, Dihydromyricetin, Leucoanthocyanidins, Anthocyanidins, and Anthocyanins. The major types of anthocyanins identified from the annotation of C. australasica by KEGG analysis were pelargonidin, pelargonidin-3-sambubioside, cyanidin, cyanidin 3-glucoside, cyanidin 5-glucoside, cyanidin 3,5-diglucoside, cyanidin-3-sambubioside, delphinidin, delphidin-3-sambubioside, delphinidin 3-glucoside. The pathways were retrieved from KEGG pathway analysis
β-citraurin is encoded by carotenoid cleavage dioxygenase 4 (CCD4) gene. There were two CCD4 genes identified in collapsed, hap1 and hap2 genomes on Chr7 and Chr8 and one additional gene was identified on Chr6 of the hap1 genome (Table S22 ).
Here, we present the first report of a haplotype resolved chromosome level assembly of C. australasica , which is one of the most important endemic limes in Australia. The assembly was produced de novo and further manually curated with the help of a previous C. australis genome to achieve a more complete chromosome level assembly. With that, 95% of the nuclear genome of the collapsed assembly, 95% of the hap1 genome and 96% of the hap2 genome could be anchored to chromosome level. The high N50s of the final chromosome level assemblies for collapsed (35.2 Mb), hap1 (32.7 Mb) and hap2 (34.4 Mb) indicate high contiguities of the assembled genomes. The high assembly and annotation BUSCO for the collapsed and two haplotypes indicated that the assembled genomes and annotated gene sets had captured most of the single-copy orthologs conserved in the viridiplantae lineage. We also compared different scaffolding pipelines using three recent scaffolding tools (SALSA, YaHS, Pin_hic) and different Hi-C read aligners (bowtie2, chromap, bwa) to select the best pipeline to generate chromosome scale assemblies that were complete, contiguous, and accurate. The accuracy was determined by checking the telomeres, N50s and mapping the scaffolds against the C. australis genome. Manual inspection of the assemblies helped the identification of interior telomeres in several instances with the YaHS tool. The joining of the contigs were similar and accurate for SALSA and Pin_hic when those tools were used with BWA aligner to align the Hi-C reads through the Arima mapping pipeline. We proceeded with BWA + Arima mapping + SALSA for scaffolding the collapsed, hap1 and hap2 assemblies. Although this pipeline resulted in accurate assembly for the collapsed genome, it produced some misassembles (contigs were wrongly oriented) for the haplotypes, therefore, some manual curations were done to correct them. A genome for C. australasica was recently assembled using Oxford Nanopore Technology (ONT) and Hi-C reads [ 53 ]. This genome was not haplotype resolved and the collapsed genome had a contig N50 of only 1.9 Mb. The assembled and phased genome reported in the present study is significantly better in terms of the assembly contiguity, gene completeness and phasing.
Of the nine chromosomes, four pseudochromosomes had telomeres at both ends. The presence of extensive rRNA gene repeats and large tandem arrays of satellite repeats at the terminal regions might be the main reason for not being able to assemble other pseudomolecules as complete chromosomes. Many plant genomes constitute repetitive regions such as transposable elements (DNA TE/ LTR RE), interspersed nuclear elements (SINE/LINE), tandem arrays of satellite repeats and rDNA, which has become a challenge in precisely assembling plant genomes to the chromosome level [ 54 ]. Some repetitive DNA sequences are highly conserved among plants whereas some repeat DNA are specific to some genera, species and even to some chromosomes in the same accession [ 55 ]. Citrus genomes are also characterized by high repetitive contents mainly at centromeric, pericentromeric, telomeric and sub telomeric regions [ 56 , 57 ]. In Chr4, the telomeric repeat at one terminal was not at the very end, instead it was found at a sub-telomeric region, and satellite repeats were found next to the telomeric repeat at that terminal. Previous studies have reported the presence of interstitial telomeric repeats (ITRs) at pericentromeric and sub-telomeric regions [ 58 , 59 ] and it could be possible that C. australasica has an ITR at a sub-telomeric region on Chr4.
Gene family clustering analysis revealed 19,980 shared orthologous clusters between C. australasica and C. australis indicating their conservation in the two species after the species divergence. The corresponding genes of the unique orthologous clusters in each species might have undergone sequence changes over the years of evolution after their divergence from the last common ancestor, and thus have attained new functions. This analysis revealed a high number of unique genes in the C. australasica genome when compared to the C. australis genome. The high number of unique genes might be due to the large number of total genes annotated in the C. australasica genome (7,431 genes more in C. australasica ). The unique genes in C. australasica are primarily involved in resistance to plant pathogens. LRR proteins recognize pathogen effectors and trigger innate immunity in plants [ 60 ]. Calcium, which acts as a secondary messenger in plants and its sensors are important in abiotic and biotic stress resistance [ 61 ]. CDPKs mediate innate immunity in plants by regulating oxidative burst and hormone signal transduction in response to plant pathogens [ 62 ]. Cyclic nucleotide-gated ion channels which regulate the calcium uptake in plants are known to play important roles in stress response, plant immunity and development [ 63 ]. Glycerol kinases are also involved in enhancing immune responses in plants [ 64 ]. Studies have shown that thiamine related genes can enhance the responses to biotic and abiotic stresses in plants [ 65 , 66 ].
The differences in the collapsed and haplotype specific genes identified in C. australasica might be due to the sequence variations present in the two haplotypes. The unique genes identified in the collapsed genome might be due to the sequence variations between the haplotypes resulting in a combined gene being annotated in the collapsed genome. All chromosomal lengths of the collapsed genome are longer than those of the haplotypes, except in Chr7 where the Chr7 in hap2 is longer than the collapsed and hap1. Some genes in the collapsed and hap2 might have been annotated in those additional regions in the chromosomes resulting of them being identified as unique by the orthovenn3 analysis. The collapsed genome may contain one of the alleles of the two haplotypes in the heterozygous regions of the genome and these genes might be represented in the shared gene families between collapsed and each haplotype. In the homozygous regions of the genome, the collapsed assembly might have picked one of the haplotypes alleles, thus these genes might have shared among the three assemblies. Significant structural variations between haplotypes such as insertions in genes, chromosomal rearrangements, allele specific expressions, and presence and absence variations have been studied extensively in previous research [ 67 ] suggesting the importance of phased assemblies in assessing genomic and phenotypic characteristics.
C. australasica has a high natural genetic diversity with a large number of VOC in different cultivars having β-citronellol, citronellal, γ-terpinene, and limonene as the predominant constituents [ 68 , 69 ]. A previous study has shown that C. australasica is rich in VOC such as citronellal, nonanal, β-phellandrene, δ-elemene, α-farnesol, β-farnesol which can act as antimicrobial agents to provide the plants with resistance against HLB. C. australasica is also known to contain high levels of some amino acids including phenylalanine, tyrosine, and tryptophan and antioxidants which modulate plant responses to pathogens [ 17 ]. Many genes related to VOCs, amino acids and antioxidants were identified in the present genome and these might play a role in modulating defense against the HLB causing pathogens.
Plants produce different families of AMPs which are rich in cystine residues and have antibacterial, antifungal, antiviral and anti-parasite activities. They target and rupture the cell membranes of pathogenic organisms resulting in loss of intracellular ions causing cell death [ 70 , 71 ]. A novel class of short SAMP, having only two cysteine residues, was recently identified from C. australasica showing an ability to suppress the growth of CLas and boost the host immunity against further HLB infections [ 26 ]. The present annotation identified genes encoding different families of AMPs which have not previously been reported in C. australasica which might play important roles in plant immunity against HLB. The gene encoding stress-response A/B barrel domain-containing protein HS1 identified from the collapsed and two haplotypes showed a high sequence homology to previously identified SAMP, however it had a longer sequence (330 bp/110 aa). The 110 bp long version of SAMP sequence is present in both HLB resistant and susceptible citrus species, and they all have a high sequence similarity with a major portion of the short version of the SAMP sequence of C. australasica . C. australis had a SAMP homologous gene encoding two relatively long peptides which also showed sequence homology with C. australasica 67 aa. All this data suggests that both HLB resistant and susceptible citrus species might encode the longer versions of SAMP peptides (large protein precursors), which may then be cleaved into mature polypeptides in resistant cultivars and subjected to further post-translational modifications resulting in short versions of SAMP in resistant cultivars. The other types of defense related genes identified in the genome might have possible roles in HLB resistance as many of those genes have previously been characterized with high expression levels in response to HLB infection in C. australasica [ 15 ] and other HLB resistant species [ 22 ].
The whole genome alignment of C. australis and C. australasica revealed that the two genomes had a high level of synteny across the 9 chromosomes with some rearrangements in all the chromosomes. These rearranged regions characterized by inversions, translocations and duplications might be the main reason for underlying phenotypic differences between the two species. C. australis naturally grows as shrubs or small trees with green, globose, or less-globose fruits and leaf oil predominantly containing α-pinene [ 72 ]. C. australasica is a thorny tree and grows as understory shrubs or small trees in sub-tropical rainforests [ 73 ]. Many CURT1D genes found in the C. australsica genome might explained its tolerance to shade within the forest canopy where it occurs. Within the chloroplasts of a plant cell, thylakoids are organized into grana and the thylakoid membranes are the sites where the light reactions of photosynthesis occur. The curving of the thylakoid membranes at the grana margins which is necessary for grana formation is mediated by CURT1 proteins. Previous studies have shown that plants that are adapted to low light have many layers of thylakoid membranes per granum relative to those found in plants adapted to bright sun light, which provides a means of enhancing the photosynthetic efficiency in shade tolerant plants [ 74 , 75 ]. There is a great variation of the genes with homology to CURT1D identified in the C. australaisca genome ranging from 252 bp to 30,726 bp with complete open reading frames, although it is not known whether they are all functional. The previously reported CURT1 genes in citrus also had a variation in size, however, they all had CDS sequences of more than 440 bp. Therefore, it is possible that the smaller CURT1 proteins might be non-functional. This is the first report of CURT1 genes in citrus and further studies are required to understand the expression of these CURT1 genes and their roles in photosynthesis of citrus plants under fluctuating light conditions.
C. australasica is unique within the Rutaceae family with finger-shaped fruits, novel caviar-like pulp, unusual organoleptic properties (citronellal/limonene/isomenthone), and wide variation in skin and pulp colours [ 2 , 73 ]. . The five cultivars used in this study varied in terms of their fruit skin and pulp colours, tree size, seediness and time of flowering. The whole genome variant analysis based on SNVs revealed structural variations among these five different cultivars which might explain some of the variation in their phenotypes. This revealed C. australasica cv 1 and cv 4 (Red finger lime) as the closest and C. australasica cv 3 (Red champagne) and cv 5 (Ricks Red) as the most divergent cultivars with respect to the Rainbow cultivar. The different skin and pulp colours of the five cultivars might be regulated at the transcription level by anthocyanin regulatory genes [ 52 , 76 ] and β-citraurin [ 77 ]. The structural variations of anthocyanin regulatory genes with their differential expression have been extensively studied among differently coloured citrus types [ 52 , 78 ]. The red pigments of C. australasica are also known to indirectly suppress the CLas infection by impeding the visual signals to D. citri and thereby preventing their feeding [ 17 ]. The high-quality genome we present here will facilitate the study of gene variations regulating a diverse array of red-orange colours in C. australasica in the future, which will provide breeders with direction for developing novel cultivars with high consumer appeal.
The lack of a high-quality genome for C. australasica has greatly hindered genomic research, particularly in relation to HLB resistance. Here we present the first report of a high quality, haplotype resolved genome for C. australasica and its structural and functional characterization. An assessment of genetic diversity present within this species and genomic variations and commonalities with C. australis at a structural and functional level are also provided. This should prove to be a valuable genomic resource to accelerate molecular breeding for the genetic improvement of citrus and will lay the foundation for comparative genomics to broaden our understanding of this unique species in the citrus genus.
Data availability
Raw PacBio HiFi data, and RNA-seq sequence data generated in this study have been deposited in NCBI Sequence Read Archive (SRA) under the BioProject [PRJNA1019815] and Biosample [SAMN37501217] with accession IDs SRR26236521, SRR26251946, and SRR26202756. The whole genome short reads are available under the Bioproject [PRJNA1010857] and the Biosample [SAMN37218318] with accession ID SRR25915022. The whole genome sequence data reported in this paper have been deposited in the Genome Warehouse in National Genomics Data Center [ 79 , 80 ] Beijing Institute of Genomics, Chinese Academy of Sciences / China National Center for Bioinformation, under accession numbers GWHDUCH00000000 (collapsed genome), GWHDUEL00000000 (hap1 genome), GWHDUEM00000000 (hap2 genome), BioProject [PRJCA019902], and Biosample [SAMC3069019] that is publicly accessible at https://ngdc.cncb.ac.cn/gwh .
Abbreviations
Huanglongbing
Candidatus liberibacter asiaticus
C. liberibacter africanus
C. liberibacter americanus
Cetyltrimethyl ammonium bromide
PacBio high fidelity
Fixed ploidy variant detection
Minimum frequencies
Single nucleotide variant positions
Nucleotide binding and leucine rich repeat proteins
Leucine rich repeat receptor-like protein kinases
Calcium dependent protein kinases
Calmodulin like proteins
Synteny and Rearrangement Identifier
Antimicrobial proteins/peptides
Cysteine rich receptor-like protein kinases
Pathogenesis related
Leucine rich repeat proteins
Curvature thylakoid proteins
Carotenoid cleavage dioxygenase 4
Oxford Nanopore Technology
Interstitial telomeric repeats
Gmitter FG, Chen C, Rao MN, Soneji JR. Citrus fruits. In: Fruits and Nuts Edited by Kole C, vol. 4. Berlin: Springer; 2007: 265–279.
Delort E, Jaquier A. Novel terpenyl esters from Australian finger lime (Citrus australasica) peel extract. Flavour Fragr J. 2009;24(3):123–32.
Article CAS Google Scholar
Lim T. Citrus australasica. Edible medicinal and non-medicinal plants. Springer; 2012. pp. 625–8.
Rennie S. Cultivation of Australian Finger Lime (Citrus australasica). In: Australian native plants: cultivation and uses in the health and food industries Taylor & Francis London; 2017: 81–87.
Hawkeswood TJ. A review of some publications concerning Citrus (Microcitrus) Australasica F. Muell.(Rutaceae) in Australia and South-East Asia (mostly Thailand). Calodema. 2017;581:1–14.
Google Scholar
Delort E, Jaquier A, Decorzant E, Chapuis C, Casilli A, Frérot E. Comparative analysis of three Australian finger lime (Citrus australasica) cultivars: identification of unique citrus chemotypes and new volatile molecules. Phytochemistry. 2015;109:111–24.
Article CAS PubMed Google Scholar
Adhikari B, Dutt M, Vashisth T. Comparative phytochemical analysis of the fruits of four Florida-grown finger lime (Citrus australasica) selections. LWT. 2021;135:110003.
Delort E, Yuan Y-M. Finger lime/The Australian Caviar—Citrus australasica. Exotic fruits. Elsevier; 2018. pp. 203–10.
Bowman KD, McCollum G, Plotto A, Bai J. Minnie finger lime: a new novelty citrus cultivar. HortScience. 2019;54(8):1425–8.
Wang N. The citrus huanglongbing crisis and potential solutions. Mol Plant. 2019;12(5):607–9.
Duan Y, Zhou L, Hall DG, Li W, Doddapaneni H, Lin H, Liu L, Vahling CM, Gabriel DW, Williams KP. Complete genome sequence of citrus huanglongbing bacterium,‘Candidatus Liberibacter asiaticus’ obtained through metagenomics. Mol Plant-Microbe Interact. 2009;22(8):1011–20.
Paula BMD, Raithore S, Manthey JA, Baldwin EA, Bai J, Zhao W, Glória MBA, Plotto A. Active taste compounds in juice from oranges symptomatic for Huanglongbing (HLB) citrus greening disease. LWT. 2018;91:518–25.
Article Google Scholar
Tipu MMH, Rahman MM, Islam MM, Elahi F-E, Jahan R, Islam MR. Citrus greening disease (HLB) on Citrus reticulata (Mandarin) caused by Candidatus Liberibacter asiaticus in Bangladesh. Physiol Mol Plant Pathol. 2020;112:101558.
Ferguson K, da Cruz MA, Ferrarezi R, Dorado C, Bai J, Cameron RG. Impact of Huanglongbing (HLB) on grapefruit pectin yield and quality during grapefruit maturation. Food Hydrocolloids. 2021;113:106553.
Weber K, Mahmoud L, Stanton D, Welker S, Qiu W, Grosser J, Levy A, Dutt M. Insights into the mechanism of Huanglongbing tolerance in the Australian finger lime (Citrus australasica). Front Plant Sci 2022, 13.
Miles GP, Stover E, Ramadugu C, Keremane ML, Lee RF. Apparent tolerance to huanglongbing in citrus and citrus-related germplasm. HortScience. 2017;52(1):31–9.
Killiny N, Jones SE, Nehela Y, Hijaz F, Dutt M, Gmitter FG, Grosser JW. All roads lead to Rome: towards understanding different avenues of tolerance to huanglongbing in citrus cultivars. Plant Physiol Biochem. 2018;129:1–10.
Zou X, Bai X, Wen Q, Xie Z, Wu L, Peng A, He Y, Xu L, Chen S. Comparative analysis of tolerant and susceptible citrus reveals the role of methyl salicylate signaling in the response to huanglongbing. J Plant Growth Regul. 2019;38:1516–28.
Hu Y, Zhong X, Liu X, Lou B, Zhou C, Wang X. Comparative transcriptome analysis unveils the tolerance mechanisms of Citrus hystrix in response to ‘Candidatus Liberibacter asiaticus’ infection. PLoS ONE. 2017;12(12):e0189229.
Article PubMed PubMed Central Google Scholar
Rao MJ, Ding F, Wang N, Deng X, Xu Q. Metabolic mechanisms of host species against citrus Huanglongbing (Greening Disease). Crit Rev Plant Sci. 2018;37(6):496–511.
Wu H, Hu Y, Fu S, Zhou C, Wang X. Coordination of multiple regulation pathways contributes to the tolerance of a wild citrus species (Citrus ichangensis ‘2586’) against Huanglongbing. Physiol Mol Plant Pathol. 2020;109:101457.
Peng Z, Bredeson JV, Wu GA, Shu S, Rawat N, Du D, Parajuli S, Yu Q, You Q, Rokhsar DS. A chromosome-scale reference genome of trifoliate orange (Poncirus trifoliata) provides insights into disease resistance, cold tolerance and genome evolution in Citrus. Plant J. 2020;104(5):1215–32.
Article CAS PubMed PubMed Central Google Scholar
Ramadugu C, Keremane ML, Halbert SE, Duan YP, Roose ML, Stover E, Lee RF. Long-term field evaluation reveals huanglongbing resistance in Citrus relatives. Plant Dis. 2016;100(9):1858–69.
Article PubMed Google Scholar
Alves MN, Lopes SA, Raiol-Junior LL, Wulff NA, Girardi EA, Ollitrault P, Peña L. Resistance to ‘Candidatus Liberibacter Asiaticus,’the huanglongbing associated bacterium, in sexually and/or graft-compatible citrus relatives. Front Plant Sci. 2021;11:2166.
Alquézar B, Carmona L, Bennici S, Peña L. Engineering of citrus to obtain huanglongbing resistance. Curr Opin Biotechnol. 2021;70:196–203.
Huang C-Y, Araujo K, Sánchez JN, Kund G, Trumble J, Roper C, Godfrey KE, Jin H. A stable antimicrobial peptide with dual functions of treating and preventing citrus Huanglongbing. Proceedings of the National Academy of Sciences 2021, 118(6):e2019628118.
Nakandala U, Masouleh AK, Smith MW, Furtado A, Mason P, Constantin L, Henry RJ. Haplotype resolved chromosome level genome assembly of Citrus australis reveals disease resistance and other citrus specific genes. Hortic Res. 2023;10(5):uhad058.
Mabberley DJ. A classification for edible citrus: an update, with a note on Murraya (Rutaceae). Telopea. 2022;25:271–84.
Furtado A. DNA extraction from vegetative tissue for next-generation sequencing. In: Cereal genomics Springer; 2014: 1–5.
Furtado A. RNA extraction from developing or mature wheat seeds. In: Cereal Genomics Springer; 2014: 23–28.
Cheng H, Concepcion GT, Feng X, Zhang H, Li H. Haplotype-resolved de novo assembly using phased assembly graphs with hifiasm. Nat Methods. 2021;18(2):170–5.
Langmead B, Salzberg SL. Fast gapped-read alignment with Bowtie 2. Nat Methods. 2012;9(4):357–9.
Zhang H, Song L, Wang X, Cheng H, Wang C, Meyer CA, Liu T, Tang M, Aluru S, Yue F. Fast alignment and preprocessing of chromatin profiles with Chromap. Nat Commun. 2021;12(1):6566.
Li H. Aligning sequence reads, clone sequences and assembly contigs with BWA-MEM. arXiv preprint arXiv:13033997 2013.
Ghurye J, Pop M, Koren S, Bickhart D, Chin C-S. Scaffolding of long read assemblies using long range contact information. BMC Genomics. 2017;18(1):1–11.
Zhou C, McCarthy SA, Durbin R. YaHS: yet another Hi-C scaffolding tool. Bioinformatics. 2023;39(1):btac808.
Guan D, McCarthy SA, Ning Z, Wang G, Wang Y, Durbin R. Efficient iterative Hi-C scaffolder based on N-best neighbors. BMC Bioinformatics. 2021;22(1):1–16.
Simão FA, Waterhouse RM, Ioannidis P, Kriventseva EV, Zdobnov EM. BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics. 2015;31(19):3210–2.
Gurevich A, Saveliev V, Vyahhi N, Tesler G. QUAST: quality assessment tool for genome assemblies. Bioinformatics. 2013;29(8):1072–5.
Cabanettes F, Klopp C. D-GENIES: dot plot large genomes in an interactive, efficient and simple way. PeerJ. 2018;6:e4958.
Manekar SC, Sathe SR. A benchmark study of k-mer counting methods for high-throughput sequencing. GigaScience. 2018;7(12):giy125.
PubMed PubMed Central Google Scholar
Vurture GW, Sedlazeck FJ, Nattestad M, Underwood CJ, Fang H, Gurtowski J, Schatz MC. GenomeScope: fast reference-free genome profiling from short reads. Bioinformatics. 2017;33(14):2202–4.
Flynn JM, Hubley R, Goubert C, Rosen J, Clark AG, Feschotte C, Smit AF. RepeatModeler2 for automated genomic discovery of transposable element families. Proc Natl Acad Sci. 2020;117(17):9451–7.
Chen N. Using repeat Masker to identify repetitive elements in genomic sequences. Curr Protocols Bioinf. 2004;5(1):410–11.
Kim D, Paggi JM, Park C, Bennett C, Salzberg SL. Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nat Biotechnol. 2019;37(8):907–15.
Sun J, Lu F, Luo Y, Bie L, Xu L, Wang Y. OrthoVenn3: an integrated platform for exploring and visualizing orthologous data across genomes. Nucleic Acids Res 2023:gkad313.
Goel M, Sun H, Jiao W-B, Schneeberger K. SyRI: finding genomic rearrangements and local sequence differences from whole-genome assemblies. Genome Biol. 2019;20(1):1–13.
Kanehisa M, Goto S. KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000;28(1):27–30.
Wang Y, Jia L, Tian G, Dong Y, Zhang X, Zhou Z, Luo X, Li Y, Yao W. shinyCircos-V2. 0: leveraging the creation of Circos plot with enhanced usability and advanced features. iMeta 2023:e109.
Wang Y, Tang H, DeBarry JD, Tan X, Li J, Wang X, Lee T-h, Jin H, Marler B, Guo H. MCScanX: a toolkit for detection and evolutionary analysis of gene synteny and collinearity. Nucleic Acids Res. 2012;40(7):e49–49.
Chen C, Chen H, Zhang Y, Thomas HR, Frank MH, He Y, Xia R. TBtools: an integrative toolkit developed for interactive analyses of big biological data. Mol Plant. 2020;13(8):1194–202.
Chen J, Liu F, Wu RA, Chen J, Wang W, Ye X, Liu D, Cheng H. An up-to-date review: differential biosynthesis mechanisms and enrichment methods for health-promoting anthocyanins of citrus fruits during processing and storage. Crit Rev Food Sci Nutr 2022:1–27.
Huang Y, He J, Xu Y, Zheng W, Wang S, Chen P, Zeng B, Yang S, Jiang X, Liu Z. Pangenome analysis provides insight into the evolution of the orange subfamily and a key gene for citric acid accumulation in citrus fruits. Nat Genet 2023:1–12.
Kong W, Wang Y, Zhang S, Yu J, Zhang X. Recent Advances in Assembly of Plant Complex Genomes. Genomics, Proteomics & Bioinformatics 2023.
Deng H, Xiang S, Guo Q, Jin W, Cai Z, Liang G. Molecular cytogenetic analysis of genome-specific repetitive elements in Citrus Clementina Hort. Ex Tan. And its taxonomic implications. BMC Plant Biol. 2019;19:1–11.
He L, Zhao H, He J, Yang Z, Guan B, Chen K, Hong Q, Wang J, Liu J, Jiang J. Extraordinarily conserved chromosomal synteny of Citrus species revealed by chromosome-specific painting. Plant J. 2020;103(6):2225–35.
Fann J-Y, Kovarik A, Hemleben V, Tsirekidze N, Beridze T. Molecular and structural evolution of Citrus satellite DNA. Theor Appl Genet. 2001;103:1068–73.
Gaspin C, Rami J-F, Lescure B. Distribution of short interstitial telomere motifs in two plant genomes: putative origin and function. BMC Plant Biol. 2010;10(1):1–12.
Maravilla AJ, Rosato M, Rosselló JA. Interstitial telomeric-like repeats (ITR) in seed plants as assessed by molecular cytogenetic techniques: a review. Plants. 2021;10(11):2541.
Padmanabhan M, Cournoyer P, Dinesh-Kumar S. The leucine‐rich repeat domain in plant innate immunity: a wealth of possibilities. Cell Microbiol. 2009;11(2):191–8.
Zia K, Rao MJ, Sadaqat M, Azeem F, Fatima K, Tahir ul Qamar M, Alshammari A, Alharbi M. Pangenome-wide analysis of cyclic nucleotide-gated channel (CNGC) gene family in Citrus Spp. Revealed their intraspecies diversity and potential roles in abiotic stress tolerance. Front Genet. 2022;13:1034921.
Wu Y, Zhang L, Zhou J, Zhang X, Feng Z, Wei F, Zhao L, Zhang Y, Feng H, Zhu H. Calcium-dependent protein kinase GhCDPK28 was dentified and involved in verticillium wilt resistance in cotton. Front Plant Sci. 2021;12:772649.
Jarratt-Barnham E, Wang L, Ning Y, Davies JM. The complex story of plant cyclic nucleotide-gated channels. Int J Mol Sci. 2021;22(2):874.
Xiao X, Wang R, Khaskhali S, Gao Z, Guo W, Wang H, Niu X, He C, Yu X, Chen Y. A novel glycerol kinase gene OsNHO1 regulates Resistance to Bacterial Blight and Blast diseases in Rice. Front Plant Sci. 2022;12:800625.
Li W, Mi X, Jin X, Zhang D, Zhu G, Shang X, Zhang D, Guo W. Thiamine functions as a key activator for modulating plant health and broad-spectrum tolerance in cotton. Plant J. 2022;111(2):374–90.
Strobbe S, Verstraete J, Stove C, Van Der Straeten D. Metabolic engineering provides insight into the regulation of thiamin biosynthesis in plants. Plant Physiol. 2021;186(4):1832–47.
Guk JY, Jang MJ, Choi JW, Lee YM, Kim S. De novo phasing resolves haplotype sequences in complex plant genomes. Plant Biotechnol J 2022.
Cozzolino R, Câmara JS, Malorni L, Amato G, Cannavacciuolo C, Masullo M, Piacente S. Comparative volatilomic profile of three finger lime (Citrus australasica) cultivars based on chemometrics analysis of HS-SPME/GC–MS data. Molecules. 2022;27(22):7846.
Johnson JB, Batley R, Manson D, White S, Naiker M. Volatile compounds, phenolic acid profiles and phytochemical content of five Australian finger lime (Citrus australasica) cultivars. LWT 2022, 154:112640.
Nawrot R, Barylski J, Nowicki G, Broniarczyk J, Buchwald W, Goździcka-Józefiak A. Plant antimicrobial peptides. Folia Microbiol. 2014;59(3):181–96.
Tang R, Tan H, Dai Y, Huang Y, Yao H, Cai Y, Yu G. Application of antimicrobial peptides in plant protection: making use of the overlooked merits. Front Plant Sci 2023, 14.
Brophy JJ, Goldsack RJ, Forster PI. The leaf oils of the Australian species of Citrus (Rutaceae). J Essent Oil Res. 2001;13(4):264–8.
Follett PA, Asmus G, Hamilton LJ. Poor host status of Australian Finger Lime, Citrus australasica, to Ceratitis capitata, Zeugodacus cucurbitae, and Bactrocera dorsalis (Diptera: Tephritidae) in Hawai’i. Insects. 2022;13(2):177.
Armbruster U, Labs M, Pribil M, Viola S, Xu W, Scharfenberg M, Hertle AP, Rojahn U, Jensen PE, Rappaport F. Arabidopsis CURVATURE THYLAKOID1 proteins modify thylakoid architecture by inducing membrane curvature. Plant Cell. 2013;25(7):2661–78.
Pribil M, Sandoval-Ibáñez O, Xu W, Sharma A, Labs M, Liu Q, Galgenmueller C, Schneider T, Wessels M, Matsubara S. Fine-tuning of photosynthesis requires CURVATURE THYLAKOID1-mediated thylakoid plasticity. Plant Physiol. 2018;176(3):2351–64.
Wang C, Ye D, Li Y, Hu P, Xu R, Wang X. Genome-wide identification and bioinformatics analysis of the WRKY transcription factors and screening of candidate genes for anthocyanin biosynthesis in azalea (Rhododendron simsii). Front Genet. 2023;14:1172321.
Ma G, Zhang L, Matsuta A, Matsutani K, Yamawaki K, Yahata M, Wahyudi A, Motohashi R, Kato M. Enzymatic formation of β-citraurin from β-cryptoxanthin and zeaxanthin by carotenoid cleavage dioxygenase4 in the flavedo of citrus fruit. Plant Physiol. 2013;163(2):682–95.
Butelli E, Garcia-Lor A, Licciardello C, Las Casas G, Hill L, Recupero GR, Keremane ML, Ramadugu C, Krueger R, Xu Q. Changes in anthocyanin production during domestication of Citrus. Plant Physiol. 2017;173(4):2225–42.
CNCB-NGDC. Database resources of the national genomics data center, China national center for bioinformation in 2022. Nucleic Acids Res vol. 2022;50:D27–38.
Chen M, Ma Y, Wu S, Zheng X, Kang H, Sang J, Xu X, Hao L, Li Z, Gong Z. Genome warehouse: a public repository housing genome-scale data. Genom Proteom Bioinform. 2021;19(4):584–9.
Download references
Acknowledgements
The Research Computing Centre (RCC), University of Queensland, provided high performance computing facilities. Patrick Mason assisted in the collection of leaf materials of C. australasica . RH was supported by the ARC Centre of Excellence for Plant Success in Nature and Agriculture (CE 200100015).
This project was funded by the Hort Frontiers Advanced Production Systems Fund as part of the Hort Frontiers strategic partnership initiative developed by Hort Innovation, with co-investment from The University of Queensland, and contributions from the Australian Government and Bioplatforms Australia.
Author information
Authors and affiliations.
Queensland Alliance for Agriculture and Food Innovation, University of Queensland, Brisbane, 4072, Australia
Upuli Nakandala, Agnelo Furtado, Ardashir Kharabian Masouleh & Robert J. Henry
ARC Centre of Excellence for Plant Success in Nature and Agriculture, University of Queensland, Brisbane, 4072, Australia
Department of Agriculture and Fisheries, Bundaberg Research Station, Bundaberg, QLD, 4670, Australia
Malcolm W. Smith
Herbalistics Pty Ltd, Bli Bli, Queensland, 4560, Australia
Darren C. Williams
You can also search for this author in PubMed Google Scholar
Contributions
The authors confirm contribution to the paper as follows: RH, AF, AKM involved in study conception, design and supervision, UN performed data collection. AF, RH advised on laboratory experiments. UN performed analysis and UN, RH, AF, MS, DW involved in the interpretation of results. UN prepared the draft manuscript and generated all the figures. All authors reviewed the results and approved the final version of the manuscript.
Corresponding author
Correspondence to Robert J. Henry .
Ethics declarations
Ethics approval and consent to participate.
Not applicable.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary material 2, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Nakandala, U., Furtado, A., Masouleh, A.K. et al. The genome of Citrus australasica reveals disease resistance and other species specific genes. BMC Plant Biol 24 , 260 (2024). https://doi.org/10.1186/s12870-024-04988-8
Download citation
Received : 23 October 2023
Accepted : 04 April 2024
Published : 10 April 2024
DOI : https://doi.org/10.1186/s12870-024-04988-8
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Chromosome scale genome
- Haplotype-resolved
- C. australasica specific genes
- Disease resistance
- Colour related genes
- Genetic improvement
BMC Plant Biology
ISSN: 1471-2229
- General enquiries: [email protected]
IMAGES
VIDEO
COMMENTS
Annotation can be: A systematic summary of the text that you create within the document. A key tool for close reading that helps you uncover patterns, notice important words, and identify main points. An active learning strategy that improves comprehension and retention of information.
The V7 Text Annotation Tool is a feature within the V7 platform that facilitates the annotation of text data within images and documents. This tool automates the process of detecting and reading text from various types of visual content, including images, photos, documents, and videos.
Learning to effectively annotate text is a powerful tool that can improve your reading, self-learning, and study strategies. Using an annotating system that includes text annotations and note-taking during close reading helps you actively engage with the text, leading to a deeper understanding of the material.
Annotate Definition. To annotate is to make notes on or mark up a text with one's thoughts, questions, or realizations while reading. The term annotation refers to the actual notes one has written ...
Annotating a Text (Hunter College) This resource is designed for college students and shows how to annotate a scholarly article using highlighting, paraphrase, a descriptive outline, and a two-margin approach. It ends with a sample passage marked up using the strategies provided.
Annotating is any action that deliberately interacts with a text to enhance the reader's understanding of, recall of, and reaction to the text. Sometimes called "close reading," annotating usually involves highlighting or underlining key pieces of text and making notes in the margins of the text. This page will introduce you to several ...
Whereas entity annotation is the labeling of individual words or phrases, text classification is the process of annotating of an entire body or line of text with a single label. Related text annotation types include: Document classification: The classification of documents used to help with the sorting and recall of text-based content.
Text annotation is a crucial part of natural language processing (NLP), through which textual data is labeled to identify and classify its components. Essential for training NLP models, text annotation involves tasks like named entity recognition, sentiment analysis, and part-of-speech tagging. By providing context and meaning to raw text, it ...
Annotating literally means taking notes within the text as you read. As you annotate, you may combine a number of reading strategies—predicting, questioning, dealing with patterns and main ideas, analyzing information—as you physically respond to a text by recording your thoughts. Annotating may occur on a first or second reading of the ...
For the annotation of reading assignments in this class, you will cite and comment on a minimum of FIVE (5) phrases, sentences or passages from notes you take on the selected readings. Here is an example format for an assignment to annotate a written text: Passage #. Quotation and Location. My Comments / Ideas.
Text annotation is a subset of data annotation where the annotation process focuses only on text data such as PDFs, DOCs, ODTs etc. Text annotation requires manual work. Data scientists determine the labels or "tags" and passes the text-specific information to the NLP model being trained. This process can be thought of as a child's ...
That's annotation—helping to make the text more accessible and understandable for you. Abstract: On the other hand, an abstract is a short summary of a document's main points. Think of it as a mini version of the text. If you've ever written a research paper, you've probably had to include an abstract at the beginning. It gives readers a ...
Adding annotations to a text is an individual process, so there's no right or wrong way. However, you can use these tips to maximize your annotations and ensure they're helpful. Enhance your learning with effective annotation. Whether reading for leisure or learning, knowing how to annotate can benefit your experience. Using annotations ...
Text annotation is labeling the text, phrases, and sentences using additional metadata to make the machines learn about objects and things. Depending upon the project requirements and complexity, data sets are created by labeling the important parts of a speech, syntax, sentence, etc. After the required text is annotated, the datasets are used ...
What is Text Annotation? Algorithms use large amounts of annotated data to train AI models, which is part of a larger data labeling workflow. During the annotation process, a metadata tag is used to mark up characteristics of a dataset. With text annotation, that data includes tags that highlight criteria such as keywords, phrases, or sentences ...
Creating an Annotation System: Annotating while you read is the most fundamental technique of active reading. Learn how to annotate a text by watching this video. Annotating an Essay or Book: Learn what to look for when annotating an essay or book. Annotating a Textbook: Learn how to identify and annotate the key parts of a textbook.
Text annotation is identifying and labeling sentences with additional information or metadata to define the characteristics of sentences. This information could be highlighting parts of speech in a sentence, grammar syntax, keywords, phrases, emotions, sarcasm, sentiments and more depending on the scope of a project.
Annotating a text, or marking the pages with notes, is an excellent, if not essential, way to make the most out of the reading you do for college courses. Annotations make it easy to find important information quickly when you look back and review a text. They help you familiarize yourself with both the content and organization of what you read.
The inclusion of annotations can bring additional value and information to your work. Understand how to properly include these with annotation examples. Dictionary ... Annotations ensure that you understand what is happening in a text when you come back to it, or provide others with valuable information about the text. ...
Annotation can be: A systematic summary of the text that you create within the document. A key tool for close reading that helps you uncover patterns, notice important words, and identify main points. An active learning strategy that improves comprehension and retention of information.
Traditionally, text annotation involves adding comments, notes, or footnotes to a body of text. This practice is commonly seen when editors review a draft, adding notes or useful comments (i.e. annotations) before passing it on for corrections. In the context of machine learning, the term takes on a slightly different meaning.
These 11 annotation techniques will bring your reading comp to the next level!Another helpful annotation strategy: https://youtu.be/tEMNDdfLWDA D E T A I L S...
Our text annotation, image annotation, audio annotation, and video annotation capabilities will cover the short-term and long-term demands of your team and your organization. Whatever your data annotation needs may be, our platform, our crowd, and managed services team are standing by to assist you in deploying and maintaining your AI and ML ...
Book annotation is a way of recording your own thoughts and reactions to the text you're reading, whether you're marking ideas to return to later or simply emphasizing a turn of phrase you ...
Help visualize the point you're trying to make. Screenshot: Annotate for Chrome SHARE. The web doesn't have to stay fixed and static. With the right tools, you can type and scribble over the ...
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications.
Teaching Proper Text Annotations & Evidence. This teacher professional development course emphasizes the significance of teaching students of various grade levels the skill of effective text annotation and explains its importance in helping them interact more deeply with the text. Participants will understand how to guide students in using ...
The finger lime (Citrus australasica), one of six Australian endemic citrus species shows a high natural phenotypic diversity and novel characteristics. The wide variation and unique horticultural features have made this lime an attractive candidate for domestication. Currently no haplotype resolved genome is available for this species. Here we present a high quality, haplotype-resolved ...